一种基于密度信息的高速撞击碎片重构方法
本发明涉及一种基于密度信息的高速撞击数值模拟碎片的重建方法,属于数值仿真技术领域。
背景技术:
随着现代航天器的发展,大量的人造卫星或者航天器被送到地球轨道,同时大量运载工具产生的喷射物和抛弃物、空间物体碰撞产生的碎片等留在太空中,导致太空垃圾逐渐增多。微流星体和空间碎片对航天器的安全造成了巨大的威胁。例如,长时间暴露的航天器外部有超过30000个直径大于0.3mm的陨石坑,都是由微流星体或轨道碎片撞击形成。太空中的空间碎片碰撞速度高达5~15km/s,即使是尺寸小的碎片,与航天器碰撞时也会对其结构造成严重破坏。因此在研制航天飞行器、人造卫星、洲际弹道导弹时,需要研究空间碎片或者陨石超高速碰撞引起的破坏效应。
空间碎片超高速撞击产生相关破坏效应的探究主要分为实验和数值模拟。其中,实验通常采用二级/三级轻气炮、电炮、磁驱动装置以及激光驱动装置等进行。实验研究让我们对超高速撞击产生的碎片云以及靶板损伤情况等有了基础的了解,也为数值模拟提供了对比的数据和图像,但目前的大部分实验技术至多只能将弹丸加速到8km/s,使进一步的研究难以开展,同时实验费用较为昂贵,也限制了其快速发展和应用。
数值模拟方法由于其本身具有的优势可有效克服上述技术问题,但通过数值方法模拟研究空间碎片超高速碰撞效应时,碎片云形貌的预测是当下的难点。在超高速撞击中,碎片云的形貌发展是碎裂、相变、以及计算方法准确性、加载条件精确性等多个方面的强耦合结果,任何一个物理概念的不准确都会导致碎片云的形貌与实际不符。因此通过数值模拟研究碎片云的形貌,即是对超高速撞击数值模拟过程中的各个关键因素进行探究。
碎片云形貌研究过程采用的数值模拟方法中,基于网格的方法如拉格朗日有限元法等存在着网格畸变导致计算无法进行的问题,而无网格方法由于没有网格依赖性,减少了因网格畸变引起的困难,对于高速碰撞这类大变形问题有较好的应用优势。但在使用无网格方法计算高速撞击实验,计算结果中节点无法生成撞击的碎片,导致无法得到真实碎片的大小和形状,不能具体观测碎片,阻碍通过数值模拟方法研究碎片云形状的发展。
技术实现要素:
本发明的目的在于提供一种基于密度信息的高速撞击碎片重构方法,获得真实的碎片分布情况。
本发明的技术方案如下:
基于密度信息的高速撞击碎片重构方法,其包括:对高速撞击数值模拟产生的粒子进行基于密度的聚类分析,根据聚类分析结果重构碎片并显示重构后的碎片。
根据本发明的一些优选实施方式,所述聚类分析需要的粒子相关信息包括但不限于:粒子空间坐标,粒子标识信息(id号)。
根据本发明的一些优选实施方式,所述聚类分析对于导入其他的粒子相关信息可以在聚类分析后根据粒子信息推得碎片的相关特征信息,如碎片等效半径,质量。
根据本发明的一些优选实施方式,所述聚类分析结果信息包括但不限于:碎片标识号,碎片包含的粒子的id号和数量、核心碎片粒子的id号及其空间坐标值、碎片的总数量及等效半径。
根据本发明的一些优选实施方式,聚类分析所需要的参数主要是划分簇时所使用的圆半径大小(eps),确定核心对象时周围点数目的阈值(min_samples)。
根据本发明的一些优选实施方式,所述基于密度的聚类分析通过dbcsan算法实现。
根据本发明的一些优选实施方式,根据聚类分析结果可通过可视化手段显示重构后的碎片,体现粒子在空间中的分簇情况。
根据本发明的一些优选实施方式,在可视化手段中包括过滤的过程,其中,过滤基于已得到的聚类结果信息。
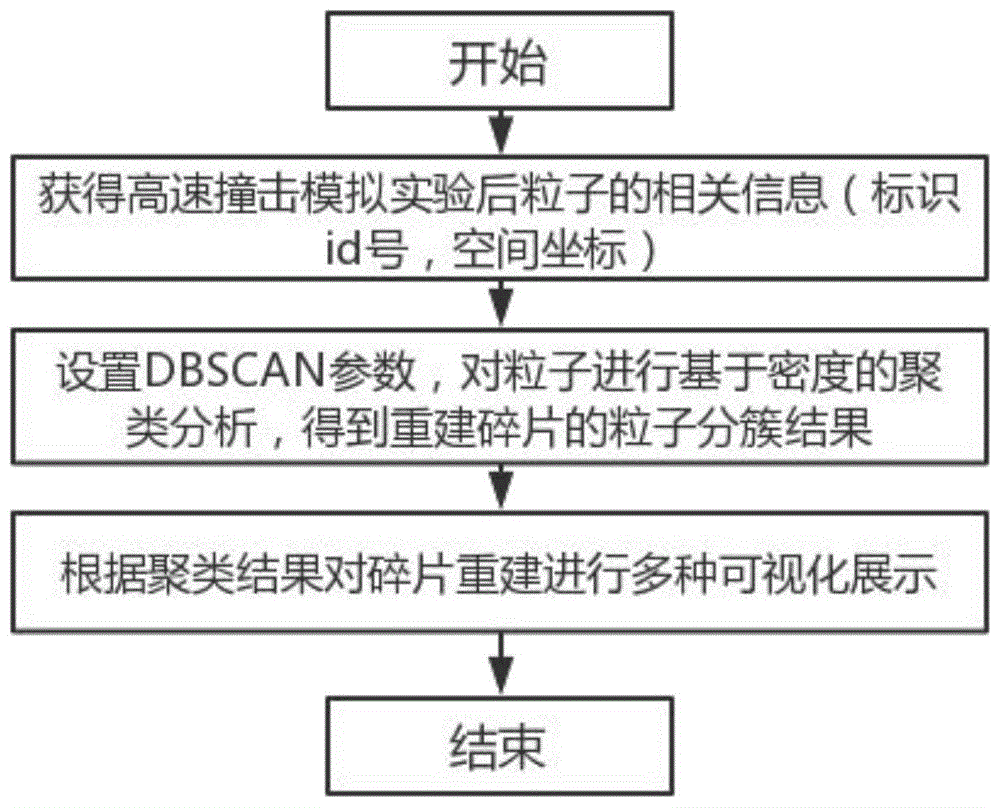
根据本发明的一些优选实施方式,所述模拟方法包括以下过程:
s1:获得高速撞击后粒子的相关信息;
s2:对粒子进行聚类分析,获得聚类分析结果重构碎片;
s3:根据聚类结果展示重构之后的碎片。
根据本发明的一些优选实施方式,所述步骤s2包括:
s21在进行聚类分析的系统中读取所述s1步骤粒子相关信息的文件。
s22通过dbscan算法进行聚类分析,获得聚类后的碎片相关信息。
根据本发明的一些优选实施方式,所述步骤s22包括:
s221设置划分簇时所使用的圆半径大小eps,确定核心对象时周围点数目的阈值min_samples;其中,eps的选择根据数值模拟中的粒子直径进行选择,min_samples的选择根据人为定义的每个碎片所需的聚集粒子的数量或对实验数据的反推。
s222基于dbscan算法,获得聚类分析结果,即每个碎片所属的粒子标识号,完成碎片重构。
本发明以高速撞击数值模拟后离散的粒子为分析对象,采用基于密度的聚类方法(density-basedspatialclusteringofapplicationwithnoise,dbscan)进行聚类分析,得到聚类分析后碎片中粒子的数量等相关信息,并通过可视化手段展示重构的碎片结果。实现超高速撞击数值模拟实验碎片云中的碎片可视化,帮助反应碎片真实情况,进一步为数值模拟的后续分析提供技术支持。
附图说明
图1为实施例1所述的流程示意图;
图2为实施例1所述的模拟结果文件格式;
图3为实施例1所述的用于聚类分析的格式文件;
图4为实施例1dbscan参数选择与sph粒子直径的关系;
图5为实施例1所述的根据现有实验确定dbscan参数的过程展示图;
图6为实施例1聚类分析结果输出文件;
图7为实施例1所述的对粒子进行聚类分析后的结果图;
图8为实施例1所述的在paraview中进行碎片过滤的最终效果图。
具体实施方式
以下结合实施例和附图对本发明进行详细描述,但需要理解的是,所述实施例和附图仅用于对本发明进行示例性的描述,而并不能对本发明的保护范围构成任何限制。所有包含在本发明的发明宗旨范围内的合理的变换和组合均落入本发明的保护范围。
根据本发明的技术方案,其中一种具体的实施方式包括:
s1:获得高速撞击后碎片元中各个粒子的相关信息。
其中,粒子相关信息从求解程序输出结果文件中提取得到,即有初始输入。
其中,空间坐标等相关信息的建立和求解问题时建立模型的坐标系相同。
具体的,其中相关信息包括但可不仅限于标识id号和空间坐标,如果除聚类分析外需要做进一步分析还可导出包括速度、质量、压力等相关粒子信息。
其中,对提取的相关信息进行整合,编写形成用于聚类分析的格式文件。
s2:对粒子进行聚类分析,获得聚类后的碎片相关信息。
其中,聚类后碎片最基础的相关信息包括碎片的个数,每个碎片由哪些粒子组成(可查看粒子id号),这些粒子包括了核心对象和非核心对象。
其中,碎片其他相关信息还可通过选择导入其他粒子信息进一步计算推导得到,具体的其它信息获得方式可如:
导入粒子信息时除了导入其空间坐标,还导入每个粒子所代表的空间域的半径,每个粒子所携带的质量,速度等(这些都是有限元计算程序中得到的结果),由此可以衍生出其他的碎片信息,如碎片等效半径(采用等体积法df3=ndp3计算得到),碎片的坐标(组成这个碎片的核心对象的坐标平均值),碎片的速度(组成这个碎片的核心对象的速度平均值),碎片的质量(所有组成碎片的粒子的质量之和),碎片的动量(组成这个碎片的粒子的动量之和)等。
具体的,其可进一步包括:
s21在进行聚类分析的系统中读取所述整合文件的信息。
s22通过dbscan方法进行聚类分析,获得聚类后的碎片相关信息。
该步骤所采用的dbcsan方法是一种比较有代表性的基于密度的聚类算法,与层次聚类方法不同,它将簇定义为密度相连点的最大集合,能够把具有足够高密度的区域划分为簇,并可在“噪声”的空间数据库中发现任意形状的聚类。
其中,步骤s21-s22可在任意编译环境中完成,进行文件读取和聚类分析。
其中,文件读取信息包括用于聚类分析的粒子的相关信息,其具体过程如下:
用数组分别读取粒子的空间坐标,id号,将粒子信息导入聚类分析系统中;
其中,聚类分析可进一步包括:
s221设置划分簇时所使用的圆半径大小eps,确定核心对象时周围点数目的阈值min_samples;
其中,eps的选择可根据数值模拟中的粒子直径进行选择,min_samples的选择可通过人为定义的每个碎片所需的聚集粒子的数量,也可通过对实验数据的反推。
其中,参数的选取是需要调试的,对于复现不同实验下的碎片需要根据其现有的实验数据对参数进行反推;若没有实验的情况下,需要人为地进行设定,可以不断调试参数达到一个满意的状态。
其中,若已有的实验数据多,需要对没有进行的工况进行数值仿真预测碎片,可以根据多组实验进行参数估计;如果实验数据少,可以根据一组实验大致估计参数,此时的参数能大致代表实验对碎片的一个定义。
s222基于dbscan算法,获得聚类后的碎片相关信息;
其可进一步包括:
基于设置的参数,通过dbscan方法对已经导入聚类分析系统的粒子信息进行分析计算,获得不同碎片的标签(label)及每个碎片所包含的粒子情况;
其中,标签在程序中是对碎片进行编号的统称,是聚类算法中的名词用法,没有涉及到碎片类型。
通过将除代表噪声点(标签为-1)外的其他每个标签对应的碎片的节点从系统中输出,并可通过计算得到每个碎片中的坐标和其他相关信息;
其中,碎片等效半径采用等体积法df3=ndp3(df为碎片的等效直径,dp为粒子直径)计算得到,碎片的坐标采用组成这个碎片的核心对象的空间坐标平均值计算得到,碎片的速度采用组成这个碎片的核心对象的速度平均值,碎片的质量采用所有组成这个碎片的粒子的质量计算累加和得到,碎片的动量采用所有组成这个碎片的粒子的动量计算累加和得到。
s3根据聚类结果展示重构之后的碎片;
其中,聚类结果为s2从聚类系统中得到的分析结果。
其中,展示可视化手段包括多种方法,
具体的,方法包括但不限于:
1)使用绘图工具通过颜色标记对碎片重构结果进行展示,用不同的颜色标记出不同的碎片,对碎片进行识别。
2)对源粒子进行过滤,在软件中形成碎片的可视化结果;。
具体的,过滤过程如下:
在后处理软件中导入有限元软件的计算结果(目前结果包含所有粒子(碎片粒子和噪声点)),通过插入步骤s2得到的聚类分析的结果,其中文件内容包括属于碎片的粒子是id号,通过比较计算结果的粒子id号和源文件中的粒子id号,留下聚类分析后的粒子,过滤掉不属于任何一个碎片的节点达到碎片的可视化过程。
实施例1
通过如附图1所示的流程对高速撞击后的碎片进行可视化模拟,其中:
高速撞击后碎片元中各个节点粒子的相关信息由高速撞击实验有限元计算软件获得的结果数据文件得到,即有粒子信息作为输入,粒子信息来自于无网格法计算软件,最后的结果得到的坐标系与一开始无网格法计算软件中几何建模的坐标系是一致的。如附图2为实施例1所用的计算结果文件格式。
从该结果数据文件中整理出碎片云粒子的id号和其空间坐标值形成格式文件用于聚类分析,其中节点id号与模型分网时的节点号(由软件分网时自动生成节点id号)相同,如附图3所示为实施例1整合的格式文件。
在python编译环境中导入该格式文件,进行文件读取和聚类分析。通过sklearn.cluster库中有dbscan算法对数据进行聚类分析。
dbscan方法的参数设置根据已经获取的高速撞击平板的实验结果进行,具体的参数选择如下:
将ε(邻域半径阈值)与粒子直径相联系。将ε选在[1d~2d)之间(其中d代表粒子直径),再根据实际情况选择minpts参数。如附图4dbscan参数选择与sph粒子直径的关系,此时的ε=1.1d,minpts=5。在这种情况下,minpts参数则决定我们认为至少5个粒子相连的状态可以称为是一个“碎片”。若没有实验的情况下,我们可以根据ε在[1d~2d)的具体取值估算在该区域内最多能有多少个粒子来得到minpts参数的上限,并通过调试参数到达一个理想的状态。
在有实验的情况下,我们可以根据一组实验结果来反推ε(邻域半径阈值)和minpts的取值。
例如在piekutowski等人的实验中,我们选取实验参数:撞击速度为5.45km/s,t/d=0.049的实验来探究ε(邻域半径阈值)和minpts的选择方式。该组实验得到的碎片平均尺寸是0.736mm,碎片数量为326。在实验中,碎片的大小和数量是通过激光拍照、对图片进行识别和分析获得的。聚类算法找到的聚集的sph粒子是不规则形状的,我们将其视为相同体积的球体,并将该球体的直径定义为碎片的大小。如下式所示:
df3=ndp3
其中df为碎片等效直径,也就是碎片尺寸;dp是一个粒子的直径,n是组成这个碎片的粒子数目。
粒子的平均直径是0.273mm。如附图5展示了选取不同的ε和minpts参数时,碎片尺寸的变化关系。其中ε(邻域半径阈值)的取值范围为[1d~2d),而minpts的取值为2~8(当minpts选取8以上的数值时,误差将越来越大)。可看出当ε在[1d~2d)范围内变动时,碎片尺寸和数目均在小范围内变化。而根据实验的碎片尺寸和碎片数目,我们取ε=0.4mm,minpts=3这组参数,此时的碎片尺寸和碎片数目误差总和最小。
对于这组参数而言,此时的ε是sph粒子直径的1.47倍,我们认为当至少3个sph粒子还相连的状态可以称为是一个“碎片”。
设置eps=0.4,min_samples=3参数值进行dbscan聚类分析,得到碎片重构结果如附图6所示,每一行的数字为碎片所属粒子的id号。
使用随机颜色表示其中核心粒子和噪声点(黑色),通过python的matplotlib.pyplot工具库生成聚类结果的展示图像,如附图7为实施例1的高速撞击实验实现碎片重构的标识图。
针对vtk的文件格式,其可通paraview中的threshold功能根据得到的聚类结果对节点进行过滤形成可视化结果过程,如附图8所示为所述的在paraview中碎片的最终效果图。
以上实施例仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例。凡属于本发明思路下的技术方案均属于本发明的保护范围。应该指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下的改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!