一种基于对抗攻击的用户人格隐私保护方法
本发明涉及一种基于对抗攻击的用户人格隐私保护方法,属于网络空间安全/社会工程学领域。
背景技术:
近年来,网络空间威胁的目标开始逐步聚焦在“人”上,针对“人”的社会工程学攻击(如电信诈骗、网络钓鱼等)层出不穷并造成了巨大损失,社会工程学利用人的心理弱点(如人的本能反应、好奇心、信任、贪婪)进行攻击,攻击者借助大数据或人工智能等更深入地了解目标、分析目标人格特点、发现目标缺陷,从而精准构造目标更易信任的场景,大幅提高攻击成功率;并且当前的防御技术主要考虑攻击的信息特征,并没有抓住社会工程学的核心——目标“人”的特殊性,且防御方法过于被动,而不同目标在社工攻击中的脆弱性差异巨大,攻击者的侧重点也有所不同。发现攻击者如何找到“人”的弱点并利用的原理,在关键环节上进行阻断或干扰,是有效进行社会工程学攻击防护的重要前提。
人是一个复杂多变的综合体,对人的分析涉及复杂的心理学因素,在诸多心理学因素中,“人格”是一个相对稳定、全面的心理学特征,广泛应用于安全领域与人有关的研究中。有研究表明社会工程学可对人格进行利用,例如研究者通过钓鱼邮件的实验发现不同人格的钓鱼邮件易感性存在差异,高宜人性人群容易对别人产生信赖、更容易相信钓鱼邮件,而高尽责性人群更加谨慎,不太容易被钓鱼邮件所欺骗。所以,保护被攻击对象的人格隐私可以有效干扰或欺骗攻击者的人格分析,使攻击者获取错误的人格信息,避免攻击者对人格脆弱性的利用,降低社会工程学攻击的成功率。
目前人格隐私保护的研究尚处于空白,进行人格隐私保护研究是对网络空间中的“人”进行安全防护的合适起点,对日后认知域安全的深入研究具有重要意义。
技术实现要素:
针对上述问题,本发明提出了一种基于对抗攻击的用户人格隐私保护方法,通过分析当前主流人格构建并训练大数据人格分类模型,通过在梯度方向增加扰动产生对抗噪音,与原语义向量叠加生成语义不变的新语义向量,经过逆向处理生成混乱人格文本,来诱导网络对生成的语义向量进行误分类,实现人格信息的改变或干扰,从而达到保护用户人格隐私的目的。
所述的基于对抗攻击的用户人格隐私保护方法,具体步骤如下:
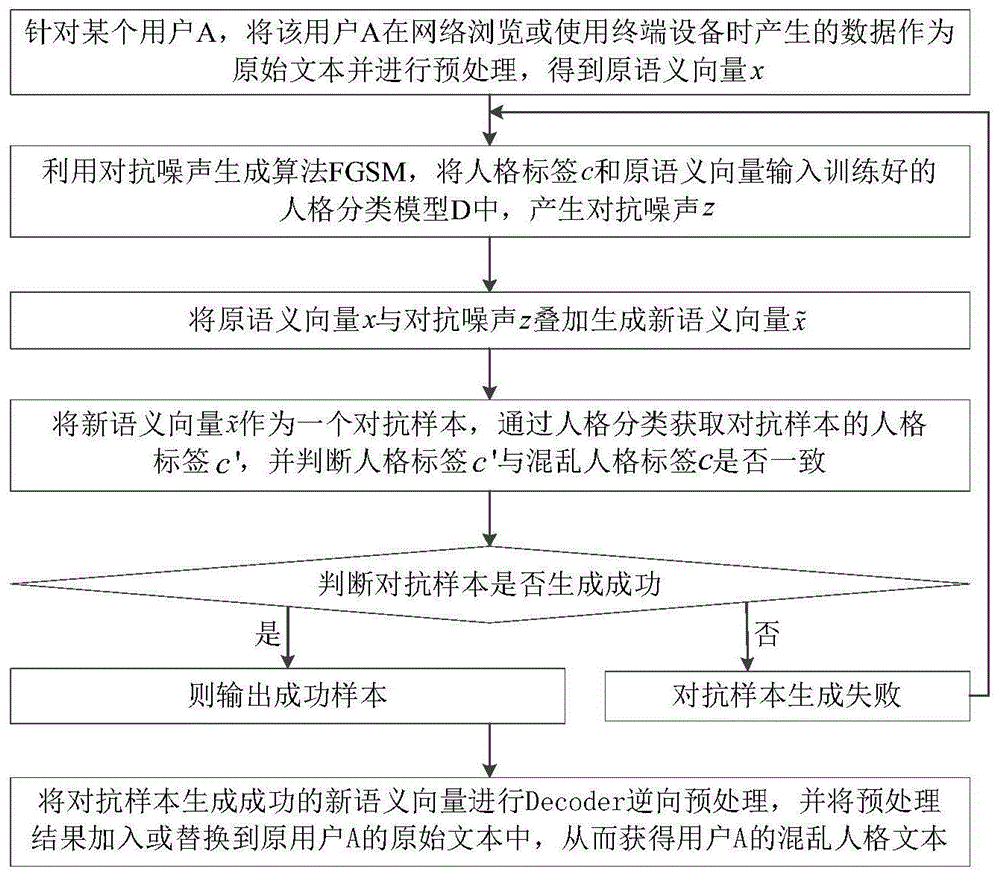
步骤一、针对某个用户a,将该用户a在网络浏览或使用终端设备时产生的数据作为原始文本并进行预处理,得到原语义向量x;
预处理是指对数据进行标准化和规范化、文本处理等;
步骤二、利用对抗噪声生成算法fgsm,将随机生成的混乱人格标签c和原语义向量输入训练好的人格分类模型d中,产生对抗噪声z;
θ是人格分类模型参数;j(θ,x,c)是损失函数;η是训练步长;c为定向的人格one-hot编码值标签,或任意的人格one-hot编码值标签;
步骤三、将原语义向量x与对抗噪声z叠加生成新语义向量
步骤四、将新语义向量
针对第i个对抗样本,判断标签是否一致需满足:
公式(1)表示对抗样本生失败,(2)表示对抗样本生成成功。
步骤五、判断对抗样本是否生成成功,如果是,则输出成功样本,进入步骤六;否则,对抗样本生成失败,则返回步骤二;
步骤六、将对抗样本生成成功的新语义向量进行decoder逆向预处理,并将预处理结果加入或替换到原用户a的原始文本中,从而获得用户a的混乱人格文本。
本发明的优点在于:
1)一种基于对抗攻击的用户人格隐私保护方法,从分析对抗的角度,对人格分类模型进行扰乱,实现人格信息分析过程的干扰,从而达到用户人格隐私保护的目的。
2)一种基于对抗攻击的用户人格隐私保护方法,为人格隐私保护方法提供指导,进行人格隐私保护方法对日后认知域安全的深入研究具有重要意义。
3)一种基于对抗攻击的用户人格隐私保护方法,对抗样本生成的过程是不断拉近原语义向量与新语义向量之间的差别,样本生成不成功时,噪音不断更新的过程即为拉近语义的过程,实现了文本数据在语义相似条件下的人格变换,进而达到保护用户人格隐藏的目的。
4)一种基于对抗攻击的用户人格隐私保护方法,人格隐私保护对网络中的社会工程学防护技术提供了支撑,同时为之后的社会工程学防护研究提供了理论基础。
附图说明
图1为本发明一种基于对抗攻击的用户人格隐私保护方法流程图;
图2为本发明一种基于对抗攻击的用户人格隐私保护方法原理图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图对本发明作进一步的详细和深入描述。
人格的隐私保护要远比位置隐私等复杂,最根本的原因是人格隐私泄露的渠道复杂繁多,攻击者进行人格分析的方法也多样,且当前对分析方法的总结也不完备。人格是重要的心理特征,应该作为隐私加以保护。但目前还没有人格隐私这一概念,更没有针对人格隐私的保护方法。考虑到现在针对用户人格隐私保护的方法研究处于空白的情况,本发明提出一种基于对抗攻击的用户人格隐私保护方法。
本发明研究基于非定向对抗攻击的混乱人格对抗样本生成方法;通过对当前主流的人格进行分析,构建大数据人格分类模型库;从分析对抗的角度,对人格分类模型进行扰乱;针对训练好的人格分类模型,通过在梯度方向上进行轻微扰动,基于混乱人格标签产生对抗噪声,与原语义向量叠加生成语义不变的新语义向量,来诱导网络对生成的新语义向量进行误分类。使得攻击者只能获得基于人格分类模型生成的混乱人格文本,实现人格信息的改变或干扰,从而达到保护用户人格隐私的目的。
所述的基于对抗攻击的用户人格隐私保护方法,如图1所示,具体步骤如下:
步骤一、针对某个用户a,将该用户a在网络浏览或使用终端设备时产生的数据作为原始文本并进行预处理,得到原语义向量x;
预处理是指对数据进行标准化和规范化、文本处理等;
步骤二、利用对抗噪声生成算法fgsm,将随机生成的混乱人格标签c和原语义向量输入训练好的人格分类模型d中,产生对抗噪声z;
θ是人格分类模型参数;j(θ,x,c)是损失函数;η是训练步长;c为定向的人格one-hot编码值标签,或任意的人格one-hot编码值标签;
步骤三、将原语义向量x与对抗噪声z叠加生成新语义向量
步骤四、将新语义向量
针对第i个对抗样本,判断标签是否一致需满足:
公式(1)表示对抗样本生失败,(2)表示对抗样本生成成功。
步骤五、判断对抗样本是否生成成功,如果是,则输出成功样本,进入步骤六;否则,对抗样本生成失败,则返回步骤二;
步骤六、将对抗样本生成成功的新语义向量进行decoder逆向预处理,并将预处理结果加入或替换到原用户a的原始文本中,从而获得用户a的混乱人格文本。
本发明探讨文本数据与人格的映射关系,提出保持语义下的人格隐私保护方法。研究基于文本信息的人格分析模型建立方法,研究基于机器学习的人格关联文本提取方法,建立人格关联的文本库,指导人格隐私保护。自然语言领域中,对文本微小的扰动也是可以清楚感知的,通过文献调研和案例分析,研究基于对抗攻击的用户混乱人格形成方法,研究基于对抗攻击的文本数据与人格分析模型之间的内在联系,建立文本数据与用户人格的关联库。研究基于非定向对抗攻击的用户混乱人格形成方法,达到混乱人格的目的,实现用户人格隐私保护。
实施例
在本实施例中,使用fgsm作为对抗样本生成算法;针对训练好的人格分类模型,通过在梯度方向上进行轻微的扰动产生对抗噪声,然后将对抗噪声与原语义向量叠加生成新语义向量。并且通过检测发现新的语义向量的语义没有发生改变,然后逆向处理获得新的混乱人格文本来诱导网络对人格进行误分类。
如图2所示,本发明主要分为原始文本的预处理,对抗噪声的生成,对抗噪声与原语义的叠加,以及语义逆向处理四个部分;
其中,获得原始文本以后,首先要对其利用预处理词典获得原语义向量x,以方便后续与产生的对抗噪声进行叠加;
然后,针对训练好的人格分类模型,选择合适的对抗噪声生成算法,将混乱人格c(是指用户输入的不是原人格onehot编码值,而是混乱人格onehot编码值,混乱人格分为定向或任意人格onehot编码值)进行处理,产生优质的对抗噪声。
接着,对原语义向量x与对抗噪声叠加合成新语义向量,并检测新语义向量是否更改了语义,如果语义被更改,则需要重新生成对抗噪声,并重新进行叠加,直到新语义向量不会更改语义。
最后,将获得的新语义采用逆向预处理字典进行处理,从而获得所需的混乱人格文本。
- 还没有人留言评论。精彩留言会获得点赞!