一种基于深度学习的黑暗条件下动作识别方法
本发明涉及计算机视觉的技术领域,尤其涉及到一种基于深度学习的黑暗条件下动作识别方法。
背景技术:
目前,基于深度学习的动作识别模型通常从原始视频帧中提取出光流信息进行辅助识别,成为双流模型。然而,传统的双流方法通常涉及光流的计算或估计,需要较高的计算能力和较大的存储资源。此外,光流只有在相邻帧之间像素值的变化非常显著时才有用,但这对于暗视频并不适用。由于目前尚未有针对黑暗条件下动作识别的专利,所以与本专利最为相近的现有方案是在正常光照条件下的动作识别,如中国专利cn110135386a所公开的一种基于深度学习的人体动作识别方法和系统。其中所采用的方法就是双流法,搭配开源模型resnet网络作为特征提取器,最后采用多层感知机进行分类。此模型在处理正常光照下的动作识别任务具有一定的准确度,然而在遇到黑暗情况时性能却急剧下降,在论文“aridanewdatasetforrecognizingactioninthedark”中的相关实验表明resnet50-i3d模型在公开数据集arid的准确率仅为73.39%。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种无需光流提取所需的较大的计算和储存资源、应用成本低、识别准确度高的基于深度学习的黑暗条件下动作识别方法。
为实现上述目的,本发明所提供的技术方案为:
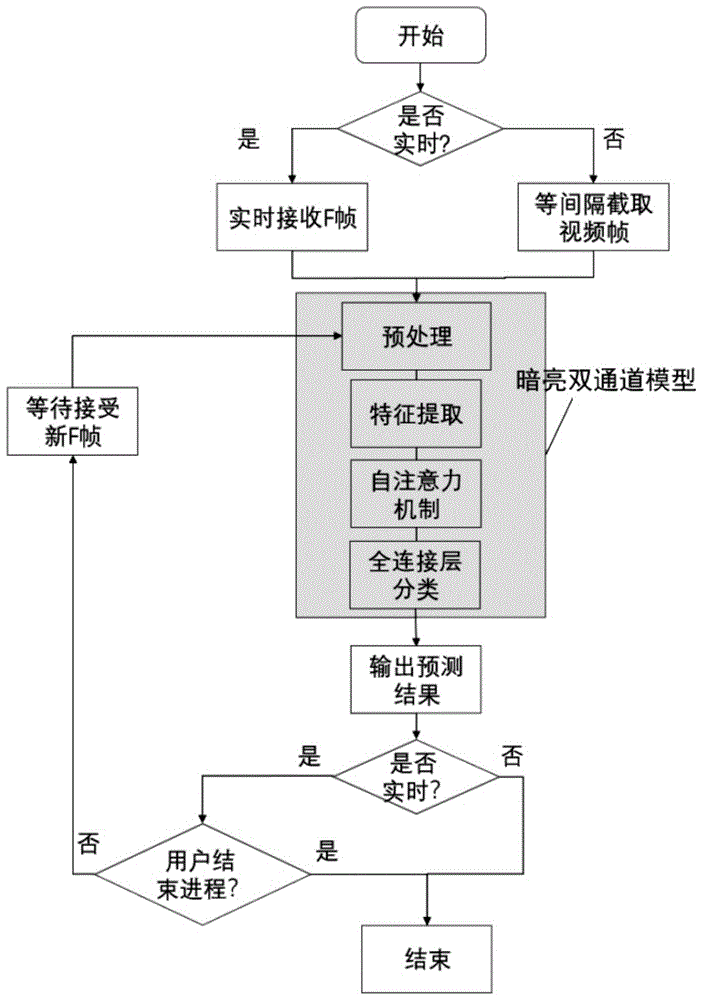
一种基于深度学习的黑暗条件下动作识别方法,包括以下步骤:
s1、选择实时黑暗条件识别或黑暗视频片段识别;
s2、从步骤s1已选择的待识别中取出f帧原始黑暗帧作为暗亮双通道模型的输入;实时黑暗条件识别时,保存每一帧信息并在保存到f帧时进入步骤s3,而选择黑暗视频片段识别则计算所有视频帧数,保证f帧的情况下等间隔提取,其间隔为2或4帧,视总帧数情况选择,如果视频片段少于f帧则进行循环取帧;
s3、对步骤s2取出的原始黑暗帧进行预处理,得到黑暗帧以及对应的增亮帧;
s4、将步骤s3得到的黑暗帧和增亮帧分别输入到共享特征提取器,得到两个通道的高级语义特征;
s5、将步骤s4得到的两个通道的高级语义特征并行输入到自注意力机制,得到输出分类向量ycls;
s6、将步骤s5得到的输出分类向量ycls输入到一个全连接层,得到类别概率,再通过softmax函数得到概率最大的类别,作为输出,并将对应的概率值输出;
s7、如果步骤s1选择的是黑暗视频片段识别,则识别结束;如果步骤s1选择的是实时黑暗条件识别,则判断现时的实时黑暗条件识别是否已结束,如果没有结束,则等待接受完新的f帧后返回步骤s3,否则识别结束。
进一步地,所述步骤s2中,f帧为64帧。
进一步对,所述暗亮双通道模型包括暗通道和亮通道,该两个通道均包括有一个输入和一个共享权值的特征提取器。
进一步地,所述步骤s3中,预处理的具体步骤如下:
s3-1、修改原始黑暗帧的尺寸,得到黑暗帧;
s3-2、进行伽马强度校正,得到增亮帧,校正公式如下:
上式中,p表示像素值,范围为[0,255],pmax表示最大的输入像素值,γ表示伽马校正的强度。
进一步地,所述步骤s3-1中,对原始黑暗帧包括左上、中间、右下在内的位置进行裁剪,使覆盖原始黑暗帧的百分之八十,将裁剪完的帧重新改变尺寸为112*112。
进一步地,所述步骤s4中,特征提取器为去掉最后全局池化层的r(2+1)d-34模型。
进一步地,
与现有技术相比,本方案原理及优点如下:
1.采用暗亮双通道模型来代替常规的双流模型,引入增亮帧代替常规的光流特征,解决了计算复杂度及存储的问题。
2.采用自注意力机制代替全局池化层及多层感知机,作为双通道的特征提取及融合,大大提高暗光条件下识别的准确度。
3.无需借助其他传感器如红外线或深度摄像头,只需普通的摄像头,分辨率高于224*224即可,大大降低应用成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的服务作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种基于深度学习的黑暗条件下动作识别方法的原理流程图;
图2为实施例中采用的去掉了最后全局池化层的r(2+1)d-34模型的示意图;
图3为本发明一种基于深度学习的黑暗条件下动作识别方法中采用到的自注意力机制的框架图。
具体实施方式
下面结合具体实施例对本发明作进一步说明:
如图1所示,一种基于深度学习的黑暗条件下动作识别方法,具体包括以下步骤:
s1、在电脑终端选择实时黑暗条件识别或者黑暗视频片段识别;选择实时黑暗条件识别时,需要保证电脑和用于检测的摄像头处于正常通讯状态。
s2、从步骤s1已选择的待识别中取出64帧原始黑暗帧作为暗亮双通道模型的输入;实时黑暗条件识别时,保存每一帧信息并在保存到64帧时进入步骤s3,而选择黑暗视频片段识别则计算所有视频帧数,保证64帧的情况下等间隔提取,其间隔为2或4帧,视总帧数情况选择,如果视频片段少于64帧则进行循环取帧。
本步骤取64帧,一般摄像头传输速率为每秒30帧,64帧大约为2秒,符合一般动作执行时长,且具有一定实时性,此外64是8的倍数,使计算机的计算资源得到充分利用。
采用的暗亮双通道模型包括暗通道和亮通道,该两个通道均包括有一个输入和一个共享权值的特征提取器。
s3、对步骤s2取出的原始黑暗帧进行预处理,得到黑暗帧以及对应的增亮帧,具体过程如下:
s3-1、对原始黑暗帧包括左上、中间、右下在内的位置进行裁剪,使覆盖原始黑暗帧的百分之八十,将裁剪完的帧重新改变尺寸为112*112(其尺寸大小既使计算机的计算压力减小又能保证一定的分辨率),得到黑暗帧;
s3-2、进行伽马强度校正,得到增亮帧,校正公式如下:
上式中,p表示像素值,范围为[0,255],pmax表示最大的输入像素值,设为255,γ表示伽马校正的强度。
s4、将步骤s3得到的黑暗帧和增亮帧分别输入到对应通道的共享特征提取器中,得到两个通道的高级语义特征;
本步骤中,特征提取器为去掉最后全局池化层的r(2+1)d-34模型,具体如图2所示。通过去掉了r(2+1)d-34模型最后的全局池化层,保存了完整的时空语义特征信息,为自注意力机制提高足够的信息。
s5、将步骤s4得到的两个通道的高级语义特征并行输入到自注意力机制,得到输出分类向量ycls;
采用的自注意力机制的框架如图3所示,其中f即为高级语义特征,x为加入一个可学习位置向量后的高级语义特征,其为自注意力机制提供了位置信息,有利于自注意力机制更好的学习到对识别有用的特征信息。多头注意力块和多层感知机是自注意力机制的基本模块,在模型中堆叠了12层。
s6、将步骤s5得到的输出分类向量ycls输入到一个全连接层,得到类别概率,再通过softmax函数得到概率最大的类别,作为输出。
s7、如果步骤s1选择的是黑暗视频片段识别,则识别结束;如果步骤s1选择的是实时黑暗条件识别,则判断现时的实时黑暗条件识别是否已结束,如果没有结束,则等待接受完新的f帧后返回步骤s3,否则识别结束。
本实施例采用的不是常规的双流模型,避免了光流提取所需的较大的计算和储存资源。本实施例所采用的是通过传统的图像增强算法伽马校正对黑暗视频进行增亮处理,同时也可用其他传统的图像增强算法;为保存原始数据的分布及避免计算的复杂度,不采用基于深度学习的图像增强算法。
本实施例采用自注意力机制代替全局池化层及多层感知机,作为双通道的特征提取及融合。在实验中表明此代替方法进一步提高了模型的准确度,如下表1在arid数据集上的准确度。
表1
本实施例所采用的模型具有先进性,比较了目前世界上优秀有竞争力的模型,如下表2所示,实验表明,使用搭配了r(2+1)d-34提取器的暗亮双通道模型在arid数据集上得到了最高的准确度。
表2
以上所述之实施例子只为本发明之较佳实施例,并非以此限制本发明的实施范围,故凡依本发明之形状、原理所作的变化,均应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!