基于缺陷分析的图像识别软件测试数据增强方法及装置
1.本发明属于智能软件的测试技术领域,具体涉及一种基于缺陷分析的图像识别软件测试数据增强方法及装置。
背景技术:
2.随着人工智能技术的不断发展,深度学习近年来被广泛应用于各种借助机器智能提高效率的行业,也包括自动驾驶、医疗诊断、飞行器防碰撞系统等安全攸关领域,例如,以图像识别等为代表的智能软件已经在自动驾驶系统领域得到了初步应用。然而,这类智能软件在快速发展的同时,缺陷问题也日益显著。缺陷是软件质量的对立面,威胁着软件质量,也影响产品的商业价值。
3.软件测试是发现软件错误,提高质量的关键手段之一。智能软件在传统软件的基础上融入了智能功能,给测试任务带来了问题与挑战,同时也提出了较大的市场需要和研究需求。由于大数据技术和各种机器学习模型的广泛使用,智能软件具有不确定性和概率性、预测应用场景的复杂性和困难性。以智能化的图像识别软件为例,当前针对图像识别软件测试面临的主要困境包括:
4.(1)软件版本更新演化频繁,对于测评机构而言,缺乏足够的测试数据,部分测试数据还依赖于研制方的训练数据,导致缺陷发现能力不高,难以适应智能软件快速迭代的质量保证要求。
5.(2)尽管部分测试数据可能检测出图像识别软件的功能缺陷,但无法正确模拟和仿真目标的真实、多样的特征,导致测试结果的可信度受到影响。
6.测试数据增强技术是指对现有的测试用例集在测试覆盖率和错误检测率等方面的提升,以全面覆盖测试需求,包括数据蜕变、数据变异等方法。数据蜕变的思想来源于蜕变测试,当前被广泛应用于智能软件的测试中。数据蜕变根据待测智能软件的功能属性,设计数据蜕变规则,对原始测试数据进行蜕变,生成衍生测试数据,增强测试数据的缺陷检测能力。当前智能软件的测试数据增强主要以随意的方式得到数据蜕变规则,领域专家甚至也认为获取数据蜕变规则较为困难,缺乏数据蜕变规则构造的指导,导致数据蜕变的效率受限,因此,如何设计一组有效的数据蜕变规则是揭露智能功能缺陷的关键。
7.智能软件的测试是为了在每一次软件演化中,进一步改进软件产品的质量,在日益激烈的市场竞争中,用户反馈的缺陷报告对于智能软件的维护与演化更具实际意义。用户反馈的自然语言文本作为智能软件用户使用体验的重要反馈媒介,包含大量真实、丰富的智能功能缺陷相关的描述信息,例如智能功能的实际输出行为与用户期望的行为表现不一致,失败用例的上下文信息等,可以为缺陷重现所用。然而用户数据具有海量性、多样性、非结构化等特点,同时也存在大量冗余、无价值的信息,如何利用用户反馈辅助智能功能的缺陷分析和测试活动仍然面临挑战。
技术实现要素:
8.针对于上述现有技术的不足,本发明的目的在于提供一种基于缺陷分析的图像识别软件测试数据增强方法及装置,以克服现有技术中智能化的图像识别软件存在的缺乏足够的、可信的测试数据的问题。本发明基于数据蜕变技术实现测试数据的增强,挖掘与图像识别功能缺陷相关的用户反馈文本,利用自然语言处理和深度学习技术,提炼描述功能缺陷的关键信息;分析缺陷发生时的上下文信息,从中抽取关键上下文,并进一步分析测试上下文间的优先级关系,构成测试上下文集合。基于测试上下文及其优先级关系,设计针对图像识别软件的通用和典型数据蜕变规则,对原始测试数据进行数据蜕变,生成大量衍生测试数据,从而增强原始测试数据的真实性和多样性。
9.为达到上述目的,本发明采用的技术方案如下:
10.本发明的一种基于缺陷分析的图像识别软件测试数据增强方法,步骤如下:
11.1)收集待测图像识别软件用户反馈的自然语言文本形式的数据,并对所述收集到的数据进行预处理,以构造统一的用户反馈数据集;
12.2)构建用户反馈分类模型,提取图像识别功能相关的缺陷报告;
13.3)构建所述缺陷报告中的实体对;
14.4)将描述相似缺陷问题的实体对进行分组,选取实体对,构造测试上下文集合;
15.5)依据所述测试上下文集合,构造满足图像识别软件的通用和典型数据蜕变规则;
16.6)依据所述数据蜕变规则,将原始测试数据进行数据蜕变,生成衍生测试数据。
17.优选地,所述步骤2)具体包括:将用户反馈数据集中的句子分为功能请求、缺陷报告、功能评价和其他四大类。
18.优选地,所述步骤2)具体包括:
19.21)采用自然语言处理方法对用户反馈数据集中的句子进行预处理,利用tf
‑
idf算法计算句子的n
‑
gram的词频和逆文档词频值,将句子进行向量表示;
20.22)定义用户反馈分类法,对用户反馈数据集中的句子进行标注,其中,功能请求、缺陷报告和功能评价三类均与图像识别功能相关,与图像识别功能不相关的句子包含在其他类中;
21.23)将向量形式的用户反馈数据集中的句子作为输入,采用机器学习分类算法,构建用户反馈分类模型,提取图像识别功能相关的缺陷报告。
22.优选地,所述步骤3)具体包括:
23.31)将缺陷报告分为训练集和测试集;采用bio三标记法标注训练集句子中的实体,其中,缺陷报告类句子中的实体被分为:缺陷问题、缺陷上下文和其他;
24.32)采用预训练bert语言模型,获取缺陷报告类句子中的文本特征,作为输入,训练crf与bilstm相结合的模型;
25.33)利用训练后的命名实体识别模型对测试集中的缺陷报告类句子进行实体识别,抽取其中表示图像识别功能缺陷问题和缺陷上下文的实体,构建<缺陷问题
‑
上下文>实体对。
26.优选地,所述步骤4)具体包括:
27.41)采用聚类算法将描述相似缺陷问题的<缺陷问题
‑
上下文>实体对进行分组,将
相似的实体对划分至同一簇中;
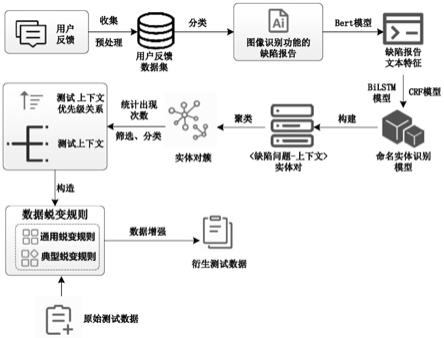
28.42)选取描述图像识别功能未能成功或准确完成其目标的缺陷问题所对应的实体对簇,提取其中的上下文实体;依据上下文实体出现的次数分析测试上下文的优先级关系,构造图像识别功能的测试上下文集合。
29.优选地,所述步骤5)具体包括:依据步骤4)中构造的测试上下文集合,构造满足图像识别软件的通用和典型数据蜕变规则,其中,通用数据蜕变规则适用于各领域的图像识别软件,满足数据蜕变规则的可复用;典型数据蜕变规则是待测图像识别软件特有的,用于刻画其特征和属性,测试上下文间的优先级关系以用于表示数据蜕变规则间的优先级关系。
30.优选地,所述步骤6)具体包括:针对待测图像识别软件,预先准备原始的图像,作为原始测试数据,依据数据蜕变规则及其优先级关系,通过图像处理、人工拍摄或从网站上收集,生成或辅助测试人员构造衍生测试数据集,模拟现实中图像识别功能的上下文环境,增强原始测试数据的真实性和多样性。
31.本发明还提出了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法中的步骤。
32.本发明的有益效果:
33.本发明通过挖掘用户反馈的图像识别软件的缺陷报告,分析图像识别功能的缺陷以及缺陷发生时的上下文环境,构造测试上下文集合,作为数据蜕变规则构造的指引,对原始测试数据进行数据蜕变,生成衍生测试数据,从而增强原始测试数据的真实性和多样性,用于缓解数据驱动的图像识别软件缺乏足够、可信的测试数据的问题;具体说,主要有如下一些优点:
34.1、本发明设计了一种用户反馈分类方法,该方法主要针对智能功能相关的用户反馈进行自动分类,可用于发现和分析用户反馈的智能功能相关的缺陷报告、功能使用评价和用户对智能功能的真实需求、建议等信息,辅助开发和测试人员实现缺陷分析、回归测试需求分析、缺陷修复等,使得开发和测试人员可以站在用户的角度,对智能功能进行改进和优化,进一步辅助软件维护与演化活动。
35.2、本发明充分利用了用户反馈中与图像识别功能缺陷相关的信息,通过挖掘自然语言形式的缺陷报告数据,综合分析评论的句式结构特点,自动识别和抽取描述图像识别功能缺陷的关键信息,为开发和测试人员分析图像识别功能的缺陷以及缺陷发生时的上下文环境提供支持;提取测试上下文,引导数据蜕变规则的构建,自动生成和辅助测试人员构造大量、可信的测试数据,提高测试数据的多样性和测试用例的充分性,提升软件缺陷检测的效率。
附图说明
36.图1为本发明方法原理流程图。
37.图2为本发明中测试上下文在<缺陷问题
‑
上下文>实体对中的比例示意图。
具体实施方式
38.为了便于本领域技术人员的理解,下面结合实施例与附图对本发明作进一步的说
明,实施方式提及的内容并非对本发明的限定。
39.参照图1所示,本发明的一种基于缺陷分析的图像识别软件测试数据增强方法,包括步骤如下:
40.步骤1)收集待测图像识别软件用户反馈的自然语言文本形式的数据,并对所述收集到的数据进行预处理,以构造统一的用户反馈数据集;示例中,
41.11)利用爬虫从google play、apple store移动应用商店中收集植物识别软件的用户反馈数据,其中包括用户反馈的文本内容和提交时间,收集提交时间范围为2020年5月至2021年5月的用户反馈文本;
42.12)对用户反馈文本进行预处理,包括:表情符号过滤、非英文评论文本过滤、缩写改正、缩略语转成为基本形式以及拼写错误改正;再依据符号“.”、“...”、“?”、“!”、“~”、“......”对用户反馈文本进行分句,形成统一的用户反馈数据集。
43.步骤2)构建用户反馈分类模型,提取图像识别功能相关的缺陷报告;示例中,
44.21)对用户反馈数据集中的句子进行预处理,具体包括:过滤掉包含少于三个单词的句子、分词、单词转换为小写、词根还原以及去掉停用词;例如,句子“keep crashing when identifying a plant”经自然语言处理后为“keep,crash,when,identify,plant”的单词组合;
45.22)分别提取出用户反馈句子中的1
‑
gram,2
‑
gram以及3
‑
gram,通过tf
‑
idf算法分别计算句子中n
‑
gram的词频和逆文档词频值,将句子进行向量表示。例如21)中经预处理后的句子抽取出的2
‑
gram序列为“keep crash”,“crash when”,“when identify”和“identify plant”;通过tf
‑
idf算法为每条用户反馈句子分别计算出n
‑
gram(n=1,2,3)的词频
‑
逆文本词频值w
t
,一条句子的特征向量即可表示为r(w1,w2,w3,...,w
t
,w
t+1
,...,w
v
),其中v表示用户反馈数据集中词汇表的大小;
46.23)定义智能功能相关的用户反馈分类法,人工对用户反馈数据集中的句子进行标注,用户反馈类型的定义见表1;其中,功能请求、缺陷报告和功能评价三类均与图像识别功能相关,与图像识别功能无关的句子包含在其他类中。智能功能相关的用户反馈分类方法并不限定于图像识别领域,其他智能功能领域也可参照该分类法,例如语音识别、机器翻译;表1如下:
47.表1
[0048][0049]
24)将步骤21)中以向量形式表示的用户反馈数据集中的句子分为训练集和验证集;将训练集作为模型的输入,采用逻辑斯蒂回归、朴素贝叶斯、梯度提升分类器以及自适应提升分类四种机器学习分类算法,训练分类模型;对验证集中的句子进行分类,调整参数,选取最优模型作为用户反馈分类模型,自动提取图像识别功能相关的缺陷报告。
[0050]
步骤3)构建所述缺陷报告中的实体对;示例中,
[0051]
31)将缺陷报告分为训练集和测试集;采用“bio”三标记法标注训练集句子中的实体,“b”表示实体的开始部分,“i”表示实体的延续部分,“o”表示其他。其中,缺陷报告类句子中的实体被分为三大类:缺陷问题、缺陷上下文和其他。描述缺陷问题的实体被标注为“b
‑
bug”或“i
‑
bug”,描述缺陷上下文的实体被标注为“b
‑
context”或“i
‑
context”,与这两类无关的实体标注为“o”。实体标注的过程使用brat工具进行人工标注;
[0052]
32)采用预训练bert语言模型,获取缺陷报告类句子中的文本特征,作为输入,训练crf与bilstm相结合的模型;
[0053]
33)利用训练后的命名实体识别模型对测试集中的缺陷报告类句子进行实体识别,抽取其中表示图像识别功能缺陷问题和缺陷上下文的实体,构成<缺陷问题
‑
上下文>实体对。
[0054]
步骤4)将描述相似缺陷问题的实体对进行分组,选取缺陷问题对应的实体对,构造测试上下文集合;示例中,
[0055]
41)采用聚类算法将描述相似缺陷问题的<缺陷问题
‑
上下文>实体对自动进行分组,将相似的实体对划分至同一簇中;
[0056]
42)选取描述植物识别功能未能成功或准确完成其目标的缺陷问题所对应的实体对簇,提取其中的上下文实体;人工对上下文实体进行分类,并为每个类别定义一个测试上下文的标签。依据各测试上下文类别对应的上下文实体出现的次数,对测试上下文进行优先级排序,构造测试上下文集合。
[0057]
图2展示了各测试上下文类别在<缺陷问题
‑
上下文>实体对中的比例,从图中可以看出图像清晰度是最常见的测试上下文,占总数据量的30%;其次是植物状态,占21%;说明图像清晰度和植物状态是缺陷报告中用户反馈最频繁的上下文因素。裁剪和旋转是用户反馈频率最低的上下文因素,均仅占总数据量的2%。以植物识别功能为例,表2为针对植物识别功能构造的测试上下文及相应的上下文实体;表2如下:
[0058]
表2
[0059][0060]
步骤5)依据步骤4)中构造的测试上下文集合,构造满足图像识别领域的通用和典型数据蜕变规则,其中,通用数据蜕变规则适用于各领域的图像识别软件,满足数据蜕变规则的可复用;典型数据蜕变规则是待测图像识别软件特有的,用于刻画其特征和属性。测试上下文间的优先级关系用于表示数据蜕变规则间的优先级关系;示例中,
[0061]
51)依据步骤4)中构造的测试上下文集合,设计满足植物识别功能的通用和典型数据蜕变规则。数据蜕变规则被定义为:设d为被测程序p的输入域,l为给定的参数集,v为数据蜕变规则的适应性条件;k维的数据蜕变规则为d
k
×
l到d的映射,对于所有l∈l,如果则
[0062]
此外,测试上下文间的优先级关系用于表示数据蜕变规则间的优先级关系。表3展示了构造的9种数据蜕变规则,其中,植物状态测试上下文对应的数据蜕变规则dm
‑
state为植物识别领域的典型数据蜕变规则,其余8种为图像识别领域的通用数据蜕变规则。以图片清晰度为例,由于受到图像不同清晰程度的影响,同一识别目标(植物)的不同测试图像可能会导致植物识别功能输出不同的结果。因此数据蜕变规则dm
‑
image clarity表示在不改变目标的情况下,改变图像的清晰程度,模拟由于相机镜头变形、拍摄者的主观因素等而导致的图像清晰度较差的上下文环境;dm
‑
image clarity是图像识别软件通用的数据蜕变规则,除植物识别软件外,其他的图像识别软件,例如人脸识别软件、飞机图像识别软件均可复用该数据蜕变规则。表3如下:
[0063]
表3
[0064][0065]
步骤6)依据步骤5)中设计的数据蜕变规则,将原始测试数据进行数据蜕变,生成衍生测试数据;其中,设原始测试用例输入为x(x1,x2,...,x
n
),数据蜕变规则为r,衍生测试用例输入为y(y1,y2,...,y
n
),则满足原始测试用例与衍生测试用例关系为:
[0066]
y=r(x);
[0067]
61)预先准备原始的植物图像,作为原始测试数据,依据数据蜕变规则及其优先级关系,根据相应的数据增强方法,自动生成和辅助测试人员构造衍生测试数据;表4展示了基于数据蜕变规则的数据增强方法,其中算法的输入为数据蜕变规则队列、数据蜕变规则集合以及数据蜕变规则优先级关系,输出是衍生测试数据结合。算法首先将数据蜕变规则依据优先级关系依次入队列;然后从优先级最高的数据蜕变规则开始,根据相应的图像变换方式,增强原始测试数据,最后构成衍生测试数据集;表4如下:
[0068]
表4
[0069][0070][0071]
62)采用opencv库中的亮度变换、裁剪变换、平移变换、旋转变换和模糊滤波器分别实现基于dm
‑
lighting、dm
‑
cropping、dm
‑
position、dm
‑
rotation以及dm
‑
image clarity这五种数据蜕变规则的测试数据增强,表5中为这五种数据蜕变规则对应的图像变换方法及参数设置。收集1000张种子测试图像,依据表4进行图像变换,共生成50000张增强后的衍生测试图像;表5如下:
[0072]
表5
[0073][0074]
63)针对dm
‑
background数据蜕变规则,收集200张植物测试图像,利用removebg库识别原始图像中的植物主体,分割主体和背景,保留植物主体部分;选取3张包含土壤和其他植物的图像,以及2张纯色的图像(纯黑和纯白)作为背景图像,将植物主体插入到背景图像中,共合成1000张衍生测试图像。
[0075]
64)针对dm
‑
angle数据蜕变规则,选择200种不同的图像识别的主体,人工使用移动设备对待识别主体进行多角度的拍摄,拍摄角度包括正面平拍、侧面平拍、背面平拍、俯拍和仰拍五种,构造1000张衍生测试图像。
[0076]
65)针对植物识别领域的dm
‑
state数据蜕变规则,收集200种不同的植物的不同生长阶段(植物种子、植物幼苗、植物开花、植物结果、植物枯萎)的图像,构造1000张衍生测试图像。
[0077]
本发明具体应用途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以作出若干改进,这些改进也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1