基于集成学习的光伏阵列故障诊断方法
本发明涉及光伏阵列监测与故障诊断技术领域,特别是一种基于集成学习的光伏阵列故障诊断方法。
背景技术:
为了缓解环境污染、化石能源消耗、气候变化等一系列问题,近年来光伏发电装机量在世界范围内迅猛增长。光伏阵列作为光伏发电系统的核心能量采集部件,长期工作在恶劣户外环境下易发生性能退化及遭受各种故障,因此评估其工作状态对提高发电效率、减少火灾事故发生等方面具有重要意义。
目前常用的光伏阵列故障诊断方法有:基于信号处理分析的方法,该方法主要是通过波形信号的分析来检测和定位出现故障的光伏组件,噪声对该方法的实验结果影响较大。基于红外热成像的方法,该方法利用高分辨率的红外成像仪采集光伏阵列的红外图像,然后采用图像分析算法检测故障类型和位置,因为恶劣的环境条件对采集高质量的红外图像也有很大挑战,因此该方法很难得到推广。基于i-v特性曲线的方法,该方法是对比光伏阵列发生故障和正常状态下的i-v曲线来确定是否存在故障。
近年来人工智能发展迅速,并在多领域表现了其强大的能力,因为人工智能算法对数据强大的分析能力,国内外研究学者开始将其应用在光伏阵列的故障诊断上。该方法主要根据光伏阵列的i-v特性曲线、rgb图像、时域暂态序列数据等设计特征,训练深度学习模型(如resnet、elm、cnn等),然后预测待测样本的故障类型。大量的研究表明利用人工智能算法相比传统方法能够更高效地定位光伏阵列的故障,并准确分析其故障类型。但现有算法仍存在很多不足,比如要求大量的数据才能训练得到一个稳定,准确的模型,这对实际数据的获取和计算资源的要求都提出了不少挑战。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于集成学习的光伏阵列故障诊断方法,结合多种算法的优势,提高光伏阵列故障诊断的准确性和稳定性。
本发明采用以下方案实现:一种基于集成学习的光伏阵列故障诊断方法,包括以下步骤:
步骤s1:获取光伏面板的实际i-v特性曲线信息和环境信息;
步骤s2:根据步骤s1获取的信息完成特征工程,获取光伏阵列故障特征;
步骤s3:对步骤s2获取的故障特征进行归一化处理,并对故障标签进行编码;
步骤s4:根据集成学习方法搭建故障诊断模型,并选择模型超参数,训练故障诊断模型;
步骤s5:根据训练好的模型预测光伏阵列的故障类型即将故障特征输入到训练好的模型,输出待测数据的故障类型。
进一步地,步骤s1所述i-v特性曲线信息包括:工作电压v和输出电流i;所述环境信息包括:阵列背板温度t和环境辐照度trr。
进一步地,通过特征构建和特征选择完成步骤s2中所述的特征工程。
进一步地,所述特征构建具体按照如下步骤建立:
步骤sa:将i-v特性曲线的电气参数作为故障特征集,包括:开路电压voc、短路电流isc、最大功率pm、最大功率电压vm和最大功率电流im;
步骤sb:根据i-v特性曲线计算曲线的几何特征添加到故障特征集,包括:ff、slop1、slop2、slop3、slop4、f1、f2,按如下方式获取:
步骤sc:根据光伏模型参数辨识算法提取光伏阵列单二极管模型的模型参数添加到故障特征集,包括:光电流iph、二极管反向饱和电流io、二极管理想化因子n、等效串联电阻rs、等效并联电阻rsh;
步骤sd:将阵列背板温度t和光照度trr添加到故障特征集。
进一步地,所述特征选择具体按照如下步骤建立:
步骤sa:选择斯皮尔曼相关系数法计算特征之间的相关性选择特征;
步骤sb:选择xgboost算法计算特征重要性选择特征。
进一步地,所述步骤s3具体按照如下步骤建立:
步骤1:选择零均值标准化方法对特征数据进行归一化处理,其计算公式如下:
其中,μ代表原始数据均值,δ代表原始数据标准差;
步骤2:选择序号编码对故障类型进行编码,故障类型包括:短路一块组件、短路两块组件、组件老化、组串老化、阴影一块组件、阴影两块组件以及正常工作状态共8种工况数据。
进一步地,步骤s4所述集成学习方法采用模型堆叠的stacking方法,选择极端随机树(et)、lightgbm(lgbm)、支持向量机(svm)和k-近邻算法(knn)作为模型堆叠结构的第一层基础算法,选择et作为第二层算法;模型超参数采用网格搜索进行确定。
进一步地,所述训练故障诊断模型的具体内容为:
步骤a:数据集的70%作为训练集,30%作为测试集;所述故障特征集是每条数据的特征集合;
步骤b:网格搜索确定集成学习第一层结构极端随机树、lightgbm、支持向量机和k-近邻算法的超参数;
步骤c:选择5折交叉验证的方式用训练集分别训练极端随机树、lightgbm、支持向量机和k-近邻算法;每折交叉验证后四个模型都会预测验证集的故障标签,预测测试集故障的概率,交叉验证训练结束后计算概率平均值,概率最大的结果为测试集的故障标签;
步骤d:将步骤sc所述的预测结果作为数据的新特征,和原始数据标签结合构成新数据集;
步骤e:网格搜索确定集成学习第二层结构et算法的超参数;
步骤f:新训练集训练et算法,预测测试集的输出结果。
与现有技术相比,本发明具有以下有益效果:
本发明根据i-v特性曲线、单二极管模型参数和环境参数设计具有代表性的故障特征,并采用斯皮尔曼相关系数法分析特征相关性和xgboost计算特征重要性进行特征选择,提高算法的运行效率;选择四种不同的机器学习模型,包括极端随机树、lightgbm、支持向量机和k近邻算法,采用网格搜索的方法选择模型的超参数,并通过集成学习stacking的方法将这四种模型融合成一个强分类器来判断光伏阵列故障类型。相较于单一机器学习算法,集成学习的方法能够进一步提高故障诊断的准确率和稳定性。
附图说明
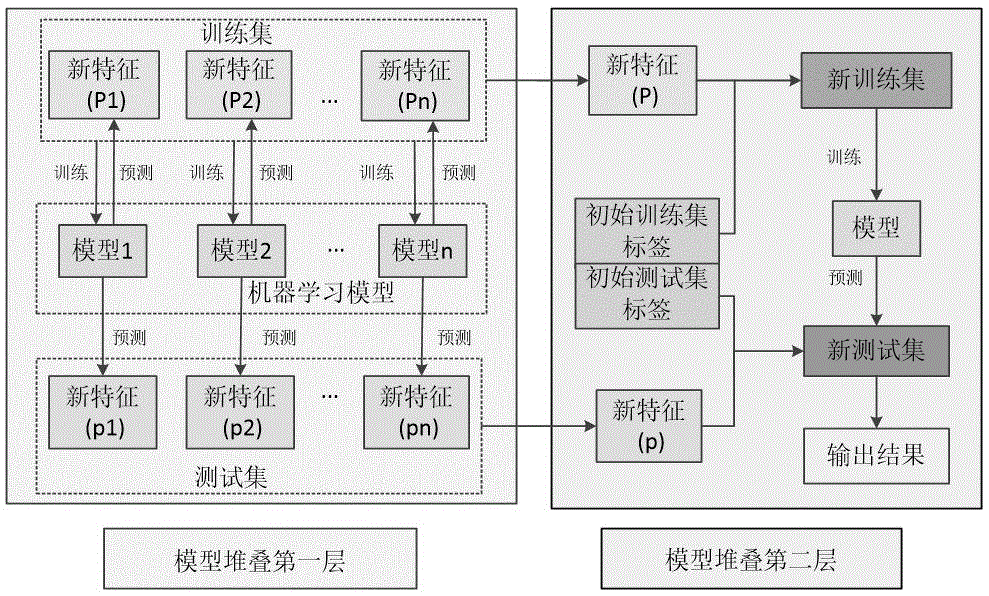
图1为本发明实施例的集成学习基本框图。
图2为本发明实施例的集成学习单模型算法流程图。
图3为本发明实施例的基于集成学习的光伏阵列故障诊断流程图。
图4为本发明实施例的单二极管模型的等效电路图。
图5(a)为本发明实施例的温度和辐照度传感器和i-v曲线采集仪。
图5(b)为本发明实施例的光伏阵列开路故障示意图。
图5(c)为本发明实施例的光伏阵列老化故障示意图。
图5(d)为本发明实施例的光伏阵列阴影故障示意图。
图5(e)为本发明实施例的光伏阵列短路故障示意图。
图6为本发明实施例的故障特征的斯皮尔曼相关系数图。
图7为本发明实施例的xgboost故障特征重要性分析图。
图8为本发明实施例的特征个数和故障诊断准确率的关系图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
本实施例提供一种基于集成学习的光伏阵列故障诊断方法,包括以下步骤:
步骤s1:获取光伏面板的实际i-v特性曲线信息和环境信息;
步骤s2:根据步骤s1获取的信息完成特征工程,获取光伏阵列故障特征;
步骤s3:对步骤s2获取的故障特征进行归一化处理,并对故障标签进行编码;
步骤s4:根据集成学习方法搭建故障诊断模型,并选择模型超参数,训练故障诊断模型;
步骤s5:根据训练好的模型预测光伏阵列的故障类型即将待测数据的特征(后文详述的故障特征)输入到训练好的模型,输出待测数据的故障类型。
在本实施例中,步骤s1所述i-v特性曲线信息包括:工作电压v和输出电流i;所述环境信息包括:阵列背板温度t和环境辐照度trr。
在本实施例中,通过特征构建和特征选择完成步骤s2中所述的特征工程。
在本实施例中,所述特征构建具体按照如下步骤建立:
步骤sa:将i-v特性曲线的电气参数作为故障特征集,包括:开路电压voc、短路电流isc、最大功率pm、最大功率电压vm和最大功率电流im;
步骤sb:根据i-v特性曲线计算曲线的几何特征添加到故障特征集,包括:ff、slop1、slop2、slop3、slop4、f1、f2,按如下方式获取:
步骤sc:根据光伏模型参数辨识算法提取光伏阵列单二极管模型的模型参数添加到故障特征集,包括:光电流iph、二极管反向饱和电流io、二极管理想化因子n、等效串联电阻rs、等效并联电阻rsh;
步骤sd:将阵列背板温度t和光照度trr添加到故障特征集。
在本实施例中,所述特征选择具体按照如下步骤建立:
步骤sa:选择斯皮尔曼相关系数法计算特征之间的相关性选择特征;
步骤sb:选择xgboost算法计算特征重要性选择特征。
在本实施例中,所述步骤s3具体按照如下步骤建立:
步骤1:选择零均值标准化方法对特征数据进行归一化处理,其计算公式如下:
其中,μ代表原始数据均值,δ代表原始数据标准差;
步骤2:选择序号编码对故障类型进行编码,故障类型包括:短路一块组件、短路两块组件、组件老化、组串老化、阴影一块组件、阴影两块组件以及正常工作状态共8种工况数据。
在本实施例中,步骤s4所述集成学习方法采用模型堆叠的stacking方法,选择极端随机树(et)、lightgbm(lgbm)、支持向量机(svm)和k-近邻算法(knn)作为模型堆叠结构的第一层基础算法,选择et作为第二层算法;模型超参数采用网格搜索进行确定。
在本实施例中,所述训练故障诊断模型的具体内容为:
步骤a:数据集的70%作为训练集,30%作为测试集;
数据集指用来训练和测试模型的许多条数据,可以是仿真i-v曲线数据集或者如后文图5所示方法采集的实测i-v曲线数据集,前述的故障特征集是每条数据的特征集合。
步骤b:网格搜索确定集成学习第一层结构极端随机树、lightgbm、支持向量机和k-近邻算法的超参数;
步骤c:选择5折交叉验证的方式用训练集分别训练极端随机树、lightgbm、支持向量机和k-近邻算法;每折交叉验证后四个模型都会预测验证集的故障标签,预测测试集故障的概率,交叉验证训练结束后计算概率平均值,概率最大的结果为测试集的故障标签;
步骤d:将步骤sc所述的预测结果作为数据的新特征,和原始数据标签结合构成新数据集;
步骤e:网格搜索确定集成学习第二层结构et算法的超参数;
步骤f:新训练集训练et算法,预测测试集的输出结果。
较佳的,本实施例故障诊断流程图如图3所示。根据图5所示设备和方法在实验室模拟光伏阵列故障,获取不同工况的i-v特性曲线数据,计算i-v特性曲线的电气参数、几何特征,并结合如图4所示的光伏阵列单二极管等效模型电路的模型参数,和光伏阵列的背板温度、环境辐照度设计故障特征。采用集成学习的模型堆叠方法搭建故障诊断模型,以et、lgbm、svm、knn作为模型堆叠第一层的算法,et作为第二层算法,用实测数据训练该模型。当需要通过待测数据判断阵列的工况时,就可以将待测数据输入到训练好的模型判断故障类型。具体按照如下步骤实现:
步骤s1:获取光伏面板的实际i-v特性曲线信息和环境信息;
步骤s2:根据步骤s1所述数据完成特征工程,获取光伏阵列故障特征;
步骤s3:对步骤s2所述特征数据进行归一化处理,并对故障标签进行编码;
步骤s4:根据集成学习方法搭建故障诊断模型,并选择模型超参数;
步骤s5:根据训练好的模型预测光伏阵列的故障类型,评估和优化光伏电站的工作状态。
在本实施例中,在步骤s1中,按图5方式获取实验数据,所述i-v特性曲线信息包括:工作电压(v)、输出电流(i);所述环境信息包括:阵列背板温度(t)、环境辐照度(trr)。
在本实施例中,特征构建方法具体按照如下步骤建立:
步骤s1:根据i-v特性曲线计算曲线的电气参数作为故障特征,包括:开路电压(voc)、短路电流(isc)、最大功率(pm)、最大功率电压(vm)和最大功率电流(im);
步骤s2:根据i-v特性曲线计算曲线的几何特征作为故障特征,包括:ff、slop1、slop2、slop3、slop4、f1、f2,按如下方式获取:
步骤s3:根据光伏模型参数辨识算法提取图4所示的光伏阵列单二极管模型的模型参数作为故障特征,包括:光电流(iph)、二极管反向饱和电流(io)、二极管理想化因子(n)、等效串联电阻(rs)、等效并联电阻(rsh)、算法的均方根误差(rmse);
步骤s4:将阵列背板温度(t)和光照度(trr)添加到故障特征集。
在本实施例中,特征选择方法具体按照如下步骤建立:
步骤s1:选择斯皮尔曼相关系数法计算特征之间的相关性,如图6所示,设置阈值为0.9,剔除相关性大于0.9的特征;
步骤s2:在皮尔曼相关系数法基础上,选择xgboost算法计算特征重要性,如图7所示;当特征数量大于9个时,准确率不在上升,如图8所示,因此选择特征重要性排名前9的特征。
在本实施例中,数据预处理具体按照如下步骤建立:
步骤s1:选择零均值标准化方法对特征数据进行归一化处理,其计算公式如下:
其中,μ代表原始数据均值,δ代表原始数据标准差;
步骤s2:选择序号编码对故障类型进行编码,故障类型包括:短路一块组件、短路两块组件、组件老化、组串老化、阴影一块组件、阴影两块组件以及正常工作状态共8种工况数据,分别按0-7方式编码。
在本实施例中,步骤s4所述集成学习方法采用模型堆叠的stacking方法,选择极端随机树(et)、lightgbm(lgbm)、支持向量机(svm)、k-近邻算法(knn)作为模型堆叠结构的第一层基础算法,选择et作为第二层算法;模型超参数采用网格搜索进行确定。
在本实施例中,训练基于集成学习的光伏阵列故障诊断模型,集成学习的基本框架如图1所示,具体按照如下步骤建立:
步骤s1:将数据集拆分成训练集、验证集和测试集;
步骤s2:网格搜索确定集成学习第一层结构et、lgbm、svm、knn算法的超参数;
步骤s3:选择交叉验证的方式用训练集分别训练et、lgbm、svm、knn,每个模型的训练方式如图2所示;每次训练后预测验证集的故障标签,预测测试集故障的概率,交叉验证训练结束后计算概率平均值,概率最大的结果为测试集的故障标签;
步骤s4:将步骤s3所述的预测结果作为数据的新特征,和原始数据标签结合构成新数据集;
步骤s5:网格搜索确定集成学习第二层结构et算法的超参数;
步骤s6:新训练集训练et算法,预测测试集的输出结果。
为了让本领域技术人员进一步了解本发明提出的技术方案,下面结合具体实例进行说明。
如表1所示,为本方法和四种机器学习算法在实验室采集的数据集上的故障诊断准确率
表1
可以看出,集成学习的故障诊断方法整体准确率高于所有的机器学习算法,其中对6种工况的诊断准确率最高。如表2所示为运行20次算法,每个模型故障诊断准确率的统计信息,其中计算准确率的方差可以评判算法的稳定性。
表2
可以看出,对于四种统计指标,集成学习的方法都能够获得最优的结果,表明该方法的稳定性最好。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!