一种云计算环境下的目标探测与识别方法与流程
本发明涉及云计算技术领域,具体而言,涉及一种云计算环境下的目标探测与识别方法。
背景技术:
网络空间是继陆、海、空、天后的第五大主权空间,关系到经济、文化、科研、教育等各个方面。随着云计算技术的发展,网络空间中的资源种类、数量越来越丰富,网络资源关系越来越错综复杂,网络空间安全将面临众多挑战。所谓知己知彼、百战不殆,网络资产探测是对网络空间中的资源及其属性进行探测、融合、分析和绘制,从而做到“摸清底数”的目的。与传统网络相比,云计算的模式更加复杂,外部网络无法实现对云环境内部的直接访问,因此适用于传统网络的探测技术无法满足云计算环境的需求。
当前网络资产探测主要采取主动探测方式,主动探测是向网络发送经过特殊构造的探测数据包,通过接收探测包经由网络时各探测目标的响应来获得探测结果。由于现有主动探测方式需要构造特殊的探测数据包从而无法满足云环境需求。
技术实现要素:
本发明旨在提供一种云计算环境下的目标探测与识别方法,以解决现有主动探测方式需要构造特殊的探测数据包从而无法满足云环境需求的问题。
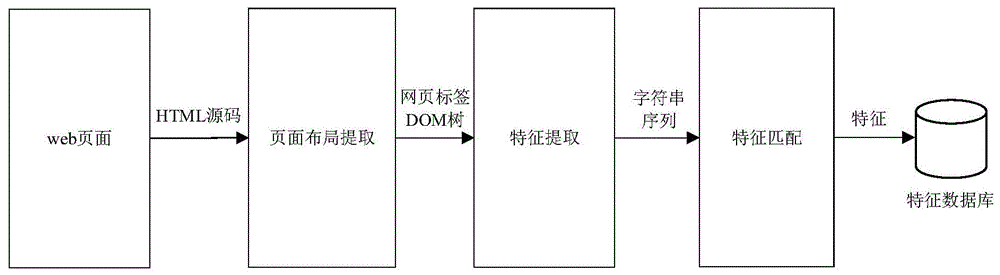
本发明提供的一种云计算环境下的目标探测与识别方法,包括如下步骤:
步骤10,提取网页页面布局并构造基于页面布局的页面标签dom树;
步骤20,基于所述页面标签dom树进行特征提取;
步骤30,对提取的特征进行特征匹配,以完成目标探测与识别。
进一步的,步骤10中所述提取网页页面布局并构造基于页面布局的页面标签dom树的方法包括如下子步骤:
步骤11,获取网页的html源码;
步骤12,通过从所述html源码中提取页面标签的方式,将html源码结构化为页面标签dom树。
进一步的,步骤20中所述基于所述页面标签dom树进行特征提取的方法为:对所述页面标签dom树进行处理,将页面标签dom树转换为一维的字符串序列。
进一步的,所述将页面标签dom树转换为一维的字符串序列的方法为:使用字典映射的方式通过自顶而下、从左到右的方式,将页面标签dom树转换为一维的字符串序列。
进一步的,步骤30中所述对提取的特征进行特征匹配的方法为:对步骤20得到的一维的字符串序列使用最长公共子序列算法进行特征匹配。
进一步的,所述对步骤20得到的一维的字符串序列使用最长公共子序列算法进行特征匹配的方法为:
假设有两个一维的字符串序列l1和字符串序列l2,其长度分别为|l1|和|l2|,字符串序列l1和字符串序列l2的最长公共子序列为lcs(l1,l2),则字符串序列l1和字符串序列l2的相似度计算公式为:
其中,s(l1,l2)表示字符串序列l1和字符串序列l2的相似度;
对步骤20得到的一维的字符串序列,使用所述相似度计算公式从特征数据库中进行特征匹配,以完成目标探测与识别。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、本发明无需构造探测数据包,仅通过解析网页html源码的方式即可实现目标探测与识别;
2、本发明减少了相似度计算复杂度,将页面标签dom树转换为一维字符串序列之间的相似度来进行目标探测与识别;
3、本发明适用于云计算环境,能够实现云计算环境下的目标探测与识别;
4、本发明也可用于钓鱼网站、诈骗网站监测等信息安全应用场景。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明实施例的云计算环境下的目标探测与识别方法的流程图。
图2为本发明实施例的网页html源码示例示意图。。
图3为本发明实施例的页面标签dom树结构示意图。
图4为本发明实施例的字典映射关系示意图。
图5为本发明实施例的页面标签dom树转换为一维字符串序列的示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
如图1所示,本实施例提出一种云计算环境下的目标探测与识别方法,包括如下步骤:
步骤10,提取网页页面布局并构造基于页面布局的页面标签dom树;
所述网页页面布局指的是网页html源码中页面标签所构成的层级结构。由此步骤10中所述提取网页页面布局并构造基于页面布局的页面标签dom树的方法包括如下子步骤:
步骤11,获取网页的html源码;所述html源码的一个示例如图2所示;
步骤12,通过从所述html源码中提取页面标签的方式,将html源码结构化为页面标签dom树。从图2中可以看出,页面标签的开始标识为<xxx>,如<html>、<head>、<title>、<body>、<p>、<b>、<a>;页面标签的结束标识为</xxx>,如</html>、</head>、</title>、</body>、</p>、</b>、</a>。因此可以基于此将网页的html源码结构化为标签序列树,即如图3所示的页面标签dom树。
步骤20,基于所述页面标签dom树进行特征提取;
由图3可见,由于所述页面标签dom树的树形结构较为复杂,所以直接计算树与树之间的相似度计算复杂度会比较高,为了减少相似度计算复杂度,本实施例中所述基于所述页面标签dom树进行特征提取的方法为:对所述页面标签dom树进行处理,将页面标签dom树转换为一维的字符串序列,从而而方便计算相似度。其中,所述将页面标签dom树转换为一维的字符串序列的方法为:使用字典映射的方式通过自顶而下、从左到右的方式,将页面标签dom树转换为一维的字符串序列。所述字典映射关系示意图如图4所示,由此可以将页面标签dom树转换为一维的字符串序列,转换过程如图5所示,可见,图3所示的页面标签dom树转换为了“abcdefg”字符串序列。
步骤30,对提取的特征进行特征匹配,以完成目标探测与识别。
本发明的设计原理即是相同的目标/设备在访问页面的页面布局上具有很高的相似性,体现在整体结构的相似性,而相同目标/设备不同版本在页面布局上具有微小的差异性,体现在局部结构的差异性。因此为了能够识别整体结构的相似性和局部结构的差异性,本实施例的步骤30中所述对提取的特征进行特征匹配的方法为:对步骤20得到的一维的字符串序列使用最长公共子序列算法进行特征匹配。由于子序列是不改变序列的顺序,而从序列中去掉任意的元素而获得新的序列,也就是说,子序列可以不必连续,因此使用最长公共子序列计算页面布局相似性既能体现出整体结构的相似性,也能挖掘出局部结构的差异性。具体地,所述对步骤20得到的一维的字符串序列使用最长公共子序列算法进行特征匹配的方法为:
假设有两个一维的字符串序列l1和字符串序列l2,其长度分别为|l1|和|l2|,字符串序列l1和字符串序列l2的最长公共子序列为lcs(l1,l2),则字符串序列l1和字符串序列l2的相似度计算公式为:
其中,s(l1,l2)表示字符串序列l1和字符串序列l2的相似度;
对步骤20得到的一维的字符串序列,使用所述相似度计算公式从特征数据库中进行特征匹配,以完成目标探测与识别。即在特征数据库中预先存储有各种网页经过页面布局构造的页面标签dom树转换而成的一维的字符串序列,将步骤20得到的一维的字符串序列与特征数据库中的这些字符串序列进行相似度计算,计算得到的相似度最高的字符串序列对应的网页即为识别结果,从而完成目标探测与识别。
通过上述可知,本发明相比现有需要构造特殊探测数据包的主动探测方式具有如下有益效果:
1、本发明无需构造探测数据包,仅通过解析网页html源码的方式即可实现目标探测与识别;
2、本发明减少了相似度计算复杂度,将页面标签dom树转换为一维字符串序列之间的相似度来进行目标探测与识别;
3、本发明适用于云计算环境,能够实现云计算环境下的目标探测与识别;
4、本发明也可用于钓鱼网站、诈骗网站监测等信息安全应用场景。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!