一种基于CGAN模型的用户人格隐私保护方法
本发明涉及一种基于cgan(conditionalgenerativeadversarialnetworks)模型的用户人格隐私保护方法,属于网络空间安全/社会工程学领域。
背景技术:
世界第一黑客凯文米特尼克在《欺骗的艺术》中曾提到:“人为因素才是安全的软肋”。近年来,网络空间威胁开始逐步聚焦在目标“人”上,针对“人”的社会工程学攻击(如电信诈骗、网络钓鱼等)层出不穷并造成了巨大损失,社会工程学利用人的心理弱点(如人的本能反应、好奇心、信任、贪婪)进行攻击,攻击者借助大数据或人工智能等更深入地了解目标和发现目标的缺陷,从而精准的构造目标更易信任的场景,大幅提高了攻击成功率。社会工程学网络攻击给政治、国防、社会和经济造成了巨大的威胁,在损失金额上,内部人员泄密导致的损失是黑客造成损失的16倍,是病毒造成损失的12倍。
人是一个复杂多变的综合体,对人的分析涉及复杂的心理学因素,在诸多心理学因素中,“人格”是一个相对稳定和全面的心理学特征,广泛应用于安全领域与人有关的研究中。
目前针对社会工程学的防御研究主要集中在网络钓鱼方面(钓鱼邮件、钓鱼网站以及社交网络钓鱼等),通过技术手段对社会工程学攻击的载体进行被动防御(如基于特征分析和基于黑白名单的钓鱼检测方法),近年来大量的案件显示其效果并不理想。究其根本,当前的防御技术主要考虑攻击的信息特征,并没有抓住社会工程学的核心——目标“人”的特殊性,且防御方法过于被动,而不同目标在社工攻击中的脆弱性差异巨大,攻击者的侧重点也有所不同,发现攻击者如何找到“人”的弱点并利用,以便在关键环节上进行阻断或干扰,是有效进行社会工程学攻击防护的重要前提。
同时,用户人格信息的泄露为攻击者提供了更加有力的攻击条件,大大提高了社工攻击的成功率,保护人格隐私也成为了现在最为迫切的任务之一。然而当前并没有人格隐私保护这一领域的研究,更没有相应的隐私保护方法。
技术实现要素:
针对上述问题,本发明提出了一种基于cgan模型的用户人格隐私保护方法,实现了文本数据在语义相似条件下的人格变换,进而达到保护用户人格隐私的目的。
所述的基于cgan模型的用户人格隐私保护方法,具体步骤如下:
步骤一、通过社交网络收集某个用户a的原始文本数据,并辨别出该用户a的人格类别标签;
条件人格类别标签包括:定向人格标签或不定向人格标签;
原始文本数据包括:用户名和用户发布的文本内容。
步骤二、对原始文本数据进行预处理,获得服从x~pdata(x)分布的原语义向量x;
步骤三、随机选择混淆人格标签c作为条件,结合随机的噪声向量z,一起输入cgan模型的语义生成器g(z|c;θg),生成新的语义向量x',且服从分布x'~pg(x');
噪声向量z服从分布z~pz(z);θg是语义生成器的参数;c为人格类别标签的one-hot编码值,如果条件是定向人格,则c为特定人格的标签,如果不定向则c为任意标签值。
语义生成器的损失函数为:
步骤四、将生成的语义向量x'和原语义向量x一起输入语义判别器d(x;θd)进行真假判别;语义判别器的损失函数为:
步骤五、判断语义判别器d(x;θd)的输出是否为真,如果是,进入步骤六;否则,继续训练混淆人格标签c和噪声向量z,返回步骤三;
步骤六、将输出为真的语义向量x'经过人格辨别器q(c′,c),得到生成语义向量x'的人格c'标签;
辨别器的损失函数计算如下:
通过训练判别器的损失函数,使得生成的人格c'标签与条件人格c一致;
步骤七、将输出的语义向量x'为真,且生成的人格c'标签与条件人格标签c一致的文本向量,逆向预处理,并将预处理结果加入或替换到原用户a的原始文本数据中,混淆用户a的人格文本信息。
本发明的优点在于:
1)一种基于cgan模型的用户人格隐私保护方法,采用cgan生成语义相似的定向或非定向人格文本,通过加入噪音和定向人格数据完成人格信息的混淆和隐藏,使得攻击者不能正确分析出用户的人格特质,进而达到用户人格隐私保护的目的。
2)一种基于cgan模型的用户人格隐私保护方法,保护被攻击对象的人格隐私可以有效干扰或欺骗攻击者的人格分析结果,使攻击者获取错误人格信息,避免攻击者对人格脆弱性的利用,降低社会工程学攻击的成功率。
3)一种基于cgan模型的用户人格隐私保护方法,为人格隐私保护空白研究领域进行了初期探索。
4)一种基于cgan模型的用户人格隐私保护方法,减少工作量,实现端到端的自动化人格转换。
附图说明
图1为本发明一种基于gan模型的用户人格隐私保护方法的流程图;
图2为本发明一种基于gan模型的用户人格隐私保护方法的原理图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图对本发明作进一步的详细和深入描述。
本发明提出了一种基于cgan模型的用户人格隐私保护方法,是一种在社交网络用户人格分析与预测模型的研究基础上,进一步探寻用户人格隐私保护的方法。人格隐私保护是基于语义不变条件下对文本数据进行轻微的改变,使得人格分类器不能正确分类修改后的文本数据。
社交网络用户人格的获取来源是对用户文本数据的分析,文本数据的泄露间接泄露了用户人格,对文本数据特征的保护或者改变对用户人格的分析会产生一定的干扰,阻断攻击者获取用户人格信息。本发明从用户文本数据的角度出发,采用cgan模型生成予以相似的定向或非定向混乱人格文本,从而定向或非定向的改变用户文本特征,混淆或隐藏与人格相关的数据信息,隐藏数据中的人格信息,实现文本数据在语义相似条件下的人格变换,进而达到用户人格隐私保护的目的。
所述的基于cgan模型的用户人格隐私保护方法,如图1所示,具体步骤如下:
步骤一、通过社交网络收集某个用户a的原始文本数据,并辨别出该用户a的人格类别标签;
条件人格类别标签包括:定向人格标签或不定向人格标签;
原始文本数据包括:用户名和用户发布的文本内容。
步骤二、用doc2vec方法对原始文本数据进行预处理,获得服从x~pdata(x)分布的原始文本的向量表达,即原语义向量x;
doc2vec方法主要有两步:训练模型,在已知的训练数据中得到词向量,softmax的参数和,以及段落向量/句向量;推断过程,对于新的段落,得到其向量表达。
doc2vec方法是一种无监督算法,能从变长的文本(例如:句子、段落或文档)中学习得到的固定长度的特征表示。
步骤三、随机选择混淆人格标签c作为条件,结合随机的噪声向量z,一起输入cgan模型的语义生成器g(z|c;θg),生成新的语义向量x',且服从分布x'~pg(x');
cgan中分为的语义生成器g(z|c;θg)和语义判别器d(x;θd),语义生成器g(z|c;θg)和语义判别器d(x;θd)进行极大极小博弈;语义生成器的作用是用分布pg去拟合pdata。
语义生成器g(z|c;θg)的噪声向量z服从分布z~pz(z);θg是语义生成器的参数;c为人格类别标签的one-hot编码值,如果条件是定向人格,则c为特定人格的标签,如果不定向则c为任意标签值。
语义生成器的损失函数为:
步骤四、将生成的语义向量x'和原语义向量x一起输入语义判别器d(x;θd)进行真假判别;语义判别器的损失函数为:
步骤五、判断语义判别器d(x;θd)的输出是否为真,如果是,进入步骤六;否则,继续训练混淆人格标签c和噪声向量z,返回步骤三;
如果语义判别器辨别的语义是假,则通过梯度下降回传loss值,然后语义生成器根据回传的loss值,不断训练调整生成的语义向量,直到语义判别器不能正确辨别出真假语义。
步骤六、将输出为真的语义向量x'经过cnn的人格辨别器q(c′,c),得到生成语义向量x'的人格c'标签;
辨别器的损失函数计算如下:
通过训练判别器的损失函数,使得生成的人格c'标签与条件人格c一致;
步骤七、将输出的语义向量x'为真,且生成的人格c'标签与条件人格标签c一致的文本向量,逆向预处理,并将预处理结果加入或替换到原用户a的原始文本数据中,混淆用户a的人格文本信息。
经过生成器与辨别器对文本语义生成的控制,辨别器对人格的控制,最终生成语义相似人格不同的用户状态文本向量,通过逆向预处理,即decoder解码器即可输出定向或不定向的人格文本。
本发明发现cgan中相似性文本生成模型与定向或不定向条件模型之间的关联,建立文本数据与用户人格的关联库;通过文献调研和案例分析,结合cgan中生成相似文本的理论基础,建立基于cgan的用户人格转变模型;在自然语言领域中,对文本微小的扰动也是可以清楚感知的,通过对文本数据进行有效扰动,进而达到用户人格隐藏保护的目的。
下面用一个实施例来具体说明本发明的运行方法。
在本实施例中,可以采用acgan、infogan或proinfogan模型指导生成定向人格文本,也可以结合leakgan算法提高生成文本的语义相似性,从而定向改变用户文本的人格特性,进而达到用户人格隐藏保护的目的。
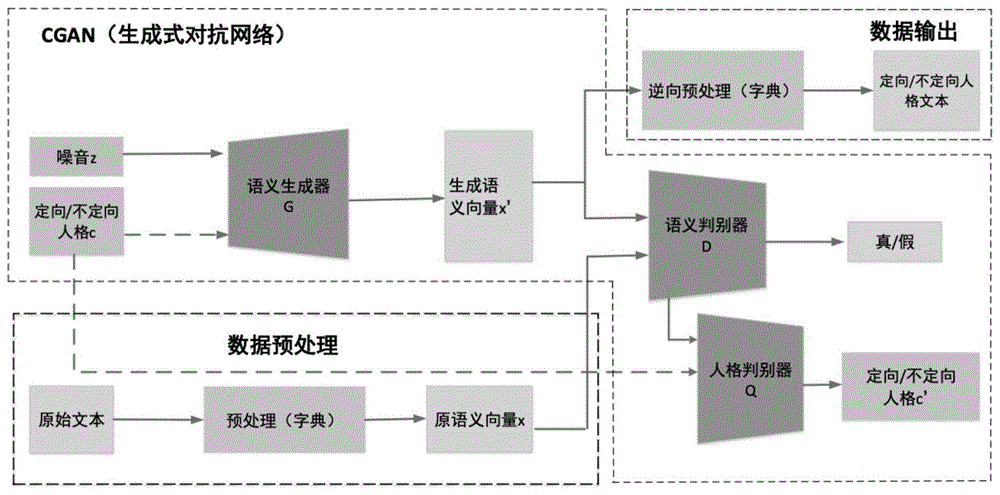
如图2所示,首先,搭建基于cgan模型的用户定向或混乱人格变换框架;
所述框架由语义生成器g、语义判别器d和人格判别器q三大部分组成;
其中语义生成器g输入是噪声z(随机向量值)和大五人格多标签混合编码值(onehot编码标签值);语义判别器d用来判别生成语义与原语义之间的差异;人格判别器q用来判别输入文本的人格类别,要求判别输入文本的人格类别是否与条件人格类别一致。
然后、针对某个用户a,收集该用户a通过社交网络发出的文本数据,并经过字典形式的预处理后生成原语义向量;
接着,使用语义生成器生成随机语义向量;具体为:
在定向人格变换方法中,将随机噪声向量z和大五人格的one-hot编码标签值输入语义生成器,由语义生成器产生合成数据即生成语义向量。
而在不定向人格变换方法中,将属于多个人格的混合编码(one-hot编码标签值)和噪声z输入语义生成器,由语义生成器产生合成数据即生成语义向量。
继续,将生成的随机语义向量和原语义向量经过语义判别器的不断训练,输出结果为真的最优语义向量,即与原始语义向量最相似;
将结果为真的随机语义向量经过人格辨别器,得到变换后对应的人格c'标签,且与条件人格的one-hot编码标签值保持一致;
在定向人格变换方法中,将定向条件人格的one-hot编码标签值和语义判别部分得到的判别结果作为人格判别器的输入;而在混乱人格变换方法中将属于多个人格的混合编码和语义判别部分得到的判别结果作为人格判别器的输入,由人格判别器生成最终变换后的人格或者模糊人格。
最后,将保持一致的文本向量以字典的形式经过逆向预处理得到人格文本,并加入或替换到原用户a的原始文本数据中,混淆用户a的人格文本信息。
将最终生成的语义相似、人格不同的用户文本,混淆或隐藏到原用户a的原始文本数据中,使得人格分类器无法正确辨别人格。进而达到用户人格隐私保护的目的。
本发明分为语义生成、语义判别以及人格判别三个部分,语义生成部分使用语义生成器生成语义向量,同时将原始文本通过预处理生成原语义向量;语义判别部分使用语义判别器判别生成语义与原语义之间的差异;人格判别部分利用人格判别器来判别输入文本的人格类别。
- 还没有人留言评论。精彩留言会获得点赞!