一种基于模态推理图神经网络的场景文本视觉问答方法
1.本发明属于视觉问答的技术领域,尤其涉及一种基于模态推理图神经网络的场景文本视觉问答方法。
背景技术:
2.深度学习使计算机视觉(cv)和自然语言处理(nlp)获得巨大的进展,视觉和自然语言之间的跨领域学科已经吸引了强烈的关注,如视觉问答(visual question answering,vqa),视觉问答的主要目标就是让计算机根据输入的图片和问题输出一个符合自然语言规则且内容合理的答案。针对一张特定的图片,如果想要有效的通过图像中的视觉特征与问题中的语义特征相关联从而推断出问题的答案,需要让视觉问答模型对图片的内容、问题的含义和意图以及相关的常识有一定的理解。视觉问答任务涉及到细粒度识别、物体识别和对问题所包含文本的理解等多方面的技术。通常视觉问答模型由三个模块构成。特征提取模块使用卷积神经网络提取图片的特征,使用循环神经网络提取问题的特征;特征融合模块将问题特征与图片特征融合为一个能够表征当前任务的抽象特征;答案分类模块将融合后的特征作为输入,对该特征进行分类,分类类别数由候选答案的数量决定。而最近提出的数据集textvqa和st
‑
vqa都是带有文字信息的场景图片,数据集中每张图像都带有真实存在的文字语义并且需要理解图像场景文本来回答问题。使用一般的视觉问答模型去处理,在这些数据集上普遍表现的效果并不好。针对带有视觉、文本和问题信息特征的多模态数据集,目前更多的是使用transformer或者使用图神经网络(graph neural network,gnn)来将不同的模态信息融合在一起,其中,多模态图神经网络mm
‑
gnn使用图神经网络将图像表示为三个图,并引入三个聚合器来引导消息从一个图传递到另一个图预测生成答案。
3.现有技术的mm
‑
gnn用于回答需要阅读的许多问题。给定一个包含可视对象和场景文本的图像和一个问题,其目标是生成答案。mm
‑
gnn分三个步骤回答了问题:(1)构建构建一个三层图结构,用于表示图像中的三种模态,即视觉实体(包括文本和对象)的视觉模态、场景文本的语义模态和与数字相关的文本的数值模态,三个图中节点的初始表示是由先验得到的,例如从语料库学习到的单词嵌入和更快的rcnn特征。(2)mm
‑
gnn用三个基于注意力的聚合器,这些聚合器根据两个节点在图像中的视觉外观和布局信息以及问题来计算它们的相关性得分,通过图间或图内的方式传递信息,它们可以引导一个子图之间的信息流到另一个子图或自身,依次动态更新节点的表示,更新后的表示包含更丰富、更精确的信息,使回答模型更容易注意到正确的答案。(3)答案预测模块,利用这些特性输出答案。
4.mm
‑
gnn在聚合之前使用隐式的全连接图没有进行特征过滤,即没有去掉无用或者冗余的特征,提取特征时会效果不好。在聚合时候使用三个聚合器去聚合特征,对于语义和语义集合和语义
‑
数值聚合相比较视觉
‑
语义聚合意义作用不大,消耗计算量过多。
技术实现要素:
5.基于以上现有技术的不足,本发明所解决的技术问题在于提供一种基于模态推理图神经网络的场景文本视觉问答方法,利用图像中多种形式的信息帮助理解场景文本内容,利用不同模态的上下文信息为答疑模块提供了更好的功能。
6.为了解决上述技术问题,本发明提供一种基于模态推理图神经网络的场景文本视觉问答方法,包括以下步骤:
7.步骤1:构建多模态图;
8.步骤2:使用问题词序列来生成自注意力权重,将经过预处理的问题词嵌入与两个独立的权重相乘分别得到视觉问题特征和文本问题特征;
9.步骤3:在视觉问题特征和文本问题特征的指导下计算注意力权重,输入到softmax中,然后将权重与特征节点对应相乘即得到过滤后的向量;
10.步骤4:利用语义上下文完善视觉节点,使子图之间的信息相互融合,更准确地回答关于场景图像中文本的问题;
11.步骤5:更新之后的节点与对应问题特征相乘后连接输出预测答案。
12.可选的,在步骤2中,给定t个单词的问题,使用预训练的bert把单词嵌入到特征序列中,然后使用两个独立的双层mlp生成两组注意力权重,生成视觉问题特征和文本问题特征。
13.由上,本发明的基于模态推理图神经网络的场景文本视觉问答方法具有如下有益效果:
14.本发明利用图像中多种形式的信息帮助理解场景文本内容,将场景文本图片分别预处理成视觉对象图和文本图的形式,并且在问题自注意力模块下过滤多余的信息;使用加入注意力的聚合器完善子图之间相互的节点特征从而融合不同模态之间的信息,更新后的节点利用不同模态的上下文信息为答疑模块提供了更好的功能。在st
‑
vqa和textvqa数据集上验证了有效性,实验结果表明,相比较此任务的一些其他模型,本发明所提出模型mrgnn(multi
‑
modal reasoning graph neural network,mrgnn)在此任务上有明显的提升。
15.上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下结合优选实施例,并配合附图,详细说明如下。
附图说明
16.为了更清楚地说明本发明实施例的技术方案,下面将对实施例的附图作简单地介绍。
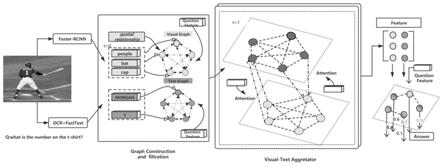
17.图1为基于多模态图神经网络推理视觉问答模型结构图。
具体实施方式
18.下面结合附图详细说明本发明的具体实施方式,其作为本说明书的一部分,通过实施例来说明本发明的原理,本发明的其他方面、特征及其优点通过该详细说明将会变得一目了然。在所参照的附图中,不同的图中相同或相似的部件使用相同的附图标号来表示。
19.视觉问答(visual question answering,vqa)模型在处理场景文本任务时,需要通过阅读图像中的视觉内容和文本内容以及推理问题来得到答案,文本阅读能力差和视觉推理能力不足是现有的视觉问答模型效果不好的主要原因,如图1所示,针对以上问题,本发明提供一种基于模态推理图神经网络的场景文本视觉问答方法,包括:
20.构建多模态图
21.提取每个模态的特征,并通过如下的特定领域嵌入方法将它们投射到一个公共的d维语义空间。构建视觉全连通图g
v
={v
v
,ε
v
},节点通过两个学习的线性变换投射到d维空间,并将其总结为最终嵌入,每个边表示两个对象之间的相对空间关系,使用faster
‑
rcnn检测器来确定一组k个对象,对象由2048维的视觉特征向量和四维目标坐标向量组成,其中b
i
=[x
i
,y
i
,w
i
,h
i
],(x
i
,y
i
)、w
i
和h
i
分别表示的坐标、边框的宽度和高度。如公式(1)所示:
[0022][0023]
其中w1和w2是学习的投影矩阵。ln是层归一化文本图g
t
也是一个全连通图,使用四种不同类型的特征来表示ocr形式:(1)一个300维的fasttext向量(2)使用faster
‑
rcnn提取的ocr字段的rol
‑
pooling边框的特征(3)一个604维phoc向量(4)边界框位置然后把每一个特征线性映射到d维空间中,把它们相加作为最终的ocr字段的嵌入,如公式(2)所示:
[0024][0025]
问题自注意模块
[0026]
问题特征的提取对最终的答案起着关键性的作用,为了把握模态之间的相互作用,来获得最佳的效果。从bertbase的前3层中提取问题词特征,使用问题词序列来生成自注意力权重,将经过预处理的问题词嵌入与两个独立的权重相乘分别得到视觉问题特征q
v
和文本问题特征q
s
。具体来说,给定t个单词的问题使用预训练的bert把单词嵌入到特征序列中得到然后使用两个独立的双层mlp生成两组注意力权重,然后使用两个独立的双层mlp生成两组注意力权重,生成视觉问题特征q
v
和文本问题特征q
s
,以视觉问题特征为例,公式如下:
[0027][0028][0029]
特征过滤模块
[0030]
本发明在进入融合之前过滤掉不相关或多余的特征,问题自注意力模块,把视觉问题特征q
v
和文本问题特征q
s
作为特征的query,在视觉问题特征q
v
和文本问题特征q
s
的指导下计算注意力权重,输入到softmax中,然后将权重与特征节点对应相乘即得到过滤后的向量。以视觉特征为例,公式如下:
[0031][0032]
s
i
=soft max(a
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0033][0034]
多模态聚合模块
[0035]
使用聚合器来聚合视觉和文本节点,目标是用图像视觉内容去精炼文本图的节点,利用语义上下文完善视觉节点,使子图之间的信息相互融合从而能够更准确地回答关于场景图像中文本的问题。对于过滤后的文本节点聚合器首先对视觉图中相关的节点进行访问,然后将参与节点的信息进行聚合,更新的表示。具体需要计算节点之间的相关性分数视觉节点及其边界框特征b
ti
和b
vi
(即边界框的坐标),问题特征是问题自注意模块来提取获得,计算公式为:
[0036][0037]
f
s
,f
v
,f
b
分别为处理语义节点,视觉节点,边界框特征的mlp,|;|表示连接两个向量。
[0038][0039][0040]
将聚合后的特征与节点连接,从而得到更新的语义表达,其中是更新的节点表示,f
v~
是一个用于编码相关节点特征的mlp。
[0041]
与文本节点更新类似,我们获取的更新节点。公式如下:
[0042][0043][0044]
答案预测模块
[0045]
更新之后的节点与对应问题特征相乘后连接输出预测答案,如公式(5)所示,其中为f
p
mlp,为element
‑
wise。得到预测结果(k为候选答案数目),之后预测答案输入到二元交叉熵损中进行优化训练。
[0046]
[0047]
问题特征:将问题最大长度设为20,使用经过维基百科数据集预先训练的三层bert模型来对问题进行编码,并且在训练中进行微调。
[0048]
视觉特征:对象区域的最大数为36,使用faster
‑
rcnn模型检测对象,通过fc6提取特征并使用faster
‑
rcnn的池化层,微调fc7输出2048维的特征向量,并且使用边框坐标嵌入到特征里。
[0049]
文本特征:在图中最多识别50个ocr令牌,使用rosetta ocr系统在每个图像上提取文本标记(我们只使用rosetta
‑
en),使用与视觉特征相同的提取器(faster r
‑
cnn是为一般目标检测而训练的),并加入fasttext和phoc(是从识别的ocr字符序列中提取的)以及坐标嵌入。
[0050]
本发明使用pytorch实现,adamax优化,在nvidia geforce 1080ti gpu上进行实验,批处理大小为128个,学习速率设置为0.0001,我们在14000和19000次迭代时将学习率乘以0.1,并且训练的最大迭代次数为24000次。
[0051]
对于场景文本图片进行多模块推理时,模型可以识别、复制和标记图像中文本信息并且结合其固定词汇来预测答案,无论是特征识别还是空间推理效果,在大多数情况下都是优秀的。通过球员的问题查询,注意力模块引导ocr系统关注更多与球员名字相关的信息和球员所在的区域,因为模型知道“casilla”下面的单词很可能是数字。ocr token“rx405”结合了问题中“boat”的位置和语义信息,可以在回答模块中进行选择。
[0052]
以上所述是本发明的优选实施方式而已,当然不能以此来限定本发明之权利范围,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和变动,这些改进和变动也视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1