一种基于位置不确定性估计的单目标跟踪方法
1.本发明属于计算机软件技术领域,涉及单目标跟踪技术,具体为一种基于位置不确定性估计的单目标跟踪方法。
背景技术:
2.目标跟踪是计算机视觉领域中的一项基本任务。一般来讲,目标跟踪问题可以简单概括为:给定一段视频序列并给出目标在第一帧的位置信息,算法需要在后续的视频序列中准确地跟踪到目标所在位置,从而得到目标运动的完整轨迹信息。
3.目标跟踪问题可以看作是分类任务和状态估计任务的组合,其中前者主要通过分类提供一个粗略的位置信息,后者在此基础上给出更精确的目标状态信息。为了使跟踪结果更为准确,状态估计任务的设计十分重要。当前目标跟踪算法若按照状态估计进行分类可分为以下三种。第一类主要包括早期的相关滤波方法和孪生网络方法如dcf,siamfc等,它们在状态估计阶段采用简单的多尺度测试方式,这种方法既不准确也较为耗时。第二类主要为siamrpn算法系列,它将目标检测领域常用的rpn模块引入siamfc中,让跟踪器可以回归位置、形状,同时也省掉了多尺度测试。尽管这种方式既提高算法的精度又保持了速度,但仍存在许多不足之处。第三类主要包括atom、dimp方法,这类方法在分类任务给出的粗略位置上随机生成若干个候选框,然后基于一个特别设计的iou预测网络并利用梯度下降迭代优化这些候选框,从而得到更为准确的预测框。这种方式虽然在准确性方面取得较大进展,但计算量较大且引入过多超参数需仔细调整。此外,近来目标检测领域出现一些无锚框的方法也被应用到目标跟踪领域,并取得不错的效果,但这些方法仍然不够精确,鲁棒性也有待提升。
技术实现要素:
4.本发明要解决的问题是:在目标跟踪过程中的候选框筛选阶段由于位置置信度缺失导致算法精准度较低的问题以及跟踪器无法适应目标可能出现的外形、尺度变化导致算法鲁棒性较低的问题。在先前基于孪生网络的跟踪方法(如siamrpn,siamfc++)中的候选框筛选阶段,一般都是选取类别置信度最高点所对应的预测框作为最终的预测框,但在目标检测领域中已有研究指出这种方式既不合理也会使得模型只能得到次优解。同时,这些方法大都缺乏快速有效的在线更新机制来适应跟踪过程中目标经常发生的外形与尺度变化。因此,本发明的设计目标就是在状态估计任务中引入位置不确定性估计模块来指导候选框的筛选,在分类任务中引入基于元学习的分类器进行在线更新,分别用于提高跟踪器的准确性与鲁棒性。
5.本发明的技术方案为:一种基于位置不确定性估计的单目标跟踪方法,首先离线训练好目标跟踪网络的网络参数,然后在跟踪过程中挑选部分先前已预测结果的视频帧,作为目标跟踪网络分类分支的在线训练样本,对基于元学习的分类器进行网络参数更新,提高跟踪的鲁棒性,同时在目标跟踪的候选框筛选阶段使用位置投票机制提高跟踪的准确
性。
6.进一步的,所述方法包括生成训练样本、主体网络离线训练、元分类器离线训练和在线跟踪:
7.1)生成训练样例,首先对离线训练数据集中每个视频的每一帧图像进行目标区域增强处理,然后裁剪出增强处理后的目标搜索区域并缩放至固定大小,从每个裁剪后的视频帧序列按照一定的间隔抽取两帧生成正样本对,从两个不同视频序列各自随机抽取一帧生成负样本对,每个样本对中的一个作为模板帧,另一个作为搜索帧,对于正样本对,根据搜索帧及其目标标注框来生成分类分支标签和回归分支标签,对于负样本对,根据搜索帧及其目标标注框只生成分类分支标签;
8.2)主体网络离线训练,包括网络主体部分训练和元分类器的训练;对于网络主体部分的训练,先将模板帧和搜索帧图片输入孪生网络,提取出各自的分类特征图和回归特征图,将模板帧的分类特征图作为分类分支的卷积核f
cls
,作用于搜索帧的分类特征图,经过该卷积操作之后生成类别得分置信图m
cls
,将模板帧的回归特征图作为回归分支的卷积核f
reg
,作用于搜索帧的回归特征图,经过卷积操作之后,生成中心点到目标边界距离回归图m
reg
和其所对应的距离置信度图m
uncert
,分别表示目标的中心点距离物体的四个边界的距离以及该预测的距离的置信度值;然后根据类别置信图m
cls
找到得分最高点,在m
reg
上找到该点以及周围临近点对应的偏置距离,再根据这些偏置距离对应的置信度进行投票得到最终的预测目标框;
9.训练时,对于分类分支使用retinanet中的focal loss作为损失函数,对于回归分支使用diou损失函数,不确定性估计模块使用负对数似然损失函数npll(negative power log-likelihood loss)损失函数,结合搜索帧得到的标签,使用sgd优化器,通过反向传播算法来更新整个网络参数,不断随机抽取正负样本重复上述过程直至达到迭代次数;
10.3)元分类器离线训练,在推理阶段元分类器的输入是搜索帧的分类特征图,输出是类别置信图m
′
cls
,此时将此类别置信图与步骤2)中的类别置信图m
cls
加权求和得到最终的类别置信图m
cls
←
α
·mcls
+(1-α)
·m′
cls
;在训练阶段,采用maml算法对元分类器进行训练,找到一组初始化参数,使得分类器在该状态下,仅仅需要使用少量样本经过数次梯度更新即可快速学习到目标的信息;
11.4)在线跟踪,首先裁剪出待跟踪视频的第一帧图像中的目标框搜索区域作为模板,然后将模板帧扩充为一个包含5帧图像的在线训练数据集,经过5此梯度下降更新网络参数,使得元分类器能够对当前跟踪目标进行分类任务,在跟踪过程中,从已经跟踪完的帧序列中每10帧挑选出一个分类得分最高的帧和已经跟踪得到的目标框作为标签添加到在线训练数据集中,用于更新元分类器。
12.本发明的目标是构建一个精准的目标跟踪器使其能够适应目标的形变,辨别背景干扰物等,进而提升跟踪器的鲁棒性。如先前的分析指出,siamrpn系列在候选框筛选阶段主要依据其所对应的类别置信度,这既不合理也会导致模型得到次优解。atom算法等虽然引入iou预测网络并使用网络预测的iou值来代替类别置信度值,但该方法计算量大且精确度提升有限。本发明采用全卷积孪生网络结构,发明一种基于位置不确定性估计的单目标追踪方法,命名为fcst(fully convolutional siamese tracker)。本发明设计的位置不确定性估计模块能够预测网络输出位置坐标的置信度信息,在后续阶段使用位置投票机制生
成最终的预测框,从而能够给出精确的回归边界框。此外,本发明提出了一种基于元学习的在线更新策略,使得跟踪器能够适应目标外形与尺度变化,从而提高追踪器的鲁棒性。
13.本发明与现有技术相比有如下优点。
14.本发明提出了一种基于位置不确定性估计的单目标跟踪方法(fully convolutional siamese tracker,fcst)。这种方法采用全卷积孪生网络结构,在目标状态估计任务中引入位置不确定性估计模块,通过位置投票方法来生成最终的预测框,在保证物体跟踪效率的同时提升了跟踪的准确度。
15.本发明在分类任务中引入了一种基于元学习的在线更新分类器,能够在跟踪过程中仅需少量训练样本经过数次迭代,即可适应目标的外形尺度变化。相比较于现有的基于孪生网络的跟踪方法,本发明提出的fcst跟踪方法能够能对跟踪过程中的物体变形有更好的适应能力,有效地提升目标分类的鲁棒性。
16.本发明单物体跟踪任务上取得了很好的结果,提升了目标回归的精度与目标分类的鲁棒性。相较于现有方法,本发明提出的treg跟踪方法在多个视觉跟踪测试基准数据集中都体现了好的跟踪成功率和定位准确度。
附图说明
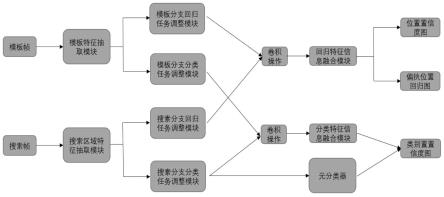
17.图1是本发明所使用的系统框架图。
18.图2是元分类器结构示意图。
19.图3是本发明提出的多元信息融合模块示意图。
20.图4是本发明提出的特征提取融合示意图。
具体实施方式
21.本发明提出了一种基于目标变换回归网络的精确单目标跟踪方法。经过在trackingnet-train、lasot-train、coco-train、got-10k-train四个训练数据集上进行离线训练,在otb100、vot2018、lasot-test、got10k-test几个测试集上测试达到了较高的准确率和追踪成功率,具体使用python3.6编程语言,pytorch1.4深度学习框架实施。
22.图1是本发明所使用的系统框架图,通过全卷积孪生网络,生成目标分类和目标回归模板,来指导分类和回归任务以及在线更新分类和回归模板的策略,来实现目标追踪任务。整个方法包括生成训练样例阶段、主体网络训练阶段、元分类器离线训练阶段以及在线跟踪阶段,具体实施步骤如下:
23.1)数据的准备阶段,即生成训练样例阶段。在离线训练过程中生成训练样例,首先对离线训练数据集中每个视频的每一帧图像进行目标区域增强处理,然后裁剪出增强处理后的目标搜索区域并缩放至固定大小,然后从每个裁剪后的视频帧序列按照一定的间隔抽取两帧生成正样本对,从两个不同视频序列各自随机抽取一帧生成负样本对。每个样本对中的一个作为模板帧,另一个作为搜索帧。对于正样本对,根据搜索帧及其目标标注框来生成分类分支标签和回归分支标签。对于负样本对,根据搜索帧及其目标标注框只生成分类分支标签。若为正样本对,则当类别标签图上的某坐标点所对应原图上的位置若落入标注框中心区域则标记为1,若落入标注框区域外则标记为0,图上其他位置标记为-1;若为负样本对,则当类别标签图上的某个坐标点所对应的原图上的位置若落入标注框中心区域则标
记为0,其他区域标注为-1。对于
24.2)网络主体部分训练阶段,具体如下。
25.2.1)提取模板分支特征:首先使用改动后的googlenet作为孪生网络的backbone进行提取特征,对模板帧zi∈rb×3×
127
×
127
提取特征得到f
temp
∈rb×
256
×5×5,其中上标temp的含义模板帧提取的特征,b代表batch size的大小。其中googlenet使用的是在imagenet上预训练后的参数。
26.2.2)模板分支特征调整:为了使得到的特征能够适应不同的任务(分类任务、回归任务),需要对特征进行调整。将步骤2.1)得到的模板分支特征输入到一个包含单个卷积层的网络,该卷积层采用3*3的卷积核,步长为1,输入通道数为256,输出通道数为256。调整后的模板分支特征大小由f
temp
∈rb×
256
×5×5变为同样,为了得到适应于回归任务的特征,将模板分支特征输入到另一个单层卷积网络,卷积核的大小、步长、通道数同上。调整后模板分支特征大小由f
temp
∈rb×
256
×5×5变为下标cls表示该特征是模板分支用来进行分类任务的特征,下标reg表示该特征是模板分支用来进行回归任务的特征。
27.2.3)搜索帧特征提取:将搜索帧输入孪生网络另一分支,该分支的网络同是调整后的googlenet,网络参数也是使用在imagenet上预训练后的参数。与模板帧大小不同,搜索帧大小为xi∈rb×3×
255
×
255
,经过主干网络提取特征后,得到的搜索分支的特征为f
search
∈rb×
256
×
27
×
27
,其中256表示通道数。
28.2.4)搜索帧特征调整:同样为了使搜索分支特征能够适应不同任务,需要对其进行调整。将步骤2.3)得到的搜索分支特征输入到一个包含单个卷积层的网络,该卷积层采用3*3的卷积核,步长为1,输入通道数为256,输出通道数为256。调整后的搜索分支特征大小由f
search
∈rb×
256
×
27
×
27
变为同样,为了得到适应于回归任务的特征,将搜索分支特征输入到另一个单层卷积网络,卷积核的大小、步长、通道数同上。调整后搜索分支特征大小由f
search
∈rb×
256
×
27
×
27
变为下标cls表示该特征是搜索分支用来进行分类任务的特征,下标reg表示该特征是搜索分支用来进行回归任务的特征。
29.2.5)得到分类置信图:将模板分支的分类特征当作卷积核与搜索分支的分类特征进行卷积操作(即互相关操作)之后,得到大小为f
cls
∈rb×
256
×
23
×
23
的特征,然后经过三层卷积网络,输出最终的类别置信度图m
cls
∈rb×1×
19
×
19
。这三层卷积网络前两层的卷积核大小为3*3,步长为1,输入通道为256,输出通道为256。最后一层卷积核大小为1*1,步长为1,输入通道数为256,输出通道数为1,主要作用是融合不同维度信息。
30.2.6)得到距离回归图m
reg
和对应的位置不确定性图m
uncert
:将模板分支的回归特征作为卷积核,与搜索分支的回归特征进行卷积操作,得到大小为f
reg
∈rb×
256
×
23
×
23
的特征。然后将此特征输入到一个两层卷积网络,卷积核大小为3*3,步长为1,输入通道与输出通道都是256,此时输出的特征大小为f
reg
∈rb×
256
×
19
×
19
。最后将其分别输入两个并行的单层卷积层,这两个卷积层的卷积核大小为1*1,步长为1,输入通道数256,输出通道数为4,此时输出的特征分别为m
reg
∈rb×4×
19
×
19
和m
uncert
∈rb×4×
19
×
19
,分别表示目标的中心点距离物体的四个边界的距离以及该预测的距离的置信度值。
31.2.7)对于分类分支的离线训练使用retinanet提出的focal loss作为损失函数,回归(状态预测)分支中的偏差距离预测模块使用diou loss作为损失函数,回归分支中的位置置信度估计模块使用负对数似然损失函数npll(negative power log-likelihood loss)损失函数,实验中使用sgd优化器,设置batchsize为16,总的训练轮数为20,学习率初始值为0.0001,15轮之后除以10,衰减率设置为0.1,在8块rtx 2080ti上训练,通过反向传播算法来更新整个网络参数。不断重复步骤2.1)至步骤2.7),直至达到迭代次数。
32.3)元分类器离线训练阶段,需要在主体网络训练之后进行,其中元分类器是一个包含若干个卷积层的网络,与主体网络共享模板分支分类特征与搜索分支分类特征进行卷积操作之后的特征f
cls
∈rb×
256
×
23
×
23
作为元分类器的输入,输出仍是一张类别置信度图,其大小与2.5)步骤中输出的类别置信度图一致,记为m
′
cls
∈rb×1×
19
×
19
。本发明采用maml算法(model-agnostic meta learning)对其进行训练,主要包括内层优化和外层优化。具体如下,
33.给定一个用于训练视频序列vi,先从中收集训练样本集合在元学习领域,它也被称为support set,将分类器定义为f(x;θ0),其中x为输入的图片,θ0为网络初始化参数,在训练集上使用k步随机梯度下降算法来更新网络:
[0034][0035]
其中α是权重因子,实验中α=0.6,l是损失函数,f(x,y)是训练集合中的样本对。在maml算法中,上式被称为内层优化(inner-level optimization)。
[0036]
为了评估分类器的泛化性能,需要再从同一个视频序列vi中收集样本集合在元学习领域,它也被称为target set,使用经过内层优化的模型,计算其在上的损失:
[0037][0038]
其中表示support set和target set的并集。整个网络的训练目标是找到可以尽量好的满足所有视频序列的网络初始化参数θ0,它可以表示为,
[0039][0040]
此公式被称为外层优化(outer-level optimization),使用adam算法进行优化更新。
[0041]
首先按步骤2)所述训练好主体网络,然后在其基础之上离线训练元分类器。在离线训练过程中,每批次随机挑选8个视频序列(即batch size=8),每个轮次迭代600次,总共训练100轮次。训练过程中内层优化使用随机梯度下降算法进行5次梯度更新,学习率为
0.01,外层使用adam算法进行优化,学习率为0.001。
[0042]
4)在线跟踪阶段,需要对元分类器进行在线更新,具体来讲,给定一个视频序列以及第一帧的标注,算法首先将第一帧图片及其标注作为训练正样本,微调元分类器,使其能够在后续过程中对当前目标进行分类任务。由于第一帧只有一个样本,为了使元分类器泛化能力更强,使用数据增强的方式扩充训练样本集,构成support set。
[0043]
在后续跟踪过程中,本发明不断收集先前的跟踪结果,用以后续过程中的更新操作,在后续的候选框筛选阶段使用位置投票机制提高跟踪的准确性,从已经跟踪完的帧序列中每10帧挑选出一个分类得分最高的帧和已经跟踪得到的目标框作为标签添加到在线训练数据集中,用于更新元分类器。由于跟踪的结果不像第一帧标注数据那样可靠,可能存在不准确甚至错误的结果,因此只有当预测框的位置置信度大于一定的阈值θ
loc
并且类别置信度也大于一定的阈值θ
cls
,才会被选入support set。实验实施中至多缓存15个样本在support set中,同时考虑到在线更新操作较耗时,每隔10帧进行更新一次。每次更新时为节省时间只进行一次梯度下降。
[0044]
跟踪初始时,首先裁剪出待跟踪视频的第一帧图像中的目标框区域并缩放至127*127的大小作为模板分支的输入,对于后续帧序列,根据先前一帧的预测结果计算出当前帧的搜索范围大小,然后裁剪出相应大小的搜索区域并缩放至255*255,输入孪生网络的另一分支。当主体网络输出类别置信度图m
cls
、偏置距离回归图m
reg
、位置不确定性图m
un rt
以及元分类器输出类别置信度图m
′
cls
后,先对两个类别置信度图进行加权融合操作得出最终的类别响应图:
[0045]mcls
←
α
·mcls
+(1-α)
·m′
cls
[0046]
α是权重因子,实验中α=0.6。
[0047]
在类别响应图上找到得分值最高点,选取该位置及其周围临近的n个位置所对应的n+1预测框作为候选集,集合中每个元素包含上下左右位置偏置及其对应的置信度,其中li表示预测框i的左侧边界的值,为其对应的不确定性;ti表示预测框i的上侧边界的值,为其对应的不确定性;ri表示预测框i的右侧边界的值,为其对应的不确定性,bi表示预测框i的下侧边界的值,为其对应的不确定性,i为预测的目标框的序号。然后依据四个边界将其划分为四个子集合:
[0048][0049][0050][0051][0052]
再依次从每个子集中分别挑选置信度最高的k个项组成新的子集:
[0053][0054]
[0055][0056][0057]
将最终的预测框记为b
pred
={l
pred
,t
pred
,r
pred
,b
pred
},其中l
pred
为最终预测框的左侧边界值,具体计算公式如下:
[0058][0059]
在测试数据集上,跟踪的效率为30fps,在跟踪精度上,在otb100数据集上auc达到了70.1%,pre达到了91.5%。在vot2018数据集上,eao达到了0.474,robustness达到了0.164,accuracy达到了0.609;在lasot数据集上,suc达到了56.2%;在got10数据集上sr
.5
为0.723,sr
.75
为0.530,ar为0.614。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1