一种基于深度学习的轻型活体检测方法与流程
1.本发明涉及图像分类技术领域,尤其涉及一种基于深度学习的轻型活体检测方法。
背景技术:
2.活体检测是一种图像分类技术,就是判断捕捉到的人脸是否为有生命的个体,定义借助其它媒介产生的人脸都为无生命的虚假人脸,包括纸质照片、电子产品的显示屏幕、硅胶面具、3d模型人像等,活体检测被广泛应用于信息安全、金融服务等领域,通常与人脸识别技术结合组成完整的系统部署到真实场景中,随着信息技术的推广,电子安全问题受到越来越多的关注,因此,保障人脸识别安全性的“活体检测”就成了实际应用中不可或缺的核心技术。
3.交互方式上,目前主流的活体解决方案分为配合式和静默式,然而,这两种方式存在以下几个弊端:
4.(1)现有的配合式活体检测需要用户根据提示做出相应的动作,通过眨眼、张嘴、摇头等配合式组合动作,提取人脸关键点后进行人脸追踪,计算连续的图片的变化距离与不变距离的比值,进行连续两帧图像的对比,从而验证用户是否为真实活体本人操作。然而,配合式活体检测的缺点是耗时长用户体验感差,同时检测的隐蔽性差,非法攻击者通过交互方法,知道系统所采用的活体检测手段,然后再设计相应的方法去欺骗系统,安全性低;
5.(2)现有的静默式活体检测为在用户无感的情况下直接进行检测。在静默式活体检测中,采集的图像信息为普通rgb图像、基于红外成像原理生成的近红外图像(ir),以及通过3d结构光或tof获取3d人脸信息生成的深度信息图像(depth),然而,首先,单目活体检测大多采用普通rgb摄像头,通过分析采集到人像的破绽如:摩尔纹、成像畸形、图像里面漏出的各种类型的边框、图像质量、反射率等,并结合分析全局特征和局部微纹理信息有效过滤假体,但在缺少其他信息加入的情况下,单目活体检测的准确度低于双目活体检测方式;
6.其次,虽然双目活体检测中的ir双目红外活体检测,在rgb单目活体的基础上,加入了红外摄像头,红外图像滤除了特定波段的光线,天生抵御基于屏幕成像的假脸攻击,对于屏幕成像和纸张照片类的防御力也更加优秀,但是,它的输入人像仍然为2d信息,针对头模和3d立体面具的防御能力差;
7.最后,虽然通过双目活体检测中的深度信息活体检测则通过(depth)信息进行活体的有效判断,引入了"深度信息"概念,可以得到人脸区域的3d数据,并基于这些数据做进一步分析,能够很容易地抵御3d媒介的假脸攻击,但是,在工业的落地使用过程中,运用更多信息的深度学习分类模型占有较大的内存和推理时长,又限制了它的应用。
技术实现要素:
8.为了解决上述背景技术中所提到的技术问题,而提出的一种基于深度学习的轻型
活体检测方法。
9.为了实现上述目的,本发明采用了如下技术方案:
10.一种基于深度学习的轻型活体检测方法,包括以下步骤:
11.s1、获取人头部的彩色图像(rgb)、近红外图像(ir)和3d深度结构图像(depth);
12.s2、获取rgb图像中的人脸区域:
13.s21、使用dlib库获取每张图像的人脸边界框,将人脸边界框向四周扩展后得到rgb面部区域;
14.s22、将rgb面部区域传递到prnet人脸重建算法中进行深度估计,得到人脸的边界区域,生成掩模图像;
15.s221、在prnet网络中得到人脸的关键点坐标,其中,在人脸区域3d深度结构图像(depth)的标定上,采用人脸的五个关键点区域平均值作为人脸平面深度值(d0),根据人脸的结构,人脸面部深度最小值设为d0
‑
5(cm),人脸面部深度最大值设为d0+10(cm),将掩模生成的面部区域深度值按照此最值进行截断处理,再进行均值滤波,最后将3d深度结构图像(depth)像素值缩放至(0
‑
255);
16.s222、近红外图像(ir)像素值缩放至(0
‑
255);
17.s223、彩色图像(rgb)转化为灰度图像并缩放至(0
‑
255);
18.s23、3d深度结构图像(depth)和近红外图像(ir)与掩模图像相乘,获得人脸区域;
19.s3、将缩放后的近红外图像(ir)与转化并缩放为灰度图像的彩色图像(rgb)输入红外图像与彩色图像数据重组模块中进行拼接,输出图像尺寸为2*224*224的特征图,将缩放后的3d深度结构图像(depth)和转化并缩放为灰度图像的彩色图像(rgb)输入深度图像重标定后与彩色图像数据重组模块中进行拼接,输出图像尺寸为2*224*224的特征图,对以上两个经过数据重组后获得的2*224*224的特征图做注意力机制处理后再进行特征图拼接,获得4*224*224的特征图;
20.s4、将步骤s3中图像尺寸为4*224*224的特征图输入深度学习轻型分类模型中进行活体检测;
21.s41、将步骤s3中图像尺寸为4*224*224的特征图像输入cnn主干网络中进行卷积提取特征,生成图像尺寸为7*7的特征图;
22.s42、将图像尺寸为7*7的特征图输入流模块中;
23.s421、使用步长大于1的深度卷积(dwconv)层对图像尺寸为7*7的特征图下采样,并将图像尺寸为7*7的特征图缩小为图像尺寸为4*4的特征图;
24.s422、将图像尺寸为4*4的特征图输出为1维特征向量(1*1024);
25.s423、将1维特征向量(1*1024)输入损失函数中计算损失进行预测,即判断该图像是否为活体。
26.作为上述技术方案的进一步描述:
27.在通过采集设备获取近红外图像(ir)和3d深度结构图像(depth)时,包括以下限制条件:
28.限制条件一:固定采集设备的镜头型号、传输方式和最终保存格式参数,近红外图像(ir)和3d深度结构图像(depth)的采集和活体检测的使用过程均使用此固定参数;
29.限制条件二:采集时,近红外图像(ir)和3d深度结构图像(depth)为同时帧图片。
30.作为上述技术方案的进一步描述:
31.用户在通过采集镜头进行活体检测过程中,包括以下限制条件:
32.限制条件一:人脸相对于采集镜头的旋转角度不超过30
°
;
33.限制条件二:人脸区域框占整张采集图像的比例不低于50%;
34.限制条件三:整张采集图像的短边像素不低于100像素值;
35.限制条件四:不允许用不透光的墨镜遮挡眼部或者口罩遮挡面部或者帽子覆盖至眼眉部位。
36.作为上述技术方案的进一步描述:
37.用户在通过采集镜头进行活体检测过程中,规定正例为真实的人脸图像,负例为攻击人脸图像,攻击方式如下所示:
38.攻击方式一:a4纸和铜版纸打印图片;
39.攻击方式二:平板和手机屏幕人像图片;
40.攻击方式三:打印纸张中将人脸眼睛、鼻子、嘴巴部位裁剪后作为面具覆盖于人脸;
41.攻击方式四:不同人的二分之一打印纸张和真实人脸组合图片;
42.攻击方式五:硅胶面具;
43.攻击方式六:真实1:1比例的3d头模。
44.作为上述技术方案的进一步描述:
45.所述深度学习轻型分类模型包括cnn主干网络和流模块,所述cnn主干网络包括blocka和blockb,所述blocka是mobilenetv2中提出的逆残差块,所述blockb作为深度学习轻型分类模型的下采样模块,blockb左侧辅助分支使用avg pool,以在不同的感受野中嵌入多尺度信息和聚合特征,所述流模块包括深度卷积(dwconv)层和损失函数。
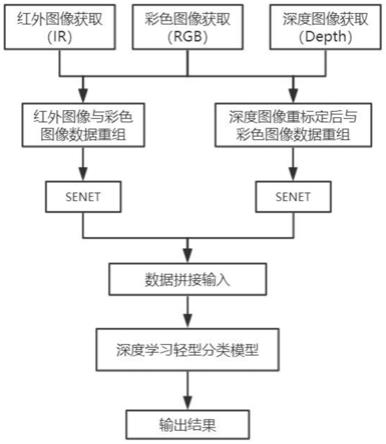
46.作为上述技术方案的进一步描述:
47.所述红外图像与彩色图像数据重组模块和深度图像重标定后与彩色图像数据重组模块内部均包含三层卷积层,经过卷积,得到通道数为r2倍的原始图片大小,其中,r为原始图片尺寸到224的倍数。
48.作为上述技术方案的进一步描述:
49.在步骤s3中,通过senet模块对不同通道获得的2*224*224的特征图赋予不同权重后再进行拼接。
50.综上所述,由于采用了上述技术方案,本发明的有益效果是:
51.1、本发明中,将获取人脸部位的彩色图像(rgb)、近红外图像(ir)和3d深度结构图像(depth)的图像数据进行数据重组,完成数据重标定和注意力机制特征图拼接,然后,再将拼接后的特征图输入到深度学习轻型分类模型中,判断出该图像是否为活体,为满足工业落地场景的快速化和轻量化等特点,选择改进cnn主干网络,使得深度学习轻型分类模型占用内存小,提高推理速度,可应用在手机或小型嵌入式设备的静默式活体检测过程。
52.2、本发明中,将3d深度结构图像(depth)的3d信息、近红外图像(ir)的2d信息和彩色图像(rgb)融合后,极大的丰富了活体检测的判断依据信息,增加深度轻型分类模型的准确性,其中,在3d深度结构图像(depth)的3d的处理上,采用特定的流程和重标定方法,有效的利用了深度图,其中,在彩色图像(rgb)、近红外图像(ir)和3d深度结构图像(depth)三种
图像输入信息的融合上,引入卷积模块重组图像,更加充分的使用提取数据,引入senet模块更加合理的分配输入数据的层权重,增加深度轻型分类模型的效果。
附图说明
53.图1示出了根据本发明实施例提供的一种基于深度学习的轻型活体检测方法的流程示意图;
54.图2示出了根据本发明实施例提供的一种基于深度学习的轻型活体检测方法的深度学习轻型分类模型的结构示意图;
55.图3示出了根据本发明实施例提供的一种基于深度学习的轻型活体检测方法的cnn主干网络的结构示意图;
56.图4示出了根据本发明实施例提供的一种基于深度学习的轻型活体检测方法的cnn主干网络的结构模块示意图。
具体实施方式
57.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
58.实施例一
59.请参阅图1
‑
4,本发明提供一种技术方案:一种基于深度学习的轻型活体检测方法,包括以下步骤:
60.s1、获取人头部的彩色图像(rgb)、近红外图像(ir)和3d深度结构图像(depth);
61.s2、获取rgb图像中的人脸区域:
62.s21、使用dlib库获取每张图像的人脸边界框,将人脸边界框向四周扩展后得到rgb面部区域;
63.s22、将rgb面部区域传递到prnet人脸重建算法中进行深度估计,得到人脸的边界区域,生成掩模图像;
64.s221、在prnet网络中得到人脸的关键点坐标,其中,在人脸区域3d深度结构图像(depth)的标定上,采用人脸的五个关键点区域平均值作为人脸平面深度值(d0),根据人脸的结构,人脸面部深度最小值设为d0
‑
5(cm),人脸面部深度最大值设为d0+10(cm),将掩模生成的面部区域深度值按照此最值进行截断处理,再进行均值滤波,最后将3d深度结构图像(depth)像素值缩放至(0
‑
255);
65.s222、近红外图像(ir)像素值缩放至(0
‑
255);
66.s223、彩色图像(rgb)转化为灰度图像并缩放至(0
‑
255);
67.s23、3d深度结构图像(depth)和近红外图像(ir)与掩模图像相乘,获得人脸区域;
68.s3、将缩放后的近红外图像(ir)与转化并缩放为灰度图像的彩色图像(rgb)输入红外图像与彩色图像数据重组模块中进行拼接,输出图像尺寸为2*224*224的特征图,将缩放后的3d深度结构图像(depth)和转化并缩放为灰度图像的彩色图像(rgb)输入深度图像重标定后与彩色图像数据重组模块中进行拼接,输出图像尺寸为2*224*224的特征图,对以
上两个经过数据重组后获得的2*224*224的特征图做注意力机制处理后再进行特征图拼接,获得4*224*224的特征图;
69.首先,大多数活体检测方法都是将ir/depth/rgb三种采集方式的数据做简单的处理和标定后,直接送入深度学习分类模型中,忽略了三种图像分布于不同的数据域中,本发明巧妙地利用rgb做中间媒介,就能容易的将三种数据做融合;
70.其次,本发明虽然也是利用三种图像判断是否为活体,但是在输入深度学习轻型分类模型前,利用三个卷积层已将三种数据做了更深层次的融合,并不是直接暴力输入,并且后面在拼接时,考虑到数据层的不同层具有不同的注意力机制,故在拼接前使用了senet模块将注意力机制这个模块的对不同通道赋予不同权重后的数据拼接,作为深度学习轻型分类模型的输入;
71.最后,3d深度结构图像(depth)和近红外图像(ir)的采集原理不同,对两种通道的直接拼接导致未能充分有效利用数据,需要引入彩色图像(rgb)做中介,将三种图像的信息充分使用,解决了低分辨率人脸图像,在输入深度学习轻型分类模型前resize的插值引入较多无效像素的弊端,一般的输入数据的人脸区域像素值较小,大多数都是将其resize到224*224,不管如何进行插值,都会导致无用的像素点产生过多,而通过这样的卷积就能自主学到如何将小像素扩展到224*224,仅仅丢失少量信息;
72.s4、将步骤s3中图像尺寸为4*224*224的特征图输入深度学习轻型分类模型中进行活体检测;
73.s41、将步骤s3中图像尺寸为4*224*224的特征图输入cnn主干网络中进行卷积提取特征,生成图像尺寸为7*7的特征图;
74.s42、将图像尺寸为7*7的特征图输入流模块中;
75.s421、使用步长大于1的深度卷积(dwconv)层对图像尺寸为7*7的特征图下采样,并将图像尺寸为7*7的特征图缩小为图像尺寸为4*4的特征图;
76.s422、将图像尺寸为4*4的特征图输出为1维特征向量(1*1024),这样可减少全连接层引起的过拟合风险;
77.s423、将1维特征向量(1*1024)输入损失函数中计算损失进行预测,即判断该图像是否为活体;
78.本发明将3d深度结构图像(depth)的3d信息、近红外图像(ir)的2d信息和彩色图像(rgb)融合后,极大的丰富了活体检测的判断依据信息,增加深度轻型分类模型的准确性,其中,在3d深度结构图像(depth)的3d的处理上,采用特定的流程和重标定方法,有效的利用了深度图,其中,在彩色图像(rgb)、近红外图像(ir)和3d深度结构图像(depth)三种图像输入信息的融合上,引入卷积模块重组图像,更加充分的使用提取数据,引入senet模块更加合理的分配输入数据的层权重,增加深度轻型分类模型的效果。
79.具体的,在通过采集设备获取近红外图像(ir)和3d深度结构图像(depth)时,包括以下限制条件:
80.限制条件一:固定采集设备的镜头型号、传输方式和最终保存格式参数,近红外图像(ir)和3d深度结构图像(depth)的采集和活体检测的使用过程均使用此固定参数;
81.限制条件二:采集时,近红外图像(ir)和3d深度结构图像(depth)为同时帧图片。
82.具体的,用户在通过采集镜头进行活体检测过程中,包括以下限制条件,因为虽然
本方法为静默式活体检测,但为在活体检测推理过程中增加识别的准确性和便利性,仍然需要用户对使用过程做出限制:
83.限制条件一:人脸相对于采集镜头的旋转角度不超过30
°
;
84.限制条件二:人脸区域框占整张采集图像的比例不低于50%;
85.限制条件三:整张采集图像的短边像素不低于100像素值;
86.限制条件四:不允许用不透光的墨镜遮挡眼部或者口罩遮挡面部或者帽子覆盖至眼眉部位;
87.限制条件五:其他原因导致面部信息采集不充足的;
88.由于活体检测应用场景多在支付安防等严肃领域,此行业规范的错误识别率在1e
‑4,故严格依照条件采集到的规范图像,经过深度轻型分类学习模型训练得到高准确率模型,一张人像不满足于上述的任一条件被输入系统时,模型提取的特征少于正常训练时的人脸特征,最终作为难例影响模型迭代方向,导致活体检测系统判断它为非活体,增加模型的错误拒绝率。
89.具体的,用户在通过采集镜头进行活体检测过程中,规定正例为真实的人脸图像,负例为攻击人脸图像,攻击方式如下所示:
90.攻击方式一:a4纸和铜版纸打印图片;
91.攻击方式二:平板和手机屏幕人像图片;
92.攻击方式三:打印纸张中将人脸眼睛、鼻子、嘴巴部位裁剪后作为面具覆盖于人脸;
93.攻击方式四:不同人的二分之一打印纸张和真实人脸组合图片;
94.攻击方式五:硅胶面具;
95.攻击方式六:真实1:1比例的3d头模;
96.采集时需要将人面部朝向正向/向左/向右/向上/向下,配饰不同眼镜和头套,开口与否,移动脸靠近或远离摄像机,表现出不同的情绪如高兴、生气、伤心等。
97.请参阅图2
‑
4,深度学习轻型分类模型包括cnn主干网络和流模块,cnn主干网络包括blocka和blockb,blocka是mobilenetv2中提出的逆残差块,blockb作为深度学习轻型分类模型的下采样模块,blockb左侧辅助分支使用avg pool,以在不同的感受野中嵌入多尺度信息和聚合特征,带来性能的提高,且cnn主干网络初始阶段采用快速下采样的策略,这能使特征图的尺寸迅速减小,且花费较少参数,可以避免算力有限的慢速下采样过程导致的特征嵌入能力弱和处理时间长的问题,流模块包括深度卷积(dwconv)层和损失函数。
98.具体的,红外图像与彩色图像数据重组模块和深度图像重标定后与彩色图像数据重组模块内部均包含三层卷积层,经过卷积,得到通道数为r2倍的原始图片大小,其中,r为原始图片尺寸到224的倍数。
99.具体的,在步骤s3中,通过senet模块对不同通道获得的2*224*224的特征图赋予不同权重后再进行拼接。
100.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1