一种基于多级缓存的企业级高并发鉴权控制方法与流程
本发明涉及互联网教育技术领域,尤其是涉及一种基于多级缓存的企业级高并发鉴权控制方法。
背景技术:
计算机技术和网络技术的快速发展,正以极快的速度改变着我们的生活、工作和学习方式,而且对当前的各大传统行业巨头也产生着重要的影响。目前教育机构的线上教育中,通过计算机和网络技术进行在线观看直播、录播视频、考试等已经是较为普遍的现象。但是面对上亿的学员的高并发访问与鉴权,是否能实现更高质量与更好的稳定性,决定了企业互联网教务产品的用户体验与系统质量。
但是在这种更加高效的学习体验的需求下,一个企业级的系统服务通常面临着高并发下服务并不可用的窘境。如果同一时间开启多场直播,那么每场直播在各种维度下的业务鉴权情况将错综复杂,包括学员是否有权限进入直播间、进入哪一场次直播间、以及拥有直播间哪些操作权限。如果实时超长链路的查询鉴权,这将对整个企业系统造成巨大的稳定性压力。不仅耗时巨大,而且并发吞吐量也会大大折扣,不堪压力下整个线上直播系统将陷入瘫痪和宕机。
因此鉴权方法或系统的高效和稳定性、可用性、精准性、实时性成为了目前需要解决的核心技术问题。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的高并发环境下系统鉴权稳定性和精准性较差的缺陷而提供一种基于多级缓存的企业级高并发鉴权控制方法。
本发明的目的可以通过以下技术方案来实现:
一种基于多级缓存的企业级高并发鉴权控制方法,具体包括以下步骤:
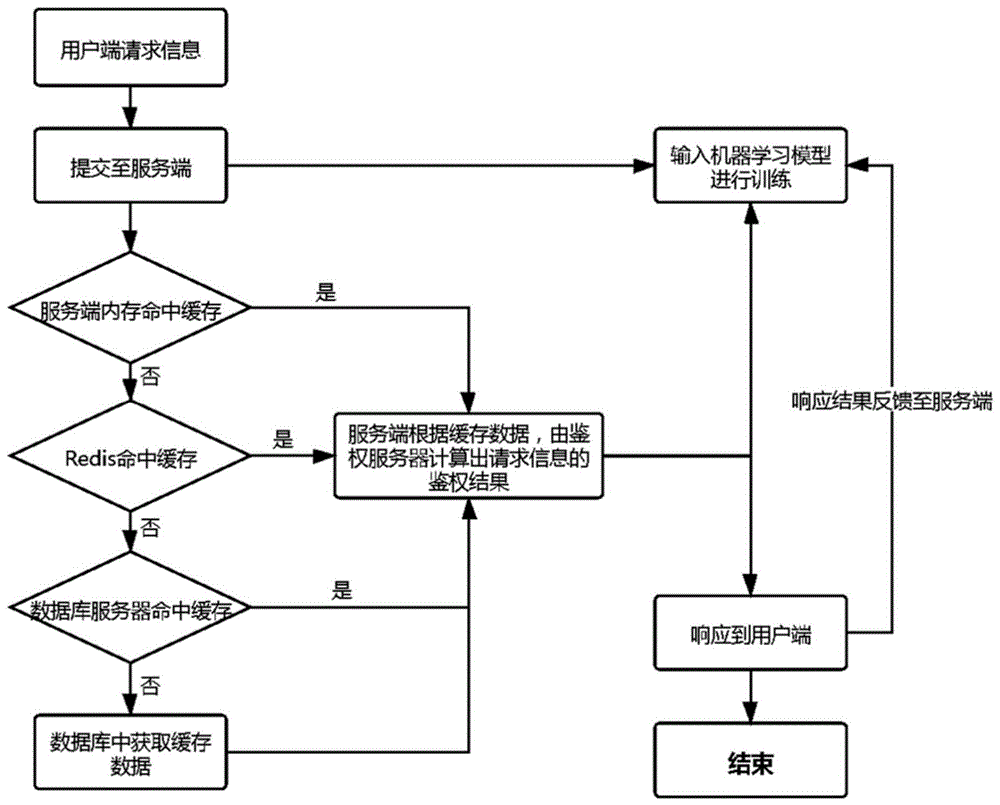
s1、获取用户端的请求信息并发送到服务端;
s2、服务端根据所述请求信息,按照优先级由高到低的顺序,从多级缓存中读取所需的缓存数据;
s3、服务端根据缓存数据,由鉴权服务器计算出请求信息的鉴权结果,并将所述鉴权结果发送回用户端;
s4、用户端根据所述鉴权结果得到权限响应,并就响应结果反馈到服务端。
所述步骤s1中用户端的请求信息包括用户信息、设备信息和授权后的请求地址信息。
所述步骤s2中多级缓存包括服务端的内存缓存、redis分布式缓存和数据库服务器缓存。
进一步地,所述多级缓存按照优先级由高到低进行排序的顺序为服务端的内存缓存、redis分布式缓存、数据库服务器缓存和数据库中的数据。
进一步地,所述redis分布式缓存的缓存数据中包括所述请求信息对应的业务场景属性信息。
所述步骤s4中权限响应的类型包括进入下一个操作的权限和可操作页面的权限。
所述步骤s4中还包括将鉴权结果中对应的缓存数据保留在用户端,以供用户端做初步鉴权使用。
所述步骤s2中还包括服务端将用户端的请求信息输入到机器学习模型中进行训练,生成训练任务,对训练任务进行解析得到训练任务参数。
进一步地,所述服务端在将用户端的请求信息输入到机器学习模型之前,对请求信息进行整合分析。
进一步地,所述步骤s3中还包括将鉴权结果输入机器学习模型进行训练。
进一步地,所述步骤s4还包括将用户端反馈的响应结果输入到机器学习模型进行训练,加快机器学习模型的训练速度,循环多维度学习用户端的鉴权路径以涉及业务的权重耦合度。
所述服务端将机器学习模型的训练结果,依次处理更新到多级缓存中,供下一次鉴权使用。
与现有技术相比,本发明具有以下有益效果:
1.本发明将用户端所需的信息通过多级缓存进行存储,在需要时通过调用缓存数据,由鉴权服务器计算出请求信息的鉴权结果,提高了高并发环境下系统鉴权的稳定性,同时灵活的多级缓存数据,匹配更加准确的加权权重与路径,使得服务端的鉴权结果更加高效精准。
2.本发明服务端通过各种机器学习模型,根据用户端的请求信息训练各种业务场景下的鉴权模型,得到更丰富、更全面的用户维度的鉴权画像。
3.本发明支持互联网在线教育下的业务鉴权需要,适用于全范围内的业务鉴权,丰富的鉴权维度与鉴权方式,支持不通权重的复杂场景下的业务鉴权。
4.本发明服务端采用了多种容错机制、缓存服务、消息队列等方式,避免了鉴权服务出现不可用的情况,实现了一个稳定、高可用的系统。
附图说明
图1为本发明的流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例
如图1所示,一种基于多级缓存的企业级高并发鉴权控制方法,能够抗千万级流量下,给到稳定高效、精准的企业级鉴权方法或系统,具体包括以下步骤:
s1、获取用户端的请求信息并发送到服务端;
s2、服务端根据请求信息,按照优先级由高到低的顺序,从多级缓存中读取所需的缓存数据;
s3、服务端根据缓存数据,由鉴权服务器计算出请求信息的鉴权结果,并将鉴权结果发送回用户端;
s4、用户端根据鉴权结果得到权限响应,并就响应结果反馈到服务端。
步骤s1中用户端的请求信息包括用户信息、设备信息和授权后的请求地址信息。
本实施例中,步骤s1中用户端会先根据用户端的缓存数据,梳理整合成有用数据,然后进行一轮简单的鉴权判断,再将请求信息发送到服务端。
本实施例中,用户端与服务端之间采用即时通讯链路,提高了用户的体验。
步骤s2中多级缓存包括服务端的内存缓存、redis分布式缓存和数据库服务器缓存。
多级缓存按照优先级由高到低进行排序的顺序为服务端的内存缓存、redis分布式缓存、数据库服务器缓存和数据库中的数据。
redis分布式缓存的缓存数据中包括请求信息对应的业务场景属性信息。
本实施例中,首先从服务端的内存缓存中获取鉴权信息,判断是否命中缓存,若否则继续从redis分布式缓存中获取机器学习的结果,判断是否命中缓存,若否则从数据库服务器缓存中获取权限信息,若否则最后从数据库中获取缓存数据,若命中缓存则服务端根据缓存数据,由鉴权服务器计算出请求信息的鉴权结果。
本实施例中,服务端若需要分布式计算,则将发送消息到消息队列中。
步骤s4中权限响应的类型包括进入下一个操作的权限和可操作页面的权限。
步骤s4中还包括将鉴权结果中对应的缓存数据保留在用户端,以供用户端做初步鉴权使用。
步骤s2中还包括服务端将用户端的请求信息输入到机器学习模型中进行训练,生成训练任务,对训练任务进行解析得到训练任务参数。
本实施例中,服务端在后续的训练中进行分场景训练,提升模型的准确性,更好的模型的识别场景。
服务端在将用户端的请求信息输入到机器学习模型之前,对请求信息进行整合分析。
步骤s3中还包括将鉴权结果输入机器学习模型进行训练。
步骤s4还包括将用户端反馈的响应结果输入到机器学习模型进行训练,加快机器学习模型的训练速度,循环多维度学习用户端的鉴权路径以涉及业务的权重耦合度,形成闭环机器学习的模型训练,得到更精准的训练鉴权模型。
服务端将机器学习模型的训练结果,依次处理更新到多级缓存中,供下一次鉴权使用。
具体实施时,服务器端根据用户端输入的信息,通过先进先出队列、优先队列、即时通讯技术,实时的传输消息。并且通过知识图谱、机器学习算法将鉴权模型训练的更加智能、全面,通过逐级缓存,提高了服务的稳定性、精准性、实时性,提高了用户学习满意度、体验感。
此外,需要说明的是,本说明书中所描述的具体实施例,所取名称可以不同,本说明书中所描述的以上内容仅仅是对本发明结构所做的举例说明。凡依据本发明构思的构造、特征及原理所做的等效变化或者简单变化,均包括于本发明的保护范围内。本发明所属技术领域的技术人员可以对所描述的具体实例做各种各样的修改或补充或采用类似的方法,只要不偏离本发明的结构或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!