一种解决医学文本数据稀缺性的深度对抗生成方法与流程
1.本发明涉及机器翻译领域,具体涉及一种解决医学文本数据稀缺性的深度对抗生成方法。
背景技术:
2.医学文本数据库中的数据形式非常丰富,包含有关临床病历的各种信息,例如病案首页信息、病程记录信息,各种物理检查结果、病理参数信息、化验与实验结果、医生诊断记录以及相关的病人症状、主诉等数据。医学文本在医学领域被广泛用于临床诊疗的各个方面之中。医学文本有着广泛的用途,在医学自然语言理解、文本自动摘要、信息提取、信息过滤、信息检索等领域具有很高的研究价值和商业价值。因此足够的医学文本数据能够支撑临床和科研发展、造福人类健康,但是由于临床病例和病案的有限性,使医学信息数据库不可能对任何一种疾病特征都能作出全面地反映,这种医学文本数据的稀缺导致了医学信息的不完整,因此如何解决医学文本数据稀缺性成为本领域的研究重点。
3.目前的医学文本的机器翻译通常采用编码器
‑
解码器,以英文医学文本翻译为中文医学文本为例,编码器首先将英文文本编码成高维向量,然后由解码器对高维向量翻译成中文文本。但是目前通用的编码器
‑
解码器利用海量英文医学文本和稀缺的中文医学文本的不平衡训练数据集训练,无法达到一般语言翻译的精准度。针对以上精准度比较低的问题,目前也可以通过医学数据标注专家进行标注从而解决翻译质量不高的问题,但是医学文本数据的标注对专业知识要求度高,医学文献数量又非常多,且不同领域需要不同的专家进行标注,因此通过人工标注需要大量的医学文本标注专家而且还会造成人力物力的浪费。因此目前还难以通过医学专家人工标注从而获得准确大量的医学文本。针对目前语料数据的稀缺(目标语言)问题,目前可通过相似语言表达进行数据增强,但是医学领域语言表达专业要求高,对翻译语意表达更为严格,所以利用相似语言表达无法取得高质量翻译效果。因此目前的医学文本标注方法还无法获取海量准确的医学标注文本,从而造成了医学文本训练数据的稀缺,这个问题成为改善医学文本机器翻译质量的重要瓶颈,是一个亟待解决的重要问题。
技术实现要素:
4.本发明目的是为了解决目前的医学文本标注方法还无法获取海量准确的医学标注文本,从而造成了医学文本训练数据的稀缺的问题,而提出了一种解决医学文本数据稀缺性的深度对抗生成方法。
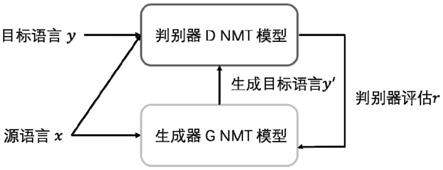
5.一种解决医学文本数据稀缺性的深度对抗生成方法具体过程为:将医学文本源语言输入到训练好的生成对抗网络gan中获得目标语言。
6.所述生成对抗网络gan包含:生成器和判别器;
7.所述判别器学习过程中采用基于神经网络的机器翻译nmt模型,所述基于神经网络的机器翻译nmt模型采用编码器
‑
解码器模型;所述编码器用于对源语言进行编码,将完
成的编码输入给解码器;所述解码器用于将编码器输入的编码转成目标语言;
8.所述机器翻译nmt模型用于将源语言从真实标记数据训练到目标语言,并对自动生成的数据进行评估,判断数据是否为真实训练数据;
9.其中,m为语料训练数据指标数值,取值为1到m,m为语料训练数据条目的总个数,x
m
是训练数据也就是源语言的集合,y是判别器目标语言,y
m
是第m个目标语言;
10.所述生成器采用gru网络模型,用于对源语言数据进行编码
‑
解码,产生生成器目标语言y
′
;
11.所述生成器将稀疏文本数据作为目标数据,语料丰富的文本数据作为源语言进行训练;
12.所述生成器目标语言y
′
在gru内部通过重置门和更新门进行时序信息学习。
13.本发明的有益效果为:
14.本发明利用生成对抗网络(gan)生成器通过一系列模型产生伪造数据用以欺骗判别器,根据判别器对伪造数据的反馈猜测真实数据的近似分布这一优点与基于神经网络的机器翻译(nmt)可以完成高质量源语言到目标语言的翻译任务这一优点相结合解决了无法获取海量准确的医学标注文本,从而造成医学标注文本训练数据的稀缺。
附图说明
15.图1为本发明系统框架图;
16.图2为生成器模型图。
具体实施方式
17.具体实施方式一:本实施方式一种解决医学文本数据稀缺性的深度对抗生成方法具体过程为:将医学文本源语言输入到训练好的生成对抗网络gan中获得医学文本目标语言;
18.所述生成对抗网络gan包含:生成器和判别器;
19.所述判别器学习过程中采用基于神经网络的机器翻译nmt模型,所述基于神经网络的机器翻译nmt模型采用编码器
‑
解码器模型;所述编码器用于对源语言进行编码,将完成的编码输入给解码器;所述解码器用于将编码器输入的编码转成目标语言;
20.所述机器翻译nmt模型用于将源语言从真实标记数据训练到目标语言,并对自动生成的数据进行评估,判断数据是否为真实训练数据;
21.其中,m为语料训练数据指标数值,取值为1到m,m为语料训练数据条目的总个数,x
m
是训练数据也就是源语言的集合,y是判别器目标语言,y
m
是第m个目标语言;
22.所述生成器采用gru网络模型,用于对源语言数据进行编码
‑
解码,产生生成器目标语言y
′
;
23.所述生成器将稀疏文本数据作为目标数据,语料丰富的文本数据作为源语言进行训练;
24.所述生成器目标语言y
′
在gru内部通过重置门和更新门进行时序信息学习。
25.所述生成对抗网络的训练具体过程为:将源语言x和判别器目标语言y输入判别
器,通过nmt模型训练,获得对目标语言和生成语言的判别能力,将源语言x作为生成器g的输入,由生成器g产生生成器目标语言y',将源语言x和生成器目标语言y'作为判别器的输入,经过判别器的识别,对所生成的生成器目标语言y'进行评估,生成器g获得奖励r,经过迭代训练,直到判别器无法判定输入来自于真实目标语言或由生成器产生,则训练结束获得训练好的生成对抗网络gan。
26.本发明采用判别器类似模型,由于目标语言稀缺性,将已有源语言作为生成器输入,然后采用类似nmt的编码器
‑
解码器模型;
27.具体实施方式二:所述生成器目标语言y'在gru内部通过重置门和更新门进行时序信息学习时,状态输出为:
[0028][0029]
其中,
[0030][0031]
z
t
=σ(w
z
·
[y
t
‑1,x
t
])
[0032]
r
t
=σ(w
r
·
[y
t
‑1,x
t
])
[0033]
其中,σ是sigmoid激活函数,t表示时刻,r
t
是重置门,z
t
是更新门,y
t
为状态输出,y
t
‑1是t
‑
1时刻的状态输出,为候选隐藏状态,x
t
为t时刻源语言输入,w
z
更新门网络权重,w
z
取值范围0到1,w
z
数值越大代表对当前输入信息记忆越多,w
r
重置门网络权重,用于对x
t
重要维度信息进行选择,并对重要维度输入赋予更高权重,w为激活函数tanh网络权重,用于将数据映射到
‑
1到1范围内。
[0034]
具体实施方式三:所述基于神经网络的机器翻译模型nmt,在给定源端句子x=x1,....,x
l
条件下的对目标句y=y1,....,y
j
,优化的条件概率为:
[0035][0036]
式中,x
i
表示源语言单个输入词,l为句子给定源端句子总长度,y
j
为目标语言对应词,j为目标语言句子长度,j∈[1,j],θ是模型的参数,y<j是j的翻译上下文;
[0037]
本实施方式中概率p(y|x)定义了基于神经网络的编码器
‑
解码器框架。
[0038]
具体实施方式四:对所述nmt模型的参数进行训练获得真实标记数据的似然估计(likelihood)为:
[0039][0040]
其中,m为语料训练数据指标数值,取值为1到m,m为语料训练数据条目的总个数,m∈[1,m],y
m
是第m个目标语言,x
m
是第m个源语言样本;
[0041]
具体实施方式五:所述生成对抗网络的整体对抗模型为:
[0042]
假设标记数据样本来自于数据真实概率分布p
true
,生成数据样本服从学习概率分布p
gen
,则构建的整体生成对抗网络目标函数为:
[0043][0044]
式中,g为生成器,d为判别器,d(x)=p(y|x,θ)为判别器评估数据样本为真实数据
的概率,(1
‑
d(g(x)))是判别器的收益期望的一部分,v(d,g)是整体目标函数,d(g(x))判别器对生成器产生语言的概率估计;
[0045]
当g固定时,v(d,g)表示判别器收益期望,由log(d(x))和log(1
‑
d(g(x)))组成;
[0046]
当d固定时,v(d,g)表示生成器收益期望即log(1
‑
d(g(x)))。
[0047]
本实施方式,对于判别器,当数据来自于训练数据,则对于d(x)的期望则越大;当数据来源于生成器,则对于判别器的收益期望(1
‑
d(g(x)))越大,因此,从判别器的角度,整体生成对抗网络需最大化目标函数v(d,g)。从生成器角度,用产生的语言数据来欺骗判别器,从而获得更高的概率估计d(g(x))。故此,从判别器的角度,整体模型需最大化目标函数v(d,g)。在训练过程中,生成器和判别器进行对抗训练,直至模型收敛。模型收敛时,生成器产生的语言数据,判别器难以区分为生成器产生抑或从真实训练数据样本的采样中产生。
[0048]
具体实施方式六:所述生成器目标语言y'优化的条件概率如下:
[0049][0050]
上式为生成器优化目标,应使其最大化:利用输入数据,通过r的优化方向,调整参数η,令生成器目标语言概率最大化;
[0051]
其中,y'是生成器目标语言即由源语言x产生的对应医学文本目标语言,η为模型参数a是生成翻译y
′
的指标,r是指由判别器对生成器生成的y
′
进行评估的打分,也就是对生成器的奖励,y
a
'是翻译目标语句中任意词。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1