一种警情信息分层要素识别方法和计算机与流程
1.本发明涉及公安管理领域,特别是涉及一种警情信息分层要素识别方法和计算机。
背景技术:
2.警情要素识别任务是从海量的警情文本中抽取出关键的要素信息。例如,警情案件中参与的人,警情事件发生的时间、地点以及警情中涉及的物品、工具和相关金额。提取这些信息不仅有助于警情的分类,同时对各类警情案件的关联关系识别也起到关键性的作用。然而,传统的人工分析的方法,存在效率低,误差率高等问题。随着机器学习和深度神经网络技术的发展,通过自然语言处理领域的相关技术能够很好的辅助民警提取和分析警情文本中的信息。
3.常见的警情事件要素识别技术多采用实体识别的方法,例如“王月,王孟轩,张胜,等.基于bert的警情文本命名实体识别[j].计算机应用,2020,40(2):535
‑
540.”公开了了一种的实体识别方法,即利用深度神经网络来学习警情文本的上下文信息,再通过条件随机场来预测文本中每一个字符的所属类别,即事先定义好的事件论元,例如,人物、时间、地点、工具等。
[0004]
这种方法虽然简单直接,但警情文本中的信息多样且复杂,不同类型的警情所包含的要素类别也各有差距。例如,在诈骗类警情中存在嫌疑人、受害人,而在殴打类的警情人物中一般存在双方当事人。并且,人物信息中又细分姓名、性别、年龄、居住地、暂住地等信息。同时,时间和地方也各不相同。例如,案发时间和出警时间。仅仅通过一层实体识别模型很难将这些要素准确的抽取出来。当要素类别粒度较粗时,无法精准的获得警情的关键信息,当要素类别粒度较细时,模型识别能力会随着类别的增加而降低。针对该问题,我们提出了一种分层的要素识别方法。
技术实现要素:
[0005]
本发明的目的是克服现有技术中的不足之处,提供一种警情信息分层要素识别方法及计算机。
[0006]
为实现上述目的,本发明一方面提供一种警情信息分层要素识别方法,包括:
[0007]
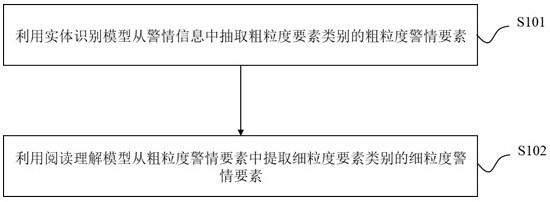
利用实体识别模型从警情信息中抽取粗粒度要素类别的粗粒度警情要素;
[0008]
利用阅读理解模型从粗粒度警情要素中提取细粒度要素类别的细粒度警情要素。
[0009]
优选地,所述实体识别模型包括:
[0010]
用于获得上下文语义向量的语义向量模型,和
[0011]
用于为文本中每个字符预测其粗粒度要素类别标签的序列化标注模型。
[0012]
优选地,所述语义向量模型为bert模型。
[0013]
优选地,所述序列化标注模型为bi
‑
lstm+crf模型。
[0014]
优选地,所述粗粒度要素类别包括:时间、地点、任务、和物品。
[0015]
优选地,所述利用阅读理解模型从粗粒度警情要素中,提取细粒度要素类别的细粒度警情要素包括:
[0016]
将细粒度要素类别对应的问题和粗粒度警情要素作为阅读理解模型的输入,输出该粗粒度警情要素中该问题对应的细粒度警情要素信息。
[0017]
优选地,所述输出该粗粒度警情要素中该问题对应的细粒度警情要素信息包括:
[0018]
输出细粒度警情要素在所述粗粒度警情要素中的位置信息。
[0019]
优选地,所述细粒度警情要素在所述粗粒度警情要素中的位置信息包括:
[0020]
细粒度警情要素在所述粗粒度警情要素中的起始位置和结束位置、或
[0021]
细粒度警情要素在所述粗粒度警情要素中的起始位置和长度信息。
[0022]
优选地,所述粗粒度要素类别为人物时,对应的细粒度要素类别包括:姓名、性别、身份证、联系方式、住址、民族、职业、和/或工作单位;
[0023]
所述所述粗粒度要素类别为物品时,对应的细粒度要素类别包括:物品名称、数量、颜色、和/或金额。
[0024]
本发明另一方面还提供一种计算机,包括:处理器和存储器,所述处理器用于执行存储器中的代码,以执行如上述的警情信息分层要素识别方法。
[0025]
本发明经过实体识别和阅读理解这样的分层要素识别模型,能够准确且高效的从警情文本中抽取出细粒度的警情要素信息。
[0026]
本发明的其他有益效果将在说明书中进行进一步说明。
附图说明
[0027]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0028]
图1为本发明实施例提供的一种警情信息分层要素识别方法的流程图;
[0029]
图2为序列化标注示意图;
[0030]
图3为实体识别模型的结构及输入输出结果示意图;
[0031]
图4为阅读理解模型的输入和输出示意图。
具体实施方式
[0032]
为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施方式。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施方式。相反地,提供这些实施方式的目的是使对本发明的公开内容理解的更加透彻全面。
[0033]
本发明实施例通过一种全新的分层级的警情要素识别模型,该模型分别从粗粒度要素和细粒度要素两个层级来抽取和识别警情文本中的关键信息,根据各类要素的相关特征分别通过实体识别模型和阅读理解模型来完成各个任务的信息抽取和识别。分层级的警情要素识别模型不仅能够让各个子模型完成其擅长的自然语言处理任务,提升整体模型的性能效果。同时,也能识别出细粒度的警情信息,更好的辅助下游的警情任务。
[0034]
以下对本发明进行详细说明。
[0035]
图1示出了本发明实施例提供的一种警情信息分层要素识别方法的流程图,参见图1,该方法包括:
[0036]
步骤s101:利用实体识别模型从警情信息中抽取粗粒度要素类别的粗粒度警情要素。
[0037]
警情信息可以是原始的警情文本。
[0038]
粗粒度要素类别可以包括时间、地点、任务、和物品等。
[0039]
实体识别模型是自然语言处理领域的一个非常基础且有效的算法模型,它在处理序列化标注任务时尤为擅长。如图2所示,我们要识别出文本“张三在酒吧殴打李四”中的人物“张三”和“李四”,以及案件的发生地点“酒吧”。
[0040]
为了实现粗粒度警情要素的抽取,实体识别模型可以包括用于获得上下文语义向量的语义向量模型,和用于为文本中每个字符预测其粗粒度要素类别标签的序列化标注模型。语义向量模型的输出可以作为序列化标注模型的输入的基础。
[0041]
通过序列化标注模型,对文本中的每一个字符预测标签,人物模型预测为per(person),地点预测为loc(loction),标注集可以采用bioes(b表示实体开头,e表示实体结尾,i表示实体内部,o表示非实体)。
[0042]
序列化标注模型有很多,从早期的机器学习的隐马尔可夫(hmm)模型和条件随机场(crf)模型,到后来深度神经网络的bi
‑
lstm+crf模型,直至目前bert等语言模型的出现,使得序列化标注模型的性能效果越来越好。
[0043]
在本发明实施例中采用bert预训练模型和经典的bi
‑
lstm+crf模型来预测警情文本中的粗粒度要素。其中bert模型为语义向量模型,bi
‑
lstm+crf模型作为序列化标注模型。
[0044]
参见图3示出的实体识别模型的结构及输入输出结果示意图,在自然语言处理领域的很多任务中,bert预训练模型都表现出绝对优势的成绩。相较于其他预训练词向量,bert使用了双向的语言模型,能够更好的表达文本的上下文语义信息。如图3所示,本发明实施例将警情文本输入到bert中,获得文本的上下文语义向量,再通过bi
‑
lstm+crf序列化标注模型,为文本中的每一个字符预测出其对应的粗粒度要素标签。
[0045]
图3的示例中定义了三类粗粒度要素标签,分别是时间(time)、地点(loction)、人物(person)、物品(good)。序列化标注任务的结果和标签类别直接相关,当要素类别定义的很细时,模型预测的类别就越多,效果就越差。因此,在警情要素识别的第一个阶段,文本中的人物信息,例如姓名、性别、手机号、身份证号都统一标注为人物。同样,与物品相关的描述信息也不做细分类,例如数量、颜色、物品名称、金额等,统一标注为物品。这样定义标签即有助于模型学习各类标签的分布特点,也有助于模型去预测每类标签,提升模型预测的准确率。
[0046]
但仅仅获得这些粗粒度的警情数据信息是远远不够的,人物的身份证号能够辅助民警锁定具体的涉案人员,涉案金额能够辅助民警对警情分类。因此需要对粗粒度警情要素进行进一步细分。
[0047]
步骤s102:利用阅读理解模型从粗粒度警情要素中提取细粒度要素类别的细粒度警情要素。
[0048]
如表1所示,粗粒度人物数据中通常包含了姓名,性别,身份证,联系方式,暂住地,户籍地,民族,职业,单位等关键信息,粗粒度物品数据中通常包含了物品名称,数量,颜色,金额等关键信息,粗粒度银行账户数据中通常包含了银行卡号,所属银行,开户人,开户行等关键信息。
[0049]
表1
[0050][0051][0052]
在本实施例中,利用阅读理解模型从粗粒度警情要素中,提取细粒度要素类别的细粒度警情要素可以包括:
[0053]
将细粒度要素类别对应的问题和粗粒度警情要素作为阅读理解模型的输入,输出该粗粒度警情要素中该问题对应的细粒度警情要素信息。
[0054]
为了从这些预测的粗粒度要素信息中提取出以上的几种细粒度信息,可以将要素识别任务转换成问答对(question
‑
answer)来处理。例如,如果想知道涉案人员的身份证号码时,可以向模型输入问句:“人物的身份证号是多少?”,模型就返回给我们身份证号对应的文本索引和相应的文本描述“320722199002251615”。当提出的问题在警情文本中没有涉及时,例如,“人物的职业是什么?”,模型应返回空,即没有对应的答案。对于这类任务场景,阅读理解模型能够有效的解决此问题。
[0055]
图4示出了阅读理解模型的输入和输出示意图。将作为粗粒度警情要素的文本和作为细粒度要素类别对应的问题的问句输入拼接在一起,并可以通过特殊字符[cls],[sep]标识开头、结尾以及区分文本和问句。并将拼接好<context,answer>对输入到作为阅读理解模型的bert模型中,最终模型会返回答案的位置信息,即细粒度警情要素在粗粒度警情要素中的位置信息。位置信息可以是开始位置(start)和结束(end)位置,也可以是开始位置和长度信息。这里,在一个优选的实施方式中,可以设置一个阈值k,当预测的start和end小于阈值k时,默认该段文本中没有问题的答案。
[0056]
最终,经过实体识别和阅读理解这样的分层要素识别模型,能够准确且高效的从警情文本中抽取出细粒度的警情要素信息。
[0057]
本发明另一实施例还提供一种计算机,包括:处理器和存储器,所述处理器用于执行存储器中的代码,以执行上述实施例所述的警情信息分层要素识别方法。
[0058]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1