热点削峰方法、装置、存储服务器、客户端及存储介质与流程
1.本公开涉及分布式存储技术领域,尤其涉及一种分布式存储系统的热点削峰方法、装置、存储服务器、客户端及存储介质。
背景技术:
2.近年来,随着互联网用户的飞速增长以及ai(artificial intelligence,人工智能)领域对于大数据的依赖,数据分析和后台开发人员需要获得与处理相关的越来越多的数据,在这样的背景下,分布式存储相对于传统的单机存储越来越流行。但是,在采用较低成本获取大量算力的同时,分布式存储系统在运维与使用中也会遇到各种各样的挑战,数据热点问题就是最常见的问题之一。
3.热点解决方案对于任何分布式存储系统都是一个值得思考的问题,实际运维中,由单个热点数据导致分布式存储系统整体不稳定是很常见的现象,例如某商品降价引发的瞬时热卖、微博热点话题的突然出现、或是开发人员写入数据库的数据大小分配不均,这些都可能引发热点问题。
4.针对热点问题,相关技术中通过集群扩容使其得以缓解,但这会增加不必要的集群扩容。
技术实现要素:
5.本公开实施例提供一种分布式存储系统的热点削峰方法、装置、存储服务器、客户端及存储介质。
6.本公开第一方面实施例提出了一种分布式存储系统的热点削峰方法,应用于主数据服务器,方法包括:获取热点数据;将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值。
7.在本公开的一个实施例中,获取热点数据,包括:将数据的键哈希分配至多个数据槽,并记录每个数据槽的数据流量;根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽;对热点槽进行细粒度筛查,得到热点数据。
8.在本公开的一个实施例中,通过原子变量记录每个数据槽的数据流量。
9.在本公开的一个实施例中,根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽,包括:根据每个数据槽的数据流量,获取多个数据槽的数据流量平均值和数据流量标准差;获取每个数据槽的数据流量与数据流量平均值之间的差值;将差值与数据流量标准差的比值超过第一预设值的数据槽确定为热点槽。
10.在本公开的一个实施例中,对热点槽进行细粒度筛查,得到热点数据,包括:对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数;根据每一类数据被读写的次数,确定热点数据。
11.在本公开的一个实施例中,对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数,包括:利用多个线程将热点槽对应的数据的值写入多个消息队列,其
中,多个线程与多个消息队列一一对应;将热点槽对应的数据的值从多个消息队列中读出,并记录每一类数据被读写的次数。
12.在本公开的一个实施例中,根据每一类数据被读写的次数,确定热点数据,包括:根据每一类数据被读写的次数,获取所有类数据被读写的次数平均值和次数标准差;获取每一类数据被读写的次数与次数平均值之间的差值;将差值与次数标准差的比值超过第二预设值的数据确定为热点数据。
13.在本公开的一个实施例中,主数据服务器包括读数据线程池、写数据线程池和分析线程池,其中,通过读数据线程池和写数据线程池分别利用多个线程将数据的键哈希分配至多个数据槽,并将热点槽对应的数据的值写入多个消息队列,通过分析池利用多个线程进行粗粒度筛查和细粒度筛查。
14.在本公开的一个实施例中,方法还包括:接收热点检测指令,其中,热点检测指令包括用户输入的热点检测指令或者监测服务器在监测到主数据服务器为热点时生成的;在接收到热点检测指令后,获取热点数据。
15.本公开第二方面实施例提出了一种分布式存储系统的热点削峰装置,应用于主数据服务器,装置包括:获取模块,用于获取热点数据;发送模块,用于将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值。
16.本公开第三方面实施例提出了一种存储服务器,包括:处理器;用于存储处理器可执行指令的存储器;其中,处理器被配置为执行指令,以实现本公开第一方面实施例提出的分布式存储系统的热点削峰方法。
17.本公开第四方面实施例提出了一种非临时性计算机可读存储介质,当存储介质中的指令由存储服务器的处理器执行时,使得存储服务器能够执行本公开第一方面实施例提出的分布式存储系统的热点削峰方法。
18.本公开第五方面实施例提出了一种分布式存储系统的热点削峰方法,应用于客户端,方法包括:在接收到分布式存储系统中的主数据服务器发送的热点数据的键后,从与主数据服务器对应的从数据服务器中读出热点数据的值。
19.本公开第六方面实施例提出了一种客户端,包括:处理器;用于存储处理器可执行指令的存储器;其中,处理器被配置为执行指令,以实现本公开第五方面实施例提出的分布式存储系统的热点削峰方法。
20.本公开第七方面实施例提出了一种非临时性计算机可读存储介质,当存储介质中的指令由客户端的处理器执行时,使得客户端能够执行本公开第五方面实施例提出的分布式存储系统的热点削峰方法。
21.本公开实施例提供的分布式存储系统的热点削峰方法、装置、存储服务器、客户端及存储介质,获取热点数据,并将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值,由此,针对热点数据,通过客户端读取从数据服务器中的热点数据的值,进行热点数据分流,以减轻主数据服务器的压力,以便快速缓解系统故障的风险,即因单机压力过大导致宕机的风险。
22.本公开附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本公开的实践了解到。
附图说明
23.本公开上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得明显和容易理解,其中:
24.图1是根据一示例性实施例示出的一种分布式存储系统的结构示意图;
25.图2是根据一示例性实施例示出的一种分布式存储系统的热点检测方法的流程图;
26.图3是根据一示例性实施例示出的一种分布式存储系统的热点检测方法中确定当前每秒查询率所处的状态的流程图;
27.图4是根据一示例性实施例示出的一种热点测试结果图;
28.图5是根据一示例性实施例示出的一种历史每秒查询率的存储示意图;
29.图6是根据一示例性实施例示出的一种分布式存储系统的热点检测装置框图;
30.图7是根据一示例性实施例示出的一种监测服务器框图;
31.图8是根据一示例性实施例示出的另一种分布式存储系统的热点检测方法的流程图;
32.图9是根据一示例性实施例示出的一种粗粒度筛查的流程图;
33.图10是根据一示例性实施例示出的一种细粒度筛查的流程图;
34.图11是根据一示例性实施例示出的一种双层筛查结构示意图;
35.图12是根据一示例性实施例示出的性能测试结果图;
36.图13是根据一示例性实施例示出的一种分布式存储系统的热点检测装置框图;
37.图14是根据一示例性实施例示出的一种存储服务器框图;
38.图15是根据一示例性实施例示出的一种分布式存储系统的热点削峰方法的流程图;
39.图16是根据一示例性实施例示出的使用热点削峰方案前后的cpu占用率;
40.图17是根据一示例性实施例示出的一种分布式存储系统的热点削峰装置框图;
41.图18是根据一示例性实施例示出的一种存储服务器框图;
42.图19是根据一示例性实施例示出的另一种分布式存储系统的热点削峰方法的流程图;
43.图20是根据一示例性实施例示出的一种客户端框图。
具体实施方式
44.这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开实施例相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开实施例的一些方面相一致的装置和方法的例子。
45.在本公开实施例使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本公开实施例。在本公开实施例和所附权利要求书中所使用的单数形式的“一种”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
46.应当理解,尽管在本公开实施例可能采用术语第一、第二、第三等来描述各种信
息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本公开实施例范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”及“若”可以被解释成为“在
……
时”或“当
……
时”或“响应于确定”。
47.下面详细描述本公开的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的要素。下面通过参考附图描述的实施例是示例性的,旨在用于解释本公开,而不能理解为对本公开的限制。
48.分布式存储系统一般使用键值对(key
‑
value)进行数据的存储,大方向上具有基于哈希(hash)分片和基于范围(range)分片两种方式,其中,基于哈希分片是按照数据哈希过后的哈希值进行数据分配;基于范围分片是按照数据的ascii码(american standard code for information interchange,美国信息交换标准代码)排序后进行数据分配。不同的数据分片分配在不同的存储服务器(即存储节点)上,在数据随机输入的情况下数据分配是均匀的,以将单机系统中单机的压力分散到集群中多台存储服务器中。但是当大量客户端访问集群中的一个或者少数几个存储服务器时,使得少数数据分片的读写请求过多,载荷过大,而其它数据分片的负载却很小,从而造成了系统的“热点”现象,使系统负载失衡,降低系统的效率,影响了分布式存储系统的整体可用性。
49.其中,热点的产生原因可能有很多种:一方面,可能是现实生活中出现了热点问题,比如网上商城出现了大降价商品,大家蜂拥而至来购买,或是微博出现了热点新闻,引发了公众的广泛讨论,这些前端的行为传递到后端的存储系统就成为了一个热点,使得相应的存储服务器压力增大;另一方面,可能是开发人员对存储系统使用不当,将可以存储在内存的数据或是可以被打散的数据存储在存储系统中,频繁的读写造成了单机压力过大,或者由于存储的键值对大小过大,单次读写的数据过多、耗时长,此时的表现形式与热点类似。
50.单机出现热点导致负载增加看似只影响了热点数据的读写效率,其实不然,因为在实际情况下,一台存储服务器上往往不止存在一个数据分片,如果单个数据分片的读写就将单机负载打满,其它存储在该存储服务器上的数据分片也会受到影响,如主数据分片会直接受到读写效率的影响,从数据分片则会写入延迟成为慢节点,影响整个系统的效率,当情况异常严重时,还会导致系统负载过高从而宕机,因此早发现早处理热点是运维过程中的重中之重。
51.相关技术中,一般是通过集群监控系统,人工观察到数据的读写延迟变化后,再根据存储服务器的cpu占用率、网卡占用率去推测热点的位置,这样不仅繁琐耗时,而且无法保证正确率。基于此,本公开提供了一种分布式存储系统的热点检测方法,该方法能够自动、快速且准确地发现热点。
52.需要说明的是,本公开提供的分布式存储系统的热点检测方法,可以应用于如图1所示的分布式存储系统中。其中,分布式存储系统可包括管理服务器(zookeeper)、元数据服务器(metaserver)、存储服务器(replicaserver)和监测服务器(collector)。
53.管理服务器主要用于为分布式应用提供一致性服务,如配置服务、域名服务、分布式同步以及主服务等。
54.元数据服务器主要用于负责管理集群的全局状态,可包括主(master)元数据服务
器和两个备份(backup)元数据服务器。
55.存储服务器主要用于负责数据读写、存储等,在数据存储时,每个数据均有三个副本,分散到不同的存储服务器上,相应的存储服务器包括主(primary)数据服务器和两个备份(secondary)数据服务器。例如,在客户端(clientlib)具有写请求时,先向元数据服务器查询数据的键的位置,之后根据键的位置向对应的主数据服务器发起写请求,而后主数据服务器将数据同步至两个备份数据服务器,两者均写入成功后,返回结果至客户端。
56.监测服务器主要用于搜集各存储服务器的性能指标,如cpu使用率、数据访问延迟等,在本公开中,还用于搜集用于判断热点的关键指标:每秒查询率,以进行热点发现,如针对每个存储节点(即存储服务器),获取数据分片的每秒查询率,包括当前每秒查询率和历史每秒查询率,而后基于历史每秒查询率确定当前每秒查询率所处的状态,并响应于当前每秒查询率所处的状态为目标状态,确定数据分片对应的存储节点为热点。需要说明的是,每秒查询率是指针对一个特定的存储服务器,在规定时间内所处理流量多少的衡量标准。
57.图2是根据一示例性实施例示出的一种分布式存储系统的热点检测方法的流程图,以该方法应用于图1中的监测服务器为例进行说明,包括以下步骤:
58.在步骤s101中,获取存储节点中数据分片的每秒查询率,每秒查询率包括当前每秒查询率和历史每秒查询率。
59.可选地,在步骤s101中,可获取每个存储节点中各个数据分片的每秒查询率,包括当前每秒查询率和历史每秒查询率。在具体实施时,可由监测服务器实时搜集和记录存储节点中数据分片的每秒查询率,包括当前每秒查询率和历史每秒查询率,用于热点发现。
60.在步骤s102中,基于历史每秒查询率确定当前每秒查询率所处的状态。
61.具体地,在获得存储节点中数据分片的当前每秒查询率和历史每秒查询率后,可基于记录的历史每秒查询率来确定当前每秒查询率所处的状态。可选地,可基于记录的所有历史每秒查询率依次确定记录的每个当前每秒查询率所处的状态,如当前每秒查询率是否严重偏离历史每秒查询率。
62.在步骤s103中,响应于当前每秒查询率所处的状态为目标状态,确定数据分片对应的存储节点为热点。
63.具体地,若基于历史每秒查询率确定某一当前每秒查询率所处的状态为目标状态,如严重偏离历史每秒查询率,则确定该当前每秒查询率对应的数据分片所对应的存储节点为热点。
64.举例来说,以图1为例,在确定存储服务器是否为热点时,可由监测服务器获取存储服务器中数据分片的当前每秒查询率和历史每秒查询率,并基于历史每秒查询率判断当前每秒查询率所处的状态是否为目标状态,若某一当前每秒查询率所处的状态为目标状态,如该当前每秒查询率严重偏离历史每秒查询率,则确定相应的存储服务器存储有热点数据,该存储服务器为热点,否则该存储服务器不具有热点数据。
65.由此,基于当前每秒查询率和历史每秒查询率,能够自动、快速且准确地确定出存储节点是否为热点,也即确定出存储节点是否存在故障(单机压力过大导致宕机)的风险,有效解决了通过人工观察方式推测热点的位置导致的繁琐耗时以及正确率低的问题。
66.需要说明的是,在公开的一些实施例中,可基于当前每秒查询率和历史每秒查询率,通过一维的异常值检测算法分析出热点,即进行热点发现。可以理解的是,在统计学中,
如果一个数据分布近似高斯分布,那么大约68%的数据会在总体数据平均值的一个标准差范围内,大约95%的数据会在总体数据平均值的两个标准差范围内,大约97%的数据会在总体数据平均值的三个标准差范围内,因此可以在数据分片的当前每秒查询率在历史每秒查询率的三个标准差范围外时,确定数据分片对应的存储节点为热点。
67.具体地,在本公开的一个实施例中,参考图3所示,基于历史每秒查询率确定当前每秒查询率所处的状态,包括:
68.在步骤s201中,获取数据分片的历史每秒查询率和当前每秒查询率的平均值和标准差。
69.具体地,在进行热点发现时,可先获取存储节点中数据分片的当前每秒查询率和历史每秒查询率,而后获取历史每秒查询率和当前每秒查询率的平均值和标准差,即计算历史每秒查询率和当前每秒查询率的平均值,以及计算历史每秒查询率和当前每秒查询率的标准差。可选地,在步骤s201中,可获取记录的所有数据分片的历史每秒查询率和当前每秒查询率的平均值和标准差。
70.在步骤s202中,针对数据分片,获取当前每秒查询率与平均值之间的差值,并根据差值和标准差,确定当前每秒查询率所处的状态。
71.可选地,可针对记录的每个数据分片,计算各个数据分片的当前每秒查询率与平均值之间的差值,根据差值和标准差,确定当前每秒查询率所处的状态。
72.进一步地,在本公开的一个实施例中,分布式存储系统的热点检测方法还包括:若差值与标准差的比值超过预设值,则确定当前每秒查询率所处的状态为目标状态,其中预设值可根据实际情况进行标定,如预设值为3,即若某一当前每秒查询率的差值与标准差的比值超过预设值(如3),则确定该当前每秒查询率所处的状态为目标状态,此时确定相应的数据分片对应的存储节点为热点。也就是说,在该示例中,利用统计学中的3σ原理,将存储节点的数据分片的当前每秒查询率与历史每秒查询率进行比对,以判断当前每秒查询率是否为离群值,即计算z分数,如果是离群值,即z分数大于预设值3,则确定相应的存储节点为热点。
73.作为一个具体示例,可通过以下方式计算z分数:
74.avg=calculate average in historydata and currentdata//计算平均值avg
75.std=calculate standard deviation in historydata and currentdata//计算标准差std
76.forqpsvaluei in currentdata
77.deviationi=max((qpsvaluei
–
avg)/std,0)//计算每个当前每秒查询率qpsvaluei与平均值之间的差值与标准差的比值,并输出相应的结果
78.output(deviationi)
79.其中,输入为当前周期统计到的各数据分片的每秒查询率,包括当前每秒查询率和历史每秒查询率,输出为各数据分片的当前每秒查询率相对于数据分片的历史每秒查询率的标准差偏离,即z分数。在获得z分数后,将其与预设值如3进行比较,如果z分数大于预设值3,说明数据分片对应的存储节点为热点。
80.由此,基于3σ原理进行热点检测,不仅检测原理简单、实现简单,而且具有较高的快速性、准确性以及有效性。当然,还可以采用其它一维异常值检测算法来确定数据分片对
应的存储节点是否为热点,如dbscan聚类方法、孤立森林等一维异常值检测算法,本公开对此不作限定。
81.为了验证本公开所具有的效果,可基于图1所示分布式存储系统,分别以四种数据配置由客户端向存储服务器发送数据,同时检测采用本公开进行热点发现的结果。测试方法如下:首先按照配置文件构造对分布式存储系统的访问字符串组,包括随机字符串部分和热点字符串部分,随机字符串部分随机生成并分散在操作队列中,热点字符串部分按照配置文件重复生成并分散在操作队列中,然后按照配置文件中的读写比例同时向分布式存储系统使用操作队列进行读写操作,并无线循环,直至数据观察结束,具体此时数据如表1所示:
82.表1
[0083][0084]
测试结果如图4所示,从图4可以看出,本公开的热点检测方法是准确有效的。其中,在数据一中,设置的数据全部为随机数据,即没有热点数据的正常读取,结果显示所有数据分片的偏差值均小于等于1,即数据分片p1至p8的偏差值均小于等于1;而数据二、三和四,分别对应的是出现1个、2个和3个热点数据的情况,本公开的热点检测方法均能够精准发现,如数据二,数据分片p4的偏差值为8,超过预设值如3,表示具有1个热点;数据三,数据分片p1和p6的偏差值均为6,超过预设值如3,表示具有2个热点;数据四,数据分片p4、p5和p6的偏差值均为5,超过预设值如3,表示具有3个热点。
[0085]
由此,本公开的热点检测方法,能够自动、快速且准确地发现热点,并且相较于传统的通过各项流量吞吐监控判断热点的方法,一是可以更加轻易明了地找出正在发生的热点,二是可以更加方便地介入自动报警监控。
[0086]
在本公开的一个实施例中,每秒查询率为读出每秒查询率或写入每秒查询率。需要说明的是,在进行热点发现时,可分别基于读出每秒查询率和写入每秒查询率进行热点发现,以利用读热点和写热点的分别发现。
[0087]
具体来说,可获取存储节点中数据分片的当前读出每秒查询率和历史读出每秒查询率,并基于数据分片的历史读出每秒查询率确定数据分片的当前读出每秒查询率所处的状态,以及响应于当前读出每秒查询率所处的状态为目标状态,确定数据分片对应的存储节点为读热点;同时,可获取数存储节点中据分片的当前写入每秒查询率和历史写入每秒查询率,并基于数据分片的历史写入每秒查询率确定数据分片的当前写入每秒查询率所处的状态,以及响应于当前写入每秒查询率所处的状态为目标状态,确定数据分片对应的存储节点为写热点。具体实现过程,可参考前述,这里不再赘述。
[0088]
在本公开的一个实施例中,采用循环队列存储方式存储历史每秒查询率。
[0089]
具体地,在进行热点发现时,需要记录历史每秒查询率,因此需要考虑将一个分布式存储系统中各个表、各个数据分片的历史数据保存下来,但是又考虑到要控制内存的使
用,防止无限制地缓存,造成内存泄露,在一些实施例中,采用循环队列存储方式存储历史每秒查询率。
[0090]
举例来说,可由监测服务器记录整个分布式存储系统的所有表的信息,并由监测服务器中的热点计算模块记录单个表的信息,其中每个表的信息以循环队列方式存储,如图5所示,当队列容量超过指定大小时,队列会淘汰旧数据再存入新数据,这样可以有效保证系统内存的使用。
[0091]
在本公开的一个实施例中,在确定数据分片对应的存储节点为热点之后,方法还包括:采用可视化方式或日志方式展示热点的数据分片,当然,也可以进行热点预警,以对用户进行提醒。
[0092]
在本公开的一个实施例中,在确定数据分片对应的存储节点为热点之后,方法还包括:发送热点流量检测指令至热点,以便热点在接收到热点流量检测指令后进行热点流量检测。
[0093]
具体地,监测服务器在发现某一存储节点为热点后,可向该存储节点发送热点流量检测指令,以便该存储节点在接收到热点流量检测指令后,进行热点流量(即热点数据)检测,对于热点流量的检测,后续再进行详述。
[0094]
图6是根据一示例性实施例示出的一种分布式存储系统的热点检测装置框图,参考图6所示,该分布式存储系统的热点检测装置10包括:获取模块11、状态确定模块12和热点确定模块13。
[0095]
其中,获取模块11被配置为用于获取存储节点中数据分片的每秒查询率,每秒查询率包括当前每秒查询率和历史每秒查询率;状态确定模块12被配置为用于基于历史每秒查询率确定当前每秒查询率所处的状态;热点确定模块13被配置为用于响应于当前每秒查询率所处的状态为目标状态,确定数据分片对应的存储节点为热点。
[0096]
在本公开的一个实施例中,状态确定模块12用于:获取数据分片的历史每秒查询率和当前每秒查询率的平均值和标准差,并针对数据分片,获取当前每秒查询率与平均值之间的差值,并根据差值和标准差,确定当前每秒查询率所处的状态。
[0097]
在本公开的一个实施例中,热点确定模块13用于:若差值与标准差的比值超过预设值,则确定当前每秒查询率所处的状态为目标状态。
[0098]
在本公开的一个实施例中,每秒查询率为读出每秒查询率或写入每秒查询率。
[0099]
在本公开的一个实施例中,分布式存储系统的热点检测装置还包括存储模块(图中未示出),用于采用循环队列存储方式存储历史每秒查询率。
[0100]
在本公开的一个实施例中,分布式存储系统的热点检测装置还包括展示模块(图中未示出),用于在确定数据分片对应的存储节点为热点之后,采用可视化方式或日志方式展示热点的数据分片。
[0101]
在本公开的一个实施例中,热点确定模块13还用于:在确定数据分片对应的存储节点为热点之后,发送热点流量检测指令至热点,以便热点在接收到热点流量检测指令后进行热点流量检测。
[0102]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0103]
图7是根据一示例性实施例示出的一种监测服务器框图。图7示出的监测服务器仅
仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。如图7所示,监测服务器20包括处理器21,其可以根据存储在只读存储器(rom,read only memory)23中的程序或者从存储器22加载到随机访问存储器(ram,random access memory)24中的程序而执行各种适当的动作和处理。在ram 24中,还存储有监测服务器20操作所需的各种程序和数据。处理器21、rom 23以及ram 24通过总线25彼此相连。输入/输出(i/o,input/output)接口26也连接至总线25。
[0104]
以下部件连接至i/o接口26:包括硬盘等的存储器22;以及包括诸如lan(局域网,localarea network)卡、调制解调器等的网络接口卡的通信部分27,通信部分27经由诸如因特网的网络执行通信处理。
[0105]
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分27从网络上被下载和安装。在该计算机程序被处理器21执行时,执行本公开的方法中限定的上述功能。
[0106]
在示例性实施例中,还提供了一种包括指令的存储介质,例如包括指令的存储器,上述指令可由监测服务器20的处理器21执行以完成上述方法。可选地,存储介质可以是非临时性计算机可读存储介质,例如,所述非临时性计算机可读存储介质可以是rom、随机存取存储器(ram)、cd
‑
rom、磁带、软盘和光数据存储设备等。
[0107]
在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
[0108]
本公开实施例提供的分布式存储系统的热点检测方法、装置、监测服务器及存储介质,通过基于历史每秒查询率和当前每秒查询率,采用异常值检测方法,能够能够自动、快速且准确地发现热点,且写热点和读热点可以分别发现,有效解决了通过人工观察方式推测热点的位置导致的繁琐耗时以及正确率低的问题。
[0109]
图8是根据一示例性实施例示出的另一种分布式存储系统的热点检测方法的流程图,需要说明的是,该方法具体是用于热点数据(即热点流量)的检测,其基本原理是将分布式存储系统中已经落盘的数据进行抓包分析,以根据数据出现的频率进行热点数据分析,找出对应的热点数据。以该方法应用于图1中的存储服务器为例进行说明,包括以下步骤:
[0110]
在步骤s301中,将数据的键哈希分配至多个数据槽,并记录每个数据槽的数据流量。
[0111]
具体地,当需要进行热点数据检测时,可由监测服务器发送热点检测指令至存储服务器,存储服务器在接收到热点检测指令后,在内部对已经存储的数据进行周期性采样分析,确定热点数据。具体可以是,先将数据的键(key)经哈希(hash)计算得到哈希值,并将
该哈希值存储至多个数据槽中,同时记录每个数据槽的数据流量。可选的,在本公开的一些实施例中,记录每个数据槽的数据流量,包括:通过原子变量记录每个数据槽的数据流量。也就是说,将整个存储服务器的数据经哈希分为多个数据槽,并且每个数据槽通过原子变量保存相应的数据流量,从而可以保证多线程环境下流量统计的安全与效率。
[0112]
在本公开的一个实施例中,分布式存储系统的热点检测方法还可包括:接收热点检测指令,其中,热点检测指令包括用户输入的热点检测指令或者监测服务器在监测到存储服务器为热点时生成的;在接收到热点检测指令后,将数据的键哈希分配至多个数据槽。
[0113]
也就是说,热点数据的检测可包括手动启动以及经热点发现后的自动启动两种方式。具体地,可由监测服务器接收用户输入的热点检测指令,并将该指令发送至需要热点数据检测的某一个或多个存储服务器,以使这些存储服务器启动热点数据检测;或者,在监测服务器通过前述方式发现某一个存储服务器为热点时,自动向该存储服务器发送热点检测指令,以使该存储服务器启动热点数据检测,进而确定出热点数据。其中,监测服务器可通过rpc(remote procedure call,远程过程调用)方式发送热点检测指令至存储服务器。
[0114]
在步骤s302中,根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽。
[0115]
具体地,在获得每个数据槽的数据流量后,可基于数据流量对多个数据槽进行粗粒度筛查,以确定存在热点数据的数据槽,简称热点槽。
[0116]
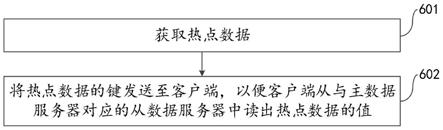
在本公开的一个实施例中,参考图9所示,根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽,包括:
[0117]
在步骤s401中,根据每个数据槽的数据流量,获取多个数据槽的数据流量平均值和数据流量标准差。
[0118]
具体地,在获得每个数据槽的数据流量后,可计算所有数据槽的数据流量平均值以及数据流量标准差,其中数据流量平均值agv1=(q1+q2+...+qm)/m,在该式中,q1、q2、...、qm为各个数据槽记录的数据流量,m为大于1的整数;数据流量标准差std1=sqrt((q1
‑
agv1)^2+(q2
‑
agv1)^2+...+(qm
‑
agv1)^2)/m。
[0119]
在步骤s402中,获取每个数据槽的数据流量与数据流量平均值之间的差值。
[0120]
可选地,每个数据槽的数据流量与数据流量平均值之间的差值为q1
‑
agv1、q2
‑
agv1、qm
‑
agv1。
[0121]
在步骤s403中,将差值与数据流量标准差的比值超过第一预设值的数据槽确定为热点槽。
[0122]
具体地,当步骤s402中计算得到的某一差值与数据流量标准差的比值超过第一预设值,则确定相应的数据槽为热点槽。
[0123]
由此,通过对每个数据槽记录的数据流量,基于均方差进行异常值分析,可确定出存在热点数据的数据槽,并将其确定为热点槽。需要说明的是,也可以采用其它异常值检测算法确定出存在异常的数据流量,例如dbscan聚类方法、孤立森林等一维异常值检测算法,本公开对此不作限定。
[0124]
在步骤s303中,对热点槽进行细粒度筛查,得到热点数据。
[0125]
也就是说,本公开采用双层筛查方式对已存储数据进行筛查,得到热点数据,具体是先基于每个数据槽记录的数据流量进行粗粒度筛查,得到热点槽,而后针对该热点槽进
行细粒度筛查,得到热点数据,这样可以有效提高筛查的效率,使其不影响主任务的执行,从而尽可能在不降低系统可用性以及性能的前提下,完成热点数据的分析。
[0126]
在本公开的一个实施例中,参考图10所示,对热点槽进行细粒度筛查,得到热点数据,包括:
[0127]
在步骤s501中,对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数。
[0128]
具体地,在对热点槽进行细粒度筛查时,可对热点槽对应的数据的值(value)进行读写操作,并记录每一类数据被读写的次数,以根据每一类数据被读写的次数,确定热点数据,也即根据数据出现的频率确定热点数据。
[0129]
在本公开的一个实施例中,对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数,包括:利用多个线程将热点槽对应的数据的值写入多个消息队列,其中,多个线程与多个消息队列一一对应;将热点槽对应的数据的值从多个消息队列中读出,并记录每一类数据被读写的次数。
[0130]
具体地,细粒度筛查可以使用多个生产者
‑
消费者队列(即消息队列)来保证抓取数据的效率以及多线程时的线程安全性,多线程包括读线程和写线程。在具体实施时,可先获取读线程和写线程的标识信息,并构造相应的生产者
‑
消费者队列,以及通过标识信息将读线程和写线程与相应的生产者
‑
消费者队列进行映射,在读写时,读线程和写线程向相应的生产者
‑
消费者队列中生产数据,即向相应的生产者
‑
消费者队列中写入热点槽对应的数据的值,这样不同的线程就不会相互抢锁,保证线程的安全与程序效率。在利用多个线程将热点槽对应的数据的值写入多个生产者
‑
消费者队列后,还将热点槽对应的数据的值从多个消息队列中读出,并记录每一类数据被读写的次数(实质是读出的次数),以根据每一类数据被读写的次数,确定热点数据。
[0131]
在步骤s502中,根据每一类数据被读写的次数,确定热点数据。
[0132]
具体地,在获得每一类数据被读写的次数后,可根据每一类数据被读写的次数确定热点数据。
[0133]
在本公开的一个实施例中,根据每一类数据被读写的次数,确定热点数据,包括:根据每一类数据被读写的次数,获取所有类数据被读写的次数平均值和次数标准差;获取每一类数据被读写的次数与次数平均值之间的差值;将差值与次数标准差的比值超过第二预设值的数据确定为热点数据。
[0134]
具体地,在获得每一类数据被读写的次数后,可先计算所有类数据被读写的次数平均值和次数标准差,其中次数平均值agv2=(k1+k2+...+kx)/x,在该式中,k1、k2、...、kx为每一类数据被读写的次数,x为正整数;次数标准差std2=sqrt((k1
‑
agv2)^2+(k2
‑
agv2)^2+...+(kx
‑
agv2)^2)/x。而后,计算每一类数据被读写的次数与次数平均值之间的差值,分别为k1
‑
agv2、k2
‑
agv2、kx
‑
agv2,最后计算各个差值与次数标准差的比值,并与第二预设值进行比较,如果比值超过第二预设值,则确定相应的数据为热点数据。
[0135]
由此,通过对热点槽中每一类数据出现的次数(即频率),基于均方差进行异常值分析,可确定出热点数据。需要说明的是,也可以采用其它异常值检测算法确定出热点数据,例如dbscan聚类方法、孤立森林等一维异常值检测算法,本公开对此不作限定。
[0136]
在本公开的一个实施例中,存储服务器包括读数据线程池、写数据线程池和分析
线程池,其中,通过读数据线程池和写数据线程池分别利用多个线程将数据的键哈希分配至多个数据槽,并将热点槽对应的数据的值写入多个消息队列,通过分析池利用多个线程进行粗粒度筛查和细粒度筛查。
[0137]
也就是说,在存储服务器内部,可包括读数据线程池、写数据线程池和分析线程池,抓取读数据、抓取写数据以及对数据进行热点检测得到热点数据分别在这三个线程池中进行,并且每个线程池均具有可同时作业的多个线程。
[0138]
具体地,参考图11所示,在存储服务器执行主任务的过程中,还可通过上述读数据线程池和写数据线程池抓取已经落盘的数据,并通过分析线程池进行热点数据检测。在进行热点数据检测时,首先进行粗粒度筛查,在筛查时,先通过读数据线程池和写数据线程池将读数据和写数据从存储服务器内部读出,并经哈希分配至多个数据槽中,同时记录每个数据槽的数据流量。考虑到在无锁情况下多线程的安全性,粗粒度筛查可采用一个原子单元的定长数组实现,并通过原子变量记录数据流量,这样可以保证多线程环境下流量统计的线程安全与效率。而后,通过分析线程池周期性地对各个数据槽的数据流量进行分析,以筛选出具有热点数据的数据槽,记为热点槽,这样可以尽可能地保证正常读写时间片分配,即通过将从存储服务器抓取读数据、抓取写数据以及对数据进行粗粒度筛查运行于不同的线程池中,可以保证正常读写的时间片分配,尽可能减少对主任务的影响。
[0139]
在粗粒度筛查得到热点槽后,开始对热点槽进行细粒度筛查。在细粒度筛查时,可为读数据线程池和写数据线程池中的每个线程对应一个生产者
‑
消费者队列即消息队列,读数据线程池和写数据线程池中的各个线程作为生产者将热点槽对应的数据的值写入相应的队列中,分析线程池从各个队列中读出热点槽对应的数据,并记录每一类数据被读写的次数(这里实质是被读出的次数),进而基于每一类数据被读写的次数确定出热点数据。其中,通过将从存储服务器抓取读数据、抓取写数据以及对热点槽对应的数据进行细粒度筛查运行于不同的线程池中,可以保证正常读写的时间片分片,尽可能减少对主任务的影响,同时针对每个线程对应一个消息队列,可在无锁的情况下保证线程的安全性与程序效率。
[0140]
由此,通过将数据的抓取和分析运行于不同的线程池中,可减少对主任务的影响,同时基于原子变量进行数据流量记录,可保证线程的安全性,以及针对每个线程对应一个消息队列,可以保证线程的安全性与程序效率。
[0141]
在本公开的一个实施例中,在得到热点数据之后,分布式存储系统的热点检测方法还包括:进行热点数据预警,和/或,以日志形式展示热点数据。
[0142]
为了验证本公开的热点数据检测方法所具有的效果,可基于图1所示分布式存储系统,对本公开进行准确度测试、性能测试以及性能分析。
[0143]
具体地,在进行准确度测试时,可构造类似真实情况下分布式存储系统的数据,测试方法类似于前述热点分片检测方法的测试,这里不再赘述,测试结果如表2所示:
[0144]
表2
[0145][0146]
在进行性能测试时,测试环境为:测试集群使用intel(r)xeon(r)cpu e5
‑
2620 v4@2.10ghz处理器、128g内存、480g sata接口固态硬盘*8,万兆网卡,操作系统采用centos linux release 7.3.1611with linux version 3.18.6版本。负载为:使用性能测试工具ycsb进行压力测试,利用一台单独的主机对测试集群进行请求发送,其中,ycsb的测试字符串长度为320bytes,累计发送300000000条数据,且每条数据随机生成,然后再启动一个热点生成客户端进行测试。测试选取了最常见的两种使用情形:一种(即test1)为读写较为均衡的使用情景,常用于内部集群元信息的写入;另一种(即test2)是互联网产品使用的典型情况,读多写少,可以反映如应用商店评论区、交流论坛的应用表现情况。两种数据集分别在关闭热点数据抓取与开启全局范围的热点数据抓取时进行实验,最终得到如表3所示测试结果:
[0147]
表3
[0148][0149][0150]
从表3可以看出,在开启热点数据检测的情况下,热点数据检测在两种数据集下表现的都比较优秀,与开启热点数据检测之前的性能无较大差别,可以在单机热点压力较大时正常使用。
[0151]
为了能够更加直观的看到本公开的各个部分对于性能的影响,可以使用单元测试代码用系统时间统计对于相同的数据流量,热点数据检测全部捕获的时间。同时,为了展现各环节的效率,设置两组对照组:第一组对照组去掉了双层筛查结构,直接将数据分线程导
入消息队列;第二组去掉了线程分组,将所有线程的数据放入允许多生产者的消息队列中进行测试,测试结果如图12所示。从图12可以看出,两个对照组的实验结果在不同程度上劣于实验组,其中,第二对照组的差距较大,其原因可能是在多线程使用同一个消息队列时,即使采用无锁化的原子操作,也会占用较多的cpu时间,因此在设计上要尽可能地避免多线程同时抢占一个资源的情况。
[0152]
图13是根据一示例性实施例示出的一种分布式存储系统的热点检测装置框图,参考图13所示,该分布式存储系统的热点检测装置30包括:粗粒度筛选模块31和细粒度筛选模块32。
[0153]
其中,粗粒度筛选模块31被配置为用于将数据的键哈希分配至多个数据槽,并记录每个数据槽的数据流量,以及根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽;细粒度筛选模块32被配置为用于对热点槽进行细粒度筛查,得到热点数据。
[0154]
在本公开的一个实施例中,粗粒度筛选模块31用于:通过原子变量记录每个数据槽的数据流量。
[0155]
在本公开的一个实施例中,粗粒度筛选模块31用于:根据每个数据槽的数据流量,获取多个数据槽的数据流量平均值和数据流量标准差,并获取每个数据槽的数据流量与数据流量平均值之间的差值,以及将差值与数据流量标准差的比值超过第一预设值的数据槽确定为热点槽。
[0156]
在本公开的一个实施例中,细粒度筛选模块32用于:对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数,以及根据每一类数据被读写的次数,确定热点数据。
[0157]
在本公开的一个实施例中,细粒度筛选模块32用于:利用多个线程将热点槽对应的数据的值写入多个消息队列,其中,多个线程与多个消息队列一一对应,以及将热点槽对应的数据的值从多个消息队列中读出,并记录每一类数据被读写的次数。
[0158]
在本公开的一个实施例中,细粒度筛选模块32用于:根据每一类数据被读写的次数,获取所有类数据被读写的次数平均值和次数标准差,并获取每一类数据被读写的次数与次数平均值之间的差值,以及将差值与次数标准差的比值超过第二预设值的数据确定为热点数据。
[0159]
在本公开的一个实施例中,存储服务器包括读数据线程池、写数据线程池和分析线程池,其中,粗粒度筛选模块31还用于:通过读数据线程池和写数据线程池分别利用多个线程将数据的键哈希分配至多个数据槽,并通过分析池利用多个线程进行粗粒度筛查;细粒度筛选模块32还用于:通过读数据线程池和写数据线程池分别利用多个线程将热点槽对应的数据的值写入多个消息队列,并通过分析池利用多个线程进行细粒度筛查。
[0160]
在本公开的一个实施例中,分布式存储系统的热点检测装置还包括:提醒模块(图中未示出),用于在细粒度筛选模块32得到热点数据之后,进行热点数据预警,和/或,以日志形式展示热点数据。
[0161]
在本公开的一个实施例中,分布式存储系统的热点检测装置还包括:指令接收模块(图中未示出),用于接收热点检测指令,其中热点检测指令包括用户输入的热点检测指令或者监测服务器在监测到存储服务器为热点时生成的。
[0162]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0163]
图14是根据一示例性实施例示出的一种存储服务器框图。图14示出的存储服务器仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。如图14所示,存储服务器40包括处理器41,其可以根据存储在只读存储器(rom,read only memory)43中的程序或者从存储器42加载到随机访问存储器(ram,randomaccess memory)44中的程序而执行各种适当的动作和处理。在ram 44中,还存储有存储服务器40操作所需的各种程序和数据。处理器41、rom 43以及ram 44通过总线45彼此相连。输入/输出(i/o,input/output)接口46也连接至总线45。
[0164]
以下部件连接至i/o接口46:包括硬盘等的存储器42;以及包括诸如lan(局域网,local area network)卡、调制解调器等的网络接口卡的通信部分47,通信部分47经由诸如因特网的网络执行通信处理。
[0165]
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分47从网络上被下载和安装。在该计算机程序被处理器41执行时,执行本公开的方法中限定的上述功能。
[0166]
在示例性实施例中,还提供了一种包括指令的存储介质,例如包括指令的存储器,上述指令可由存储服务器40的处理器41执行以完成上述方法。可选地,存储介质可以是非临时性计算机可读存储介质,例如,所述非临时性计算机可读存储介质可以是rom、随机存取存储器(ram)、cd
‑
rom、磁带、软盘和光数据存储设备等。
[0167]
在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
[0168]
本公开实施例提供的分布式存储系统的热点检测方法、装置、存储服务器及存储介质,通过双层无锁筛查结构对存储服务器内的数据进行抓包分析,在高并发大流量的环境下,能够在基本不降低系统可用性以及性能的前提下,完成热点数据的定位分析,确定出热点数据,以便于对该热点数据及时处理,防止系统故障,即因热点数据导致单机压力过大导致宕机,与传统的通过在存储服务器的前端增设一层代理过滤流量即流式计算系统相比,能够减少对主任务的影响,提高系统可用性。同时,利用原子变量以及多个消息队列,可以保证多线程的安全性及程序效率。
[0169]
图15是根据一示例性实施例示出的一种分布式存储系统的热点削峰方法的流程图,以该方法应用于图1所示存储服务器中的主数据服务器为例进行说明,包括以下步骤:
[0170]
在步骤s601中,获取热点数据。
[0171]
在步骤s602中,将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值。
[0172]
具体来说,在无热点数据时,仅由主数据服务器对外提供数据服务,此时客户端对主数据服务器进行读写操作,同时从数据服务器时刻同步主数据服务器的数据,以在主数据服务器出现宕机时,及时恢复数据,保证服务的可用性。
[0173]
而在获得热点数据后,可开启热点削峰功能,此时将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值,以进行热点削峰,也就是说,在本公开中,从数据服务器不仅能够时刻同步主数据服务器的数据,而且在出现热点数据时,能够提供数据服务,此时主数据服务器可将数据的键发送至客户端,由客户端从对应的从数据服务器中读取热点数据的值,以进行热点数据的分流,减轻主数据服务器的压力。
[0174]
由此,通过将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值,以进行热点数据的分流,减轻主数据服务器的压力,从而能够在无扩容条件下,有效减轻在大流量、高并发情景下由热点问题带来的单机负载过高,导致系统整体可用性降低,甚至导致单点宕机的问题,同时能够解决因开发人员对分布式存储系统使用不当导致的单机负载压力过大的问题,以及因存储的键值对大小过大导致的类似热点的问题。
[0175]
需要说明的是,在将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值的过程中,还通过一致性协议保持数据的一致性。
[0176]
具体来说,在图1所示分布式存储系统中,数据的多副本备份可采用pacifica一致性算法来实现。在pacifica中,如果所有集群均是以顺序处理相同的请求集,假设更新是确定性的,则可以实现强一致性。主数据服务器分配了连续递增的序列号进行更新,所有从数据服务器跟随这一序列号处理请求。
[0177]
具体地,当主数据服务器收到一个查询请求后,其立刻返回一个本地当前版本的数据。当主数据服务器收到一个更新请求后,该主数据服务器将分配一个可用的序列号给该请求,并写入准备信息(prepare message)中,发送给所有的从数据服务器,当从数据服务器收到该请求后,从数据服务器将该请求入序列化的准备信息中,并返回一个确认信息给主数据服务器,由主数据服务器将确认时刻(commitpoint)向前移动到顶,顶下请求被提交,并反馈给客户端已成功提交的信息。在发送准备信息时,主数据服务器将此时已经提交的请求的确认时刻附带,从数据服务器以此来移动自身的确认时刻,在这个主从复制过程中,主数据服务器与从数据服务器数据始终保持线性一致性。
[0178]
开启热点削峰后,在处理查询请求时,访问从数据服务器时,数据保持线性一致性;访问主数据服务器时,因为主数据服务器的每次更新数据都会在得到从数据服务器的准备信息确认后再将答复传给客户端,所以从数据服务器依旧保持线性一致性。
[0179]
但在有异常发生时,比如当从数据服务器突然与主数据服务器发生网络分区,此时主数据服务器无法与从数据服务器同步数据,而从数据服务器若依然处于心跳包的租约范围内,从数据服务器不会主动拒绝请求,客户端由于默认向从数据服务器发送数据,有可能拿到过期数据,直到从数据服务器的租约到期拒绝提供服务,所以在该情况下,数据的一
致性将会退化成顺序一致性。虽然该情况下会牺牲一定的数据一致性,但是在出现热点数据时,本公开的热点削峰方法能够有效缓解热点数据对单机的压力,保证整个系统的可用性,并在一定程度上保持了系统的强一致性。
[0180]
为了验证本公开的热点削峰方法所具有的效果,可基于图1所示分布式存储系统,分两个方向对热点削峰性能进行测试:其一(test1)是测试当使用了热点削峰方案后,热点数据的延迟是否存在显著变化;其二(test2)是测试当使用了热点削峰方案后,热点数据的负载是否得到有效降低,测试环境如前述热点数据检测的测试环境相同,这里不再赘述,测试结果如表4和图16所示:
[0181]
表4
[0182][0183]
表4给出了由ycsb给出的系统整体性能,图16给出了主数据服务器和从数据服务器的cpu使用率,从表4和图16可以看出,热点削峰方案在由数据倾斜造成的热点问题下,主数据服务器的压力能够被有效缓解,集群整体的响应速度与吞吐有所提高,从数据服务器由于分担了大部分热点数据,资源占用率略有提高,但依然处在不影响系统稳定性的水平上。
[0184]
在本公开的一个实施例中,获取热点数据,包括:将数据的键哈希分配至多个数据槽,并记录每个数据槽的数据流量;根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽;对热点槽进行细粒度筛查,得到热点数据。
[0185]
在本公开的一个实施例中,通过原子变量记录每个数据槽的数据流量。
[0186]
在本公开的一个实施例中,根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽,包括:根据每个数据槽的数据流量,获取多个数据槽的数据流量平均值和数据流量标准差;获取每个数据槽的数据流量与数据流量平均值之间的差值;将差值与数据流量标准差的比值超过第一预设值的数据槽确定为热点槽。
[0187]
在本公开的一个实施例中,对热点槽进行细粒度筛查,得到热点数据,包括:对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数;根据每一类数据被读写的次数,确定热点数据。
[0188]
在本公开的一个实施例中,对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数,包括:利用多个线程将热点槽对应的数据的值写入多个消息队列,其中,多个线程与多个消息队列一一对应;将热点槽对应的数据的值从多个消息队列中读出,
并记录每一类数据被读写的次数。
[0189]
在本公开的一个实施例中,根据每一类数据被读写的次数,确定热点数据,包括:根据每一类数据被读写的次数,获取所有类数据被读写的次数平均值和次数标准差;获取每一类数据被读写的次数与次数平均值之间的差值;将差值与次数标准差的比值超过第二预设值的数据确定为热点数据。
[0190]
在本公开的一个实施例中,主数据服务器包括读数据线程池、写数据线程池和分析线程池,其中,通过读数据线程池和写数据线程池分别利用多个线程将数据的键哈希分配至多个数据槽,并将热点槽对应的数据的值写入多个消息队列,通过分析池利用多个线程进行粗粒度筛查和细粒度筛查。
[0191]
在本公开的一个实施例中,方法还包括:接收热点检测指令,其中,热点检测指令包括用户输入的热点检测指令或者监测服务器在监测到主数据服务器为热点时生成的;在接收到热点检测指令后,获取热点数据。
[0192]
需要说明的是,关于本公开的热点削峰方法中获取热点数据的过程,请参考前述图8至图11所对应的热点数据检测的过程,这里就不再赘述。
[0193]
图17是根据一示例性实施例示出的一种分布式存储系统的热点削峰装置框图,其应用于主数据服务器,参考图17所示,该分布式存储系统的热点削峰装置50包括:获取模块51和发送模块52。
[0194]
其中,获取模块51被配置为用于获取热点数据;发送模块52被配置为用于将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值。
[0195]
在本公开的一个实施例中,获取模块51用于:将数据的键哈希分配至多个数据槽,并记录每个数据槽的数据流量,以及根据每个数据槽的数据流量对多个数据槽进行粗粒度筛查,得到热点槽,并对热点槽进行细粒度筛查,得到热点数据。
[0196]
在本公开的一个实施例中,获取模块51用于:通过原子变量记录每个数据槽的数据流量。
[0197]
在本公开的一个实施例中,获取模块51用于:根据每个数据槽的数据流量,获取多个数据槽的数据流量平均值和数据流量标准差,并获取每个数据槽的数据流量与数据流量平均值之间的差值,以及将差值与数据流量标准差的比值超过第一预设值的数据槽确定为热点槽。
[0198]
在本公开的一个实施例中,获取模块51用于:对热点槽对应的数据的值进行读写操作,并记录每一类数据被读写的次数,以及根据每一类数据被读写的次数,确定热点数据。
[0199]
在本公开的一个实施例中,获取模块51用于:利用多个线程将热点槽对应的数据的值写入多个消息队列,其中,多个线程与多个消息队列一一对应,以及将热点槽对应的数据的值从多个消息队列中读出,并记录每一类数据被读写的次数。
[0200]
在本公开的一个实施例中,获取模块51用于:根据每一类数据被读写的次数,获取所有类数据被读写的次数平均值和次数标准差,并获取每一类数据被读写的次数与次数平均值之间的差值,以及将差值与次数标准差的比值超过第二预设值的数据确定为热点数据。
[0201]
在本公开的一个实施例中,主数据服务器包括读数据线程池、写数据线程池和分析线程池,其中,获取模块51还用于通过读数据线程池和写数据线程池分别利用多个线程将数据的键哈希分配至多个数据槽,并将热点槽对应的数据的值写入多个消息队列,以及通过分析池利用多个线程进行粗粒度筛查和细粒度筛查。
[0202]
在本公开的一个实施例中,分布式存储系统的热点削峰装置还包括:指令接收模块(图中未示出),用于接收热点检测指令,其中,热点检测指令包括用户输入的热点检测指令或者监测服务器在监测到主数据服务器为热点时生成的。
[0203]
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0204]
图18是根据一示例性实施例示出的一种存储服务器框图。图18示出的存储服务器仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。如图18所示,存储服务器60包括处理器61,其可以根据存储在只读存储器(rom,read only memory)63中的程序或者从存储器62加载到随机访问存储器(ram,randomaccess memory)64中的程序而执行各种适当的动作和处理。在ram 64中,还存储有存储服务器60操作所需的各种程序和数据。处理器61、rom 63以及ram 64通过总线65彼此相连。输入/输出(i/o,input/output)接口66也连接至总线65。
[0205]
以下部件连接至i/o接口66:包括硬盘等的存储器62;以及包括诸如lan(局域网,localareanetwork)卡、调制解调器等的网络接口卡的通信部分67,通信部分67经由诸如因特网的网络执行通信处理。
[0206]
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分67从网络上被下载和安装。在该计算机程序被处理器61执行时,执行本公开的方法中限定的上述功能。
[0207]
在示例性实施例中,还提供了一种包括指令的存储介质,例如包括指令的存储器,上述指令可由存储服务器60的处理器61执行以完成上述方法。可选地,存储介质可以是非临时性计算机可读存储介质,例如,所述非临时性计算机可读存储介质可以是rom、随机存取存储器(ram)、cd
‑
rom、磁带、软盘和光数据存储设备等。
[0208]
在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
[0209]
图19是根据一示例性实施例示出的另一种分布式存储系统的热点削峰方法的流程图,其应用于如图1所示的客户端,包括以下步骤:
[0210]
在步骤s701中,在接收到分布式存储系统中的主数据服务器发送的热点数据的键
后,从与主数据服务器对应的从数据服务器中读出热点数据的值。
[0211]
具体来说,在无热点数据时,仅由主数据服务器对外提供数据服务,此时客户端对主数据服务器进行读写操作,同时从数据服务器时刻同步主数据服务器的数据,以在主数据服务器出现宕机时,及时恢复数据,保证服务的可用性。
[0212]
而在获得热点数据后,可开启热点削峰功能,此时主数据服务器将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值,以进行热点削峰,也就是说,在本公开中,从数据服务器不仅能够时刻同步主数据服务器的数据,而且在出现热点数据时,能够提供数据服务,此时主数据服务器可将数据的键发送至客户端,由客户端从对应的从数据服务器中读取热点数据的值,以进行热点数据的分流,减轻主数据服务器的压力。
[0213]
由此,通过将热点数据的键发送至客户端,并且客户端从与主数据服务器对应的从数据服务器中读出热点数据的值,以进行热点数据的分流,减轻主数据服务器的压力,从而能够在无扩容条件下,有效减轻在大流量、高并发情景下由热点问题带来的单机负载过高,导致系统整体可用性降低,甚至导致单点宕机的问题,同时能够解决因开发人员对分布式存储系统使用不当导致的单机负载压力过大的问题,以及因存储的键值对大小过大导致的类似热点的问题。
[0214]
图20是根据一示例性实施例示出的一种客户端框图。图20示出的客户端仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。如图20所示,客户端70包括处理器71,其可以根据存储在只读存储器(rom,read only memory)73中的程序或者从存储器72加载到随机访问存储器(ram,randomaccess memory)74中的程序而执行各种适当的动作和处理。在ram 74中,还存储有客户端70操作所需的各种程序和数据。处理器71、rom 73以及ram 74通过总线75彼此相连。输入/输出(i/o,input/output)接口76也连接至总线75。
[0215]
以下部件连接至i/o接口76:包括硬盘等的存储器72;以及包括诸如lan(局域网,localareanetwork)卡、调制解调器等的网络接口卡的通信部分77,通信部分77经由诸如因特网的网络执行通信处理。
[0216]
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分77从网络上被下载和安装。在该计算机程序被处理器71执行时,执行本公开的方法中限定的上述功能。
[0217]
在示例性实施例中,还提供了一种包括指令的存储介质,例如包括指令的存储器,上述指令可由客户端70的处理器71执行以完成上述方法。可选地,存储介质可以是非临时性计算机可读存储介质,例如,所述非临时性计算机可读存储介质可以是rom、随机存取存储器(ram)、cd
‑
rom、磁带、软盘和光数据存储设备等。
[0218]
在本公开中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本公开中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何
计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
[0219]
本公开实施例提供的分布式存储系统的热点削峰方法、装置、存储服务器、客户端及存储介质,获取热点数据,并将热点数据的键发送至客户端,以便客户端从与主数据服务器对应的从数据服务器中读出热点数据的值,由此,针对热点数据,通过客户端读取从数据服务器中的热点数据的值,进行热点数据分流,以减轻主数据服务器的压力,以便快速缓解系统故障的风险,即因单机压力过大导致宕机的风险。
[0220]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本公开旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
[0221]
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1