一种基于过滤式和封装式层次递进的特征选择方法
技术领域:
本发明涉及一种基于过滤式和封装式层次递进的特征选择方法,该方法在数据集特征选择方面有着很好的应用。
背景技术:
:
数据集合中存在大量的冗余特征和无关特征,这给数据挖掘带来了很大的挑战,严重影响数据挖掘结果的准确性和科学性,因此在数据挖掘之前将数据集合中的无关特征和冗余特征进行处理。
特征选择也称特征子集选择,特征选择能从原始特征中提出不相关或冗余的特征,减少特征个数找到最优特征子集,提高模型精确度,减少运行时间。特征选择方法依据是否独立于后续的学习算法,可分为过滤式和封装式两种,过滤式与后续学习算法无关,一般直接利用所有训练数据的统计性能评估特征,速度快,但评估与学习算法的性能偏差较大,封装式利用学习算法的训练准确率评估特征子集,偏差小,计算量大,不适合大数据集,过滤式和封装式是两种互补的模式,两者可以结合,一种基于过滤式和封装式层次递进的特征选择方法,能够减少不相关特征和删除冗余特征,减少对计算资源的消耗,缩短训练时间,提高模型性能。
技术实现要素:
:
为了解决数据集的特征不相关或特征冗余问题,本发明公开了一种基于过滤式和封装式层次递进的特征选择方法。
为此,本发明提供了如下技术方案:
1.一种基于过滤式和封装式层次递进的特征选择方法,其特征在于,该方法包括以下步骤:
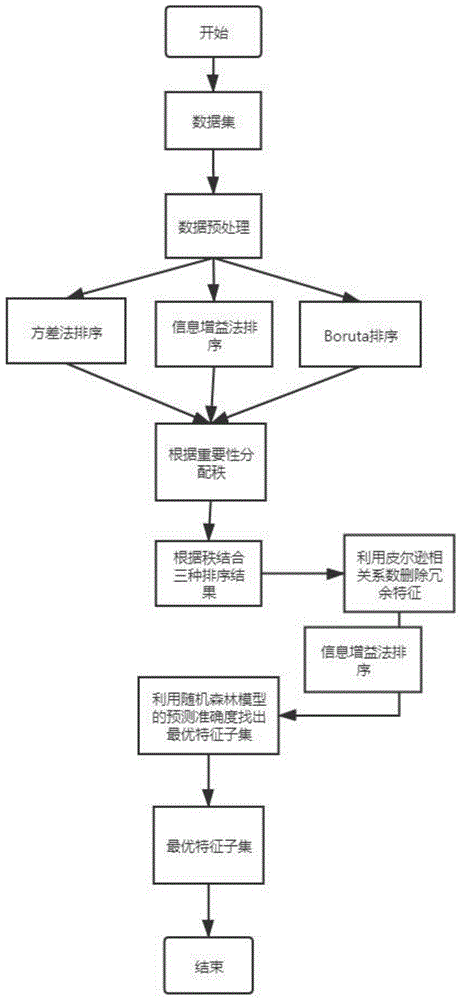
步骤1:基于过滤式的方差排序法和信息增益排序法和基于封装式的boruta排序法,对特征进行排序,对排序后的特征根据重要性程度分配秩,对三种排序方法的结果进行融合。
步骤2:基于皮尔逊相关系数计算特征两两之间的相关性,设定特征的皮尔逊相关系数阈值,根据特征之间的相关性,选择性删除部分特征。
步骤3:基于封装式的序列向前选择法结合随机森林模型找到最好的特征组合,从而得到最优特征子集。
2.根据权利要求1所述的一种基于过滤式和封装式层次递进的特征选择方法,其特征在于,所述步骤1中,基于过滤式的方差排序法和信息增益法以及基于封装式的boruta排序法对特征进行排序,具体步骤为:
步骤1-1采用过滤式的方差排序法和信息增益法以及基于封装式的boruta排序法,分别对特征重要程度由到大到小依次进行排序;
步骤1-2为排序后的特征分配秩,重要性程度最高的秩为1,其余特征依次分配;
步骤1-3依次把每个特征在不同排序方法中所得的秩相加并按由小到大的顺序进行排列,得到特征的最终排列顺序。
3.根据权利要求1所述的一种基于过滤式和封装式层次递进的特征选择方法,其特征在于,所述步骤2中,基于皮尔逊相关系数删除冗余特征,具体步骤为:
步骤2-1对排序后的特征基于皮尔逊相关系数计算特征两两之间的相关性;
步骤2-2设定特征的皮尔逊相关系数阈值;
步骤2-3根据特征之间的皮尔逊相关系数,选择性删除部分特征。
4.根据权利要求1所述的一种基于过滤式和封装式层次递进的特征选择方法,其特征在于,所述步骤3中,基于封装式的序列向前选择法结合随机森林模型找到最好的特征组合,从而得到最优特征子集,具体步骤为:
步骤3-1将删除冗余特征后的特征的秩作为序列前向选择法的评价函数;
步骤3-2将特征排序中按照特征的秩从小到大依次加入特征集中;
步骤3-3通过随机森林算法建立训练模型,通过比较模型预测的准确度来找到最优特征子集。
有益效果:
1、本发明是一种基于过滤式和封装式层次递进的特征选择方法,是为数据集进行特征选择的一种新方法。
2、本发明弥补了过滤式方法评估与学习算法的性能偏差较大的缺点,封装式方法具有良好的评估效果。
3、本发明解决了封装式方法不适合大型数据的问题,不仅适用于小型数据集,还适用于大型数据集。
4、本发明讲过滤式和封装式结合,互补不足,在此基础上添加了利用皮尔逊相关系数删除冗余特征,减少对计算资源的消耗,提高模型性能。
附图说明:
图1为本发明实施方式中的一种基于过滤式和封装式层次递进的特征选择方法的流程图。
图2为本发明实施方式中的基于皮尔逊相关系数删除冗余特征的流程图。
图3为本发明实施方式中的基于封装式的序列向前选择法结合随机森林模型的流程图。
具体实施方式:
为了使本发明的实施例中的技术方案能够清楚和完整地描述,以下结合实施例中的附图,对本发明进行进一步的详细说明。
以某肿瘤医院采集的乳腺癌数据集进行特征选择为例,本发明实施例一种基于过滤式和封装式层次递进的特征选择方法的流程,如图1所示,包括以下步骤。
步骤1基于过滤式的方差排序法和信息增益法以及基于封装式的boruta排序法对特征进行排序的过程如下:
步骤1-1采用过滤式方法中的方差排序法和信息增益法以及基于封装式的boruta排序法,分别对特征重要程度由到大到小依次进行排序;
其中,方差值的计算公式如下:
x1...xn为特征x的不同特征值值,m为特征的平均值。
信息增益的计算公式如下:
igain(x,y)=e(x)-e(x|y)
e(x)为信息熵,即只考虑目标特征时对样本进行分类所带来的信息量,e(x|y)为条件熵,即在条件y下x的信息熵。
步骤1-2为排序后的特征分配秩,重要性程度最高的秩为1,其余特征依次分配;
步骤1-3依次把每个特征在不同排序方法中所得的秩相加并按由小到大的顺序进行排列,得到特征的最终排列顺序bi.rads分级、弹性评分、尺寸、年龄、腋下淋巴结大小、形态、血流信号、腋下淋巴结、阻力指数、钙化灶、钙化灶,排序结果如表1所示。
表1
步骤2基于皮尔逊相关系数删除冗余特征的过程如下:
基于皮尔逊相关系数删除冗余特征流程如图2所示,具体为:
步骤2-1对排序后的特征基于皮尔逊相关系数计算特征两两之间的相关性;
其中,皮尔逊相关系数的计算过程如下:
δ为样本的标准差,n为样本数量。
步骤2-2设定特征的皮尔逊相关系数阈值为0.5;
步骤2-3根据特征之间的皮尔逊相关系数可知弹性评分和bi.rads分级的相关性最大,弹性评分和bi.rads分级对分类结果的相关性相似,bi.rads分级又与其他特征变量的相关性紧密,所以删除冗余特征弹性变量,特征之间的皮尔逊相关系数超过0.5的如表2所示。
表2
步骤3基于封装式的序列向前选择法结合随机森林模型的过程如下:
基于封装式的序列向前选择法结合随机森林模型的流程如图3所示,具体为:
步骤3-1将删除冗余特征后的特征的秩作为序列前向选择法的评价函数;
步骤3-2将特征排序中秩最小的特征bi.rads分级加入特征集中;
步骤3-3通过随机森林算法建立训练模型,记录加入秩最小的特征bi.rads分级的模型准确度;
步骤3-4根据秩从小到大依次加入特征变量,并记录每加入一个特征变量后的模型准确度;
步骤3-5比较得到的模型准确度,准确度最高相对应的特征子集为:bi.rads分级、尺寸、年龄、腋下淋巴结大小、形态、腋下淋巴结大小、血流信号、腋下淋巴结,这一特征子集为求得的最优特征子集。
本发明实施方式中的一种基于过滤式和封装式层次递进的特征选择方法,能够为数据集选出最优特征子集,为后续的学习建模提供准确的特征信息,提高模型的准确性。
以上所述是结合附图对本发明的实施例进行的详细介绍,本文的具体实施方式只是用于帮助理解本发明的方法,对于本技术领域的普通技术人员,依据本发明的思想,在具体实施方式及应用范围内均可有所变更和修改,故本发明书不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!