一种基于BTBC模型的知识图谱构建方法
一种基于btbc模型的知识图谱构建方法
技术领域
1.本发明属于深度学习和自然语言处理技术领域,具体的说是涉及一种基于btbc模型的知识图谱构建方法。
背景技术:
2.知识图谱的构建是指利用自然语言处理和深度学习的技术,从非结构化文本中抽取、存储的过程。目前,知识图谱构建研究涉及多个领域,包括自然语言处理、机器学习和信息抽取等,得到了许多研究者的关注。在领域知识图谱中,医疗知识图谱占有很大比例,例如linked life data项目包括25个公共生物医学数据库,可以访问100亿个rdf语句,包括基因、药物、临床试验和副作用等等。医疗知识图谱的构建可以应用于辅助医生对疾病进行诊断,减少查阅资料的时间,提高工作效率,降低治疗成本,挖掘药物间的相似联系;对于用户而言,知识图谱的应用可以使医学问答更加智能和专业,同时方便用户在搜索引擎中查询疾病或症状。
3.知识图谱的构建实质上就是将基础数据以多种方法和技术构建成一个三元组集合的过程,涉及到数据获取、实体关系抽取、知识表示、知识融合、知识存储和知识推理等多项技术。
4.上下文编码器常使用卷积神经网络(cnn)和循环神经网络(rnn)。其中,cnn能够提取输入数据的局部特征,因此主要用于特征的学习;rnn考虑句子中字符间的影响,可同时用于特征学习和序列标注,rnn中的长短期记忆网络(lstm)在序列数据建模方面取得了显著成效,特别是双向lstm(bilstm〉能从两个方向来处理一个句子。但是没有词嵌入层,随机初始化效果不稳定。
5.bert最大的创新在于用transformer同时引入上下文信息。该模型用transformer encoder的结构,为了防止标签泄漏,提出了masked lm的预训练,引入上下文信息参与训练,但是在计算的过程中弱化了位置信息。
6.cn112347265a公开了一种知识图谱构建方法,该方法对需要处理的句子进行分词,得到多个单独词;识别多个单独词中的实体,得到两个一组的实体对;对于每个实体对,获取句子的句向量;根据句向量,提取所述句子的表示特征;对所述表示特征进行特征筛选,屏蔽其中的噪声特征;根据表示特征预测所述实体对的实体关系;根据实体对和对应的实体关系构建知识图谱,虽然此方法可以将实现了噪声特征的滤除,但是这种知识图谱的构建需要投入了大量的人工和时间投入,且构建知识图谱的效率低成本高。
技术实现要素:
7.为了解决上述问题,本发明提供了一种基于btbc模型的知识图谱构建方法,针对现有的bert模型进行改进,用lstm习得观测序列上的依赖关系,最后再用crf习得状态序列的关系并得到答案。
8.为了达到上述目的,本发明是通过以下技术方案实现的:
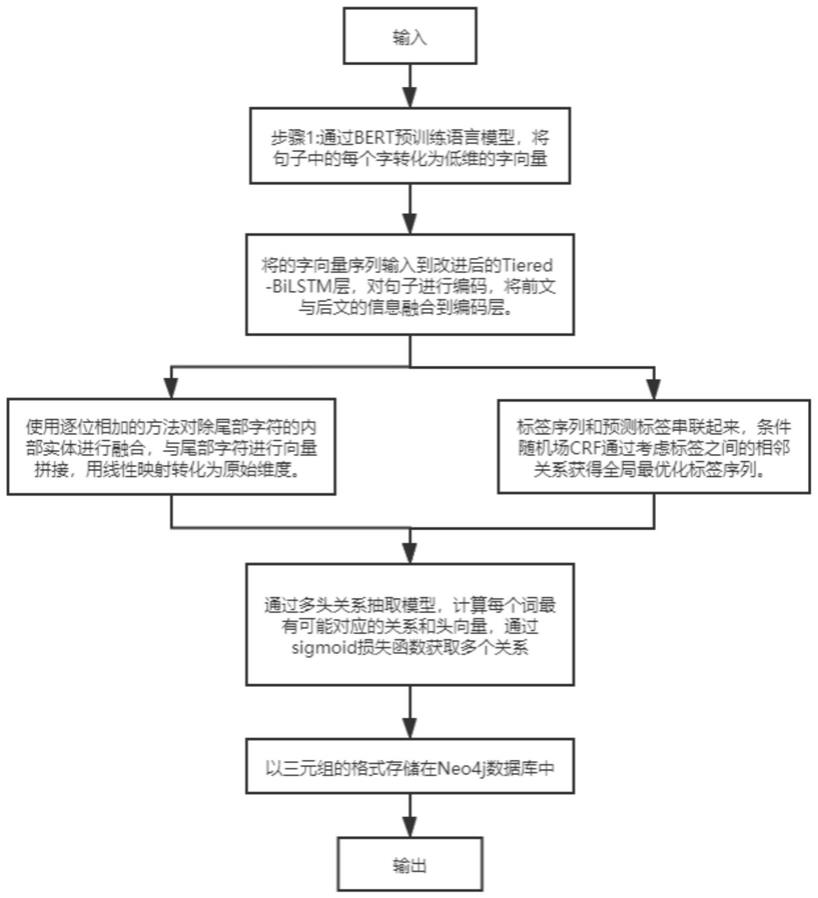
9.本发明是一种基于btbc模型的知识图谱构建方法,该btbc模型包括词嵌入层、上下文编码层、嵌套命名实体识别、关系抽取层和知识存储层,该知识图谱构件方法包括如下步骤:
10.步骤1、通过bert预训练语言模型,将句子中的每个字转化为低维的字向量。
11.步骤1中的预训练具体为:面对爬取的大量无标注数据,使用百度百科的词条名,以及半结构化数据形成的三元组中的实体,组合并去除重复值来对非结构化数据进行回标,从而自动产生大量训练语料,因为bert模型对输入句子有最大长度的要求,还需要按照句号对长句进行截断。
12.步骤1中的bert模型是一种transformer的双向编码器,将输入的训练语料编码成字向量,再把子向量序列输入到堆叠ner层,ner层是嵌套命名实体识别层。
13.步骤2、将步骤1得到的字向量序列输入到改进后的tiered-bilstm层,对句子进行编码,将前文与后文的信息融合到上下文编码层;
14.所述步骤2具体为:
15.步骤2-1:在t时刻,给定输入x
t
,tiered-bilstm的隐藏层输出表示的具体计算过程如公式(1)(2)(3)(4)(5)获得:
16.i
t
=σ(w
xi
x
t
+w
hiht-1
+w
cict-1
+bi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
17.f
t
=σ(w
xf
x
t
+w
hfht-1
+w
cfct-1
+bf)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
18.c
t
=f
tct-1
+i
t
tanh(w
x
cx
t
+w
hcht-1
+bc)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
19.o
t
=σ(w
xo
x
t
+w
hoht-1
+w
coct
+bo)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
20.h
t
=o
t
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
21.其中,w为两层之间的权重矩阵,w
xi
为输入层到输入们的权重矩阵,b为偏置向量,bi为输入门的偏执向量,c为记忆单元状态,σ和tanh为两种激活函数,i
t
为输入门,o
t
为输出门,f
t
为遗忘门,h
t
为输出向量;这种存储单元能够有效过滤和记忆单元的信息,对长距离信息能够有效利用,解决了rnn模型容易产生的梯度弥散问题。
22.步骤2-2:对于给定输入序列(x1,x2,...,xn),每个单词表示为d维向量,前向tiered-bilstm计算每个单词t从左向右句子的上下文表示相应的,使用后向tiered-bilstm反向读取相同的序列,从而得到从右向左的上下文表示通过将单词的左右上下文表示串联在一起,得到使用该模型的单词表示为:
[0023][0024]
步骤2-3:对于给定序列x=(x1,x2,...,xn)和对应的标签序列y=(y1,y2,...,yn),通过tiered-bilstm层后,经过线性映射得到每个标签的得分为:
[0025]
pi=w
sht
+bsꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0026]
其中h
t
是上一层t时刻tiered-bilstm层的输出,ws和bs是线性映射参数。
[0027]
步骤3、将步骤2检测到的实体上下文表示进行融合,使用逐位相加的方法对除尾部字符的内部实体进行融合,再与尾部字符进行向量拼接,最后用线性映射转化为原始维度;
[0028]
在所述步骤3中,最后用线性映射转化为原始维度具体方法为:
[0029][0030]
其中z
start
表示当前平面ner识别出的实体中第一个单词的表示形式,z
end
为实体中最后一个单词表示形式,w为线性映射参数,mi是实体的融合表示形式,融合从实体位置的起点开始,并在实体位置的终点结束,如果该区域被检测为实体,这种融合表表示形式允许将检测到的实体作为单个字符处理;如果该区域被检测为非实体,则将该表示传递到下一层,而不进行任何处理。
[0031]
步骤4、将步骤2得到的标签序列和预测标签串联起来得到标签转移分数,条件随机场crf通过考虑标签之间的相邻关系获得全局最优化标签序列;
[0032]
所述步骤4中的具体步骤为:
[0033]
步骤4-1:crf定义从输入序列到标签序列的标签转移分数:
[0034]
其中w为转换矩阵,表示标签转移分数,表示该字符第yi个标签的得分,为了解决标注偏置问题,crf需要做全局归一化,具体而言就是输入x对应的标签序列为y的概率定义为:
[0035][0036]
步骤4-2:在训练过程中,希望最大化正确标签序列的对数概率,即:
[0037][0038]
其中,λ和θ为正则化参数。
[0039]
步骤5、将步骤3的原始维度和步骤4的全局最优化标签序列拼接,通过多头关系抽取模型,计算每个词最有可能对应的关系和头向量,通过sigmoid损失函数获取多个关系;
[0040]
所述步骤5具体为:
[0041]
步骤5-1:通过下列公式计算每个词最有可能对应的关系和头向量得到rel_scores
[0042]s(r)
(zj,zi,zk)=v
(r)
f(u
(r)
zj+w
(r)
zi+b
(r)
)
ꢀꢀꢀꢀꢀꢀ
(11)
[0043]
其中上标表示关系抽取,f()为激活函数,relu激活函数,tanh激活函数;
[0044]
步骤5-2:将步骤5-1得到的分数经过sigmoid函数处理,就得到token wi与关系rk的概率,训练时最小化关系抽取的损失函数,来对模型的参数进行优化:
[0045][0046]
其中是wi的ground truth头像量和相对应的关系标签;m是对于wi的关系数量,默认对于一个头只选出一种关系;θ是参数集合。预测中只要控制计算后的概率值大于所有真实标签值得到的最低概率,这样为一个关系对。
[0047]
步骤6、将步骤5输出以三元组的格式存储在neo4j图数据库中,具体为:采用neo4j图数据库,基本元素为节点、边和属性,节点用来存储实体和属性,边用来存储实体间的关系,使用拓扑结构来存储,将数据以可视化的形式展示出来。
[0048]
本发明的有益效果是:本发明的btbc模型的知识图谱构建方法通过将bert模型和
改进后的bilstm-crf模型结合,bert模型克服了bilstm-crf需要大量的标注样本的缺点,改进后的lstm-crf层通过加强实体尾部字符的权重来强化对嵌套实体的识别,突出了上下文语义特征中的重要特征,在识别多对关系的基础上,有效解决了实体重叠的问题,提高图谱构建的准确性。
附图说明
[0049]
图1是本发明的知识图谱构建方法流程。
具体实施方式
[0050]
以下将以图式揭露本发明的实施方式,为明确说明起见,许多实务上的细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用以限制本发明。也就是说,在本发明的部分实施方式中,这些实务上的细节是非必要的。此外,为简化图式起见,一些习知惯用的结构与组件在图式中将以简单的示意的方式绘示之。
[0051]
如图1所示,本发明是一种基于btbc模型的知识图谱构建方法,其特征在于:所述btbc模型包括词嵌入层、上下文编码层、嵌套命名实体识别、关系抽取层和知识存储层,具体的,知识图谱构件方法包括如下步骤:
[0052]
步骤1、通过bert预训练语言模型,将句子中的每个字转化为低维的字向量。
[0053]
面对爬取的大量无标注数据,使用百度百科的词条名,以及半结构化数据形成的三元组中的实体,组合并去除重复值来对非结构化数据进行回标,从而自动产生大量训练语料,因为bert模型对输入句子有最大长度的要求,还需要按照句号对长句进行截断。
[0054]
步骤2、将步骤1得到的字向量序列输入到改进后的tiered-bilstm层,对句子进行编码,将前文与后文的信息融合到上下文编码层。
[0055]
具体为:
[0056]
步骤2-1:在t时刻,给定输入x
t
,tiered-bilstm的隐藏层输出表示的具体计算过程如公式(1)(2)(3)(4)(5)获得:
[0057]it
=σ(w
xi
x
t
+w
hiht-1
+w
cict-1
+bi)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0058]ft
=σ(w
xf
x
t
+w
hfht-1
+w
cfct-1
+bf)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0059]ct
=f
tct-1
+i
t
tanh(w
x
cx
t
+w
hcht-1
+bc)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0060]ot
=σ(w
xo
x
t
+w
hoht-1
+w
coct
+bo)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0061]ht
=o
t
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0062]
其中,w为两层之间的权重矩阵,w
xi
为输入层到输入们的权重矩阵,b为偏置向量,bi为输入门的偏执向量,c为记忆单元状态,σ和tanh为两种激活函数,i
t
为输入门,o
t
为输出门,f
t
为遗忘门,h
t
为输出向量;这种存储单元能够有效过滤和记忆单元的信息,对长距离信息能够有效利用,解决了rnn模型容易产生的梯度弥散问题。
[0063]
步骤2-2:对于给定输入序列(x1,x2,...,xn),每个单词表示为d维向量,前向tiered-bilstm计算每个单词t从左向右句子的上下文表示相应的,使用后向tiered-bilstm反向读取相同的序列,从而得到从右向左的上下文表示通过将单词的左右上下文表示串联在一起,得到使用该模型的单词表示为:
[0064][0065]
步骤2-3:对于给定序列x=(x1,x2,...,xn)和对应的标签序列y=(y1,y2,...,yn),通过tiered-bilstm层后,经过线性映射得到每个标签的得分为:
[0066]
pi=w
sht
+bsꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0067]
其中h
t
是上一层t时刻tiered-bilstm层的输出,ws和bs是线性映射参数。
[0068]
步骤3、将步骤2检测到的实体上下文表示进行融合,使用逐位相加的方法对除尾部字符的内部实体进行融合,再与尾部字符进行向量拼接,最后用线性映射转化为原始维度,具体方法为:
[0069][0070]
其中z
start
表示当前平面ner识别出的实体中第一个单词的表示形式,z
end
为实体中最后一个单词表示形式,w为线性映射参数,mi是实体的融合表示形式,融合从实体位置的起点开始,并在实体位置的终点结束,如果该区域被检测为实体,这种融合表表示形式允许将检测到的实体作为单个字符处理;如果该区域被检测为非实体,则将该表示传递到下一层,而不进行任何处理。
[0071]
步骤4、将步骤2得到的标签序列和预测标签串联起来得到标签转移分数,条件随机场crf通过考虑标签之间的相邻关系获得全局最优化标签序列;
[0072]
计算输入序列到标签序列的标签转移分数,将步骤3得到的输出序列带入公式(8):
[0073][0074]
其中w为转换矩阵,表示标签转移分数,表示该字符第yi个标签的得分,为了解决标注偏置问题,crf需要做全局归一化,具体而言就是输入x对应的标签序列为y的概率定义为:
[0075][0076]
步骤4-2:在训练过程中,希望最大化正确标签序列的对数概率,即:
[0077][0078]
其中,λ和θ为正则化参数。
[0079]
步骤5、将步骤3的原始维度和步骤4的全局最优化标签序列拼接,通过多头关系抽取模型,计算每个词最有可能对应的关系和头向量,通过sigmoid损失函数获取多个关系。
[0080]
步骤5-1:将步骤3和步骤4的输出拼接,作为步骤4的关系抽取任务的输入,通过下列公式计算每个词最有可能对应的关系和头向量得到rel_scores
[0081]s(r)
(zj,zi,zk)=v
(r)
f(u
(r)
zj+w
(r)
zi+b
(r)
)
ꢀꢀꢀꢀꢀꢀ
(11)
[0082]
其中上标表示关系抽取,f()为激活函数,relu激活函数,tanh激活函数;
[0083]
将上面得到的分数经过sigmoid函数处理,就得到token wi与关系rk的概率,训练时最小化关系抽取的损失函数,来对模型的参数进行优化:
[0084]
[0085]
其中是wi的ground truth头像量和相对应的关系标签;m是对于wi的关系数量,默认对于一个头只选出一种关系;θ是参数集合。
[0086]
预测中只要控制计算后的概率值大于所有真实标签值得到的最低概率,这样为一个关系对。这样既可以判断是否存在关系,也能识别句子中是否有多对关系,有效解决了实体重叠问题。
[0087]
步骤6、将步骤5输出以三元组的格式存储在neo4j图数据库中,使用拓扑结构来存储,将数据以可视化的形式展示出来。
[0088]
词嵌入层将医疗信息的数据集编码为词向量,上下文编码层采用tiered-bilstm-crf模型,通过动态堆叠平面ner层来识别嵌套实体,每个平面ner层均为bilstm-crf的平面ner模型,每一层将lstm层的实体输出融合,再输出到下一个平面ner层中,关系抽取层采用多头关系抽取模型,最后以三元组的格式存储在neo4j图数据库里。本发明得btbc模型将bert和bilstm-crf联合,有效解决了实体重叠的问题,提高图谱构建的准确性。
[0089]
以上所述仅为本发明的实施方式而已,并不用于限制本发明。对于本领域技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原理的内所作的任何修改、等同替换、改进等,均应包括在本发明的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1