利用深度生成模型检测恶意软件的制作方法
1.本文描述的主题涉及用于使用深度生成模型表征可能为恶意的制品(artifact)的增强技术。
背景技术:
2.黑客们在通过开发恶意软件来访问各种计算系统的尝试方面变得越发老练,这些恶意软件被设计成欺骗或以其他方式绕过传统防病毒解决方案。特别地,对抗技术被采用,其中各种制品封装恶意软件被迭代地且自动地修改,直到当这种制品被防病毒软件不正确地分类为良性的时候为止。同时,恶意软件检测系统变得越发多模式(multimodal),在做出最终判定时会整合来自多个异构信息源的信息。
技术实现要素:
3.在第一方面,制品被接收。此后,特征会被从制品中提取,使得向量可以被填充。该向量然后被输入到异常检测模型中,该异常检测模型包括用以生成第一得分的深度生成模型。该第一得分可以将该制品表征为对于访问、执行、或继续执行是恶意的或良性的。此外,该向量被输入到基于机器学习的分类模型中,以生成第二得分。该第二得分也可以将该制品表征为对于访问、执行、或继续执行是恶意的或良性的。第二得分然后基于第一得分被修改,以得到最终得分。然后,该最终得分可以被提供给消费应用或过程。
4.深度生成模型可以是基于似然度的模型。在一些变型中,该基于似然度的模型包括变分自编码器和/或归一化流。
5.异常检测模型可以形成模型集合的一部分,该模型集合包括从以下组中选择的至少一个机器学习模型,该组包括:逻辑回归模型、神经网络、卷积神经网络、递归神经网络、生成对抗网络、支持向量机、随机森林和/或贝叶斯模型。
6.在向量被输入异常检测模型和/或分类模型之前,使用特征减少操作,向量中的特征可以被减少。该特征减少操作可以包括以下一项或多项:随机投影、特征哈希、确定性主成分分析、或随机性主成分分析。
7.该修改可以包括组合第一得分和第二得分。
8.该修改可以包括当第一得分高于阈值时,覆写第二得分。在这种情况下,第二得分可以被基线得分或先前得分替换作为最终得分。
9.该修改可以包括将权重应用于第二得分,该权重是变化的,并且是基于第一得分的。
10.在一些变型中,多个不同向量被创建,这些向量依次被对应的分类模型和/或异常检测模型分析。被用于生成最终得分的分类模型的输出的权重可以是变化的,并且是基于(多个)第一得分的。
11.该修改可以包括将权重应用于第二得分,该第二得分是变化的且基于第一得分的,并且将加权的第二得分和基线得分组合。
12.该修改可以包括当第一得分高于阈值时,将向量传送给第二分类模型以用于分类,其中第二分类模型的输出被用于生成最终得分。相比于分类模型,第二分类模型可以是在计算上更密集的。第二分类模型被计算设备执行,计算设备也执行分类模型。备选地,第二分类模型可以被计算设备执行,该计算设备远离执行分类模型的计算设备。
13.本文也描述了存储指令的非暂态计算机程序产品(即物理实施的计算机程序产品),这些指令在由一个或多个计算系统中的一个或多个数据处理器执行时,使至少一个数据处理器执行本文的操作。类似地,还描述了计算机系统,其可以包括一个或多个数据处理器和存储器,该存储器被耦合到该一个或多个数据处理器。存储器可以暂时地或永久地存储指令,这些指令使至少一个处理器执行本文所描述的操作中的一个或多个操作。此外,方法可以由一个或多个数据处理器实现,该一个或多个数据处理器在单个计算系统内,或者在两个或更多个计算系统中分布。经由一个或多个连接,这种计算系统可以被连接,并且可以交换数据和/或命令或其他指令等,这些连接包括但不限于网络上的连接(例如,因特网、无线广域网、局域网、广域网、有线网络等),经由多个计算系统中的一个或多个计算系统之间的直接连接等。
14.本文描述的主题提供了许多技术优点。例如,与传统技术相比,当前主题提供了可能为恶意的制品的更精确的分类。
15.本文所描述的主题的一个或多个变型的细节在附图和下面的说明书中被阐述。根据说明书、附图和权利要求书,本文所描述的主题的其他特征和优点将是明显的。
附图说明
16.图1是图示了用于将制品表征为恶意的或良性的、基于计算机的工作流程图。
17.图2是图示了使用深度生成模型的恶意软件检测的过程流程图;以及
18.图3是图示了可以用于实现本文主题各方面的计算设备的示意图。
具体实施方式
19.本文主题涉及用于使用深度生成模型来检测恶意软件(例如,恶意代码等)的增强技术。一旦通过使用这种模型,恶意软件在文件中被检测到,校正动作就可以被采取,诸如阻止访问这样的文件、停止执行这样的文件、和/或隔离该文件等。
20.判别模型(discriminative model)估计概率p(y|x),其中y为响应(诸如标签),且x为特征向量。相比之下,生成模型估计p(x),其中x为特征的向量(注意,如需要,那些特征之一可以为标签y)。判别模型的经典示例包括回归和多层感知器。生成模型的经典示例包括指数族分布和混合模型。
21.相对于判别模型,生成模型的优点为它们允许针对新样本计算异常得分。对于判别模型,不论特征向量x是正常的或异常的都是没有意义的,因为该模型采取的x为给定的。相比之下,生成模型可以评估特征的样本(再次,如需要,则包括类标签)是否异常。
22.如本文所提供的,针对恶意软件检测产品,对异常的这些评估是无价的。如果文件的对应特征看似是典型的,而不是那些特征看似异常,那么人们将对机器学习(ml)系统的表征或其组件之一会更有信心。这里突出显示两种场景,其中这种“信任”的评估可以增强分类:当保护免受对抗攻击时,以及当将多个模型集成到单个得分中时。
23.在基于ml的防病毒产品上的对抗攻击可能涉及转变坏文件的特征,直到他们被该产品表征为“好”为止。如果攻击成功,则该文件可以通过那些仅使用了判别模型的基于ml的防病毒产品。然而,考虑这些产物可以产生看起来高度不寻常的特征的制造组合。例如,可以执行“字符串填充”攻击,通过该攻击将许多字符串附加到恶意文件的末尾,这些字符串通常是好(goodness)的指示(诸如与视频游戏相关的术语)。这产生了具有奇异特征组合的文件,并且该文件将会被高质量异常检测器标记。
24.现在考虑多模式恶意软件检测系统,其跨多个异构信息源整合信息。例如,在恶意用户检测的上下文中,可能需要组合来自各种模型(过程、网络、击键、鼠标、登录、文件、注册表等)的得分。在恶意软件检测的上下文中,可能需要组合来自静态(即,预执行等)模型和动态(即,后执行等)模型的得分。在这种示例中,来自多个分类器的得分必须被组合到最终判定中。当这样做时,根据每个分类器输入的异常水平(高异常导致低权重),该分类器的得分可以被加权。因为高异常得分暗示这些输入是偏离分布的,该策略是合理的,因此该策略对于分类器模型是固有地未知的。注意,在先前得分或基线得分也贡献于最终判定的情形下,然后随着在所有分类器中异常水平增加,最终判定将看起来越来越像先前得分或基线得分。
25.因此,异常检测是恶意软件检测系统的重要部分。文件、文件截图、制品等被分类为“好”但“异常”保证了较低的信任度。最后,这样的文件可能需要被阻止、或临时隔离、或者可能授权由更昂贵的模型、系统操作员或恶意软件分析师进一步处理。相比之下,被分类为“好”且“正常”的文件授权较高的信任度,使它们运行而无需进一步检查。此外,在复杂多模式恶意软件检测系统中,该系统整合来自多个分类器的信息,给定模态的异常水平可以用于衡量该模态向最终判定的贡献,该最终判定与文件是否需要被阻止、或暂时隔离、或授权由更昂贵的模型、系统操作员或恶意软件分析师进一步处理有关。
26.用于标识异常计算机文件的现有方法具有有限的表达度(即在数据中捕获复杂结构的能力等),这是由于这些现有方法使用了简单的生成模型,诸如高斯函数或高斯函数混合、或由其导出的距离测度(如马氏距离(mahalanobis distance))。利用本文主题,通过使用基于深度生成似然度的模型,可以对计算机文件执行异常检测。本文所使用的深度生成模型提供了密度估计器的富类;特别地,它们组成具有深度神经网络的概率模型,以构建具有表现力的和可缩放到高维输入的模型。
27.通常有两类深度生成模型:生成对抗网络(gan)和基于似然度的模型。本文主题聚焦于基于似然度的模型,因为它们提供了对新样本的异常水平进行评分的自然的方式。依次,存在基于似然度的模型的三种主要子类:自回归模型、变分自编码器(vae)、以及归一化流。虽然每个子类都可以被利用,但是本文主题聚焦于vae和归一化流,因为自回归模型难于并行化。关于vae和归一化流模型如何可以用于标识异常计算机文件的细节被提供如下。
28.图1是过程流程图100,其图示了用于将制品分类为恶意或良性的样本计算机实现的工作流。初始地,制品110可以被接收(例如,被访问、加载、从远程计算系统接收等)。制品110可以是文件、文件的一部分、表征文件的元数据、和/或源代码。该制品110可以被观测器解析或以其他方式处理。特别地,观测器可以从制品中提取120特征(有时被称为属性或观测)并向量化130该特征。进一步地,取决于向量内的特征的复杂度和/或数量,特征减少操作140可以被执行在向量上,该操作减少该向量维度的数量。特征减少操作140可以利用各
种技术,包括但不限于主成分分析和随机投影矩阵,用以减少向量中被提取的特征的数量且同时保持有用(如用于分类目的等)。具有减少的特征的向量可以被输入到一个或多个异常检测模型150中。如下详述,异常检测模型150可以包括深度生成模型。
29.异常检测模型150的输出可以为第一得分160。除非另有指示,否则如本文所用的第一得分160(和附加地第二得分180)可以是数值,分类类型或集群、或其他字母数字输出,它们依次可以被消费过程或应用195直接使用或间接使用(如下所描述,在与第二得分组合190后),以采取后续动作。针对恶意软件应用,最终得分190(其可以是第一得分160和第二得分180的组合、基于第一得分160的第二得分180的变型、另一得分等)可以用于确定是否访问、执行、继续执行、隔离、或采取一些其他补救动作,这些动作会阻止软件和/或计算系统被恶意代码或封装在制品110内的其他信息感染或以其他方式渗透。
30.在一些情况下,得分160可以被一个或多个分类模型170消耗,该分类模型然后会生成第二得分180,该第二得分然后可以被消费过程或应用195(代替使用第一得分的消费过程或应用195)直接地使用或间接地使用(在190处与第一得分160结合后)。例如,第一得分160连同减少的特征140一起提高分类模型170的精确度。分类模型170可以采取各种形式,包括但不限于深度生成模型、逻辑回归模型、神经网络(包括卷积神经网络、递归神经网络、生成对抗网络等)、支持向量机、随机森林、贝叶斯模型等、或一些组合。
31.在最终得分生成190的情况下,各种权重可以被应用于第一得分160和第二得分180。异常检测模型150可以用于提供关于多少分类模型170的输出可以被信任的见解。例如,如果第一得分160(即异常得分)足够高,则在组合190过程中,第二得分180(分类)可以被覆写。例如,覆写可以包括用基线得分、先前得分、或默认得分替换第二得分180。当处于预期默认为恶意文件的环境中时、当有上下文的信息暗示为恶意时、和/或当决策权衡倾向于为侵略性大于保守性(即,希望避免漏报
‑
错过恶意软件
‑
以任何代价)时,该基线得分可以是低分(在恶意分类的方向上)。
32.当处于期望默认为良性文件的环境中时、当有上下文的信息暗示为良性时、和/或当决策权衡倾向于为保守性大于侵略性(即,希望避免误报
‑
调用好文件恶意软件
‑
以任何代价)时,基线得分可以为高分(在良性分类的方向上)。
33.在一些情况下,针对最终得分生成190,第二得分180可以与基线得分组合,并且权重可以是基于第一得分160的。例如,由第一得分160指示的异常水平越高,越大的权重被给到基线得分。
34.如果第一得分160(异常得分),分类模型得分180可以被利用未知指示覆写。例如,考虑分类器被训练以映射花的图片到它的名称。如果该分类器突然得到一张汽车的图片,它可以被配置为不返回它的列表中可能的花的名称,该花恰巧与图像最匹配;否则它可以报告“未知”。
35.在进一步情况下,如果第一得分160足够高,则附加处理可以被征集。例如,更加计算密集的模型可以被使用。这样的模型可以是本地的或可选地远程的(即基于云的,而非在本地客户端上)。例如,该模型可以执行更深的潜入到文件中(如,脚本分析、或反编译等),这花费额外的金钱或时间去运行,因此它应当仅在必要时才被征集。在一些情况下,较高的第一得分160可以标记制品100用于手工检测/调查。
36.在一些实现中,可以存在异常检测模型150的总体(ensemble)和/或分类模型170
的总体。当使用总体时,可以存在不同类型的向量130,并且在190处的组合可以被配置,使得第一得分160可以用于提供针对第二得分180的权重以达到最终的组合得分。作为示例,在恶意软件分类上下文中,假设有基于静态文件特征的向量a(可以在文件的预执行时被提取)和基于动态文件特征的向量b(发生在文件执行过程中)。假设这些向量被分别减少为精简向量a和精简向量b,并且然后被馈入分类器a(在静态特征上)和分类器b(在动态特征上)中。进一步假设异常检测器a(在静态特征上)产生了高得分。然后,当组合分类器得分a和分类器得分b为最终得分时,调低(或完全忽略)分类器a的决策是期望的。
37.在恶意用户检测的上下文中,假设针对不同的模态(过程、网络、文件、注册表等)存在向量v1、v2、v3
…
等。这些向量v1、v2、v3
…
等可以被馈入分类模型c1、c2、c3
…
等,以一个向量对一个模态的方式。这些相同的向量v1、v2、v3
…
等可以被馈入异常检测模型a1、a2、a3
…
等,以一个向量对一个模态的方式。分类模型c1、c2、c3
…
等的输出可以被组合到最终决策中。更低的权重可以被放置在来自具有更高异常得分的模态的分类器得分上,因为高异常得分暗示向量偏离分布,并因此对于分类器模型是固有未知的。
38.变分自编码器。为便于说明,本文提供了示例变分自编码器,其始终应用了独立同分布假设和高斯分布(并因此为实数值观测)。
39.概率模型。考虑参数频率潜变量模型,其中实数值观测潜变量和参数θ。注意针对一些观测到的数据维度d和一些潜变量维度k,每个和
40.经由因式分解,观测x可以被建模
[0041][0042]
通过使用多层感知器(mlp),每个观测x
(i)
的似然度可以被获取、通过权重θ被参数化,以将潜变量z
(i)
映射到控制观测x
(i)
的分布的高斯参数。
[0043][0044]
因为mlp将潜变量z映射到在观测到的数据x之上的概率分布的参数,mlp的这方面可以被称为概率译码器。
[0045]
在前分布可以被附加地放置在潜变量上:
[0046][0047][0048]
并且如在频率潜变量模型的上下文中,可以假设是θ是固定(但未知的)常数,该常数将被学习。
[0049]
在这种情况下,后验分布p
θ
(z|x)是难解的。然而,通过使用多层感知器(mlp)、通过权重φ被参数化,以将观测x映射到控制潜变量z的分布的高斯参数,近似法可以被考虑:
[0050][0051][0052]
因为mlp将观测x映射到在潜变量z上的概率分布的参数,mlp的这方面可以被称为概率编码器(其也可以被称为识别模型)。
[0053]
注意概率编码器可以被因此视为在潜变量上的后验分布的近似,其产生于使用概率译码器作为似然度。
[0054]
概率编码。例如,可以具体地假设,观测x
(i)
可以被概率地编码到潜变量z
(i)
中,经由以下过程
[0055]
h
(i)
=tanh(w1x
(i)
+b1)
[0056][0057]
其中
[0058]
其中(w1,w
21
,w
22
)为权重,并且(b1,b
21
,b
22
)是多层感知器(mlp)的偏差。令φ:=(w1,w
21
,w
22
,b1,b
21
,b
22
),经训练的编码器可以用于定义近似后验q
φ
(z|x)。
[0059]
概率译码。例如,可以具体地假设,潜变量z
(i)
可以被概率地译码到观测x
(i)
中,经由以下过程
[0060]
h
(i)
=tanh(w3z
(i)
+b3)
[0061][0062]
其中
[0063]
其中(w3,w
41
,w
42
)是权重,并且(b3,b
41
,b
42
)是多层感知器(mlp)的偏差。令θ:=(w3,w
41
,w
42
,b3,b
41
,b
42
),可以使用经训练的译码器,该译码器可以用于定义似然度p
θ
(x|z)。
[0064]
推导。变分推导可以用于共同地优化(θ,φ)。例如,在本文的样本实现中,具有
[0065]
θ=(w3,w
41
,w
42
,b3,b
41
,b
42
)生成参数
[0066]
φ=(w1,w
21
,w
22
,b1,b
21
,b
22
))变分参数
[0067]
特别地,作为边际似然度p
θ
(x)的下界的可以经由熵/能量分解被构建,如在变分推导所提供:
[0068][0069]
通过在变分下界执行随机梯度下降,该模型可以被训练。在训练期间,通过执行期望值的蒙特卡罗近似,目标函数可以被逼近。给定小批量x
(i)
,l个样本可以被从q
φ
(z|x
(i)
)中得出用以获取以下估计量:
[0070][0071]
注意在这种情况下,在采样步骤中,自然反向传播梯度会忽视参数的作用。然而,
再参数化手段可以被利用,即无参数分布p(∈)的可微变换g
φ
被构建,使得g
φ
(∈,x
(i)
)具有和q
φ
(z
(i)
|x
(i)
)一样的分布。使用这种手段,l个样本{∈1,...,∈
l
}可以被从p(∈)中得出以获取估计量:
[0072][0073]
异常评分。通过使用变分自编码器,样本x
(i)
的异常性可以被评估如下。首先,从拟合的变分分布(即编码器)q
φ
(z
(i)
|x
(i)
)中得出l个样本{z
(i,1)
,...,z
(i,l)
}。通过指定它的参数每个这种样本z
(i,l)
确定拟合的似然度的具体形式(即,译码器)。使用这个,样本的重构概率可以被定义为这些似然度的平均值:重构概率
[0074][0075]
现在转向恶意软件异常检测变型的、使用归一化流的变型。
[0076]
密度估计和变量改变。考虑,将持续随机变量x映射到持续随机变量z的参数函数。
[0077]
f
θ
:x
→
z
[0078][0079]
其中x是被观测的样本且z是潜变量。假设密度p
z
被给定。然后通过变量改变定理,被观测的样本x的密度通过以下被给定
[0080][0081]
密度估计的目标可以给出如下:依据所假设的潜变量密度p
z
,学习φ以对未知数据密度p
x
建模。
[0082]
归一化流。归一化流是可逆变换的序列,其将观测到的数据点x映射到隐藏状态表示z。
[0083]
如果被提供
[0084][0085][0086]
则由于det∏
i
a
i
=∏
i
deta
i
,因此似然度变为
[0087][0088]
真实nvp。真实nvp是如上所描述的归一化流,其中被构成为使得:
[0089][0090]
其中b1,...,b
k
是二元掩模,
⊙
是阿达玛乘积(hadamard product)或逐元素乘积
(element
‑
wise product),并且s和t代表缩放和平移。
[0091]
仿射耦合层。在真实nvp中,仿射耦合层是可逆变换的序列的一个元素,即针对某个i∈{1,...,k},它是h
i
。
[0092]
如果随机变量是d维的,且b
i
:=[1,...1,0,...0],其中0条目开始在第d
i+1
个元素处,则仿射耦合层通过以下被给定
[0093][0094][0095]
注意,真实nvp允许雅可比行列式的快速计算,因为:
[0096][0097]
左下项可以是任意复杂的且不必被计算,因为三角矩阵的行列式是对角线的乘积:
[0098][0099]
因此通过上述似然度等式,被应用于单个数据样本x的具有真实nvp归一化流的对数似然度为
[0100][0101]
并且假设独立同分布,被应用于样本集合的对数似然度是各个对数似然度的总和。
[0102]
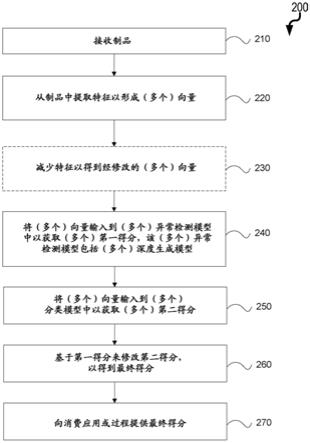
图2是在210处制品被接收的示意图200。此后,在220处,特征被从制品中提取使得向量可以被填充。可选地,在230处,使用一个或多个特征减少操作,向量中的特征可以被减少。然后,在240处,向量被输入异常检测模型,该异常检测模型包括用以生成第一得分的深度生成模型。该第一得分可以将制品表征为对于访问、执行、或继续执行是恶意的或良性的。此外,在250处,向量被输入到基于机器学习的分类模型中,以生成第二得分。该第二得分还可以将制品表征为对于访问、执行、或继续执行是恶意的或良性的。在206处,基于第一得分,第二得分然后被修改以得到最终得分。在270处,该最终得分可以然后被提供给消费应用或过程。
[0103]
图3是图示了用于实现本文所描述的各种方面的、样本计算设备架构的示意图300。总线304可以充当互连硬件的其他图示组件的信息高速公路。标记为cpu(中央处理单元)的处理系统308(例如,在给定的一个或多个计算机处的一个或多个计算机处理器/数据处理器)可以执行计算和逻辑运算,计算和逻辑运算为执行程序所需。非暂态处理器可读存储介质,诸如只读存储器(rom)312和随机存取存储器(ram)316,可以与处理系统308通信,并且可以包括用于这里所指定的操作的一个或多个编程指令。可选地,程序指令可以被存
储在非暂态计算机可读存储介质上,诸如磁盘、光盘、可记录存储器设备、闪存或其他物理存储介质。
[0104]
在一个示例中,磁盘控制器348可以与一个或多个可选磁盘驱动器接口连接到系统总线304。这些磁盘驱动器可以是外部或内部软盘驱动器(诸如360);外部或内部cd
‑
rom、cd
‑
r、cd
‑
rw或dvd、或固态驱动器(诸如352);或者外部或内部硬盘驱动器356。如前所述,这些各种磁盘驱动器352、356、360和磁盘控制器是可选设备。系统总线304也可以包括至少一个通信端口320,用以允许与外部设备的通信,该外部设备被物理地连接到计算系统、或者在外部通过有线或无线网络可获得。在一些情况下,至少一个通信端口320包括或以其他方式包括网络接口。
[0105]
为提供与用户的交互,本文所描述主题可以被实现在计算设备上,该计算设备具有:显示设备340(如crt(阴极射线管)或lcd(液晶显示器)监视器),用于向用户显示经由显示接口314从总线304获取的信息;以及输入设备332,诸如键盘和/或指向设备(例如,鼠标或轨迹球)和/或触摸屏,通过这些设备用户可以向计算机提供输入。其他种类的输入设备332也可以用于提供与用户的交互;例如向用户提供的反馈可以为任何形式的感觉反馈(例如可视反馈、通过麦克风336的听觉反馈、或触觉反馈);以及以任何形式接收的来自用户的输入,包括声学、语音或触觉输入。输入设备332和麦克风336可以通过输入设备接口328,被耦合到总线304并经由总线304传达信息。其他计算设备(诸如专用服务器)可以省略一个或多个显示器340和显示接口314、输入设备332、麦克风336和输入设备接口328。
[0106]
本文所描述主题的一个或多个方面或特征可以被实现在数字电子电路、集成电路、特别设计的专用集成电路(asic)、现场可编程门阵列(fpga)、计算机硬件、固件、软件和/或其组合。这些各种方面或特征可以包括在一个或多个计算机程序中的实现,这些计算机程序在可编程系统上是可执行和/或可解译的;这些可编程系统包括:至少一个可编程处理器、至少一个输入设备和至少一个输出设备,该可编程处理器可以是专用或通用的、被耦合以从存储系统接收数据和指令以及向存储系统传送数据和指令。该可编程系统或计算系统可以包括客户端和服务器。客户端和服务器通常彼此远离,并且通常通过通信网络进行交互。客户端和服务器的关系是通过计算机程序产生的,这些程序运行在各自计算机上并具有彼此的客户端
‑
服务器关系。
[0107]
这些计算机程序(其也可以被称为程序、软件、软件应用、应用、组件、或代码)包括用于可编程处理器的机器指令,并且可以用高级程序语言、面向对象的编程语言、功能性编程语言、逻辑编程语言和/或汇编/机器语言来实现。如本文所用,术语“计算机可读介质”指的是用于向可编程处理器提供指令和/或数据的任何计算机程序产品、装置和/或设备(诸如,例如磁盘、光盘、存储器和可编程逻辑器件(pld)),术语“计算机可读介质”包括接收机器指令作为机器可读信号的计算机可读介质。术语“机器可读信号”是指用于向可编程处理器提供机器指令和/或数据的任何信号。该机器可读介质可以非暂态地存储这种机器指令,诸如例如非暂态固态存储器、或磁性硬盘驱动器、或任何等效的存储介质那样。机器可读介质可以备选地或附加地以瞬态的方式存储这种机器指令,诸如例如处理器高速缓存或与一个或多个物理处理器核心相关联的其他随机存取存储器那样。
[0108]
在上述描述和权利要求中,诸如
“…
中的至少一个(at least one of)”或
“…
中的一个或多个(one or more of)”之类的短语可以出现在元素或特征的联合列表之后。术语
“
和/或”也可以出现在两个或更多个元素或特征的列表中。除非另外隐式地或显式地与使用它的上下文相抵触,否则这种短语旨在单独地表示任何列出的元素或特征、或表示任何记载的元素或特征与其他任何记载的元素或特征的组合。例如,短语:“a和b中的至少一个”、“a和b中的一个或多个”、以及“a和/或b”分别旨在表示“单独a、单独b、或a和b一起”。相似的理解也旨在用于包括三个或更多个项。例如,短语“a、b和c中的至少一个”、“a、b和c中的一个或多个”以及“a、b、和/或c”各自旨在表示“单独a、单独b、单独c、a和b一起、a和c一起、b和c一起、或者a和b和c一起”。此外在上面和在权利要求书中,术语“基于”的使用旨在表示“至少部分地基于”,使得未记载的特征或元素也是可允许的。
[0109]
取决于期望的配置,本文所描述的主题可以被实施在系统、装置、方法、和/或制品中。前面的描述中阐述的实现不表示所有与本文所描述的主题一致的实现。相反,它们是仅与所描述主题相关的方面一致的一些示例。虽然几种变型已经在上面被详细描述,但是其他修改或添加也是可能的。特别地,除了本文所阐述的那些实现之外,进一步的特征和/或变型也可以被提供。例如,上述实现可以针对所公开特征的各种组合和子组合,和/或以上所公开的几个进一步的特征的组合和子组合。此外,附图所描绘的逻辑流程图和/或本文所描述的逻辑流程图不必然要求所示的特别顺序、或连续顺序用以实现所期望的结果。其他实现可以在所附权利要求的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1