汽车金融风险智能语音调查系统及调查方法与流程
本申请涉及一种语音调查系统及调查方法,本申请涉及一种汽车金融风险智能语音调查系统及调查方法。
背景技术:
现有的贷款分期,在贷款前的电话调查均由信审人员通过座机或者手机给客户拨打电话的方式来完成,为此需要配置专门的信审团队来操作电话审核的工作,人员培训、运营和管理的成本高,审核效率也比较低。
技术实现要素:
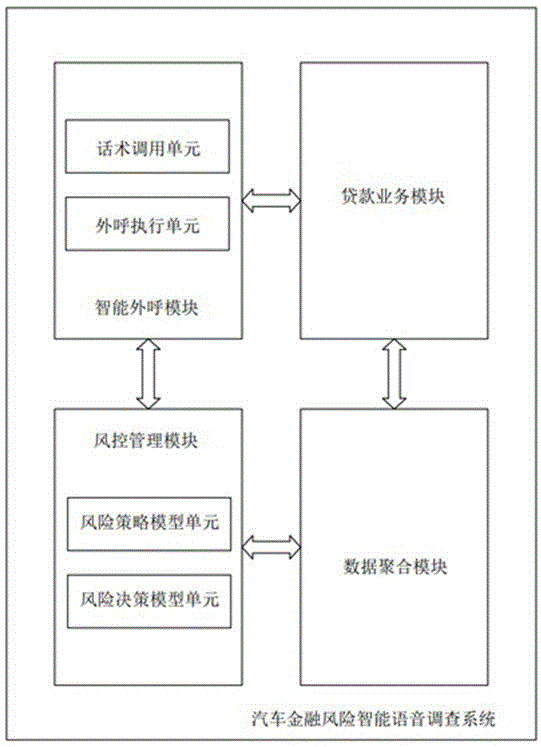
为了解决现有技术的不足之处,本申请提供了一种汽车金融风险智能语音调查系统,包括:智能外呼模块,用于实现针对贷款客户的智能外呼;贷款业务模块,用于采集贷款客户的申请数据;数据聚合模块,用于采集第三方与贷款客户相关的三方数据;风控管理模块,用于根据所述申请数据和所述三方数据输出风险决策数据;其中,所述风控管理模块至少与所述智能外呼模块构成数据连接以使所述智能外呼模块根据所述风控管理模块的风险策略模型的计算结果调用对应调查话术并使所述根据所述风控管理模块根据所述智能外呼模块反馈的调查结果进行风险决策模型的计算和输出。
进一步地,所述智能外呼模块包括:话术调用单元,用于实现调查话术的调用。
进一步地,所述智能外呼模块还包括:外呼执行单元,用于实现外呼和采集语音数据。
进一步地,所述风控管理模块包括:风险策略模型单元,用于根据所述申请数据和所述三方数据进行计算以输出风险策略结果。
进一步地,所述风控决策模块包括:风险决策模型单元,用于根据客户语音调查结果进行计算以输出风险决策结果。
作为本申请的另一方面,本申请还提供一种汽车金融风险智能语音调查方法,具体包括如下步骤:采集贷款客户的申请数据;采集第三方与贷款客户相关的三方数据;根据构建的一个风险策略模型的计算结果调用对应调查话术;执行外呼以所述调查话术对客户进行调查;根据所述智能外呼模块反馈的调查结果使构建的一格风险决策模型进行计算并输出风险决策结果。
进一步地,所述申请数据包括年龄数据、性别数据和职业数据。
进一步地,所述三方数据包括:fico分数据、征信报文数据、银联数据。
进一步地,所述汽车金融风险智能语音调查方法还包括如下步骤:构建所述风险策略模型和所述风险决策模型。
进一步地,所述风险策略模型包含但不限于k-means模型。
本申请的有益之处在于:提供了一种无需人工接入自动化实现贷前风险调查的汽车金融风险智能语音调查系统及调查方法。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请一种实施例的汽车金融风险智能语音调查系统的模块组成结构框图;
图2是根据本申请一种实施例的汽车金融风险智能语音调查方法步骤示意框图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
参照图1所示,本申请的汽车金融风险智能语音调查系统,包括:智能外呼模块、贷款业务模块、数据聚合模块和风险管理模块。
作为具体方案,智能外呼模块用于实现针对贷款客户的智能外呼;贷款业务模块用于采集贷款客户的申请数据;数据聚合模块用于采集第三方与贷款客户相关的三方数据;风控管理模块用于根据申请数据和三方数据输出风险决策数据。
其中,风控管理模块至少与智能外呼模块构成数据连接以使智能外呼模块根据风控管理模块的风险策略模型的计算结果调用对应调查话术并使根据风控管理模块根据智能外呼模块反馈的调查结果进行风险决策模型的计算和输出。
具体而言,智能外呼模块包括:话术调用单元。话术调用单元用于实现调查话术的调用。
具体而言,智能外呼模块还包括:外呼执行单元。外呼执行单元用于实现外呼和采集语音数据。
具体而言,风控管理模块包括:风险策略模型单元。风险策略模型单元用于根据申请数据和三方数据进行计算以输出风险策略结果。
具体而言,风控决策模块包括:风险决策模型单元。风险决策模型单元用于根据客户语音调查结果进行计算以输出风险决策结果。
参照图2所示,作为另一方面,本申请的汽车金融风险智能语音调查方法包括如下步骤:采集贷款客户的申请数据;采集第三方与贷款客户相关的三方数据;根据构建的一个风险策略模型的计算结果调用对应调查话术;执行外呼以调查话术对客户进行调查;根据智能外呼模块反馈的调查结果使构建的一格风险决策模型进行计算并输出风险决策结果。
具体而言,申请数据包括年龄数据、性别数据和职业数据。
具体而言,三方数据包括:fico分数据、征信报文数据、银联数据。
具体而言,汽车金融风险智能语音调查方法还包括如下步骤:构建风险策略模型和风险决策模型。
具体而言,风险策略模型包含但不限于一个k-means模型。
作为优选方案,语音数据首先通过asr(语音识别)技术转化成文本数据,再通过nlp技术对文本数据进行处理,分析客户的答案,加工成可作为模型入参的指标。
总体而言,首先通过分析信审人员作业时候,审核关注的风险要点,针对风险点所应用的调查话术,总结出对应的风险调查话术库。通过风险策略模型对客户申请提供的信息和数据聚合平台获取的第三方数据进行分析,发现所申请的业务可能存在的风险点(如客户填写的常住地址跟工作地址距离超过50公里则会命中工作信息异常的规则),针对具体的风险点预先配置对应的调查话术来完成风险点的调查。应用智能语音外呼系统来模拟信审人员对客户进行风险调查,通过预先配置好的流程和风险调查话术跟客户进行沟通,记录沟通过程并反馈沟通的结果给风控系统。风险决策模型结合智能语音调查结果对客户进行风险评估,对客户的申请作出决策。
作为具体方案,根据风险策略模型的结果,加工成话术模板调用规则,应用话术调用规则实现话术模板调用,通过风险策略模型的结果加工一条规则,比如,风险策略模型的结果为申请人的信额度<实际申请额度,则启动可授信额度不足的调查话术模板。
作为一种可选方案,以下介绍本申请中风险策略模型的构建方法。
步骤一:数据抽取:
首先,可以抽取基于个人资质数据,如申请年龄,性别等。
其次,外部上方数据源,如fico分,中诚信评分等,人行征信报文、运营商、银联等数据,并从整体数据中随机抽样10000条样本作为模型训练样本。
步骤二:特征衍生。
基于业务专家经验,能够准确区分客户资质的主要维度有:个人申请年龄客户教育水平婚姻状态职业信息贷款信息信用卡信息公积金信息住房信息等;根据这些维度,梳理指标,并结合时间特征性,构造出近1年申请信用卡数、贷款笔数等历史统计量。
步骤三:缺失值和异常值处理。当缺失比例高于80%的指标,采用直接删除的方式;当缺失值有特殊含义时,可以单独将缺失归为一类,其余可以用插值法进行填充,比如拉格朗日插值法、均值、众数填充等。通过箱型图进行异常值识别,一般大于或小于箱型图设定的上下界的数据认作异常点,识别后采用直接删除的方式。
步骤四:离散变量连续化处理:如果离散变量的取值有大小的意义,使用数值映射方法进行替换,如果离散变量的取值之间没有大小的意义,则对离散变量进行one-hot编码。one-hot编码又称一位有效编码,其方法使用n位状态寄存器来对n个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
步骤五:标准化处理:不同特征指标往往具有不同的量纲和量纲单位,为了消除指标之间的量纲影响,需要进行数据标准差标准化(standardscale)处理。标准差标准化使得经过处理的数据符合标准正态分布,即均值为0,标准差为1。
步骤六:pca降维:pca即主成分分析发,是一种广泛使用的数据降维方法,主要思想是将n维特征映射到k维上,这k维的全新正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。pca降维的优点有:(1)去除噪声;(2)降低算法的计算开销;(3)使得数据集更易使用;(4)使得结果更容易理解。
步骤七:模型构建:将降维后数据集(3维)采用k-means算法进行模型训练。k-means算法是一种无监督机器学习方法,其基本思想是在数据集中根据一定策略选择k个点作为每个簇的初始中心,然后观察剩余的数据,将数据划分到距离这k个点最近的簇中,在生成的新簇中,重新计算每个簇的中心点,然后再进行划分,直到每次划分的结果保持不变。训练k-means模型,最重要的是k值的选取,常见的确定聚类数k的方法有以下两种:
(1)肘部法则:k-means算法以最小化样本与质点平方误差作为目标函数,将每个簇的质量与簇内样本点的平均误差和称为畸变程度。对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以看作最优的k值。
(2)轮廓系数法:对于一个聚类任务,希望得到的类别簇中,簇内尽量紧密,簇间尽量远离,轮廓系数便是类的密集和分散程度的评价指标,公式为s=(b-a)/max(a,b),其中a代表簇样本到同簇的其他样本的平均距离,b代表簇样本到除本身所外的最近簇的样本的平均距离,求出所有样本的轮廓系数后再求平均值得到了平均轮廓系数。平均轮廓系数的取值范围为[-1,1],平均轮廓系数越大,聚类效果越好,因此,平均轮廓系数最大的k便是最佳聚类数。
步骤八:人群画像的客群类别分类:确定客户所属类别后,分析不同客群类别的特征变量分布,刻画出不同客群的客户特征,进行画像分析,按客户资质优劣将客群类别分为i类,ii类,iii类,iv类人群。
步骤九:基于用户画像、准入评分、资产三个维度对已通过银行准入策略客户进行授信,如用户画像维度下的i类,ii类,iii类,iv类客户分别赋予1.3,1.2,1.1,1.0权重,准入评分维度的权重根据以下公式进行确定:权重=申请评分/750,上下幅度为0.7至1.3,客户资产情况维度下的房贷客户、车贷客户、公积金客户、普通客户的权重分别为1.3,1.2,1.1,1.0。根据这三个维度确定客户的最终权重。然后将系数乘以授信初始额度,给出客户的最终额度。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!