一种基于K-Means及步态周期相似性的运动模式识别方法与流程
一种基于k
‑
means及步态周期相似性的运动模式识别方法
技术领域
1.本发明涉及一种基于k
‑
means及步态周期相似性的运动模式识别方法,属于外骨骼机器人领域。
背景技术:
2.运动意图感知是外骨骼机器人助力的基础和前提,而运动模式识别是运动意图感知的重要组成部分。人体运动模式是指外骨骼机器人运动过程中,所处的站立、平地行走、平地跑步、上楼、下楼等状态。如何快速识别当前运动模式对实时调整助力策略、提高外骨骼助力效果具有重要意义。
3.目前运动模式识别多采用机器学习或模板匹配,前者存在计算量大,难以在低功耗嵌入式中应用的缺点;后者需根据实际情况手动生成模板,且精度有限。
技术实现要素:
4.本发明解决的技术问题是:针对目前现有技术中,传统外骨骼机器人运动模式识别多采用机器学习计算量大或模板匹配精度有限的问题,提出了一种基于k
‑
means及步态周期相似性的运动模式识别方法。
5.本发明解决上述技术问题是通过如下技术方案予以实现的:
6.一种基于k
‑
means及步态周期相似性的运动模式识别方法,步骤如下:
7.(1)离线采集数据并生成模板向量;
8.(2)进行识别过程中,将实时采集数据经过处理后,获取实时特征向量并与步骤(1)所得模板向量进行相似性分析;
9.(3)根据相似性分析结果进行运动模式识别分类,并给出当前分类结果的概率。
10.所述步骤(1)中,生成模板向量的具体步骤为:
11.离线采集数据并进行处理后,进行步态周期划分,通过特征提取生成特征向量,并根据特征向量生成模板向量。
12.所述步骤(2)中,生成实时特征向量的具体步骤为:
13.采集实时数据并进行处理后,进行步态周期划分,通过特征提取生成特征向量。
14.根据运动周期性,对离线数据或实时数据进行数据压缩,获取步态周期数据切片,完成步态周期划分。
15.根据步态周期数据切片,进行降采样,具体方法为:
16.于步态周期数据{x(k)|k=1,
…
,n}中均匀采样p个数据点x={x(mi)|i=1,
…
,p},处理后获取特征向量mi=1+[(i
‑
1)*n/p];
[0017]
其中,x(k)为当前数据切片中序号为k的数据;n为当前数据切片中数据总个数;mi为采样点的序号;[x]为不大于x的最大整数。
[0018]
将特征向量x={x(k)|k=1,
…
,p}进行归一化及单位偏移处理,获取特征向量集合x'=x/(||x||)+e;
[0019]
式中,||x||为x的模;e为单位向量。
[0020]
采用k
‑
means聚类方法对特征向量集合进行聚类,将各聚类中心与运动模式进行匹配分类,以各类运动模式对应的标准向量集作为该类运动模式带有分类标签的模板向量集。
[0021]
所述基于k
‑
means聚类方法具体为:
[0022]
(1)根据运动模式种类m设定类别数k初值k=m;
[0023]
(2)于特征向量集合中选择初始化的k个样本作为初始聚类中心;
[0024]
(3)计算特征向量集合中各样本到k个聚类中心的距离,并将该样本分类至距离最小的聚类中心对应分类中;
[0025]
(4)重新计算各聚类中心;
[0026]
(5)重复步骤(3)、步骤(4),直至无任意特征向量被重新分配至其它聚类或迭代次数达到指定阈值;
[0027]
(6)对各聚类中心进行评估,判断是否具有代表性,若不具有代表性,则增加k值,并返回步骤(2),若具有代表性,则进入步骤(7);
[0028]
(7)获取k个聚类中心,与运动模式进行匹配分类,获取带标签的模板向量集。
[0029]
所述相似性分析具体为:
[0030]
根据相似性度量函数对当前实时数据获取的特征向量与模板向量集进行分类匹配,相似性度量函数具体为:
[0031]
f(p,q)=var((mp)./(mq))
[0032]
式中,var为方差函数;m为0
‑
1权值矩阵,根据特征向量集合下运动模式分类准确率最高的目标进行调整。
[0033]
本发明与现有技术相比的优点在于:
[0034]
(1)本发明提供的一种基于k
‑
means及步态周期相似性的运动模式识别方法,结合人体运动特点,以整步态周期内数据为对象并进行数据压缩,解决常规方式运算量大的问题,同时提出了基于k
‑
means的标准模板集提取方法,可实现标准模板的半自动生成,同时提出了一种基于方差的相似性度量函数,可根据权值调整度量长度,解决步态周期起始点、终点不确定性对相似性判别准确率下降的问题;
[0035]
(2)本发明通过采集数据离线生成对应类别的模板向量;识别时,将实时采集的数据处理后与模板向量进行相似性分析,根据相似性结果进行运动模式分类,并根据相似性给出当前结果的概率,可半自动提取特征向量集;识别运算量低,以整步态周期内数据为对象处理后比传统直接采用模板匹配方法精度更高。
附图说明
[0036]
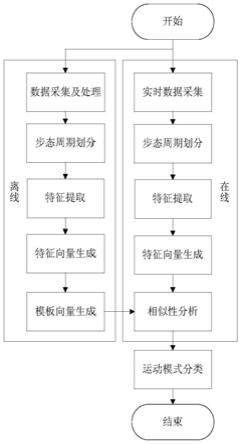
图1为发明提供的基于模板匹配的运动模式识别流程图;
[0037]
图2为发明提供的原向量与处理后的特征向量对比示意图;
[0038]
图3为发明提供的k
‑
means聚类结果示意图;
[0039]
图4为发明提供的运动模式模板向量示意图;
具体实施方式
[0040]
一种基于k
‑
means及步态周期相似性的运动模式识别方法,首先通过采集数据离线生成对应类别的模板向量;识别时,将实时采集的数据处理后与模板向量进行相似性分析,根据相似性结果进行运动模式分类,并根据相似性给出当前结果的概率,识别方法具体步骤如下:
[0041]
(1)离线采集数据并生成模板向量;
[0042]
其中,生成模板向量的具体步骤为:
[0043]
离线采集数据并进行处理后,进行步态周期划分,通过特征提取生成特征向量,并根据特征向量生成模板向量;
[0044]
根据运动周期性,对离线数据或实时数据进行数据压缩,获取步态周期数据切片,完成步态周期划分;
[0045]
根据步态周期数据切片,进行降采样,具体方法为:
[0046]
于步态周期数据{x(k)|k=1,
…
,n}中均匀采样p个数据点x={x(mi)|i=1,
…
,p},处理后获取特征向量mi=1+[(i
‑
1)*n/p];
[0047]
其中,x(k)为当前数据切片中序号为k的数据;n为当前数据切片中数据总个数;mi为采样点的序号;[x]为不大于x的最大整数;
[0048]
需要说明的是,可以根据数据来源或特点选择不同的采样方式。如利用mems惯性导航单元时,增加运动周期前半周期数据采集密度,减小后半周期数据采集密度。
[0049]
将特征向量x={x(k)|k=1,
…
,p}进行归一化及单位偏移处理,获取特征向量集合x'=x/(||x||)+e;
[0050]
式中,||x||为x的模;e为单位向量;
[0051]
采用k
‑
means聚类方法对特征向量集合进行聚类,将各聚类中心与运动模式进行匹配分类,以各类运动模式对应的标准向量集作为该类运动模式带有分类标签的模板向量集;
[0052]
k
‑
means聚类方法具体为:
[0053]
1)根据运动模式种类m设定类别数k初值k=m;
[0054]
2)于特征向量集合中选择初始化的k个样本作为初始聚类中心;
[0055]
3)计算特征向量集合中各样本到k个聚类中心的距离,并将该样本分类至与其距离最小的聚类中心对应分类中;
[0056]
4)重新计算各聚类中心;
[0057]
5)重复步骤(3)、步骤(4),直至无任意特征向量被重新分配至其它聚类或迭代次数达到指定阈值;
[0058]
6)对各聚类中心进行评估,判断是否具有代表性,若不具有代表性,则增加k值,并返回步骤(2),若具有代表性,则进入步骤(7);
[0059]
7)获取k个聚类中心,与运动模式进行匹配分类,获取带标签的模板向量集。
[0060]
(2)进行识别过程中,将实时采集的数据经过处理后,获取实时特征向量并与步骤(1)所得模板向量进行相似性分析;
[0061]
其中,生成实时特征向量的具体步骤为:
[0062]
采集实时数据并进行处理后,进行步态周期划分,通过特征提取生成特征向量;
[0063]
特征向量与原向量对比示意图如图2所示。
[0064]
(3)根据相似性分析结果进行运动模式识别分类,并给出当前分类结果的概率,其中:
[0065]
相似性分析具体为:
[0066]
根据相似性度量函数对当前实时数据获取的特征向量与模板向量集进行分类匹配,相似性度量函数具体为:
[0067]
f(p,q)=var((mp)./(mq))
[0068]
式中,var为方差函数;m为0
‑
1权值矩阵,根据特征向量集合下运动模式分类准确率最高的目标进行调整。
[0069]
与当前实时数据获取的特征向量相似度最高的模板向量种类即为当前运动模式,该分类结果准确的概率由以下公式给出:
[0070][0071]
其中fi为当前实时数据获取的特征向量与模板向量的相似度;fm为fi中的最大值。
[0072]
下面结合具体实施例进行进一步说明:
[0073]
在本实施例中,如图1所示,为运动模式识别方法流程图,首先通过采集数据离线生成模板向量;识别时,将实时采集的数据处理后与模板向量进行相似性分析,根据相似性结果进行运动模式分类,并根据相似性给出当前结果的概率;
[0074]
运动模式识别方法,根据运动周期性,对原始数据进行数据压缩,得到步态周期数据切片;运动模式识别方法,将所得步态周期数据进行降采样,采样方法如下:
[0075]
步态周期数据{x(k)|k=1,
…
,n}内均匀采样出p个数据点x={x(mi)|i=1,
…
,p},处理后作为特征向量。
[0076]
mi=1+[(i
‑
1)*n/p]
[0077]
其中x(k)为当前数据切片中序号为k的数据;n为当前数据切片中数据总个数;mi为采样点的序号;[x]为不大于x的最大整数;
[0078]
运动模式识别方法,将向量x={x(k)|k=1,
…
,p}进行归一化及单位偏移处理,其中:
[0079]
x'=x/(||x||)+e
[0080]
其中,||x||为x的模;e为单位向量;
[0081]
运动模式识别方法,对于特征向量集合,采用k
‑
means进行聚类,将每个聚类中心与运动模式进行匹配分类,每类运动模式对应的标准向量集作为该类运动模式的模板向量集。最后形成带分类标签的模板向量集;
[0082]
k
‑
means聚类方法,其步骤如下:
[0083]
(1)根据运动模式种类m设定类别数k初值k=m;
[0084]
(2)于特征向量集合中选择初始化的k个样本作为初始聚类中心;
[0085]
(3)计算特征向量集合中各样本到k个聚类中心的距离,并将该样本分类至距离最小的聚类中心对应分类中;
[0086]
(4)对步骤(3)分类后的各聚类中心进行重新计算;
[0087]
(5)重复步骤(3)、步骤(4),直至无任意特征向量被重新分配至其它聚类或迭代次数达到指定阈值;
[0088]
(6)对各聚类中心进行评估,判断是否具有代表性,若不具有代表性,则增加k值,并返回步骤(2),若具有代表性,则进入步骤(7);
[0089]
(7)获取k个聚类中心,与运动模式进行匹配分类,获取带标签的模板向量集。
[0090]
将某次包括平地行走、上楼、下楼过程的数据进行聚类,结果如图3、图4所示,其中图4为聚类中心形成的模板向量。
[0091]
运动模式识别方法,基于相似性对当前数据与模板向量进行分类匹配。相似性度量函数如下:
[0092]
f(p,q)=var((mp)./(mq))
[0093]
其中var为方差函数;m为0
‑
1权值矩阵,以特征向量集合下运动模式分类准确率最高为目标进行调整。
[0094]
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
[0095]
本发明说明书中未作详细描述的内容属于本领域技术人员的公知技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1