一种基于层级化聚类的金融新闻流突发检测方法
1.本发明涉及金融新闻数据挖掘领域,尤其是一种基于层级化聚类的金融新闻流突 发检测方法。
背景技术:
2.投资者是金融市场的重要参与者,一旦爆发金融突发事件,将殃及广大投资者。 对于金融突发事件的检测,有助于帮助投资者规避风险。
3.近年来,金融行业相关的舆情呈现“浪涌”态势,出现时间相对集中、信息交互 量大,交互次数频繁。金融舆情的产生、扩大和传播对投资者、金融机构、金融业乃 至宏观经济运行都会产生重要影响,往往一些小的信用危机,则有可能酿成金融危机 事件,因此,对金融舆情进行监测与应对可以把握预期管理的节奏,减少和避免金融 舆情危机的爆发。金融行业目前应对突发事件存在以下问题:
4.1.危机意识薄弱,金融突发事件监控力度不够;
5.2.金融突发事件应对体系不够完善;
6.3.金融突发事件发生时网络舆论的引导和处置不够专业。
7.这些问题也是由于现行对于金融突发事件的监控方法所导致的,当前的方法以专业人 员梳理新闻脉络根据潜在规律分析为主。专业人员通常会通过观察宏观、中观(行业)、 微观(企业)的新闻事件再根据过去的经验辅助推断可能会发生某个类似的金融突发 事件。宏观新闻主要包括以下几种:
8.1.国际政治军事的大事件。有可能造成国际局势动荡的大事件,都会造成避险资产(黄 金、白银、美元、日元、瑞士法郎)的升值,风险资产(尤以股票为甚)的下跌。相 反,当国际局势趋于明朗安定的时候,避险资产会下跌,市场风险偏好会增加。
9.2.国内财政政策。一般减税、大型基建计划推出时会利好股市。
10.3.国内货币政策。降准、公开市场操作、调整再贴现利率、信贷政策等也会对债市、 股市、汇市产生影响。
11.4.定期发布的宏观经济数据。具体而言,有ppi(生产者物价指数),cpi(消费者物 价指数),gdp,pmi,美国非农就业人数等。
12.5.国际经贸协定。
13.中观的行业新闻包括以下几种:
14.1.产业政策。例如,医保政策限定药品采购价,医药股大跌。
15.2.产业自身及其上下游重大技术进展,特别是可能改变行业竞争格局的技术进展。
16.3.个别的突发新闻。
17.微观(企业个体、某类商品)新闻主要包括以下几种:
18.1.大宗商品供需;
19.2.公司财务报表发布;
20.3.公司新产品销售状况;
21.4.公司自身重大风险事件;
22.5.股东减持、解禁等;
23.6.公司并购与重组等。
24.从以上内容可以看出监控金融突发事件需要考虑的新闻数据和要素繁多,仅依靠 人力去分析判断无法满足多层次、全方位、全屏全网全时段全天候的金融事件监控力 度;无法及时建立应对体系来调查金融新闻舆情传播源头,路径,传播范围;无法低 成本的培训大量相关人员快速上手进行金融事件的监控和处理。
技术实现要素:
25.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种可以高 效准确的对金融突发事件进行聚类和识别的方法。
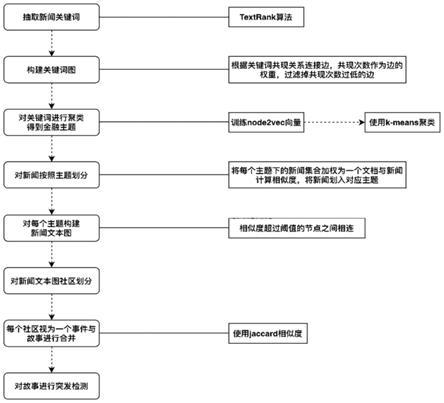
26.为了解决上述技术问题,本发明公开了一种基于层级化聚类的金融新闻流突发检 测方法,包括如下步骤:
27.步骤s1:文本的预处理;
28.步骤s2:抽取关键词并构建关键词共现图;
29.步骤s3:采用二分k
‑
means算法对关键词聚类,将关键词共现图划分为若干子图, 每个子图中的关键词为一个金融主题;
30.步骤s4:通过相似度计算识别每篇金融新闻所属金融主题;
31.步骤s5:构建以每篇金融新闻为节点的无向图,采用二分k
‑
means算法对金融新 闻聚类,将金融新闻节点无向图划分为若干子图,每个子图中的金融新闻为一个 金融事件;
32.步骤s6:通过相似度计算生成故事链;
33.步骤s7:突发事件检测。
34.步骤s1包括:
35.步骤s11:通过网络爬虫获取金融新闻文本;
36.步骤s12:去除金融新闻文本中的非正文冗余内容,包括页面标签和非法字符;
37.步骤s13:获取金融新闻信息,包括新闻标题、新闻正文和新闻发布时间三个信息;
38.步骤s14:对金融新闻创建索引。
39.进一步地,步骤s11中,金融新闻文本数据来源可以包括巨潮资讯(证监会信息 披露网站),同花顺(财经资讯网站),东方财富(财经资讯网站),凤凰财经(财经资 讯网站),新浪财经(新浪财经)以及华为,阿里巴巴,腾讯,新城控股等公司官网发 布的公告。
40.进一步地,步骤s14中,对金融新闻清洗后创建关系型数据库存储格式的索引, 字段包括新闻编号(唯一标识),新闻类型,发布时间,新闻来源网站,新闻链接,作 者,标题,新闻内容。
41.步骤s2包括:
42.步骤s21:对步骤s1中预处理后的数据进行中文分词处理,去除停用词,获得候 选词集;
43.步骤s22:用一定的关键词提取方法从候选词集中提取关键词;
44.步骤s23:以关键词作为节点,任意两个关键词的共现关系为边构建关键词共现图;
45.步骤s24:过滤关键词共现图中共现频次小于阈值thre1以及共现频率小于阈值 thre2的边。
46.进一步地,步骤s22中,关键词提取方法是:利用textrank算法将候选词以重要 性进行排序,取出排名靠前的若干词;利用kp
‑
miner算法将候选词以权重进行排序, 取出排名靠前的若干词;从两种方法取出的若干词中筛选出较好的关键词。
47.进一步地,步骤s22中,可采用机器学习代替textrank算法对关键词进行识别。
48.进一步地,步骤s24中,阈值thre1的取值范围是[1,5],当阈值thre1=1时,规模 较大的公司如华为所构建的关键词共现图中边的数目大概在10000左右,当阈值 thre1=5时,关键词共现图中边的数目大概在2000左右。
[0049]
优选地,步骤s24中,阈值thre1=3。
[0050]
进一步地,步骤s24中,阈值thre2的取值范围是[0.05,0.25],在thre1=3的条件 下,当阈值thre2=0.05时,关键词共现图中边的数目大概在6500左右,当阈值 thre2=0.25时,关键词共现图中边的数目大概在2200左右。
[0051]
优选地,步骤s24中,阈值thre2=0.15。
[0052]
步骤s3包括:
[0053]
步骤s31:对步骤s2中构建的关键词共现图使用图挖掘算法,得到每个关键词节 点表示向量;
[0054]
步骤s32:训练步骤s31中得到的关键词节点表示向量;
[0055]
步骤s33:通过二分k
‑
means算法,将关键词共现图划分为若干个子图,每个子 图中的关键词为同一个金融主题。
[0056]
进一步地,步骤s31中,使用的图挖掘算法为:图表示学习算法node2vec。
[0057]
步骤s4包括:
[0058]
步骤s41:将每个金融主题通过词袋模型表示为向量,构建k
‑
d树;
[0059]
步骤s42:将每篇金融新闻表示为tf
‑
idf向量;
[0060]
步骤s43:通过k
‑
d树最近邻搜索,将每篇金融新闻划分入对应的金融主题,最 终所有金融新闻被划分为若干个金融主题。
[0061]
步骤s5包括:
[0062]
步骤s51:在一个金融主题下,以每篇金融新闻作为节点,任意两篇金融新闻的相 似度作为边的权重相连,构建金融新闻节点无向图;
[0063]
步骤s52:过滤上述金融新闻节点无向图中相似度小于阈值thre3的边;
[0064]
步骤s53:利用td
‑
idf加权词向量生成金融新闻节点无向图中每个金融新闻节点 表示向量;
[0065]
步骤s54:训练s53中得到的金融新闻节点表示向量;
[0066]
步骤s55:通过二分k
‑
means算法,将金融新闻节点无向图划分为若干个子图, 每个子图中的金融新闻为同一个金融事件;
[0067]
步骤s56:将一个金融事件下所有金融新闻的关键词的并集作为该金融事件的关键 词。
[0068]
进一步地,步骤s51中,计算任意两篇金融新闻的余弦相似度或jaccard相似度作 为边的权重。
[0069]
进一步地,步骤s52中,阈值thre3的取值范围是[0.3,0.7],当阈值thre3=0.3时, 平均一个金融新闻节点无向图中边的数量为200左右,当阈值thre3=0.7时,边的数量 为40左右。
[0070]
优选地,步骤s52中,阈值thre3=0.6。
[0071]
进一步地,步骤s53中,可用图卷机神经网络gcn代替tf
‑
idf加权词向量来生 成无向图节点的向量表示,以词向量作为节点属性向量,相似度作为权值放入图卷机 神经网络中,每个节点的表示向量由邻居节点的信息聚合得到。
[0072]
步骤s6包括:
[0073]
步骤s61:设定阈值thre4;
[0074]
步骤s62:将一个金融事件作为根节点生成故事链;
[0075]
步骤s63:将一个故事链下所有金融事件的关键词的并集作为该故事链的关键词;
[0076]
步骤s64:计算新识别出的金融事件的关键词与已生成故事链的关键词之间的相似 度,将新识别出的金融事件加入到相似度最高且高于设定阈值thre4的故事链中,每 一件金融事件均为故事链上的一个节点;否则以根节点的形式创建新故事链。
[0077]
进一步地,步骤s61中,阈值thre4的取值范围是[0,1],当阈值thre4=0.7时,结 果生成的故事链较短但主题集中,当阈值thre4=0.5时,结果生成的故事链较长主题比 较集中。
[0078]
优选地,步骤s61中,阈值thre4=0.6。
[0079]
进一步地,步骤s64中,相似度计算方法为jaccard相似度。
[0080]
步骤s7包括:
[0081]
步骤s71:设置一个滑动时间窗口,并计算窗口期内故事链中事件的平均发生频率;
[0082]
步骤s72:确定阈值thre5;
[0083]
步骤s73:判断故事链中最新的窗口期内事件的发生频率是否高于阈值thre5,若 高于,则判定为突发事件,反之不为突发事件。
[0084]
进一步地,步骤s71中,针对主流金融主体的新闻流数据,滑动时间窗口宽度一 般设置为1天。
[0085]
进一步地,步骤s72中,阈值thre5的取值范围是[30,100],当阈值thre5=30时, 结果出现较多较低的突发事件,当阈值thre5=100时,结果中出现典型且主题具有异 常性的突发事件。
[0086]
优选地,步骤s72中,阈值thre5=100。
[0087]
为了便于说明,本发明中约定了下列概念:
[0088]
候选词:这里是指名词、动词。
[0089]
故事链:定义为事件序列,该事件序列共享同一主体或相关主体,在时间上从前 至后单调递进,反映了一组相关事件或一个事件主题的时间演进过程。
[0090]
有益效果:本发明的一种基于层级化聚类的金融新闻流突发检测方法,通过自然 语言处理及图论相关技术,对金融新闻进行事件聚类生成故事链,解决了传统金融突 发事
件不能将同一事件相关新闻综合考虑的问题;本技术方法计算复杂度较低,可用 于海量金融新闻流式数据中的突发状态检测;有利于净化网络舆论环境,进一步帮助 金融企业或机构树立品牌形象、加强声誉风险管理,有效防止负面信息的肆意传播和 舆情失控,协助金融企业或机构提高网络舆论引导能力,营造积极向上的舆论环境, 为金融企业或机构快速健康发展提供强有力的舆论保障;有利于辅助决策与投资管理, 通过收集市场的舆情信息,构建研究知识库、政策模型库和情报研究方法库,建设并 不断完善,为金融机构和投资人提供全方位、多层次的和知识服务;具体包括以下几 点:
[0091]
1.通过对关键词共现图划分子图的方法,将金融新闻的文本数据划分为金融事件 主题;一方面利用关键词共现图描述金融新闻文本,大大缩小了词典空间,可在相对 较小且重要的关键词词典集合上构建金融新闻文本表示;另一方面通过子图划分,能 够较好的控制和引入用户需求,灵活处理主题生成。
[0092]
2.对金融新闻的文本数据,通过计算其向量表示与主题关键词子图的向量表示的 相似度来识别新闻所属的主题;通过向量之间的相似度来为金融新闻文本数据分配主 题,计算简便,方便实施。
[0093]
3.通过对每个主题下金融新闻两两预测关系的方式构建新闻关系图谱,使得主题 约束了相似金融新闻文本的范围,在一个较小的范围内计算文本相似度,对于复杂度 较高的两两相似度计算较为友好。
[0094]
4.对通过子图划分识别出的金融事件,通过对该事件下所有新闻取并集来生成该 金融事件的关键词集合;一方面约束了金融新闻的范围,即只在相关聚类内进行关键 词提取,数据规模可控;另一方面由于子图内的新闻主题相似,联合多条相关新闻提 取关键词即引入了文档的关联性,可有效避免内容的重复和冗余。
[0095]
5.通过计算事件与故事链相似度的方式,动态地将事件合并到相应的故事链上, 依靠增量添加事件的方法,动态地增长故事链,可以实时处理海量新闻,并从新闻中 快速地梳理出新闻主体近期发生的故事链,有利于提高金融事件突发性检测的效率和 准确性。
附图说明
[0096]
图1是本发明所述方法流程示意图;
[0097]
图2是故事链生成示例;
[0098]
图3是突发事件检测示例。
具体实施方式
[0099]
下面结合附图和具体实施方式对本发明的一种基于层级化聚类的金融新闻流突发 检测方法做出更进一步的具体说明。
[0100]
实施例
[0101]
本实施例在ubuntu18.04操作系统、python3编程环境、intel core i7
‑
9700cpu、32g 内存、rtx2070gpu的实验环境下,对一个大型金融新闻流数据集进行了充分测试和 验证。
[0102]
如图1所示,一种基于层级化聚类的金融新闻流突发检测方法,包括以下步骤:
[0103]
步骤s1:文本的预处理;包括:
[0104]
步骤s11:通过网络爬虫抓取了2019年12月至2020年8月这段时间内,涉及2138 个主要上市公司实体,超过50个可靠金融新闻流来源的共计129,779条数据;数据内 容涵盖时间戳、新闻标题、新闻内容、发布次数、url地址等信息;
[0105]
步骤s12:通过计算标题编辑距离去除重复新闻;根据时间戳完整性、url是否 可访问去除噪声数据;
[0106]
步骤s13:获取金融新闻信息,包括新闻标题、新闻正文和新闻发布时间三个信息;
[0107]
步骤s14:对清洗后的金融新闻创建关系型数据库存储格式的索引,字段包括新闻 编号(唯一标识)、新闻类型、发布时间、新闻来源网站、新闻链接、作者、标题及新 闻内容。
[0108]
步骤s2:抽取关键词并构建关键词共现图;包括:
[0109]
步骤s21:对步骤s1中预处理后的数据进行中文分词处理,去除停用词,获得候 选词集;
[0110]
步骤s22:通过textrank和kp
‑
miner算法,分别对每个主体的全量金融新闻按文 本抽取候选词,两种不同方法抽取的结果通过取交集和人工筛选保留可用关键词集合;
[0111]
步骤s23:根据关键词在同一主体下新闻文本中的共现次数,构建关键词共现图;
[0112]
步骤s24:过滤关键词共现图中共现频次小于阈值thre1=3以及共现频率小于阈值 thre2=0.15的边。
[0113]
步骤s3:采用二分k
‑
means算法对关键词聚类,将关键词共现图划分为若干子图, 每个子图中的关键词为一个金融主题;包括:
[0114]
步骤s31:利用node2vec算法抽取关键词节点特征,得到每个关键词节点表示向 量;
[0115]
步骤s32:训练步骤s31中得到的关键词节点表示向量;
[0116]
步骤s33:利用二分k
‑
means算法,将关键词共现图划分为若干子图,每个子图中 的关键词为同一个金融主题。
[0117]
步骤s4:通过相似度计算识别每篇金融新闻所属金融主题;包括:
[0118]
步骤s41:将每个金融主题通过词袋模型表示为向量,构建k
‑
d树;
[0119]
步骤s42:将每篇金融新闻表示为tf
‑
idf向量;
[0120]
步骤s43:通过k
‑
d树最近邻搜索,将每篇金融新闻划分入对应的金融主题,最 终所有金融新闻被划分为若干个金融主题。
[0121]
步骤s5:构建以每篇金融新闻为节点的无向图,采用二分k
‑
means算法对金融新 闻聚类,将金融新闻节点无向图划分为若干子图,每个子图中的金融新闻为一个金融 事件;包括:
[0122]
步骤s51:在一个金融主题下,以每篇金融新闻作为节点,任意两篇金融新闻的余 弦相似度作为边的权重相连,构建金融新闻节点无向图;
[0123]
步骤s52:过滤上述金融新闻节点无向图中相似度小于阈值thre3=0.6的边;
[0124]
步骤s53:利用td
‑
idf加权词向量生成金融新闻节点无向图中每个金融新闻节点 表示向量;
[0125]
步骤s54:训练s53中得到的金融新闻节点表示向量;
[0126]
步骤s55:通过二分k
‑
means算法,将金融新闻节点无向图划分为若干个子图, 每个子图中的金融新闻为同一个金融事件;
[0127]
步骤s56:将一个金融事件下所有金融新闻的关键词的并集作为该金融事件的关键 词。
[0128]
步骤s6:通过相似度计算生成故事链;包括:
[0129]
步骤s61:设定阈值thre4=0.6;
[0130]
步骤s62:将一个金融事件作为根节点生成故事链;
[0131]
步骤s63:将一个故事链下所有金融事件的关键词的并集作为该故事链的关键词;
[0132]
步骤s64:计算新识别出的金融事件的关键词与已生成故事链的关键词之间的 jaccard相似度,将新识别出的金融事件加入到相似度最高且高于设定阈值thre4=0.6 的故事链中,每一件金融事件均为故事链上的一个节点;否则以根节点的形式创建新 故事链。
[0133]
如图2所示,对新闻总数量排名前200的公司主体进行上述实验,结果显示本发 明准确找出多个在时间跨度较大,但内容和主题一致的金融新闻事件,生成了“苹果 计划收购自动驾驶初创公司drive.ai”这一故事链。
[0134]
步骤s7:突发事件检测;包括:
[0135]
步骤s71:针对主流金融主体的新闻流数据,滑动时间窗口宽度一般设置为1天, 计算窗口期内故事链中事件的平均发生频率;
[0136]
步骤s72:确定阈值thre5=100;
[0137]
步骤s73:判断故事链中最新的窗口期内事件的发生频率是否高于阈值thre5=100, 若高于,则判定为突发事件,反之不为突发事件。
[0138]
突发事件检测结果示例如图3所示,该实例证明本方法能够较准确的实时发现突 发时点,即图中st位置所示。
[0139]
综上所述,本发明对梳理金融信息脉络、理清重要事件发展过程意义重大;能够 较准确的实时发现突发时点,而不需要通过全局视角发现曲线极值点;本实施例证实 了所提发明内容的有效性、可实施性及易用性。
[0140]
本发明提供了一种基于层级化聚类的金融新闻流突发检测方法,具体实现该技术 方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技 术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和 润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分 均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1