一种基于安全性评价的分层汇聚联邦学习方法
本发明属于联邦学习技术领域,具体涉及一种基于安全性评价的分层汇聚联邦学习方法。
背景技术:
自从互联网问世以来,人类便开启了信息时代的大门。随着网络科技的快速发展,基于互联网、物联网等技术的产品在人们的日常生活中越来越普及,应用也越来越广泛。因此,人类所产生的数据量更是以惊人的速度急剧增长。海量数据的价值在如今社会环境的大背景下正在变得越来越高,如何挖掘其中的价值已被研究多时。机器学习通过学习大量数据并不断地更新及修改其模型中的参数,以实现对后续数据的判断或预测。近年来,移动设备配备了越来越先进的传感器和计算功能。结合机器学习的进步,这为更多高级功能的应用(例如用于医学目的和车载网络)提供了无数可能性。但在传统的场景下,训练计算模型的企业或机构需要收集、存储、处理海量的相关数据。而这对其网络、存储和计算能力都提出了较高的要求,训练成本相对较高。并且在数据传输与共享的过程中,会遇到以下几个关键性问题:“数据孤岛”现象激增、安全法规愈发严格、数据存储能力满足不了实际应用等。联邦学习(federatedlearning简称为fl)就是为了解决传统数据共享技术难以得到满足等问题所诞生的一项全新的技术,因此近些年来联邦学习备受关注。
在联邦学习的过程中,参与训练的节点使用自己本地的数据集来训练服务器所提供的训练模型;之后参与训练节点将本地训练出的子模型发送到中心服务器;服务器在汇集众多子模型后对其进行聚合得到新的全局模型。由于在整个学习过程中不需要隐私数据的传输,所以联邦学习可以在移动边缘网络上启用协作训练或深度学习来完成训练任务的同时保护数据的安全。但是由于移动边缘网络规模庞大且繁杂,学习过程中涉及到众多质量与稳定性不同的边缘设备。这对通信成本、安全隐私和资源分配等方面都有相应的要求,从而对联邦学习的广泛普及带来了的一定的困难。使用区块链来替代联邦学习过程中的中心节点,利用区块链去信任的特点来克服中心节点可能造成的隐私泄露和单点故障的弱点。但克服“搭便车攻击”与“模型中毒攻击”会造成了算力浪费的问题并且增加了整个训练过程的通信成本。
技术实现要素:
本发明的目的在于针对基于区块链的联邦学习的过程中验证各节点所造成的通信成本过高的问题,提供在保证节点安全性的基础上降低训练的通信成本的一种基于安全性评价的分层汇聚联邦学习方法。
本发明的目的通过如下技术方案来实现:包括以下步骤:
步骤1:用户向平台提出注册请求,所述的用户包括请求者和工作者;管理员根据用户的请求来注册用户,注册用户需要给出其用于接收任务及其奖励的以太网地址;
步骤2:注册完成后,请求者通过智能合约发布联邦学习训练任务;
所述的训练任务包括训练模型的描述、安全性评价指数s、用于模型更新的轮数n、任务开始时间、每轮工人数k′、每轮工人的总奖励r、总奖励的存款d;且d>r×n;
步骤3:请求者发布任务后,事件通知将通过以太坊的事件处理功能发送给所有注册的工作者,每个工作者决定是否参加此任务;如果工作者决定参加此任务,则在训练任务开始时间之前调用智能合约;
步骤4:任务申请期结束后,请求者获取加入训练任务t的工作者集合wt,且不告知工作者用于模型更新的轮数n;请求者将联邦学习模型参数初始化为ω0并提交到区块链中;
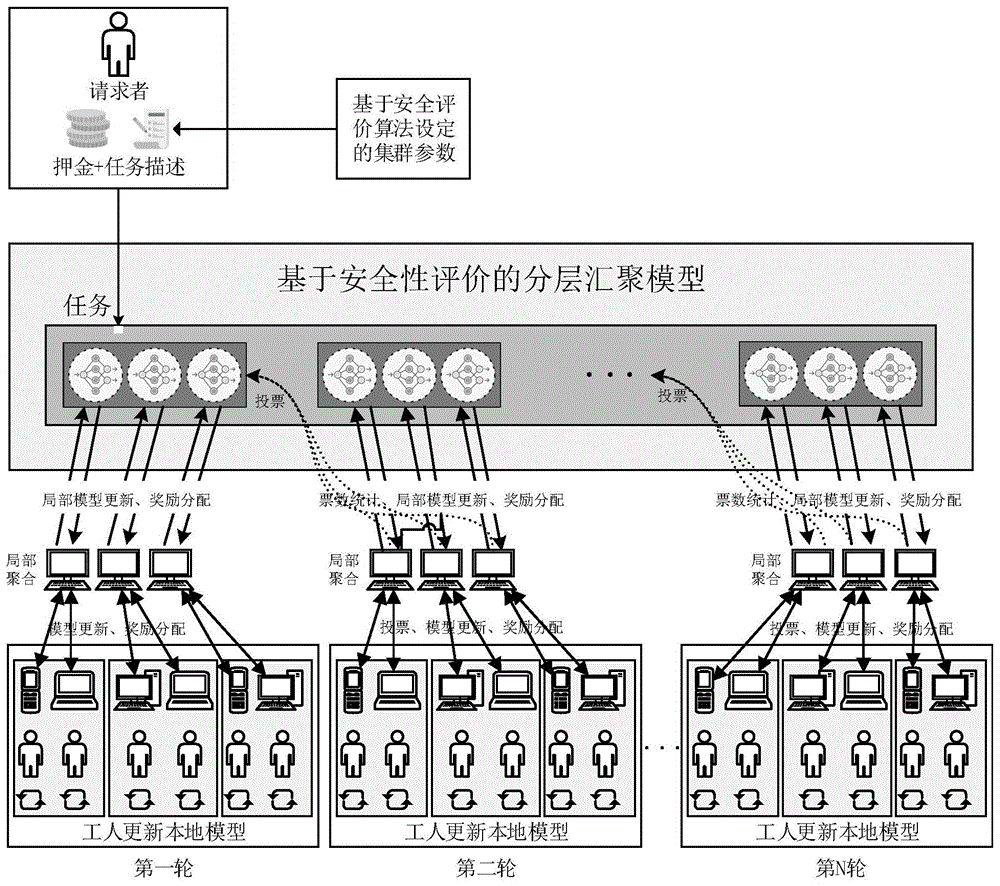
步骤5:在任务的模型训练开始后,智能合约从集合wt中随机选择k′个工作者,并根据安全性评价算法计算出每个集群中工作者的个数以及集群个数;每个工作者从区块链上获得上一轮各个集群的局部聚合模型参数并进行验证和投票,然后根据所选择的顶级模型计算出用于模型更新的全局模型;最后每个工作者根据本地数据集进行训练得出本轮子模型并提交给集群的区块链共识节点,共识节点将该集群的所有工作者的子模型按照平均聚合算法进行局部聚合得到该集群的局部模型参数并与各个节点的投票结果一并提交上链;
步骤6:根据各集群所得票数进行奖励分配;
在模型更新的提交阶段,第e轮中的每个工作者都对前g个局部模型投了赞成票;基于合计的投票,智能合约计算第e-1轮中各集群的所得票数;基于投票数的结果,奖励按r1≥r2≥…≥rk≥0分配给各个集群;获得最多票数的集群获得r1的奖励,获得票数第二的集群获得r2的奖励,依此类推;每个集群根据各自获得的奖励按照各集群中子节点参与训练的数据量进行利润分配。每一轮的总奖励固定为r,各集群利润关系为:
步骤7:模型更新和奖励分配重复n-1次后,将最后一轮任务中的奖励平均分配给所有参与训练的工作者。
本发明的有益效果在于:
本发明针对基于区块链的联邦学习的过程中验证各节点所造成的通信成本过高的问题,提供了一种基于安全性评价的分层汇聚联邦学习方法。本发明通过研究针对无用或恶意节点的验证机制及其安全性与通信成本,结合竞争的投票验证方法与聚合算法,提供了在联邦学习过程中的双层聚合模型。本发明在保证节点安全性的基础上降低训练的通信成本,可应用于基于区块链的架构下带有安全评估功能的分层汇聚联邦学习中。
附图说明
图1是本发明的架构图。
图2是本发明中模型更新算法的伪代码图。
图3是通信成本节省与安全值关系表。
具体实施方式
下面结合附图对本发明做进一步描述。
本发明的目的在于针对基于区块链的联邦学习的过程中验证各节点所造成的通信成本过高的问题,提供在保证节点安全性的基础上降低训练的通信成本的一种基于安全性评价的分层汇聚联邦学习方法。本发明可应用于基于区块链的架构下带有安全评估功能的分层汇聚联邦学习中。本发明包括以下步骤:
(1)用户注册。所有参与的用户,即请求者和工作者,必须向平台进行注册。
(2)任务发布。任何注册为请求者的参与者都可以通过智能合约发布联邦学习的训练任务。
(3)任务加入。请求者发布任务后,事件通知将通过以太坊的事件处理功能发送给所有注册的工作人员。然后,每个工作人员决定是否参加此任务。
(4)任务开始。任务申请期结束后,请求者根据加入任务t的一组工作人员wt选择用于模型更新的轮数n和每轮参与的工作人员个数k′。
(5)模型更新。在任务的模型训练开始后,每一轮的工作人员k都是从在智能合约中注册任务t的全部工作人员中随机选择的。然后根据安全性评价算法计算出每个集群中工作人员的个数以及集群个数进行投票和训练。
(6)奖励分配。根据各集群所得票数进行奖励分配。
(7)任务完成。模型更新和奖励分配重复n-1次后,最后一轮奖励被参与训练的节点平均分配。
本发明在针对联邦学习过程中的节点安全性验证所导致通信成本增加的问题,提出面向联邦学习的区块链架构优化方法。通过研究针对无用或恶意节点的验证机制,及其安全性与通信成本。然后结合竞争的投票验证方法与聚合算法,提出在联邦学习过程中的双层聚合模型。最后通过实验的对比分析,验证所提出的模型有效地降低了在基于区块链的联邦学习过程中节点验证的通信成本并保证了联邦学习过程中各个子结点的安全性。减少的通信比例如图3中的表格所示。
在进行安全性与通信成本分析前,首先对基于竞争性的模型更新方法(iabfl)进行介绍。这是一种在参与者采取合理行动的情况下实现预期目标的经济方法。关键思想是为联邦学习引入重复竞争,以使任何理性工作者都遵循协议并最大化他们的利润。在特定回合中选择的每个工作人员都会选择上一轮工作人员提交的顶级更新模型,并使用它们来更新自己的模型。在该模型架构中,假设每轮有n个参与训练的工作人员,在网络中传输单个模型参数所消耗的通信量为t。首先,n个参与训练的工作人员向区块提交本地模型并将链上其他所有节点的子模型同步到自身,此过程需要消耗c1的数据通信量,如公式(1)。
c1=n×(n-1)×t(1)
假设单条的投票所消耗的数据通信量为1,则n个参与训练的工作人员在链上完成投票并同步需要c2的数据通信量,如公式(2)。
c2=n×(n-1)(2)
定义iabfl方案中的模型架构中n个工作人员完成一轮训练所消耗的数据通信量为cpre,如公式(3)。
cpre=c1+c2=n×(n-1)×t+n×(n-1)(3)
在公式(3)中可以看出联邦学习任务的通信成本会随着结点的数量剧增,因此提出了一种具有验证机制设计的基于安全性评价的双层聚合模型。该模型背后的关键思想是通过竞争机制使得无用或恶意节点无法获得回报,并通过双层聚合机制减少验证模型的数量以降低通信成本。如图1所示。在特定回合中先将全体参与训练的节点分为多个小集群,一个小集群中的若干个节点的子模型先局部聚合出一个局部模型,每个子节点都会选择上一轮小集群提交的前k个模型更新,并根据这些更新来更新自己的模型。上一轮对工人的奖励取决于投票结果。下一轮的工人仍然无法产生恶意模型,因为他们的模型也被下一轮的工人竞争和投票。
假设系统中存在管理员、请求者、工作者和共识节点四种角色。管理员的作用是在公共区块链上部署一系列智能合约,例如以太坊,并根据请求将请求者和工作人员注册到平台。假设参与者知道如何通过论坛或网站访问智能合约的位置。请求者可能既没有用于训练的数据,也没有用于训练深度学习模型的设备。而工作者需要既有用于训练的数据,也有用于训练深度学习模型的设备。任何类型的数据都可以在这个平台上处理,例如图像、文本和音频。为任务t输入工人i的数据集。因为接下来都是针对特定的任务t,所以将下标t省略。假设工作人员为特定任务拥有的数据集是独立且同分布的。这种假设是自然的,因为请求者为特定的任务提交一个模型,例如用于在图片中识别猫的深度学习模型,会要求只有拥有特定于该任务的数据集的工作者才可以加入。
平台由几个程序组成;用户注册、任务发布、任务加入、任务开始、模型更新、奖励分配和任务完成。在本发明中使用以太坊作为区块链,因为它是支持智能合同的最流行的区块链之一。但是本发明的系统可以在支持加密货币和智能合约的任何其他公共区块链上实现。
1)用户注册。所有参与的用户,即请求者和工作者,必须向平台进行注册。管理员需要根据用户的请求来注册用户。管理员注册一个参与者需要每个参与用户必须给出其用于接收任务及其奖励的以太网地址以及是否注册为请求者和/或工作者。注册完成后,请求者可以在区块链上发布联邦学习训练任务,工作人员可以加入训练任务进行模型更新以获得相应的奖励。
2)任务发布。任何注册为请求者的参与者都可以通过智能合约发布联邦学习训练任务。请求者必须指定:
(1)模型描述,例如损失函数、数据格式、学习率、层数、单位数和激活函数;
(2)参数,例如该任务的训练期限,安全性评价指数s、开始时间t、每轮工人数k′、每轮工人的总奖励r;
(3)总奖励的存款d=r×n。
3)任务加入。请求者发布任务后,事件通知将通过以太坊的事件处理功能发送给所有注册的工作人员。然后,每个工作人员决定是否参加此任务。如果工作人员决定加入,则应在训练任务开始时间之前调用智能合约。根据要求,智能合约仅在调用方被注册为工作者时才可以调用,否则将中止代码执行。从代码实现的角度来讲,工作人员的以太坊地址被存储在一个数组中。
4)任务开始。任务申请期结束后,请求者根据加入任务t的一组工作人员wt选择用于模型更新的轮数n和每轮参与的工作人员个数k′。但是请求者不应该事先向工作人员透露用于模型更新的轮数n,而需要在n轮结束时向工作人员表明,这样做的原因会在后续进行详细的解释。此外,请求者需将联邦学习模型参数初始化为ω0并提交到区块链中。请求者可以使用任何算法来进行模型的初始化。
5)模型更新。在任务的模型训练开始后,每一轮的工作人员k都是从在智能合约中注册任务t的全部工作人员中随机选择的。然后根据安全性评价算法计算出每个集群中工作人员的个数以及集群个数,该算法在接下来的文章中会进行详尽的说明。之后每个工作人员从区块链上获得上一轮各个集群的局部聚合模型参数并进行验证并投票,然后根据所选择的顶级模型计算出用于模型更新的全局模型。最后每个工作人员根据本地数据集进行训练得出本轮子模型并提交给集群的区块链共识节点,共识节点将该集群的所有工作人员的子模型按照平均聚合算法进行局部聚合得到该集群的局部模型参数并与各个节点的投票结果一并提交上链。模型更新的算法如图2所示。算法详解:在算法1-6行中,主要任务是选取最好的a个顶级模型进行投票并提供给之后的模型聚合使用。具体操作是:如果不是训练任务开始的第一轮,则每个工作人员使用本地数据集对上一轮的g各集群的局部聚合模型进行验证,选出a个它认为最好的模型进行投票,否则略过此步骤。在算法7-11行中,作用是计算本轮训练的基础全局模型。具体操作是:如果是训练任务开始的第一轮,则使用请求者提供的初始化参数ω0作为全局模型的参数,否则将算法1-6行中选取出的a个局部模型进行平均聚合得到全局模型。在算法12-18行中,每个工作者根据算法7-11行中计算出的全局模型使用本地数据集进行本地模型训练,训练出该轮的子模型参数。值得注意的是,本地训练一共e轮,每轮的数据集并不是本地的全部数据集,而是在训练之前先将数据集随机分成b批,每轮本地训练使用其中一批。
6)奖励分配。如模型更新中的算法所示,在模型更新的提交阶段,第e轮中的每个工作人员都对前g个局部模型投了赞成票(对一个模型只能投一票)。基于合计的投票,智能合约计算第e-1轮中各集群的所得票数。基于投票数的结果,奖励按r1≥r2≥…≥rk≥0分配给各个集群。因此,获得最多票数的集群获得r1的奖励,获得票数第二的集群获得r2的奖励,依此类推。每个集群根据各自获得的奖励按照各集群中子节点参与训练的数据量进行利润分配。
每一轮的总奖励固定为r,各集群利润关系为公式(4)。
7)任务完成。模型更新和奖励分配重复n-1次后。由于下一轮没有训练任务以及工作人员,因此无法对最后一轮训练n中的工作人员完成的模型更新进行投票。因此将最后一轮任务中的奖励平均分配给所有参与训练的工作人员。但是,这产生了一个可能降低了工作人员正确工作动力的问题。如果工作人员知道他们被选中参与最后一轮中的训练任务,则只需任意发送以前的模型更新之一便可以得到一定奖励。如果这种情况发生,则前几轮工作人员诚实计算的动机同样会降低,因为他们的模型更新可能不会在下一轮中得到工作人员的正确投票。然后,再以前的工作人员和他们以前的工作人员之间也会发生同样的事情。因此,为了使模型得到有效的训练,最后的工作人员必须不知道他们是否处于最后一轮的训练。所以请求者需要在第n轮结束后向所有工作人员揭示n的信息。为了不让工作人员从剩余的存款中猜测出n的数值,请求者应该在任务开始之前提供比实际总奖励n×r大的存款d。同时在工作人员完成所有任务后将其多余的存款退回给请求者,所以请求者不会丢失其余的存款。
安全性评价指数:
在该模型架构中,假设每轮有n个参与训练的工作人员,g个连接到区块链上的共识节点,在网络中传输单个模型参数所消耗的通信量为t。首先n个参与训练的工作人员从区块链上获取上一轮各个集群的局部聚合的模型参数,此过程需要消耗c1的数据通信量,如公式(5)。
c1=n×g×t(5)
之后每个工作人员更新本地模型并将训练出的模型参数以及自身投票结果提交给它所属集群的共识节点,此过程需要消耗c2的数据通信量,如公式(6)。
c2=n×(t+1)(6)
最后g个共识节点将该集群中的子节点模型聚合成局部模型,然后向区块提交该集群的局部模型及投票结果并将链上其他所有共识节点的局部模型同步到本地,此过程需要c3的数据通信量,如公式(7);
c3=g×(g-1)×(t+1)(7)
定义本发明的模型架构中n个工作人员完成一轮训练所消耗的数据通信量为cstep,如公式(8)。
根据之前的通信成本分析可知,iabfl的方案中单轮训练的数据通信量为cpre,这里给出几个定义:
csave为本发明所提出算法的单轮训练的数据通信量比iabfl的方案中单轮训练的数据通信量所减少的部分,如公式(9)。
csave=cpre-cmod=n2t-nt+n2-n-bnt-b2t+bt+n-b2+b(9)
设rsave是节约系数,为节约的数据通信量除以传输单个模型所消耗的通信量,如公式(10)。
定义改进后模型的安全值为csafe,定义csafe的计算公式如(11)所示。
csafe=(s+1)×(g3+g/n)(11)
其中定义s∈[0,10]为安全值,由发布任务的请求者自行设定。
定义本发明所提出模型的安全系数为rsafe,计算公式如(12)。
定义θ为本模型的整体均衡系数,θ的计算公式如(13)所示。
定义,当θ=1时模型在节约通信消耗与模型安全性之间处于一个相对平衡的状态;当θ>1时偏重于节省整个联邦学习架构的通信成本;θ<1时偏重于注重整个联邦学习架构的安全性。具体取值可由请求者在训练任务发布时进行个性化调整,本发明建议取平衡状态θ=1即可。
当θ=1时,rsave=rsafe,计算公式如(14)。
计算得到公式(15)。
根据公式(15)得到关系表,如图3。可以看出,即使安全值的取值最小即设定系统安全等级最高时即可节省约25%的通信成本,当安全值s≥3时即可节省约超过50%的通信成本。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!