1.本发明属于深度学习
‑
计算机视觉算法领域,涉及一种参数化视角学习的三维立体形状识别方法。
背景技术:2.从ar/vr到自动驾驶,三维立体物体的形状识别越来越受到关注。随着公开数据集的传播,各式各样的基于深度学习的方法被提出。目前三维物体的建模数据主要包括体素、点云、多视图等。体素数据通常由3d卷积神经网络处理,但体素化网格分布稀疏,内存占用大,对资源要求较为苛刻。多视图数据通过池化手段完成不同视图特征的聚合。而点云数据是无序且不规则的所以无法采用常规的卷积操作。pointnet是处理点云数据类型的先驱,它采用全局最大池化函数来实现不规则点集的排列不变性并且从整个点云聚集信息。另外考虑到pointnet独立地处理每个点元素,后续的很多工作试图去改进网络对于局部信息的捕获能力。
3.目前在二维图像上的深度学习方法已经相当成熟,业界提出了包括resnet、vgg在内的诸多经典网络,这也使得针对多视图数据类型的处理网络处于立体形状识别领域的领先地位。尽管基于多视图数据类型的网络相比基于点云数据类型的网络具有更高的识别精度,但它有着极为巨大的时间复杂度,对于资源的要求较为苛刻。以往的工作很少关注多视图网络的效率,因为模型参数的减少可能会导致精度的严重下降。
技术实现要素:4.为了解决现有技术中存在的问题,本发明提供一种参数化视角学习的三维立体形状识别方法,通过使用基于多视图数据类型的新型网络,在使用较少参数的基础上,可以保持较高的识别精度。
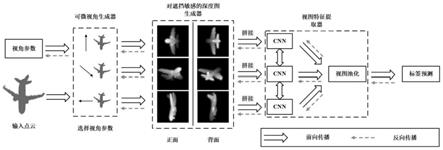
5.为了实现前述发明目的,本发明提供一种参数化视角学习的三维立体形状识别方法,采用pvlnet网络进行识别,所述pvlnet网络包括可微分视角生成器、可感知遮挡的深度图生成器和视图特征提取器,包括以下步骤:
6.s1:将点云和多个代表不同视图方向的视角参数输入可微分视角生成器,分别得到点云在不同视图方向下的投影平面,其中,点云在每个视图方向下的投影平面均有两个,且两个投影平面相对,定义为上投影面和下投影面;
7.s2:将点云的的不同视图方向的上投影面和下投影面均输入可感知遮挡的深度图生成器,分别得到点云在不同视图方向下的正面深度图和背面深度图;
8.s3:分别将同一视图方向下的点云的正面深度图和背面深度图拼接后得到的双通道深度图输入视图特征提取器,分别得到每个视图方向下的点云特征,将每个视图方向下的点云特征聚合,得到聚合特征,根据所述聚合特征得到识别结果。
9.进一步地,s1中得到投影平面的方式为:
10.通过旋转矩阵对齐点云,旋转对齐后的视觉方向与z轴对齐,并对点云的坐标进行
归一化;
11.根据对齐后的点云得到上投影面和下投影面。
12.进一步地,所述上投影面z1=1,下投影面z1=
‑
1。
13.进一步地,所述通过旋转矩阵对齐点云中,对齐后的点云式中,r
v
是从视图向量v到z轴上的单位向量u的旋转矩阵,p为原始点云数据。
14.进一步地,所述旋转矩阵r
v
为:
[0015][0016]
式中,i是单位矩阵。
[0017]
进一步地,对齐后的点云在上投影面和下投影面上的像素为
[0018][0019][0020]
式中,[i,j]代表图像平面的像素坐标,代表了上投影面i,j点的像素,代表了下投影面i,j点的像素。
[0021]
进一步地,s2中采用欧氏距离计算点云的点与投影后的像素的关联程度然后作为权重掩码计算投影点像素值。
[0022]
进一步地,s2中采用高斯核函数来计算点云像素与对齐后的点云之间置信度的估计掩膜。
[0023]
进一步地,s3中每个视图方向下拼接得到的双通道深度图以共享权重的方式输入视图特征提取器。
[0024]
进一步地,所述视图特征提取器为卷积神经网络。
[0025]
与现有技术相比,本发明能够实现的有益效果至少如下:
[0026]
(1)与基于点云的方法相比,基于视图的方法虽然具有更高的精度,但其计算量很大。以往的研究很少关注基于多视图的网络的效率,因为模型参数的重减可能会导致精度的严重下降。为了解决这一问题,本发明将视角坐标作为pvlnet的参数,根据视角参数把点云数据投影生成深度图像,然后通过视图特征提取器来获得识别结果,可以在不依赖大量参数的情况下保持较高的精度。
[0027]
(2)与以往的基于多视图的方法相比,该网络仅使用1/10的参数就能实现最好的性能。
附图说明
[0028]
图1是本发明实施例提供的一种参数化视角学习的三维立体形状识别方法的网络结构图。
[0029]
图2是本发明实施例提供的可微分视角生成器示意图。
[0030]
图3是本发明实施例提供的可感知遮挡的深度图生成器示意图。
具体实施方式
[0031]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都是本发明保护的范围。
[0032]
请参阅图1,本发明提供的一种参数化视角学习的三维立体形状识别方法,采用pvlnet网络进行识别,所述pvlnet网络包括可微分视角生成器、可感知遮挡的深度图生成器和视图特征提取器,该方法包括以下步骤:
[0033]
步骤1:将点云和多个代表不同视图方向的视角参数输入可微分视角生成器,分别得到点云在不同视图方向下的投影平面,其中,点云在每个视图方向下的投影平面均有两个,且两个投影平面相对,定义为上投影面和下投影面。
[0034]
可微分视角生成器的目的是根据输入的表示视图方向的一系列坐标来计算投影平面。其中输入网络的视图参数采用随机初始化的方法并在之后的梯度传播中跟随网络进行优化,在本发明其中一个实施例中,假设视图向量与单位向量沿z轴对齐,而不是直接计算正面和背面的映射函数。
[0035]
本步骤中,输入的数据是点云和视角参数,视角参数是几个随机的代表不同视图方向的坐标,视角参数的目的是把每个坐标作为一个方向进行投影,即如图2所示,把三维的点云沿着方向投影到二维的平面。然后这个视角参数也就是坐标会跟随网络进行梯度更新找到一个使得最后的分类结果最好的视角(x,y,z)。
[0036]
在本发明其中一个实施例中,v表示视图向量,在z轴上的单位向量为u。为了从v旋转到u,本发明使用rodrigues旋转公式得到旋转矩阵r
v
:
[0037][0038]
其中u=[0,0,1]
t
表示z轴上的单位向量,i是单位矩阵,r
v
是从v到u的旋转矩阵。借助旋转矩阵r
v
,本发明可以在对齐的基础上旋转点云。同时切平面也与水平面:z=1和z=
‑
1对齐。
[0039]
步骤2:将点云的的不同视图方向的上投影面和下投影面均输入可感知遮挡的深度图生成器,分别得到点云在不同视图方向下的正面深度图和背面深度图。
[0040]
从图2可以看出,本发明可以摆脱投影函数的繁琐计算,通过公式(2)直接将点云映射到水平面上。另外点云的x、y、z坐标都归一化为[
‑
1,1]。
[0041][0042]
是平面上对应的点云上的投影点,也就是说点云上投影点的距离决定了投影面上像素值的大小。
[0043]
是对齐之后的点云,r
v
是从v到u的旋转矩阵,p代表了原始点云数据,因为把点云
在一个方向上做向上和向下投影,代表了上投影面i,j点的像素,代表了下投影面i,j点的像素。[i,j]代表图像平面的像素坐标,d是生成的深度图,正面深度图中的像素值表示正表面上的点到投影平面z=
‑
1的距离,背面深度图中的像素值表示背面上的点到投影平面z=1的距离,并且整个过程是可微的。这个z轴是指公式(1)中旋转之后的z轴,也就是说把视角所在的位置旋转到z轴然后在z轴上进行投影,如此可方便后续的计算。
[0044]
直接将点云映射到图像平面存在几个局限性:首先,点云的点没有严格定位在预定义像素的位置,因此存在不匹配的情况;其次,点云通常是稀疏的点集,成像平面中的许多像素可能没有相应的投影点。也就是说生成的深度图并不能提供一个严格的一一映射表示;第三,在将整个点云映射到同一平面时,正面和背面的点可能重叠在一起,或者位于一个十分近的区域,这就会使得投影点混淆,导致最后深度图的严重模糊。此外遮挡关系对于联结正面和背面并最后表征为一个完整的形状也很重要。
[0045]
为了解决上述问题,本发明提出了可感知遮挡的深度图生成器,如图3所示。假设对齐的点云为共包含m个点,生成的深度图像的分辨率为n
×
n。像素[i,j]在图像平面上的位置q
i,j
通过公式(3)计算,其中i=0,1,
…
n
‑
1,j=0,1,
…
,n
‑
1。
[0046][0047]
为了减少点云p的投影点与规则网格中预定义像素之间的映射误差,本发明使用欧几里得距离来估计点与像素的关联程度的置信度。如果它们的欧氏距离越大,那么它们的关联程度就越小。像素[i,j]与对齐点云p的第k个点之间的欧氏距离由公式(4)计算。
[0048][0049]
表示对齐点云的第k个点的位置。
[0050]
采用的欧氏距离计算关联程度然后作为权重掩码计算投影点像素值的方法可以避免正面背面遮挡融合到一起的问题。
[0051]
在本发明其中一个实施例中,为了使得投影得到的深度图更加平滑,在公式(5)中采用了高斯核,w
i,j,k
是用于验证点云像素[i,j]与对齐点云p的第k个点之间的置信度的估计掩膜。σ是控制高斯函数方差的超参数。
[0052][0053]
公式(2)中投影函数的朴素形式可以重写为公式(6)。点云的z坐标表示深度。到平面z=
‑
1的距离表示正面深度,到z=1平面的距离表示背面深度。本发明使用上标z来说明公式(7)中只使用点云的z坐标。
[0054][0055]
表示对齐点云p的第k个点的深度值。
[0056]
高斯估计掩模w
i,j,k
对稀疏深度图进行平滑处理,以提供稠密深度图的近似估计。公式(6)估计每个像素与点云所有投影点之间的距离。由于只需要估计表面,本发明可以只选用最大值来过滤所有其他值。因此,可以通过公式(6)自动区分光滑的前后表面。
[0057]
步骤3:分别将同一视图方向下的点云的正面深度图和背面深度图拼接后得到的双通道深度图输入视图特征提取器,得到每个视图方向下的点云特征,将每个视图方向下的点云特征聚合,得到聚合特征,根据所述聚合特征得到识别结果。
[0058]
在本发明其中一个实施例中,视图特征提取器为卷积神经网络。优选地,采用6层cnn作为骨架网络。
[0059]
在本发明其中一个实施例中,生成深度图的默认分辨率设置为32
×
32。
[0060]
本发明中,假设k个视图是在视图参数中预定义的。然后生成由正面深度图和背面深度图组成的2k个深度图。为了利用深度图中正面和背面在同一位置的像素对应关系,本发明将正面图像和背面图像拼接起来,构建k张双通道深度图。然后将这些图像以共享权重的方式反馈给卷积神经网络cnn以提取最后的特征。
[0061]
在本发明其中一个实施例中,采用全局最大池化函数来聚合不同视图方向下的的特征,得到聚合特征,根据该聚合特征得到最终的识别结果。
[0062]
本发明中,通过训练获得所需要的pvlnet网络,在训练时,通过反向传播方式对参数进行优化。
[0063]
通过实验验证,如表1所示,表中,params表示参数量,flops代表计算量,time代表运行时间,可以看到本发明方法在采用较少的参数量的基础上,能够获得比其他现有的方法更高的识别精度。
[0064]
表1各种不同方法的实验结果
[0065][0066]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本发明中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于前述的这些实施例,而是要符合与本发明所公开的原理和新颖特点相一致的最宽的范围。