本发明属于多目标跟踪检测领域,涉及一种多目标跟踪检测方法、系统、设备及存储介质。
背景技术:
安全设施佩戴多目标跟踪检测模型是利用基于深度学习的多目标跟踪检测算法跟踪检测视频或者监控摄像头中的施工人员是否合格佩戴安全设施。目前,将目标检测类算法生成的权重文件应用在多目标跟踪检测(mot)技术中已经相对成熟,并应用到各个领域中。
基于深度学习的多目标跟踪检测技术在性能上已经相当成熟,mot算法目前分为离线以及在线的跟踪,而不管是哪一种方式,此技术的关键之处是:运算匹配度以及距离的计算。基于学习特征将基于深度学习的mot分为三大类,又包含了六个小类。基于深度学习的多目标跟踪的三大类分为:深度表现特征应用、深度相似性度量学习以及深度高阶特征匹配。深度表现特征应用分图像识别特征和深度光流特征;深度相似性度量学习分为距离度量学习和二分类学习;深度高阶特征分为高阶表现特征和高阶运动特征。
在施工现场较复杂的施工环境中进行多目标跟踪时,存在遮挡、施工人员形态多样、检测速度低等情况。
技术实现要素:
本发明的目的在于克服上述现有技术的缺点,提供一种多目标跟踪检测方法、系统、设备及存储介质,不受遮挡和施工人员形态多样影响,提高了对施工现场人员的实时检测准确度以及速度。
为达到上述目的,本发明采用以下技术方案予以实现:
一种多目标跟踪检测方法,包括以下步骤;
步骤一,采集现场图片整理为voc数据集,作为训练集,并对训练集打标签;
步骤二,获取训练集的先验框的大小,将检测网络yolov4基础数据中的先验框大小替换为训练集的先验框的大小,根据voc数据集和先验框的大小更新检测网络yolov4基础数据中配置文件;
步骤三,搭建检测网络yolov4,将voc数据集以及更新后的配置文件传入检测网络yolov4中进行训练,得到视频跟踪所需的权重文件;
步骤四,搭建deepsort模型,将yolov4的权重文件输入deepsort模型中,且更改deepsort模型的配置文件config中的数据,得到多目标跟踪检测模型;
步骤五,将视频片段或实时监控画面传输至多目标跟踪检测模型中,进行多目标跟踪检测。
优选的,步骤一中,现场图片采集时,包含施工人员的多个角度,多个姿态,施工人员远近大小不一,多个小目标,包含佩戴与未佩戴安全帽和安全背心的施工人员。
优选的,步骤一中,使用labelimg工具对训练集打标签。
优选的,步骤二中,使用聚类算法对voc数据集进行处理,获取训练集的先验框的大小。
优选的,步骤三中,检测网络yolov4包括input输入层、backbone主干网络、neck和head检测头。
优选的,步骤四中,先将yolov4的权重文件转化为tensorflow模型,再将tensorflow模型输入deepsort模型中。
优选的,步骤四中,更改config配置文件中的数据包括类别存放文件中的内容和先验框anchors数组值。
一种多目标跟踪检测系统,包括:
voc数据集模块,用于采集现场图片整理为voc数据集,作为训练集,并对训练集打标签;
yolov4基础数据更新模块,用于获取训练集的先验框的大小,将检测网络yolov4基础数据中的先验框大小替换为训练集的先验框的大小,根据voc数据集和先验框的大小更新检测网络yolov4基础数据中配置文件;
检测网络yolov4搭建模块,用于搭建检测网络yolov4,将voc数据集以及更新后的配置文件传入检测网络yolov4中进行训练,得到视频跟踪所需的权重文件;
deepsort模型搭建模块,用于搭建deepsort模型,将yolov4的权重文件输入deepsort模型中,且更改deepsort模型的配置文件config中的数据,得到多目标跟踪检测模型;
多目标跟踪检测模块,用于将视频片段或实时监控画面传输至多目标跟踪检测模型中,进行多目标跟踪检测。
一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述任意一项所述多目标跟踪检测方法的步骤。
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上述任意一项所述多目标跟踪检测方法的步骤。
与现有技术相比,本发明具有以下有益效果:
本发明通过采用改进后的yolov4模型获取到的权重文件,此权重文件在对图片检测时平均精度可达97.57%,对小目标、遮挡物的检测精度高,将其转换格式后迁移至deepsort模型中进行多目标的实时跟踪检测。首先准备好安全设施的voc数据集,获取训练数据集的先验框的大小,更换配置文件数据,这样可以提高检测过程中对小目标物体的检测度。其次将训练得到的权重文件更改格式后迁移至deepsort模型中进行检测,这样提高了对施工现场人员的实时检测准确度以及速度。
附图说明
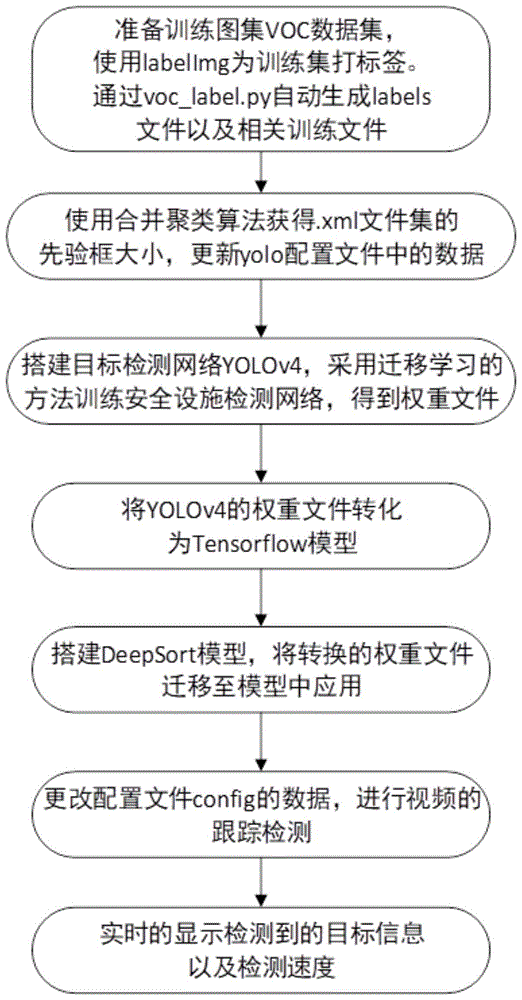
图1为本发明的流程图;
图2为本发明的安全设施检测算法图;
图3为本发明的实时跟踪检测内容信息显示图;
图4为本发明的视频检测标注图。
具体实施方式
下面结合附图对本发明做进一步详细描述:
如图1所示,为本发明所述的多目标跟踪检测方法,包括以下步骤:
步骤1:准备训练所需的数据集。在建筑施工现场采集原始图像数据,分训练集和视频集。
具体的:准备voc数据集。源图像数据采集时必须包含施工人员的多个角度,多个姿态,源图片中的施工人员远近大小不一,包含多个小目标,且环境不可单一,场地不可过于简单,且图片中包含佩戴与不佩戴安全帽和安全背心的施工人员;voc数据集结构包含:存放图片的jpegimages文件夹;存放标签.xml文件的annotations文件夹;存放main(含:test.txt、train.txt、trainval.txt、val.txt)文件的imagesets文件夹;存放转化标签数据后的labels文件夹;训练集路径信息文件train.txt。将采集到的图片集统一命名:00xxxx.jpg,统一存放在jpegimages文件夹中。使用labelimg工具对训练集打标签,标签类型分为,.xml标签文件统一存放在voc文件夹下的annotations文件中,标签文件名与源图片保持一致。
步骤2:使用聚类算法对voc数据集的annotations文件夹中的.xml文件进行处理,获取训练集的先验框的大小,并且将yolov4中的先验框大小替换为训练集的先验框的大小。更新配置文件cfg中的相关参数,包含:检测集和训练集的路径信息,检测类的类文件obj.names,yolo-obj.cfg中的输入图片大小(width=608(或416)、height=608(或416))、mini-batch=1或4、max_batches=4000(2000*classes)、steps=3200,3600(max_batches*0.8,max_batches*0.9)、classes=4、filters=27((classes+5)*3)、anchors,anchors为合并聚类生成的先验框数据。
步骤3:搭建安全设施检测网络yolov4,使用cmake和visualstudio2017进行编译。yolov4包含以下四部分:input输入层、backbone主干网络、neck以及head检测头。输入图像的尺寸是608*608,特征图变化的规律是:608->304->152->76->38->19,经过5次csp模块后得到19*19大小的特征图。将voc数据集以及更改后的配置文件传入网络中进行训练,得到视频跟踪所需的权重文件。
步骤4:将yolov4的权重文件转化为tensorflow模型。在将yolov4的权重文件迁移至deepsort模型应用时,由于deepsort使用的是tensorflow的模型,无法读取yolov4的权重文件,故先将其转化为tensorflow的模型。
具体的:将步骤3得到的权重文件存放在data文件夹下,并将其命名为yolov4.weights,通过项目根目录下的save_model.py文件在cmd中将文件格式转为适合tensorflow模型的格式。
步骤5:搭建deepsort模型。deepsort是在实际应用中使用较为广泛的一个算法,其特别之处在于:它的基础方法是fasterr-cnn,其次核心就是两个算法:卡尔曼滤波和匈牙利算法。卡尔曼滤波算法具备两步:预测以及更新,预测指的是目前监测到的这一帧内的物体预测框的位置等参数,更新指的是实时的更新监测画面状态的两个值:预测值以及观测值。并且此算法将画面中检测到的物体的状态分为八个满足正态分布的向量。匈牙利算法用来处理分配问题,主要处理的是相邻两帧所匹配到的目标物。将这两种算法结合使用,使得多目标监测时速度提高的同时保证了准确度。据图2,deepsort算法在sort添了两项:matchingcascade以及confirmed,即级联匹配和对新的轨迹的确认。步骤如下:(1)卡尔曼滤波器预测轨迹tracks;(2)使用(1)中的tracks以及目前帧的检测框实现级联匹配;(3)卡尔曼滤波更新。
具体方法是:在github官网下载原始的yolov4-deepsort项目,使用anaconda进行配置,创建名为yolo-deepsort的环境。将步骤4得到的转型后的yolov4的识别权重模型和视频数据放置在data对应的文件下。切换到cmd目录对应的路径下,进行requirements-gpu.txt库包的安装。
配置安全设施检测deepsort模型的环境,包括:cuda10.0版本、cudnn-10.0-windows10-x64-v7.6.5.32、tensorflow-gpu==2.3.0rc0、opencv-python==4.1.1.26、lxml、tqdm、absl-py、matplotlib、easydict、pillow。操作环境:win10操作系统,cpu:intel(r)core(tm)i7-9700f,gpu:rtx2080ti,显存:11g。
步骤6:更改配置文件config中的数据;最后进行视频的检测,向模型中输入准备好的视频文件。
更改config配置文件中的数据具体包含:类别存放文件(data/classes/voc.names)中的内容(helmet、no-helmets、safety_vest以及no_safety_vest)、先验框anchors数组值。
步骤7:使用安全设施识别模型对视频片段进行实时的检测并显示检测到的目标信息以及检测速度。
图3和图4为检测的结果展示,图3为实时检测时的检测帧数,检测到的物体的名称以及准确度;图4对应到的是检测的视频,对应有标记框以及目标物体的名称和准确度。由上述实验结果可以明显看出,将改进后的yolov4训练的权重文件迁移至deepsort模型中进行检测,保证实时性的同时,很大程度上提高了检测的精准度,并对有部分遮挡、远距离小目标检测的准确度较好。
本发明还公开了多目标跟踪检测系统,包括:
voc数据集模块,用于采集现场图片整理为voc数据集,作为训练集,并对训练集打标签。
yolov4基础数据更新模块,用于获取训练集的先验框的大小,将检测网络yolov4基础数据中的先验框大小替换为训练集的先验框的大小,根据voc数据集和先验框的大小更新检测网络yolov4基础数据中配置文件。
检测网络yolov4搭建模块,用于搭建检测网络yolov4,将voc数据集以及更新后的配置文件传入检测网络yolov4中进行训练,得到视频跟踪所需的权重文件。
deepsort模型搭建模块,用于搭建deepsort模型,将yolov4的权重文件输入deepsort模型中,且更改deepsort模型的配置文件config中的数据,得到多目标跟踪检测模型。
多目标跟踪检测模块,用于将视频片段或实时监控画面传输至多目标跟踪检测模型中,进行多目标跟踪检测。
本发明还公开了计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上述多目标跟踪检测方法的步骤。
本发明还公开了计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上述多目标跟踪检测方法的步骤。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。