基于改进YOLOv4-Tiny算法的铁矿石品位识别方法
基于改进yolov4
‑
tiny算法的铁矿石品位识别方法
技术领域
1.本发明涉及品位识别及定位技术领域,尤其涉及一种基于改进yolov4
‑
tiny算法的铁矿石品位识别方法。
背景技术:
2.铁矿石的品位一直是铁矿企业降低生产成本,增加利润的重要依据。现阶段铁矿石品位的判断在露天以及地下开采都不能及时有效进行。对于有经验的矿工能够大致判断铁矿石的大致品位,但这是需要时间来积累经验。并且,人工判断带有一定的主观性使判断不够准确。随着十四五规划的提出,深度学习结合机械臂和嵌入式设备实现自动化选矿也符合现在矿业自动化、智能化的发展趋势,对于物联网芯片行业也起到一点的促进作用。因此,需要一种能够大致判断矿石品位的方法来解决上述问题。
3.中国专利“cn201910859933.9一种基于深度学习的煤矿动态人脸识别考勤方法及系统”提供了一种基于res50残差网络的人脸识别考勤方法。此专利利用res50作为主干特征提取网络,生成的特征层利用8种尺度,3种比例的的锚点窗口对人脸的特征进行识别;在检测时设定阈值,对较为模糊的图片进行跳过检测,并利用归一化的算法对特征进行处理,提高了模型的准确性。但该方法利用res50作为主干特征提取网络,模型的运算速度以及参数量都偏大,所以不太可能用于嵌入式设备的搭载没有办法进行防爆,对于煤矿来说就不可能应用在井下且res50作为主干特征提取网络的性能已经相对落后。视频处理中,对于模糊图片直接略过会进一步减慢运行的速度,利用图像处理算法对图片进行增强是一种更好的选择。
4.中国专利“cn202011590566.6一种基于yolov4的摩托车头盔佩戴检测方法”利用yolov4算法并改进非极大抑制算法,对摩托车和骑乘人员进行检测。此专利通过特定的数据集对算法进行训练,对摩托车和骑乘人员区域进行头盔roi,并利用自定义模块进行检测,可以对摩托车有没有超员和是否佩戴头盔进行统计和记录。该方法也同样具有上述问题,且yolov4的训练所需要的的计算设备,一般高校实验室都不具备,后期模型的更新是一个很大的问题,且此专利对于统计方面有计算的问题,同一摩托车和骑乘人员可能会造成多计或者漏计情况。
技术实现要素:
5.本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于改进yolov4
‑
tiny算法的铁矿石品位识别方法,根据铁矿石的品位的特性(主要为纹理和颜色等),对主干特征提取网络以及特征提取网络进行结构改进,增强了神经网络对于低层特性(纹理颜色等)的识别效果,采用leaky
‑
relu、early stopping函数对网络的训练进行加速,针对嵌入式设备将keras模型利用自定义算子将模型转换为tensorflow
‑
lite模型。打开了现有矿业方面人工智能只局限在传统计算机的局面,让人工智能在矿业可以进行产品化、小型化、泛用化,结合物联网、嵌入式设备、单片机等更符合现代设备的发展。
6.为解决上述技术问题,本发明所采取的技术方案是:基于改进yolov4
‑
tiny算法的铁矿石品位识别方法,包括以下步骤:
7.采集不同品位矿石图片,对采集的矿石图片进行数据增强、扩充得到样本集;
8.基于改进的yolov4
‑
tiny网络结构生成矿石品位识别模型,并使用样本集进行模型训练;
9.对采集的不同品位矿石图片进行降噪处理;
10.利用训练好的矿石品位识别模型进行矿石品位识别。
11.进一步地,所述采集不同品位矿石图片,对采集的矿石图片进行数据增强、扩充得到样本集的具体方法为:
12.从露天及井下铁矿采场采集m张不同品位的铁矿石及围岩的图片,并将图片按铁矿石类别进行标号;
13.使用标注软件对采集的图片进行标注;
14.将标注后的图片进行翻转、截取和缩放操作,实现数据增强;
15.将数据增强后的图片缩小到随机长宽比例长度和宽度的图片,并将缩小后的n张图片拼接到一起,n<4,形成新的图片,得到样本集。
16.进一步地,基于改进的yolov4
‑
tiny网络结构生成的矿石品位识别模型包括cspdarknet21_tiny主干特征提取网络和改进的panet简单双向特征融合网络;
17.所述cspdarknet21_tiny主干特征提取网络用于对于矿石色彩以及轮廓的识别,输入图片尺寸为832*832,结构为:
18.darknetconv2d_bn_leaky+resblock_body*3+resblock_body*2+resblock_body*1+resblock_body*1+resblock_body*1
19.其中,darknetconv2d是二维卷积模块,bn代表归一化,leaky代表激活函数是leaky_relu,resblock_body表示残差块,选用leaky_relu作为网络的激活函数;
20.所述改进的panet简单双向特征融合网络,选择融合的三个特征层的尺寸分别为104*104、52*52和26*26,输出特征层分别为52*52和26*26两个尺寸;将尺寸为104*104的特征层简称p1,尺寸为52*52的特征层简称p2,尺寸为26*26的特征层简称p3,则改进的panet简单双向特征融合网络的特征融合过程为:
21.p3与p2进行特征融合获得p4并在上采样后与p1进行融合获得p5,p5进行下采样后与p4进行下采样获得第一个尺寸为52*52的输出特征层p6,p6又进行下采样并与p3融合获得第二个尺寸为26*26的输出特征层p7,最终获得两个输出特征层p6,p7。
22.进一步地,所述使用样本集进行模型训练的具体方法为:
23.基于迁移学习思想并载入已训练好的模型权重进行矿石品位识别模型的迭代训练:
24.(1)采用early stopping(早停法)控制迭代是否提前终止,在训练结束时保存模型并对模型进行格式转换,最终生成两种尺寸的特征层进行目标检测;
25.(2)将数据增强并标注的训练集按照长宽比例不变缩放到832*832大小输入到矿石品位识别模型中进行迭代计算;
26.(3)设置迭代次数,通过gpu对训练集进行训练,生成训练好的矿石品位识别模型文件。
27.进一步地,所述对采集的不同品位矿石图片进行降噪处理的具体方法为:
28.对测试集中的不同品位矿石图像使用均值滤波、gaussian滤波或中值滤波进行降噪处理。
29.进一步地,所述利用训练好的矿石品位识别模型进行矿石品位识别的具体方法为:
30.将测试集中通过降噪处理后的图像进行实时检测,提取矿石品位目标的类别、坐标、置信度和偏移量信息,并实时输出检测后的图像或视频,实现矿石品位的识别。
31.进一步地,所述方法还通过lattepanda开发板将训练好的矿石品位识别模型进行产品化,具体包括模型移植和平台测试两部分;
32.所述模型移植的具体方法为:
33.本发明的铁矿石品位识别模型不适用与嵌入式设备搭载,tensorflow库也没有转换本发明模型的必要算子,故本发明转换阶段依照需求设计三个自定义算子对本发明的铁矿石品位识别模型进行转换;
34.一、依照需求设计三个自定义算子对矿石品位识别模型进行转换;其中,第一算子用于在python和tensorflow环境下编译改进的yolov4
‑
tiny算法所需要的各种类型的函数以及数据结构:包括改进的yolov4
‑
tiny算法所用的后端、主干网络结构、特征提取网络结构、激活函数、损失函数、数据结构、输入输出的处理信息;
35.第二算子用于转换win10系统下所生成的矿石品位识别模型,训练所生成的矿石品位识别模型均为keras库下的.h5格式的模型,在利用tensorflow
‑
lite进行转换时即使使用了第一算子依旧不能进行转换,故利用第二算子将keras的.h5模型转换为tensorflow模型文件;
36.第三算子用于转换模型,利用tensorflow
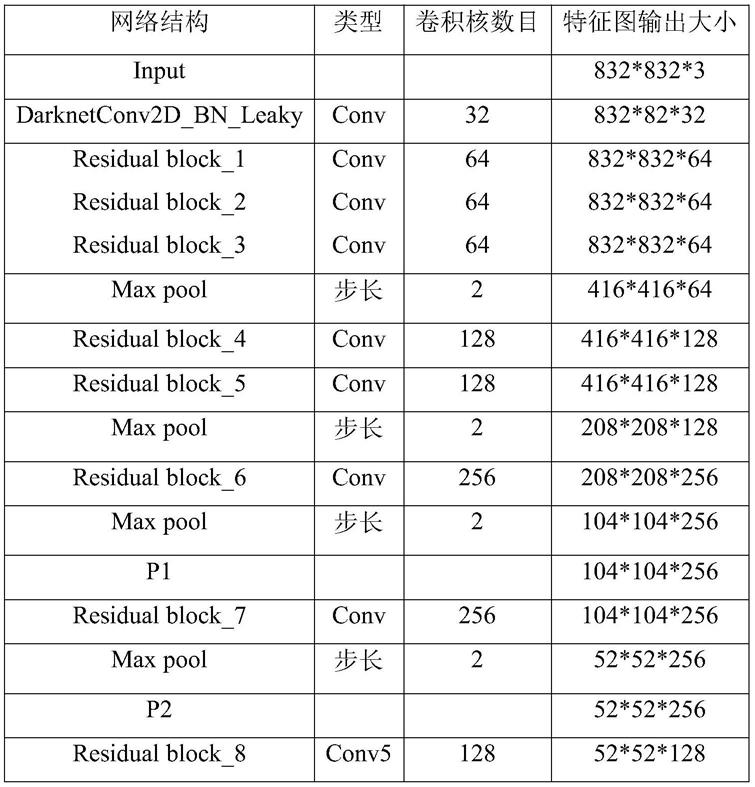
‑
lite库下函数转换第二算子所生成的tensorflow模型文件,包括自定义算子的范围、矿石品位识别模型输入图片的尺寸和转换存储;最终将在win10系统生成的keras的.h5模型转换为嵌入式设备可以使用的.tflite模型文件;
37.二、配置lattepanda开发板系统以及配置开发环境,并载入矿石品位识别模型程序和转换后的.tflite模型文件,利用cpu的算力进行矿石品位识别;
38.所述平台测试的具体方法为:
39.使用pyqt5进行装置ui设计,具体设置三个按钮,分别用于:图像识别、视频识别和摄像头实时识别,同时,设置矿石样本图像和识别的矿石品位图像的显示框;其中,图像识别和视频识别按钮用于选取矿石图片或视频文件并将文件路径输入矿石品位识别程序,摄像头实时识别按钮连接摄像头进行矿石品位实时识别;
40.打开lattepanda开发板点击ui界面三个按钮对三个功能进行测试,得到矿石品位识别结果。
41.采用上述技术方案所产生的有益效果在于:本发明提供的基于改进yolov4
‑
tiny算法的铁矿石品位识别方法,根据铁矿石的品位的特性(主要为纹理和颜色等),对yolov4
‑
tiny网络的主干特征提取网络以及特征提取网络进行结构改进,增强了网路对于低层特性(纹理颜色等)的识别效果,采用leaky
‑
relu、early stopping函数对网络的训练进行加速,针对嵌入式设备将keras模型转换为tensorflow
‑
lite模型。打开了了现有矿业方面人工智
能只局限在传统计算机的局面,让人工智能在矿业可以进行产品化、小型化、泛用化,结合物联网、嵌入式设备、单片机等更符合现代设备的发展。
42.利用改进的yolov4
‑
tiny算法并优化训练过程,减少了模型训练及预测对于计算机性能的问题,同时提升了模型的便携性让模型可以在lattepanda开发板上运行,实现了模型的实际应用问题。模型解决了现场无法粗略判断矿石品位以及自动化选矿的前期问题,同时对于图像只存在一个类别或多个类别的图像识别准确率都可以达到90%以上。除此之外,对于矿石堆叠,互相遮挡也可以进行很好的识别。经过优化的yolov4
‑
tiny深度学习网络框架还可以移植到小型便携设备,经过测试在lattepanda开发板上视频识别效率超过20fps/s,进一步解决矿区由于网络问题无法进行云端运算的问题。模型训练过程中针对现场所能遇到的拍摄问题,例如光线和噪点等,在测试以及使用时去除噪点、平衡亮度,进一步增强了模型的鲁棒性。本发明的矿石品位识别模型对于不同矿石品位的识别具有较好的鲁棒性和泛化性,又得益于模型小型化也可以在小型设备搭载进行产品化。
附图说明
43.图1为本发明实施例提供的基于改进yolov4
‑
tiny算法的铁矿石品位识别方法的流程图;
44.图2为本发明实施例提供的改进yolov4
‑
tiny网络结构示意图;
45.图3为本发明实施例提供的改进的panet简单双向特征融合网络的融合过程示意图;
46.图4为本发明实施例提供的采用不同滤波方法的图像预处理效果图,其中,(a)为原始铁矿石图片,(b)为均值滤波结果,(c)为gaussian滤波结果,(d)为中值滤波结果;
47.图5为本发明实施例提供的测试集中不同类型的铁矿石图片的识别结果图,其中,(a)为磁铁矿富矿,(b)为磁铁矿贫矿,(c)为赤铁矿富矿,(d)为赤铁矿贫矿;
48.图6为本发明实施例提供的铁矿石品位识别装置的ui界面图。
具体实施方式
49.下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
50.本实施例中,一种基于改进yolov4
‑
tiny算法的铁矿石品位识别方法,如图1所示,包括以下步骤:
51.步骤1:采集不同品位矿石图片,对采集的矿石图片进行数据增强、扩充得到样本集;从露天及井下铁矿采场采集不同品位矿石图片,并将图片按铁矿石类别进行标号,然后根据实际情况对采集的矿石图片进行数据增强、扩充得到样本集,并将样本集按一定比例划分为训练集、验证集和测试集,具体方法为:
52.步骤1.1:从露天及井下铁矿采场采集不同品位的铁矿石及围岩的图片,并将图片按类别进行标号;
53.本实施例采集磁铁矿和赤铁矿两种品位的铁矿石及围岩的图片,每种铁矿石分为三类:贫矿、富矿和围岩,每种类别150
‑
200张图片,总共获得1131张图片,再将图片进行分类,类别标号分别用01
‑
06表示,具体为:磁铁矿:贫矿01、富矿02、围岩03,赤铁矿:贫矿04、
富矿05、围岩06;
54.步骤1.2:使用标注软件对采集的图片进行标注;
55.步骤1.3:将标注后的图片进行翻转、截取和缩放操作,实现数据增强;
56.本实施例中,图片翻转概率为50%,方向不定(左、右、对角);截取图像的60%
‑
80%图像随机放置,保持图像大小不变,空白使用白色进行填充;对每个图像进行缩放0.2
‑
0.8倍,同样保持图像不变余下空白用白色填充。
57.步骤1.4:图片拼接:将数据增强后的图片缩小到随机长宽比例长度和宽度的图片,并将缩小后的n张图片拼接到一起,n≤4,形成新的图片,得到样本集;
58.本实施例中,经过数据扩充原始矿石图片从1131张扩充到7756张图片,即样本集中包括7756张矿石图片;
59.步骤1.5:将样本集按一定比例划分为训练集、验证集和测试集;
60.本实施例中,将样本集中的的85%作为训练集,5%作为验证集,10%作为测试集。
61.步骤2:基于改进的yolov4
‑
tiny网络结构生成矿石品位识别模型,并使用样本集进行模型训练;
62.步骤2.1:基于改进yolov4
‑
tiny网络结构生成矿石品位识别模型,具体包括cspdarknet21_tiny主干特征提取网络和改进的panet简单双向特征融合网络,如图2所示;
63.所述cspdarknet21_tiny主干特征提取网络用于对于矿石色彩以及轮廓的识别,采用大分辨率下增强浅层特征信息的提取(大分辨率也是为了细节信息),也就是在整体结构上偏重前端,简化后端,具体为输入图片尺寸为832*832,结构为:
64.darknetconv2d_bn_leaky+resblock_body*3+resblock_body*2+resblock_body*1+resblock_body*1+resblock_body*1
65.其中,darknetconv2d是二维卷积模块,bn代表归一化,leaky代表激活函数是leaky_relu,resblock_body表示残差块,选用leaky_relu作为网络的激活函数,结构参数如表1所示;
66.表1 cspdarknet21_tiny主干特征提取网络结构参数
[0067][0068][0069]
所述改进的panet简单双向特征融合网络,选择融合的三个特征层的尺寸分别为104*104、52*52和26*26,输出特征层分别为52*52和26*26两个尺寸;将尺寸为104*104的特征层简称p1,尺寸为52*52的特征层简称p2,尺寸为26*26的特征层简称p3,则改进的panet简单双向特征融合网络的特征融合过程如图3所示,具体为:
[0070]
p3与p2进行特征融合获得p4并在上采样后与p1进行融合获得p5,p5进行下采样后与p4进行下采样获得第一个尺寸为52*52的输出特征层p6,p6又进行下采样并与p3融合获得第二个尺寸为26*26的输出特征层p7,最终获得两个输出特征层p6,p7;
[0071]
步骤2.2:基于迁移学习思想并载入已训练好的模型权重进行矿石品位识别模型的迭代训练;
[0072]
拆解改进yolov4
‑
tiny网络权重文件中的浅层权重进行矿石品位识别模型训练,并采用early stopping(早停法)控制迭代是否提前终止,在训练结束时保存模型并对模型进行格式转换;
[0073]
因为改进yolov4
‑
tiny网络的小单元结构和yolo一样,故可以拆解权重文件中的浅层权重进行利用,采用early stopping(早停法)控制迭代是否提前终止,并在训练的最
后使用代码库tensorflow.keras.model中的save_model函数进行整体模型的保存(包括网络结构、激活函数、权重信息、迭代函数以及各种优化器);
[0074]
步骤2.3:矿石品位识别模型最终生成两种尺寸的特征层进行目标检测,也就是26*26及52*52尺寸上进行检测;
[0075]
本实施例在26*26及52*52尺寸上的特征层利用k
‑
means聚类获得六个anchor box(预设框),最终获得的anchorbox(预设框)和grand truth(真实框)对比正确率为79.8%;
[0076]
步骤2.4:将数据增强并标注的训练集按照长宽比例不变缩放到832*832大小输入到矿石品位识别模型中进行迭代计算;
[0077]
本实施例迭代设置为50个epoch,通过gpu对训练集进行训练,生成训练好的矿石品位识别模型文件,最终模型在44epoch停止训练,最终损失值loss值为5.9;
[0078]
本实施例中,最终获得的矿石品位识别模型在验证集测试准确率为94%,loss值为6.1;
[0079]
步骤3:对采集的不同品位矿石图片进行降噪处理;
[0080]
针对现场使用时lattepanda开发板相机补光不足,造成图像产生噪点情况进行图像预处理,对测试集中或现场采集的不同品位矿石图像使用均值滤波、gaussian滤波或中值滤波进行降噪处理。
[0081]
对比三种去除噪点的方法分别为:均值滤波、gaussian滤波(gaussian)和中值滤波(median);
[0082]
其中,均值滤波(blur):采用3*3窗口进行均值滤波,原理为将3*3窗口中心点周围八个点相加取均值,然后带入中心点;
[0083]
gaussian滤波(gaussian):利用gaussian公式产生一个3*3gaussian滤波器对图像进行滤波。
[0084]
中值滤波(median):同样采用3*3窗口,取中心点附近八个点的中值代替中心点的值。
[0085]
本实施例,通过如图4所示的测试集的滤波效果对比,选择中值滤波作为识别时的图像预处理方法。
[0086]
步骤4:矿石品位识别:利用步骤2训练的矿石品位识别模型对测试集中或现场拍摄的图像或视频进行实时检测识别,提取矿石品位目标的类别、坐标、置信度和偏移量信息,并实时输出检测后的图像或视频,实现矿石品位的识别;
[0087]
本实施例中,将步骤1中按比例分配的10%的测试集提取出来;利用步骤2生成的矿石品位识别模型对测试集进行测试,并计算mpa值;map为多种类别ap的平均值,是评价模型的关键指标之一,ap为召回率(recall)为x轴坐标,精确度(precision)为y轴坐标的坐标系所围成的面积,其中,召回率(recall)和精确度(precision)如下公式所示:
[0088]
precision=tp/(tp+fp)
[0089]
recall=tp/(tp+fn)
[0090]
其中,tp是分对了的正样本数;tn是分对了的负样本数;fp是分错了的正样本数
(实际上这个样本是负样本);fn是分错了的负样本数(实际上这个样本是正样本)。
[0091]
本实施例中,针对测试集中的矿石图片的识别结果如图5所示。
[0092]
本发明还通过lattepanda开发板将训练好的矿石品位识别模型进行产品化,包括模型移植和平台测试两部分;
[0093]
所述模型移植的具体方法为:
[0094]
本发明所改进的模型不适用与嵌入式设备搭载,tensorflow库也没有转换本发明模型的必要算子,故最后转换阶段本发明依照需求设计三个自定义算子对本发明的模型进行转换;
[0095]
所述模型移植的具体方法为:
[0096]
一、依照需求设计三个自定义算子对矿石品位识别模型进行转换;其中,第一算子用于在python和tensorflow环境下编译改进的yolov4
‑
tiny算法所需要的各种类型的函数以及数据结构:包括改进的yolov4
‑
tiny算法所用的后端、主干网络结构、特征提取网络结构、激活函数、损失函数、数据结构、输入输出的处理信息;
[0097]
第二算子用于转换win10系统下所生成的模型,训练所生成的矿石品位识别模型均为keras库下的.h5格式的模型,在利用tensorflow
‑
lite进行转换时即使使用了第一算子依旧不能进行转换,故利用第二算子将keras的.h5模型转换为tensorflow模型文件;
[0098]
第三算子用于转换模型,利用tensorflow
‑
lite库下函数转换第二算子所生成的模型文件,包括自定义算子的范围、矿石品位识别模型输入图片的尺寸和转换存储;最终将在win10系统生成的keras的.h5模型转换为嵌入式设备可以使用的.tflite模型文件;
[0099]
本实施例中,三个自定义算子的程序代码具体为:
[0100]
#导入所需要的的代码库
[0101]
import tensorflow as tf
[0102]
import tensorflow.keras as keras
[0103]
import h5py
[0104]
import os
[0105]
from ogiv1 import model
[0106]
import functools
[0107]
from tensorflow.python.keras.utils import customobjectscope,get_custom_objects
[0108]
#编写关于keras(.h5)模型的自定义函数,(也叫算子,这部分就是自定义算子)
[0109]
第一个函数作用是注入在tensorflow.keras下编译的ogiv1方法的主干网络结构、征提取网络结构、激活函数、损失函数、数据格式和处理方式等。
[0110]
#第二个函数作用就是初始化自定义对象,,上面是说明结构,第二个函数来初始化这个结构,两个函数对应第一个算子。
[0111][0112][0113]
#下面函数是正式开始转换工作,先将模型的格式进行转换,对应第二个算子;
[0114]
#第一行代码是调用第二个函数(也就是自定义算子),第二行获取要转换模型的名字,第三行是未转换时的路径,第四行加载未转换的模型,第五六就是将未转换的模型进行保存,保存成不同的格式,最后一行又进行模型加载
[0115]
#tensorflow
‑
lite库不支持直接利用keras直接保存的模型,虽然库里有示例但是就是报错,所以将keras模型加载以后再转换成tensorflow模型再加载进行后续的转换使用,同时初始化必要的算子
[0116]
init_keras_custom_objects()
[0117]
keras_model_name='ogiv1.h5'
[0118]
keras_model_path=os.path.join('keras_models',keras_model_name)
[0119]
save_model=tf.keras.models.load_model(keras_model_path)
[0120]
export_dir='save'
[0121]
tf.saved_model.save(save_model,export_dir)
[0122]
new_model=tf.saved_model.load(export_dir)
[0123]
#下面函数是正式转换模型,对应第三个算子;
[0124]
#区别于tensorflow
‑
lite官方库所提供的函数,本发明所定义的第三算子添加了范围圈定,否则转换模型会报错;
[0125]
#在定义算子的scope范围内进行转换:
[0126][0127][0128]
#调用函数进行转换,然后保存
[0129]
converter.optimizations=[tf.lite.optimize.optimize_for_size]
[0130]
converter.allow_custom_ops=true
[0131]
tflite_model=converter.convert()
[0132]
open("ogiv1.tflite","wb").write(tflite_model)
[0133]
二、配置lattepanda开发板系统以及配置开发环境,并载入矿石品位识别模型程序和转换后的.tflite模型文件,利用cpu的算力进行矿石品位识别;
[0134]
所述平台测试的具体方法为:
[0135]
使用pyqt5进行装置ui设计,如图6所示,具体设置三个按钮,分别用于:图像识别、视频识别和摄像头实时识别,同时,设置矿石样本图像和识别的矿石品位图像的显示框;其中,图像识别和视频识别按钮用于选取矿石图片或视频文件并将文件路径输入矿石品位识别程序,摄像头实时识别按钮连接摄像头进行矿石品位实时识别;
[0136]
打开lattepanda开发板点击ui界面三个按钮对三个功能进行测试,得到矿石品位识别结果。
[0137]
本实施例中,利用两段准备好的视频进行视频检测,经检测到矿石品位识别模型在lattepanda开发板上识别的速度可以达到20fps/s以上,map值为73.11。
[0138]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1