一种基于人工智能的主动脉结构图像自动分割方法与流程
1.本发明属于医学图像处理领域,特别是涉及一种基于人工智能的主动脉图像自动分割方法,其主要应用于经导管主动脉瓣置换术的术前评估。
背景技术:
2.主动脉根部位于心脏的中心部位,其下部为主动脉窦。主动脉窦呈圆柱状插入在二尖瓣与三尖瓣之间,基底部完全包埋在周围的组织中,后半周则完全被两侧心房所包绕。为心脏自身提供供血的冠状动脉一般开口于主动脉窦内的左冠窦和右冠窦。主动脉瓣位于主动脉根部底部,主动脉窦与左室流出道交界处,构成了主动脉与左心室的边界,处于心脏的形态学中心,同时也是血流动力学中心,其在主动脉和左心室之间起到了单向阀门作用,在心脏舒张期防止主动脉血流回流到左心室,在收缩期允许血流从左心室流入主动脉中。
3.主动脉瓣对维持心脏和全身的正常供血发挥了重要的作用,但由于先天性、风湿性、退行性改变等原因,主动脉瓣会出现主动脉瓣狭窄(aotic valve stenosis,as),主动脉瓣反流(aortic regurgitation,ar)等病变,严重影响全身血供,危害身体健康,降低生活质量,重度主动脉瓣膜病直接威胁患者的生命。
4.近年来,主动脉瓣膜病通过介入手术进行干预治疗的方式得到了广泛推广,给外科高危或禁忌患者带来了希望。经导管主动脉瓣置换术(transcatheter aortic valve replacement,tavr),又称经导管主动脉瓣置入术(transcatheter aortic valve implantation,tavi),是指将组装完备的人工主动脉瓣经导管置入到病变的主动脉瓣处,在功能上完成主动脉瓣的置换。由于tavr手术是在非直视状态下进行介入操作,故要求医生在术前基于影像检查对患者的主动脉根部及毗邻的生理结构进行细致深入的个体化测量、评估,并基于测量评估的结果进行手术策略的制定、手术器械的选择。
5.影像学评估是tavr/tavi术前评估的重点,包括自体主动脉瓣膜、主动脉瓣虚拟瓣环、主动脉根部、冠状动脉及血管入路解剖情况,判断是否适合tavr及选择置入瓣膜的型号。多排计算机断层扫描(multislices computed tomography,msct)是目前tavr影像学评估最主要的手段之一,是判断患者是否适合tavr及选择人工瓣膜型号的主要依据。通过多平面重建,可以多切面观察瓣膜形态、评估瓣膜厚度、钙化程度及其在主动脉根部所占体积;在瓣环平面测量虚拟瓣环的周长和面积,继而计算瓣环内径(周长导出径、面积导出径、长短径);在此基础上进行左室流出道(lvot)、瓦氏窦、窦管交界(stj)、升主动脉等区域的参数测量,为瓣膜型号、类型选择提供依据,并可分析预测瓣周漏风险;msct还可用来评估冠脉开口高度,预估冠状动脉阻塞的风险,评估冠状动脉病变。此外,msct也可以用来对手术入径进行评估。
6.目前,在ct影像后处理领域已有解剖结构测量平台工具软件,如fluoroct、3mensio、cvi42等。医生需依靠自身经验和对主动脉根部解剖结构的理解,通过纯手动或半自动的方式对主动脉根部相关结构进行打点、描绘和测量。对影像中特征范围的选择和提取,完全通过医生手工操作完成。
7.本发明的目的在于提供一种基于人工智能的主动脉结构图像的全自动分割方法,该方法能够提高图像分割特别是结构轮廓分割的准确度,由此提高基于所述图像分割结果的三维模型构建的准确度,进而提高相关结构的定位和测量的准确度,最终达到提高tavr/tavi术前评估的效率和精度的有益效果。解决了手工操作测量不准确、测量主观性大、存在人为误差、难以复制重现等缺点。
技术实现要素:
8.根据tavr/tavi手术核心影像数据的特点,其分割难点主要集中在结构边缘,即各个结构轮廓分割的不准确导致自动化分割方法性能有瑕疵。因此本发明的目的在于提供一种基于人工智能的主动脉结构图像自动分割方法,该方法能够对目标区域进行更精准分割,使分割不完全的区域更加完善,有效提升分割效果。
9.本发明通过如下技术方案实现:
10.一种基于人工智能的主动脉结构图像自动分割方法,其特征在于,包括以下步骤:
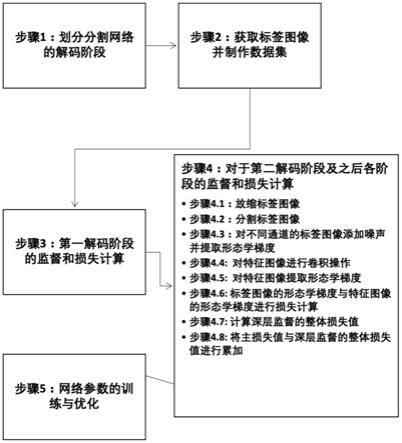
11.步骤1:对分割网络的解码阶段进行划分;
12.步骤2:获取标签图像并制作数据集,根据心脏结构的原始ct图像通过人工标注得到标签图像,通过对所述原始ct图像和所述标签图像进行切片操作,分别制作成原始图像数据集和标签图像数据集;
13.步骤3:进行第一解码阶段的监督和损失计算,在第一阶段解码器末端使用原始图像进行监督,对预测图像和标签图像通过损失函数进行损失计算,得到主损失lmain,所述损失函数为本领域通常使用的损失函数,优选为交叉熵损失函数;
14.步骤4:对于第二解码阶段及之后各阶段的监督和损失计算,通过以下步骤实现:
15.步骤4.1:将标签图像进行放大或缩小,使其尺寸大小与相应解码阶段的特征图尺寸大小相同,上述标签图像的放缩方法为本领域通常使用的图像放缩方法,优选为双线性差值法;
16.步骤4.2:将标签图像进行分割,使用独热编码(one
‑
hot)将标签图像转换为多通道图像,每个目标结构占据所述标签图像的一个通道;
17.步骤4.3:对不同通道的标签图像添加噪声并提取形态学梯度,首先,对放缩后的多通道标签图像添加噪声,所述噪声为本领域通常使用的噪声,优选为高斯噪声或椒盐噪声,其次,对添加噪声后的标签图像进行形态学梯度提取;
18.步骤4.4:对各解码阶段的特征图像进行卷积操作,输出多通道图像,通道数与相应解码阶段的标签图像的通道数保持一致;
19.步骤4.5:对各解码阶段的多通道特征图像进行形态学特征提取,得到每个解码阶段的多通道特征图像的形态学梯度;
20.步骤4.6:将添加噪声后的标签图像的形态学梯度与对应解码阶段的特征图像的形态学梯度进行损失计算,设损失函数为lossfunc,该损失函数为现有技术中通常使用的损失函数,优选为交叉墒损失函数,由如下公式所示:
21.22.其中,k代表某个解码阶段,表示第k个解码阶段的损失值,i代表某个通道,n代表总的通道数量,p
i
代表多通道特征图像的形态学梯度,g
i
代表标签图像的形态学梯度;
23.步骤4.7:将第二及其之后的各解码阶段的损失值进行累加,即可得到深层监督的整体损失值,其累加方式可以是根据不同比例调整的加权和,其具体如下所示:
[0024][0025]
其中,k为某个解码阶段,n为解码阶段总数,n
‑
1表示除去第一个解码阶段外的解码阶段数,λ
k
代表不同解码阶段的权重,l
aux
代表深层监督的整体损失值;
[0026]
步骤4.8:将主损失值与深层监督的整体损失值进行累加,即可得到总体损失值,其累加方式可以是根据不同比例调整的加权和,其具体如下所示:
[0027]
l=l
main
+γl
aux
[0028]
其中,l代表总体损失值,l
main
为主损失值,l
aux
代表深层监督的整体损失值,γ代表权重;
[0029]
步骤5:将l作为最终损失值,根据反向传播算法,利用选定的优化器进行网络参数的训练与优化,所述优化器优选sgd或adam。
[0030]
根据本发明的一种基于人工智能的主动脉结构图像自动分割方法,步骤2中,所述原始ct图像与所述标签图像均包含三维图像信息,经多平面重建后可获得矢状面、冠状面和横断面三个切面,分别从所述三个切面对原始ct图像和标签图像进行切片操作,分别得到三个切面对应的二维原始图像及与其匹配的二维标签图像,分别制作成原始图像数据集和标签图像数据集。
[0031]
根据本发明的一种基于人工智能的主动脉结构图像自动分割方法,步骤4.2中,由于tavr/tavi手术使用的数据是基于ct图像的主动脉根部结构影像,此手术需要涉及的生理结构和病理组织主要包括主动脉,左心室以及钙化组织,以上三个目标结构具有各自不同的特点,其中,主动脉整体形态较为清晰和规则,但边缘部分与周边结构成像差异较小,所以易于分割主体但边缘分割较难;左心室内形态复杂且与主动脉瓣膜交界处结构复杂;钙化部分分布随机且形状各异,本阶段的目标是将标签图像中的上述三个目标结构准确分割出来。
[0032]
根据本发明的一种基于人工智能的主动脉结构图像自动分割方法,步骤4.3中,由于不同的解码阶段包含有不同程度的语义信息,统一使用原始标签图像进行监督,会忽略不同解码阶段所包含语义信息的差异性,限制了深度监督所带来的性能增益,因此,为了更好地模拟特征的特异性,针对每个解码器阶段,添加的高斯噪声程度不同,越深的层次特征越抽象,需要添加的噪声就越大,从第二解码阶段之后,噪声添加的程度依次增加,具体添加噪声的程度,依据以下方法确定:
[0033]
a.先对第二解码阶段添加不同程度噪声,通过对比试验,确定该阶段的噪声程度;
[0034]
b.在第二解码阶段的基础上,对第三解码阶段添加比第二解码阶段更大程度的噪声,通过对比试验确定该阶段的噪声程度;
[0035]
c.依次在上一解码阶段的基础上,对其后一解码阶段添加噪声,从而确定不同解码阶段所需添加的噪声程度。
[0036]
根据本发明的一种基于人工智能的主动脉结构图像自动分割方法,步骤4.3中,提取形态学梯度的具体操作方法为:
[0037]
a.对添加噪声后的标签图像进行膨胀,得到膨胀图像;
[0038]
b.对添加噪声后的标签图像进行腐蚀,得到腐蚀图像;
[0039]
c.将膨胀图像与腐蚀图像做异或运算,得到添加噪声后的标签图像的形态学梯度。
[0040]
根据本发明的一种基于人工智能的主动脉结构图像自动分割方法,步骤4.7中,根据不同的数据集通过试验调整所述权重λ
k
,具体方法为:首先将数据集送入神经网络得到预测图像,然后通过具有预定权重的损失函数计算预测图像和标签图像的损失值并进行优化,不同的权重会导致不同的损失值,会将神经网络优化成不同的效果,通过对比试验选择最优的权重值。
[0041]
根据本发明的一种基于人工智能的主动脉结构图像自动分割方法,所述神经网络为医学图像分割常用网络,例如fcn,unet,unet++及编码阶段进行预训练之后的此类网络,优选为在imagenet上预训练之后unet。
[0042]
本发明的有益效果:通过使用上述基于人工智能的图像处理方法,相比于目前已有的图像处理方法,可以去除明显的误分割区域,提升图像分割效果,对目标区域进行更精准分割,使分割不完全的区域更加完善。为之后的三维模型的建立提供了准确度更高的图像数据,有效提高了tavr/tavi术前评估的效率和精度。
附图说明
[0043]
图1本发明的基于人工智能的主动脉图像自动分割方法的流程图;
[0044]
图2本发明的基于人工智能的主动脉图像自动分割方法的示意图;
[0045]
图3a本发明第一实施例的ct切片图像;
[0046]
图3b本发明第一实施例的标签图像;
[0047]
图3c本发明第一实施例的添加噪声后的标签图像;
[0048]
图3d本发明第一实施例的添加噪声后的标签图像的形态学梯度图;
[0049]
图3e本发明第一实施例中通过现有的基础方法预测的分割结果;
[0050]
图3f本发明第一实施例中通过本发明的方法预测的分割结果;
[0051]
图4a本发明第二实施例的ct切片图像;
[0052]
图4b本发明第二实施例的标签图像;
[0053]
图4c本发明第二实施例的添加噪声后的标签图像;
[0054]
图4d(1)本发明第二实施例的添加噪声后的标签图像的左心室流出道结构的形态学梯度图;
[0055]
图4d(2)本发明第二实施例的添加噪声后的标签图像的主动脉结构的形态学梯度图;
[0056]
图4e本发明第二实施例中通过现有的基础方法预测的分割结果;
[0057]
图4f本发明第二实施例中通过本发明的方法预测的分割结果。
具体实施方式
[0058]
下面结合具体实施例,进一步阐述本发明。应理解,实施例仅用于说明本发明而不用于限制本发明的保护范围。此外,应理解,在阅读了本发明所公开的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本发明所限定的保护范围之内。
[0059]
如图1所示,本发明的基于人工智能的主动脉结构图像自动分割方法包括以下5个步骤:
[0060]
步骤1:对分割网络的解码阶段进行划分,具体划分为4个或5个阶段,本实施例中采用5个解码阶段,如图2所示。
[0061]
步骤2:获取标签图像并制作数据集,根据心脏结构的原始ct图像通过人工标注得到标签图像,原始ct图像与标签图像均包含三维图像信息,经多平面重建后可获得矢状面、冠状面和横断面三个切面,分别从所述三个切面对原始ct图像和标签图像进行切片操作,分别得到三个切面对应的二维原始图像(如图3a和4a所示)及与其匹配的二维标签图像(如图3b和4b所示),分别制作成原始图像数据集和标签图像数据集。
[0062]
步骤3:进行第一解码阶段的监督和损失计算,在第一阶段解码器末端使用原始图像进行监督,对预测图像和标签图像通过损失函数进行损失计算,得到主损失lmain,所述损失函数为本领域通常使用的损失函数,优选为交叉熵损失函数。
[0063]
步骤4:对于第二解码阶段及之后各阶段的监督和损失计算,通过以下步骤实现:
[0064]
步骤4.1:将标签图像进行放大或缩小,使其尺寸大小与相应解码阶段的特征图尺寸大小相同,上述标签图像的放缩方法为本领域通常使用的图像放缩方法,优选为双线性差值法。
[0065]
步骤4.2:对标签图像进行分割,由于tavr/tavi手术使用的数据是基于ct图像的主动脉根部结构影像,此手术需要涉及的生理结构和病理组织主要包括主动脉,左心室以及钙化组织。以上三个目标结构具有各自不同的特点,其中,主动脉整体形态较为清晰和规则,但边缘部分与周边结构成像差异较小,所以易于分割主体但边缘分割较难;左心室内形态复杂且与主动脉瓣膜交界处结构复杂;钙化部分分布随机且形状各异。本阶段的目标是将标签图像中的上述三个目标结构准确分割出来,使用独热编码(one
‑
hot)将标签图像转换为多通道图像,每个目标结构占据所述标签图像的一个通道。
[0066]
步骤4.3:对不同通道的标签图像添加噪声并提取形态学梯度,首先,对放缩后的多通道标签图像添加噪声,所述噪声为本领域通常使用的噪声,本实施例选用高斯噪声或椒盐噪声,由于不同的解码阶段包含有不同程度的语义信息,统一使用原始标签图像进行监督,会忽略不同解码阶段所包含语义信息的差异性,限制了深度监督所带来的性能增益。因此,为了更好地模拟特征的特异性,针对每个解码器阶段,添加的高斯噪声程度不同,越深的层次特征越抽象,需要添加的噪声就越大,从第二解码阶段之后,噪声添加的程度依次增加,具体添加噪声的程度,依据以下方法确定:
[0067]
a.先对第二解码阶段添加不同程度噪声,通过对比试验,即根据试验所获得的图像的不同精度来确定该阶段的噪声程度;
[0068]
b.在第二解码阶段的基础上,对第三解码阶段添加比第二解码阶段更大程度的噪声,通过对比试验确定该阶段的噪声程度;
[0069]
c.依次在上一解码阶段的基础上,对其后一解码阶段添加噪声,从而确定不同解码阶段所需添加的噪声程度;
[0070]
图3c和图4c分别为两个实施例中添加噪声后的标签图像的示例。
[0071]
其次,对添加噪声后的标签图像img进行形态学梯度提取,其具体操作为:
[0072]
a.对添加噪声后的标签图像img进行膨胀,得到膨胀图像img_dila;
[0073]
b.对添加噪声后的标签图像img进行腐蚀,得到腐蚀图像img_ero;
[0074]
c.将膨胀图像img_dila与腐蚀图像img_ero做异或运算,得到添加噪声后的标签图像的形态学梯度img_gradient;
[0075]
图3d和图4d(1)、图4d(2)分别为两个实施例中添加噪声后的标签图像的示例。
[0076]
步骤4.4:对各解码阶段的特征图像,进行卷积操作,输出多通道图像,通道数与相应解码阶段的标签图像的通道数保持一致。
[0077]
步骤4.5:对各解码阶段的多通道特征图像进行形态学特征提取,得到每个解码阶段的多通道特征图像的形态学梯度。
[0078]
步骤4.6:将添加噪声后的标签图像的形态学梯度与对应解码阶段的特征图像的形态学梯度进行损失计算,设损失函数为lossfunc,该损失函数为现有技术中通常使用的损失函数,优选为交叉熵损失函数,由如下公式所示:
[0079][0080]
其中,k代表某个解码阶段,表示第k个解码阶段的损失值,i代表某个通道,n代表总的通道数量,p
i
代表多通道特征图像的形态学梯度,g
i
代表标签图像的形态学梯度。
[0081]
步骤4.7:将第二及其之后的各解码阶段的损失值进行累加,即可得到深层监督的整体损失值,其累加方式可以是根据不同比例调整的加权和,其具体如下所示:
[0082][0083]
其中,k为某个解码阶段,n为解码阶段总数,n
‑
1表示除去第一个解码阶段外的解码阶段数,λ
k
代表不同解码阶段的权重,l
aux
代表深层监督的整体损失值,其中,根据不同的数据集通过试验调整所述权重λ
k
,具体方法为:首先将数据集送入神经网络得到预测图像,所述神经网络为医学图像分割常用网络,例如fcn,unet,unet++及编码阶段进行预训练之后的此类网络,优选为在imagenet上预训练之后unet,然后通过具有预定权重的损失函数计算预测图像和标签图像的损失值并进行优化,不同的权重会导致不同的损失值,会将神经网络优化成不同的效果,通过对比试验选择最优的权重值。
[0084]
步骤4.8:将主损失值与深层监督的整体损失值进行累加,即可得到总体损失值,其累加方式可以是根据不同比例调整的加权和,其具体如下所示:
[0085]
l=l
main
+γl
aux
[0086]
其中,l代表总体损失值,l
main
为主损失值,l
aux
代表深层监督的整体损失值,γ代表权重。
[0087]
步骤5:将l作为最终损失值,根据反向传播算法,利用选定的优化器进行网络参数
的训练与优化,所述优化器优选sgd或adam。
[0088]
关于本发明的有益效果,在此通实施例一和实施例二予以举例说明。如图3e所示,在第一实施例中,通过基础方法进行图像分割后,出现了原有结构之外的一块区域(2),而此区域不属于目标区域,属于神经网络识别错误,区域(1)属于误分割区域,所以在左心室流出道(1)分割类似的情况下,基础方法出现了误分割或者识别错误。图3f示出了通过本发明的方法进行图像分割的结果,本发明的方法没有产生误分割,相对于现有技术有效提升了分割精度。
[0089]
如图4e所示,在第二实施例中,通过基础方法进行图像分割后,主动脉(3)区域几乎没有分割出来。图4f示出了通过本发明的方法进行图像分割的结果,其表明,本发明的方法能够将主动脉结构更准确地分割出来,在左心室流出道(1)区域分割结果类似的情况下,明显本发明的方法分割效果更好。
[0090]
以上实施例中使用的基础方法为在imagenet上预训练之后的resnet
‑
34作为编码器的unet网络,即backbone
‑
34。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1