一种基于强化学习的增强现实多智能体协作对抗实现方法
1.本发明属于信息技术领域,具体涉及一种基于强化学习的增强现实多智能体协作对抗实现方法。
背景技术:
2.近年来,随着人工智能(artificial intelligence,以下简称“ai”)相关技术的持续突破和相关算法的不断成熟,ai智能体已经逐渐深入各个领域,并且在智能机器人、无人车、虚拟现实与增强现实等领域表现出较好的应用效果。在增强现实仿真对抗环境中,良好的虚实交互体验便成了当前需要优化的重要一环,虚拟目标的智能性则是提升虚实交互体验的关键之一。而在当前的增强现实仿真对抗环境中,实现虚拟多智能体与真实用户的协作对抗交互通常是通过预先设定虚拟目标的行为规则来执行,例如常采用的状态机、行为树等行为设计,然而由于缺乏智能决策,对于预先设定所实现的合作行为极容易出现策略单一,对抗效果不佳等问题,无法起到增强现实仿真环境应有的对抗效果。
3.为了提升增强现实仿真对抗环境中多智能体的智能性,可以采用深度强化学习算法对该环境中的多智能体进行训练,使其自主学会智能协作策略,在增强现实仿真环境中完成同用户的虚实交互,实现智能协作对抗行为。深度强化学习是当前人工智能领域的新兴技术之一,它以强化学习为基石,利用深度学习特征提取能力优势来弥补强化学习的诸多缺陷,形成互补,实现从感知到决策的端到端自主学习策略框架。相较于传统方法所实现的多智能体行为,拥有更优良的虚实对抗交互体验,可以达到更好的协作效果。
4.同时为了解决深度强化学习在学习过程中需要不断试错,导致其在真实环境中训练的成本过高的问题,通常先在搭建的虚拟仿真环境中完成训练后再进行真实环境的迁移。unity3d作为当前广泛使用的专业游戏引擎,可用于构建增强现实仿真环境。利用强化学习算法对虚拟多智能体进行训练,得到多智能体协作策略模型后迁移到增强现实环境中,提高在增强现实仿真对抗环境中多智能体的智能性,提升交互体验。该方法可用于军事仿真训练、增强现实游戏等的智能对抗仿真环境构建。
技术实现要素:
5.有鉴于此,本发明的目的是提供一种基于强化学习的增强现实多智能体协作对抗实现方法,可以解决增强现实仿真对抗环境中多智能体行为策略单一,协作智能性不佳,所造成的虚实目标交互体验差的问题。
6.一种基于强化学习的增强现实多智能体协作对抗实现方法,包括如下步骤:
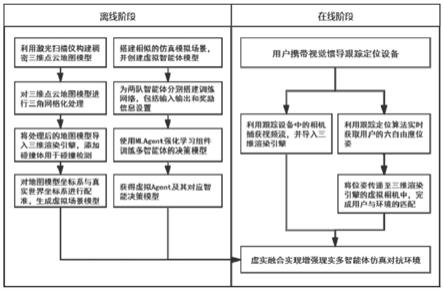
7.步骤1:在离线阶段,对真实场景进行建模,构建稠密的三维点云地图并三角网格化;
8.步骤2:仿照真实场景搭建虚拟仿真对抗环境对多智能体进行训练,包括如下步骤:
9.(1)仿照真实场景,再搭建虚拟仿真对抗场景,将多个智能体设置在该虚拟仿真对
抗场景中;多个智能体分为互为对抗的两队,对抗双方均可在场景中自由移动,双方的任务目标均为团队协作配合歼灭对方装备,以此形成仿真对抗环境;
10.(2)为对抗双方分别设置一个策略模型,同队的智能体之间共享一套策略模型参数;
11.(3)利用三维渲染引擎unity3d自带组件mlagent完成对智能体的状态输入、奖励设置和动作输出;
12.(4)智能体根据不断输入的状态输入、奖励信息及动作输出对策略模型进行循环往复训练;
13.步骤3:训练完成后,在线阶段导入训练完成的智能体策略模型,将步骤1构建好的真实场景模型导入三维渲染引擎,并在其中添加刚体组件;然后将装备渲染在真实场景中的相应位置,实现后续增强现实仿真对抗环境的渲染绘制;
14.步骤4:实时获取用户的六自由度全局位姿,并传递给三维渲染引擎中的虚拟相机;
15.步骤5:导入真实摄像机捕获的画面,渲染在真实场景中;
16.步骤6:将步骤1中构建的真实场景模型隐藏,保留刚体组件,用于碰撞检测,最终形成用户在真实场景中与智能体进行交互的增强现实仿真对抗环境,与智能体之间形成协作完成对抗任务。
17.进一步的,所述步骤2中,训练过程结合课程训练模式,将场景复杂度分为简单、中等、困难三个程度,在训练是按顺序采用该三个复杂度对策略模型进行训练。
18.较佳的,所述步骤3中,利用世界坐标系、相机坐标系、图像坐标系和像素坐标系之间的如下转换公式,将装备渲染在真实场景中的相应位置:
[0019][0020]
上式中,(ε,η,δ)是智能体在世界坐标系中的三维位置信息;t
cw
表示从世界坐标系到相机坐标系的转换;相机模型决定相机坐标系与图像坐标系的转换关系;对于透视投影模型,θ表示相机的纵向视角,n是从相机中心到近裁剪平面的距离,f是从相机中心到远裁剪平面的距离,aspect是投影图像的长宽比,k是相机的内部参数,z
c
和γ与深度有关。
[0021]
较佳的,采用实时跟踪定位算法实时获取用户的六自由度全局位姿。
[0022]
较佳的,智能体中采用python软件接收状态输入和奖励信息并训练模型。
[0023]
较佳的,所述步骤1中,利用三维激光扫描仪对真实场景进行建模。
[0024]
较佳的,状态输入包括:以向量形式表征的周围智能体的属性和方位以及自身相关状态信息;友方智能体的图像信息和位置信息。
[0025]
本发明具有如下有益效果:
[0026]
本发明方法提供一种增强现实环境下多智能体对抗仿真环境实现方法,利用深度
强化学习网络结合课程学习预测各个智能体行为并作出决策,再将训练完成的强化学习智能体模型迁移至增强现实环境中,能够解决增强现实对抗仿真环境中虚拟多智能体协作策略单一造成的人机交互体验不佳的问题,具有使真实用户和虚拟多智能体之间协作对抗策略灵活多变的效果。
附图说明
[0027]
图1为本发明的三维激光扫描并三角网格化后得到的真实地图模型;
[0028]
图2为搭建的虚拟仿真环境;
[0029]
图3为本发明方法流程图;
[0030]
图4为训练流程图;
[0031]
图5为训练过程示意图;
[0032]
图6为训练完成效果图;
[0033]
图7为真实场景效果图。
具体实施方式
[0034]
下面结合附图并举实施例,对本发明进行详细描述。
[0035]
一种基于强化学习的增强现实多智能体协作对抗实现方法,其基本实施过程如下:
[0036]
步骤1:在离线阶段,利用三维激光扫描仪对真实场景进行建模,构建稠密的三维点云地图并三角网格化。
[0037]
步骤2:将构建好的模型导入三维渲染引擎,添加刚体组件以实现碰撞检测,用于后续强化学习训练。
[0038]
步骤3:由于真实场景模型过大,为提升训练速度,仿照真实场景搭建虚拟仿真对抗环境对多智能体进行训练,其具体过程如下:
[0039]
(1)仿照真实场景,利用模型预制体搭建虚拟仿真对抗场景,将多智能体分为红蓝两队,红蓝双方均可在场景中自由移动,双方的任务目标均为团队协作配合歼灭对方坦克,以此形成仿真对抗环境。
[0040]
(2)设置两个策略模型,两队分别使用各自的策略模型,但同队之间共享一个模型参数。训练过程为对观测状态输入进行收集,结合针对不同任务的奖励信息,通过深度强化学习网络学习获得奖励更高、更有效的动作输出。场景管理包括控制回合开始,回合进行与回合终止。
[0041]
(3)强化学习模块利用三维渲染引擎unity3d自带组件mlagent(强化学习插件)完成状态输入、奖励设置和动作输出。agent对环境的状态感知输入分为向量和图像两部分输入。向量状态输入包括射线检测获取周围目标的属性和方位、自身相关状态信息,周围目标的属性通过设置不同标签进行区分。图像输入为利用遮罩处理后的场景中只存在友方智能体的图像信息,以确保状态输入既包括自身所观测的状态,同时包括友方位置信息,实现多智能体之间的状态输入相通。
[0042]
(4)在场景中每一个agent对环境感知得到各自的状态输入,python端对接收到的agent状态结合设置的奖励信息训练模型,将动作值作为输出传递回agent并在unity3d场
景中完成行为,再次收集新的状态输入,循环往复,不断提升决策后获得的奖励值。
[0043]
(5)训练过程结合课程训练模式,将场景复杂度分为简单、中等、困难三个程度,训练前期采用简单场景对智能体的行为进行初步训练,当决策奖励值收敛后提升场景复杂度,使得智能体在原有策略模型的基础上进行进一步学习,最终得到强化学习模型。
[0044]
步骤4:训练完成后,在线阶段导入训练完成的agent模型,利用世界坐标系、相机坐标系、图像坐标系和像素坐标系之间的转换公式(1),将虚拟智能坦克渲染在真实场景中的相应位置,实现后续增强现实仿真对抗环境的渲染绘制。
[0045][0046]
公式(1)中,(ε,η,δ)是agent在世界坐标系中的三维位置信息。t
cw
表示从世界坐标系到相机坐标系的转换,由跟踪定位算法实时进行更新。相机模型决定相机坐标系与图像坐标系的转换关系。对于透视投影模型,θ表示相机的纵向视角,n是从相机中心到近裁剪平面的距离,f是从相机中心到远裁剪平面的距离,aspect=w/h是投影图像的长宽比,k是相机的内部参数,由相机自身决定。zc和γ与深度有关。1/zc是尺度因子。
[0047]
步骤5:采用实时跟踪定位算法实时获取用户的六自由度全局位姿,并传递给三维渲染引擎中的虚拟相机。
[0048]
步骤6:导入真实摄像机捕获的画面,渲染在场景中。
[0049]
步骤7:将步骤1中构建的离线三维地图模型隐藏,仅保留碰撞检测,最终形成用户在真实场景中与虚拟智能体进行交互的增强现实仿真对抗环境。虚拟多智能体之间采用强化学习模型实现智能决策,用户可以同时在真实场景中可以进行移动、攻击操作,与智能体之间形成协作完成对抗任务。
[0050]
实施例:
[0051]
一种基于强化学习的增强现实多智能体协作对抗实现方法,其具体步骤包括:
[0052]
步骤1:离线构建地图。采用faro激光扫描仪进行离线构建真实场景的三维稠密点云地图模型。在扫描实验场景时采取多站点扫描,将每个站点的地图三维数据通过坐标系变换转换到首次扫描站点为原点的坐标系。扫描结束后,利用faro激光扫描仪扫描结果所提供的3d点及颜色信息的rgbd全景图,通过贪婪投影三角剖分算法将该全景图转换成三角网格化地图,最终离线地图模型如图1所示。
[0053]
步骤2:将构建好的真实场景地图模型导入到unity3d三维渲染引擎中,利用unity3d中基于包围盒的碰撞检测方式,为真实场景中存在的地形、建筑物、物体等添加刚体,以此来实现虚实对象之间的碰撞交互。
[0054]
步骤3:由于真实场景模型过大,为提升训练速度,仿照真实场景搭建虚拟仿真对抗环境对多智能体进行训练,训练具体步骤如下:
[0055]
(1)搭建虚拟仿真对抗环境中,包含地面、建筑物、障碍物、树木,以及红蓝双方智
能体坦克,如图2所示。每方智能体数量为3,红蓝双方均可在场景中自由移动,双方的任务目标均为团队协作配合歼灭对方坦克,以此形成仿真对抗环境。回合开始时,红蓝双方所有坦克的初始生命值均设置为100。当自身受到攻击或碰撞时,会造成生命值减少。其中,炮弹造成的伤害值按照真实情况进行物理仿真,会受炮弹落点与目标的距离影响,造成的伤害值不等。当坦克的生命值小于或等于0时,坦克被毁死亡,场景中坦克消失。当场景中一方坦克全部被毁消亡时,另一方即为对抗获胜方。随后回合立即重启,场景及坦克状态全部重置。
[0056]
(2)强化学习部分采用unity3d渲染引擎中的mlagent组件搭建。将红蓝两队分为两个模型同时在场景中进行训练,同一队共享一个模型参数,以此促进红蓝双方产生更多的协作和对抗策略。
[0057]
(3)为获得更有效的观测信息,状态输入信息分为向量和图像两个部分。其中,向量输入一方面通过坦克从自身发出的射线检测来实现。在坦克以下角度{0,30,50,70,80,85,90,95,100,110,130,150,180,220,270,320}设置长度为100的射线,射线可通过对射线碰撞物体的标签进行对物体感知,感知信息包括敌方坦克,友方坦克,障碍物和地面。若当前角度检测到感知物体,则将状态输入对应的向量空间位置的值置为1,并输出相对于射线长度100的距离。向量输入的另一方面是坦克自身状态信息,包括自身生命值、自身速度。而图像输入信息作为重要的友方信息共享方式,通过对摄像机输出图像添加遮罩,仅保留显示友方坦克图层,以此可以有效显示当前友方坦克位置和是否存活的状态信息,然后将该图像作为状态输入同时传入训练网络。
[0058]
(4)动作空间的输出包括移动、旋转和是否攻击,具体设计如下表所示:
[0059]
动作输出移动旋转是否攻击
‑
1向后左转 0静止方向不变不攻击1向前右转攻击
[0060]
(5)训练算法采用ppo(近端策略优化)算法。它将坦克观测传递的状态信息作为输入,结合奖励设置,自主学习使得目标能找到最优策略以完成任务并获得更高的奖励值。算法网络将动作输出传递回坦克,坦克执行策略后收集新的状态信息,循环往复,最终得到策略模型。其中,奖励设置如下表所示:
[0061]
智能体坦克奖励打中敌方+5打中己方
‑
1.5打空
‑
0.01时间线每步
‑
0.00005死亡
‑
0.5向前移动+0.0005碰撞障碍物
‑
0.05
[0062]
训练参数设置如下表所示:
[0063][0064][0065]
(6)训练过程采用课程训练模式,将场景复杂度分为简单、中等、困难三个程度。其中,场景具体设置如下表:
[0066]
场景复杂度障碍物数量场景大小简单22*2中等1010*10困难5050*50
[0067]
总回合数的前1/3回合采用简单场景对智能体的行为进行初步训练,当决策奖励值收敛后提升场景复杂度,将三种场景复杂度随机出现,使得智能体在原有策略模型的基础上进行进一步学习,当决策奖励值再一次达到收敛后,训练场景变为仅使用复杂场景进行训练,此时直到完成总步长后得到最终的协作对抗策略模型。通过课程学习的方式可以有效提升多智能体模型收敛速度及最终训练效果。
[0068]
步骤4:导入训练好的协作对抗策略模型,并渲染虚拟智能坦克至真实场景,完成增强现实仿真对抗环境。首先需要将世界坐标系下的虚拟智能坦克目标转换到像素坐标系下。转换过程中涉及的公式如下:
[0069][0070]
其中,(ε,η,δ)是agent在世界坐标系中的三维位置信息。t
cw
表示从世界坐标系到相机坐标系的转换,由跟踪定位算法实时进行更新。相机模型决定相机坐标系与图像坐标系的转换关系。在unity3d中,相机模型是透视投影模型,对于透视投影模型,θ表示相机的纵向视角,n是从相机中心到近裁剪平面的距离,f是从相机中心到远裁剪平面的距离,aspect=w/h是投影图像的长宽比,k是相机的内部参数,z
c
和γ与深度有关。通过上述坐标变换可以将虚拟智能坦克渲染在真实场景中的相应位置。
[0071]
步骤5:采用多传感器融合实时跟踪定位算法获取用户的六自由度全局位姿,并将该位姿传递给unity3d中的虚拟相机。
[0072]
步骤6:导入真实摄像机捕获的画面,渲染在场景中,以此作为用户的操作对象,用于与虚拟坦克及场景进行虚实交互。
[0073]
步骤7:在unity3d中改变真实场景模型、实时视频流和虚拟坦克物体的渲染通道顺序,最后根据真实场景模型和虚拟坦克物体的深度关系,调整两者的渲染顺序,从而将步骤1离线阶段生成的虚拟场景中的三维地图模型隐藏,最后形成虚拟坦克与真实环境融合的增强现实仿真对抗环境。此时在真实场景中,用户可以操作真实坦克与虚拟智能坦克协作完成对抗任务,与此同时,虚拟智能坦克自身具有面对环境变化做出更优决策的智能型,并且多智能体坦克之间存在协作策略,使得真实用户和虚拟多智能体之间协作对抗策略更加灵活多变,提升了交互体验和仿真对抗效果。
[0074]
自此,就实现了基于强化学习的增强现实多智能体协作对抗环境。
[0075]
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1