本发明涉及数据处理领域,特别是涉及一种面向图数据库的数据管理与检索增强的方法。
背景技术:
图数据库作为知识图谱的存储引擎,提供了最优化的关系遍历和路径搜索类查询执行效率,支持丰富的数据语义描述且兼具灵活性,并提供了面向图分析和模式匹配、声明型的cypher查询语言,基于图数据库构建的知识库,可以实现具有高价值的智能化应用。
neo4j作为一种常用的图数据库,随着知识图谱技术的不断发展而应用愈加广泛。随着数据规模的不断增大,在多任务多知识库实例的情况下,难以有效地对图数据进行集中管理。此外,对大数据场景下,neo4j在关系检索上存在效率较低的问题,尤其在通过大规模实体属性进行路径检索时,该问题尤为明显。
elasticsearch是一个分布式、高扩展、高实时的搜索与数据分析引擎,不仅支持对海量规模的数据分布式索引与检索,还能提供数据聚合分析等。本发明采用了将图数据库与elasticsearch相结合的方法,充分发挥两者的技术特性,解决了多图数据库实例管理困难,大数据场景下,知识推理效率低的问题,实现了对图数据库的数据集中管理与检索效率提升的目的。
技术实现要素:
有鉴于此,本发明提出一种图数据库的数据管理与检索增强的方法。
为解决上述技术问题,本发明采用的一个技术方案是:提出一种图数据库的数据管理与检索增强的方法,其特征在于,包括以下步骤:
步骤1:原始数据加工与信息抽取:从原始数据中提取出实体、关系和属性,将所述实体、关系和属性存储到图数据库neo4j实例中;
步骤2:对实体、关系和属性进行数据校验,包括在语义层面通过算法模型进行校验,在数据层面上通过规则的方式进行校验;
步骤3:数据汇集:对存储在不同图数据库neo4j实例中的数据,通过实时数据同步的方式,将图数据库neo4j实例中的实体和属性同步到elasticsearch中;
步骤4:设置数据副本策略;
步骤5:基于elasticsearch的提供数据接口服务,通过所述数据接口获取到实体数据和属性数据,定位到不同类别的实体对象后,通过访问neo4j进行关系检索。
进一步的,所述原始数据为多源异构的,包括结构化数据、半结构化数据以及非结构化数据。
进一步的,所述结构化数据和半结构化数据采用自动化程序结合etl工具kettle进行信息抽取,非结构化数据采用算法模型进行信息抽取;
算法模型可使用实体抽取模型,关系抽取模型。
进一步的,所述数据校验为:对从结构化或非结构化数据中抽取出的实体词进行校验。
进一步的,所述在语义层面上对实体、关系和属性进行校验方式主要通过算法模型,如:实体融合、实体消歧;所述在数据层面上通过规则的方式进行校验,包括:采用正则表达式,对所抽取出的实体词进行数据校验。
进一步的,所述实时数据同步,包括:
s1.获取图数据库neo4j中的实体数据状态的时间戳;
s2.筛选出最新时间戳的实体id、关系id;
s3.根据所述实体id、关系id在elasticsearch中更新相应的实体数据和关系数据。
进一步的,所述数据副本策略,设置为3副本。
本发明提供的图数据库的数据管理与检索增强方法,搭建了一个从不同原始数据中抽取知识数据,创建neo4j图数据库到多个neo4j数据集成到elasticsearch进行统一数据管理,并基于elasticsearch为应用提供数据接口服务的全流程图数据管理与检索增强工具。
附图说明
图1为本发明实施例提供的一种面向图数据库的数据管理与检索增强方法的架构设计图。
图2为本发明实施例提供的一种面向图数据库的数据管理与检索增强方法的流程图。
图3为本发明实施例提供的一种面向图数据库的数据管理与检索增强方法的示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本申请涉及一种面向图数据库的数据管理与检索增强方法,包括以下步骤:
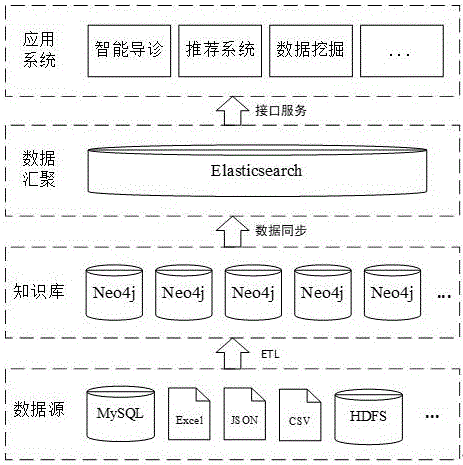
如图1所示,本发明的实施例的数据管理与检索增强方法的架构设计。
本发明在架构设计上主要包含了四个层面的内容,其中包括数据源层、知识库层、数据汇聚层与应用层。
结合图2和图3,本发明实施例的图数据库的数据管理与检索增强具体实施方式,如下:
在数据源层,图数据的来源多源异构的,主要是mysql数据库、excel文件、csv文件、json文件及hdfs分布式文件系统,针对不同的原始数据类型采用不同的数据加工与信息抽取方法。
在知识库层,主要是对各个neo4j图数据库进行数据监控,通过统计图数据库中实体数量,关系数量,实体属性与关系属性的数量等,及时发现知识数据的更新状况以及异常数据。
在数据汇聚层,采用了elasticsearch全文搜索引擎,将分散在各neo4j图数据库实例中的数据进行统一管理与应用,形成了一个“统一数据资源库”,具体步骤如下:
步骤1,原始数据加工与信息抽取。针对结构化、半结构化以及非结构化的数据,通过一系列自动化或半自动化的数据抽取、转换与加载(etl)方法以及数据校验,从原始数据中提取出知识要素,所述知识要素为实体、关系与属性,将其存储到相应的图数据库neo4j实例中。
例如:对于原始数据是mysql数据库的情况,mysql中一般存储的是基础数据,基础数据作为图数据的来源,以结构化形式存在,通过多表关联的方式,从基础数据中抽取图数据所需要的实体与关系数据,并将其作为中间结果数据存放在mysql数据库中。基于已抽取的中间结果数据,通过pymysql工具或者kettle工具导入到相应的图数据库neo4j实例中。
对于原始数据是excel文件、csv文件、json文件的情况,该数据文件中存放的是从非结构化原始文本中经过实体抽取模型,关系抽取模型所提取出三元组数据,通过xlrd、pandas、json工具将三元组存储到相应的neo4j数据库中。
对于原始数据是hdfs分布式文件系统的情况,通过使用已有的信息提取工具,提取出知识要素,将其存放在hdfs中,并通过hdfs工具将知识要素存储到neo4j中。
步骤2:数据校验:将来自不同原始数据的实体、关系和属性数据存储到neo4j过程中,需要对所述数据进行校验。数据校验主要是在语义层面与数据层面进行,语义层面主要通过算法模型进行校验,如针对同一个实体具有不同的表达的情况,需要进行实体融合;针对同名实体具有歧义的问题,需要进行实体消歧,如“近视”可以是疾病,也可以是症状。数据层面,主要通过正则表达式的方式进行规则校验,如实体词含有特殊字符,需要进行清洗操作。
将来自不同原始数据中提取的知识数据加载到对应neo4j后,需要对各个图数据库实例进行管理。
为了更好的了解各个neo4j图数据库实例中的数据情况,本发明中采用了知识数据可视化的方式,通过使用图浏览器以及关系查找工具,生动展示了实体与实体之间的关联。对于图数据库中的任意两个实体,通过设置实体间的最大路径深度,可展示出实体间的推理路径。
步骤3,数据汇聚。对存储在各图数据库neo4j实例中的数据,通过实时数据同步的方式,将各图数据库neo4j实例的实体和属性同步到elasticsearch中,通过elasticsearch作为统一数据资源库,来统一管理图数据库中的数据。
具体来说,本发明使用了python中的elasticsearch工具,通过获取各个图数据库的连接,遍历了数据库中实体及实体与实体之间的关系,按照不同的实体类型分别建立了索引。如在某医学图数据库中,存储了疾病、症状、科室等实体数据,以及实体间的关系数据,在elasticasearch中,则分别为疾病、症状、科室等建立索引,并将其他图数据库中具有相同实体类型的数据分别纳入对应的索引中,在数据集成的过程中,为了区分实体数据的来源,为每个数据打上了数据来源的标签,以及该数据在来源数据中的id。对于图数据库中的关系数据,则统一集成到同一个索引中进行存储,同时在存储时对数据进行了数据来源的区分。
为了能让elasticasearch更好的识别图数据库中的实体,本发明抽取了各图数据库中的实体名称,形成了一个专有字典,在elasticasearch的配置中将其引入,结合使用了ik分词器,在创建倒排索引时,实体名称字段采用了text数据类型并使用了ik_max_word模式,在实体检索的时候采用了ik_smart模式,其他索引字段包括data类型,long类型等。
进一步的,在步骤3中,实时数据同步采用基于时间戳的增量同步方式,主要针对元数据以及实例数据进行同步,其中元数据的同步主要是字段(属性)名称与字段类型,实例数据主要同步实例属性值。实时数据同步步骤如下:s1.获取图数据库neo4j中的实体数据状态的时间戳;s2.筛选出最新时间戳的实体id、关系id;s3.根据实体id、关系id到elasticsearch中更新相应的实体数据和关系数据。
步骤4,设置数据副本策略,将elasticsearch的number_of_shards参数设置为3,number_of_replicas设置为1,3个主分片和1个复制分片有效保证了数据的可靠性。
步骤5,数据服务。基于elasticsearch统一数据资源库为应用层提供restful数据接口服务,接口的目的在于实时检索各图数据库中的实体,为预测推理等应用提高检索效率。
具体来说,数据接口基于flask模块开发,提供了针对不同类别实体的实时精确检索与模糊检索的功能。在接口中定义了isexact参数,如果参数值为1,表示该接口使用的是精确检索,如果为0,则使用模糊检索。接口中还定义了cls参数,该参数代表实体类别,通过cls可以获取不同实体类别的实体。此外,接口中定义了item参数,该参数控制要检索的实体属性。对于接口服务产生的异常信息,通过日志的方式进行存储,以便快速并定位解决问题。
本发明提供的图数据库的数据管理与检索增强方法,实现了一个从不同原始数据中抽取知识数据到图数据库中,对多图数据库进行监控到将多个图数据中的数据集成到elasticsearch统一数据管理,并基于elasticsearch为应用提供数据服务接口的全流程图数据管理与检索增强的方法,elasticsearch作为统一数据资源库,分布式的特征保证了数据在存储时可横向灵活扩容,同时因为其具备对海量规模数据的分布式索引与检索的功能,实现了对图数据库的数据集中管理与检索效率提升的目的。
以上所述仅为本发明的实施例、并非因此限制本发明的专利范围、凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换、或直接或间接运用在其他相关的技术领域、均同理包括在本发明的专利保护范围内。