一种数据库表的差异比较方法及装置与流程
1.本发明涉及计算机数据备份容灾技术领域,特别是涉及一种大数据量的数据库表的差异比较方法和装置。
背景技术:
2.目前,在计算机数据容灾备份过程中,经常需要进行数据库表的比较,例如,在进行数据备份之前需要查询备份源端和备份目的端当前的数据库表差异以决定是否备份,此时需要进行数据库表比较,而在数据备份之后确认数据是否完整、准确,也需要对备份源端和备份目的端进行数据库表比较,因此,数据库表的差异比较在计算机数据容灾备份过程中至关重要。
3.目前,计算机数据容灾备份中的数据库表比较过程通常采用如下过程:数据库表比较时需要对源端数据库中每行数据和备份端数据库中每行数据都进行 md5加密,然后使用md5数据进行比较,如果相同就代表行数据相同。
4.具体地,对数据行进行md5加密之前需要对每行的数据进行处理,处理时将每行数据的每一列转换(即将行的每列数据存到连续的字节空间,然后对这个连续的空间执行md5加密),然后所有列的转换结果汇总,对汇总之后再进行 md5加密操作,源端的数据在源端已经进行处理,发送到备份端则已经是md5 数据了,当源端的数据行发送到备份端后,备份端读取备端的数据库数据,然后对数据行进行md5加密,与源端发送来的数据进行比较,此时如果差异数据量特别大,或者不确定哪一端的数据读取特别慢,则会导制比较进程比较缓慢,从而积压大量未进行比较的数据,由于内存中积存大量数据,很可能导制内存撑爆,进程崩溃。
技术实现要素:
5.为克服上述现有技术存在的不足,本发明之目的在于提供一种数据库表的差异比较方法和装置,以通过在数据库表比较进行中积存数据量过大时,将一部分数据暂时保存文件,并在差异数据过大停止表比较返回当前结果,从而避免将内存撑爆的问题。
6.为达上述目的,本发明提出一种数据库表的差异比较方法,包括如下步骤:
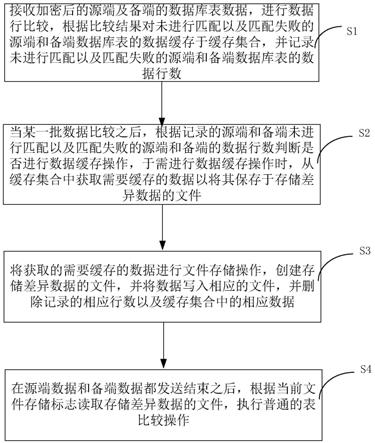
7.步骤s1,接收加密后的源端及备端的数据库表数据,进行数据行比较,根据比较结果对未进行匹配以及匹配失败的源端和备端数据库表的数据缓存于缓存集合,并记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数;
8.步骤s2,当某一批数据比较之后,根据记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数判断是否进行数据缓存操作,于需进行数据缓存操作时,从缓存集合中获取需要缓存的数据以将其保存于存储差异数据的文件;
9.步骤s3,将获取的需要缓存的数据进行文件存储操作,创建存储差异数据的文件,并将数据写入相应的文件,并删除记录的相应行数以及缓存集合中的相应数据;
10.步骤s4,在源端数据和备端数据都发送结束之后,读取存储差异数据的文件,执行
普通的表比较操作。
11.优选地,于步骤s1中,利用数据行数数组记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数,所述数据行数数组为二维整型数组。
12.优选地,于步骤s1中,利用一个二维哈希数组的缓存集合对未进行匹配以及匹配失败的源端和备端数据库表的数据进行缓存。
13.优选地,所述用于缓存未进行匹配以及匹配失败的源端和备端数据库表的数据的二维哈希数组为:
14.m_hash[当前数据源端还是备端][key值]
[0015]
其中,key值为使用预设的key函数对相应的行数据代表的md5加密获得。
[0016]
优选地,于步骤s2中,将记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数相加,如果相加结果大于预设的阈值,则确定需进行缓存操作。
[0017]
优选地,在保存缓存数据之前将记录的源端数据行数和备端的数据行数进行比较,确定哪端的数据行数更大,从而确定存储行数更大的一端。
[0018]
优选地,于步骤s2中,当进行数据缓存操作时,确定一个key,根据key 从缓存集合中每次遍历增加256的方法获取存储数据存储于同一文件下。
[0019]
优选地,于步骤s3中,以确定的key与当前表的objn为文件名创建文件,将获取的数据存储写入相应的文件,并将缓存是否进行了存储的标志设置为 true。
[0020]
优选地,于步骤s4中,在进行读取文件前,先将缓存集合中剩余的从源备端发过来比较之后未匹配的数据存储到相应文件,之后读取文件,每次读取一个文件对其中的数据执行普通的表比较操作。
[0021]
为达到上述目的,本发明还提供一种数据库表的差异比较装置,包括:
[0022]
数据行比较处理单元,用于接收加密后的源端及备端的数据库表数据,进行数据行比较,根据比较结果对未进行匹配以及匹配失败的源端和备端数据库表的数据缓存于缓存集合,并记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数;
[0023]
数据缓存单元,用于当某一批数据比较之后,根据记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数判断是否进行数据缓存操作,于需进行数据缓存操作时,从缓存集合中获取需要缓存的数据以将其保存于文件;
[0024]
文件存储单元,用于将获取的需要缓存的数据进行文件存储操作,创建存储差异数据的文件,并将数据写入相应的文件,并删除记录的相应行数以及缓存集合中的相应数据;
[0025]
文件读取比较单元,用于在源端数据和备端数据都发送结束之后,读取存储差异数据的文件,执行普通的表比较操作。
[0026]
与现有技术相比,本发明一种数据库表的差异比较方法和装置通过在数据库表比较进行中积存数据量过大时,将一部分数据暂时保存文件,并在差异数据过大停止表比较返回当前结果,从而实现了避免将内存撑爆的目的。
附图说明
[0027]
图1为本发明一种数据库表的差异比较方法的步骤流程图;
[0028]
图2为本发明一种数据库表的差异比较装置的系统架构图;
具体实施方式
[0029]
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
[0030]
图1为本发明一种数据库表的差异比较方法的步骤流程图。如图1所示,本发明一种数据库表的差异比较方法,包括如下步骤:
[0031]
步骤s1,接收加密后的源端及备端的数据库表数据,进行数据行比较,根据比较结果对未进行匹配以及匹配失败的源端和备端数据库表的数据缓存于缓存集合,并记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数。
[0032]
在本发明中,表进行的操作是在备端进行,首先初始化一个数据行数数组,用来记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数,在本发明具体实施例中,所述数据行数数组为二维整型数组,对应源端和备端,如果源端的数据不匹配,那么数组对应源端的值加1,如果备端的数据不匹配,则数组对应备端的值加1,在本发明具体实施例中,源端与备端的数据都是进行md5 加密的,也就是说,无论此时传过来的该数据行是源端数据还是备端数据,如果没有匹配的对应的数据,也就是md5没有相同的,那么于该数据行数数组中该数据对应端的数据行数就会加1,即如果是源端的数据没匹配,那么该数据行数数组中对应源端的值加1,如果是备端数据没匹配则该数据行数数组中对应备端的值加1。
[0033]
在数据库表比较时,除了记录源端和备端的行数,还对未进行匹配以及匹配失败的源端和备端数据库表的数据进行缓存,具体地,所述缓存集合为一个二维哈希数组(2),即将源端和备端未进行匹配以及匹配失败的数据库表的数据存储在一个二维哈希数组(2)中,由于行数据md5的值有256种,在本发明具体实施例中,使用预设的key函数对行数据代表的md5加密获得key值,表比较时将未进行匹配以及匹配失败的数据存到数组中对应的key,例如如下二维哈希数组:
[0034]
m_hash[当前数据源端还是备端][key值]
[0035]
例如,如果某行数据md5值根据key函数获得的key值是254,则将该数据行的数据存到m_hash[0][254],,若某行数据md5值根据key函数获得的key 值为762,则将该数据行的数据存到m_hash[0][762]。由于key是根据数据行的 md5计算的,所以每次保存的也是随机的,而且有效数据不会是相同的,从而可以均匀的保存数据。
[0036]
也就是说,假设二维哈希数组(2)中0对应源端,1对应备端,源端传送数据与m_hash[1][x]数据比较,匹配失败则记录的数据行数的二维整型数组对应源端的值加1,并将源端未匹配数据存到m_hash[0][x],反之备端传输数据与m_hash[0][x]比较,匹配失败则记录的数据行数的二维整型数组对应备端的值加 1,并将备端未匹配数据存到m_hash[1][x]。
[0037]
步骤s2,当某一批数据比较之后,根据记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数判断是否进行数据缓存操作,于需进行数据缓存操作时,从缓存集合中获取需要缓存的数据以将其保存于文件。
[0038]
具体地,当某一批数据比较之后,将记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数相加,如果相加结果大于预设的阈值(此阈值为固定值,例如内存
缓存数据的最大行数),则表示需进行缓存操作,需将二维哈希数组(2)中存储的数据进行保存文件,如果未超过预设的阈值,则继续比较处理下一批数据。
[0039]
优选地,在保存缓存数据之前首先将记录的源端数据行数和备端的数据行数进行比较,确定哪端行数更大,以存储行数更大的一端。
[0040]
当匹配失败的数据行过大时,则准备从缓存集合中获取数据存成文件。具体地,首先确定一个key(例如使用一个宏定义((idx)&(256
‑
1))决定此时存储的key),假如此次决定存文件的key为11,那么从m_hash[x][11], m_hash[x][11+256],m_hash[x][11+256*2[,m_hash[x][11+256*3]抓数据进行文件存储,也就是说,需要缓存的数据根据key(通过数据行的md5使用key函数获得)从缓存集合中每次遍历增加256的方法获取存储数据。
[0041]
步骤s3,将获取的需要缓存的数据进行文件存储操作,创建存储差异数据的文件,将数据写入相应的文件,并删除记录的相应行数以及缓存集合中的相应数据。
[0042]
具体地说,在需要存储的数据获取之后开始文件存储操作,存储差异数据的文件的文件名根据之前确定的key和表的objn创建,例如key为254,则创建文件名为254_123456(假设123456为表objn)的文件,然后将需要存储的数据写入对应目录的文件,并将缓存是否进行了存储的标志即文件存储标志设置为 true。
[0043]
步骤s4,在源端数据和备端数据都发送结束之后,读取存储差异数据的文件,执行普通的表比较操作。
[0044]
具体地,在源端数据和备端数据都发送结束之后,判断文件存储标志是否为true,如果为true,那么将读取文件(即读取时objn_key文件为true时才有读文件操作),因为缓存的数据有部分是因为已经比较之后差异的,但还有一部分是因为与他匹配的数据还没传送来,因此需要在该表数据源端备端都发送过来之后再进行比较。
[0045]
具体地,读取文件前,先将现有数据(指内存缓存集合中剩余的从源备端发过来比较之后未匹配的数据)存储到文件,之后读取文件,每次读取一个文件(即 objn_key文件,其中存储的是源端和备端的未匹配成功的行数据)的,也就是比较一个key对应的文件中的数据,某一个key对应的文件中的数据比较结束之后再比较下一key对应的文件。因为只是某一个key对应的文件撑满内存的几率也不大。具体地,读取对应key文件的内容,里面存储了源端发送和备端发送的数据,由于存储的数据有类型,因此可以区分源端和备端,然后对其中的数据执行普通的表比较操作。因为是读取的文件操作,不会有数据延迟的问题,在某一个key对应的文件比较时如果其差异数据已经大于预设的阈值,则表示当前比较结果出错,那么则不比较其他key了,避免内存撑满,因为差异数据太多意义也不大,此时表比较结束,需返回重新进行表比较操作。
[0046]
图2为本发明一种数据库表的差异比较装置的系统架构图。如图2所示,本发明一种数据库表的差异比较装置,包括:
[0047]
数据行比较处理单元201,用于接收加密后的源端及备端的数据库表数据,进行数据行比较,根据比较结果对未进行匹配以及匹配失败的源端和备端数据库表的数据缓存于缓存集合,并记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数。
[0048]
在本发明中,表进行的操作是在备端进行,首先初始化一个数据行数数组,用来记录未进行匹配以及匹配失败的源端和备端数据库表的数据行数,在本发明具体实施例中,所述数据行数数组为二维整型数组,对应源端和备端,如果源端的数据不匹配,那么数组对
应源端的值加1,如果备端的数据不匹配,则数组对应备端的值加1,在本发明具体实施例中,源端与备端的数据都是进行md5 加密的,也就是说,无论此时传过来的该数据行是源端数据还是备端数据,如果没有匹配的对应的数据,也就是md5没有相同的,那么于该数据行数数组中该数据对应端的数据行数就会加1,即如果是源端的数据没匹配,那么该数据行数数组中对应源端的值加1,如果是备端数据没匹配则该数据行数数组中对应备端的值加1。
[0049]
在数据库表比较时,除了记录源端和备端的行数,还需对未进行匹配以及匹配失败的源端和备端数据库表的数据进行缓存,具体地,所述缓存集合为一个二维哈希数组(2),即将源端和备端未进行匹配以及匹配失败的数据库表的数据存储在一个二维哈希数组(2)中,由于行数据md5的每一个值有256种,在本发明具体实施例中,使用预设的key函数对行数据代表的md5加密获得key值,表比较时将未进行匹配以及匹配失败的数据存到数组中对应的key。,例如如下二维哈希数组:
[0050]
m_hash[当前数据源端还是备端][key值]
[0051]
例如,如果某行数据md5值根据key函数获得的key值是254,则将该数据行的数据存到m_hash[0][254],,若某行数据md5值根据key函数获得的key 值为762,则将该数据行的数据存到m_hash[0][762]。由于key是根据数据行的 md5计算的,所以每次保存的也是随机的,而且有效数据不会是相同的,从而可以均匀的保存数据。
[0052]
也就是说,假设二维哈希数组(2)中0对应源端,1对应备端,源端传送数据与m_hash[1][x]数据比较,匹配失败则记录的数据行数的二维整型数组对应源端的值加1,并将源端未匹配数据存到m_hash[0][x],反之备端传输数据与 m_hash[0][x]比较,匹配失败则记录的数据行数的二维整型数组对应备端的值加 1,并将备端未匹配数据存到m_hash[1][x]。
[0053]
数据缓存单元202,用于当某一批数据比较之后,根据记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数判断是否进行数据缓存操作,于需进行数据缓存操作时,从缓存集合中获取需要缓存的数据以将其保存于文件。
[0054]
具体地,当某一批数据比较之后,将记录的源端和备端未进行匹配以及匹配失败的源端和备端的数据行数相加,如果相加结果大于预设的阈值(此阈值为固定值,例如内存缓存数据的最大行数),则表示需进行缓存操作,需将2维哈希数组(2)中存储的数据进行保存文件,如果未超过预设的阈值,则继续比较处理下一批数据。
[0055]
优选地,在保存缓存数据之前首先将记录的源端数据行数和备端的数据行数进行比较,确定哪端行数更大,以存储行数更大的一端。
[0056]
当匹配失败的数据行过大时,则准备从缓存集合中获取数据存成文件。具体地,首先确定存文件的key(例如使用一个宏定义((idx)&(256
‑
1)),假如此次决定存文件的key为11,那么从m_hash[x][11],m_hash[x][11+256], m_hash[x][11+256*2[,m_hash[x][11+256*3]抓数据进行文件存储,也就是说,需要缓存的数据根据key从缓存集合中每次遍历增加256的方法获取存储数据。
[0057]
文件存储单元203,用于将获取的需要缓存的数据进行文件存储操作,创建存储差异数据的文件,并将数据写入相应的文件,并删除记录的相应行数以及缓存集合中的相应数据。
[0058]
具体地说,在需要存储的数据获取之后开始文件存储操作,存储差异数据的文件
的文件名根据之前确定的key和表的objn创建,例如key为254,则创建文件名为254_123456(假设123456为表objn)的文件,然后将需要存储的数据写入对应目录的文件,并将缓存是否进行了存储的标志,即文件存储标志设置为 true。
[0059]
文件读取比较单元204,用于在源端数据和备端数据都发送结束之后,读取存储差异数据的文件,执行普通的表比较操作。
[0060]
具体地,在源端数据和备端数据都发送结束之后,判断当前文件存储标志是否为true,如果为true,那么将读取文件(即读取时objn_key文件为true时才有读文件操作),因为缓存的数据有部分是因为已经比较之后差异的,但还有一部分是因为与他匹配的数据还没传送来,因此需要在该表数据源端备端都发送来之后再进行比较。
[0061]
具体地,读取文件前,先将现有数据(指内存缓存集合中剩余的从源备端发过来比较之后未匹配的数据)存储到文件,之后读取文件,每次读取一个文件(即 objn_key文件,其存储的是源端和备端的未匹配成功的行数据)的,也就是比较一个key对应的文件中的数据,某一个key对应的文件中的数据比较结束之后再比较下一key对应的文件。因为只是某一个key对应的文件撑满内存的几率也不大。具体地,读取对应key文件的内容,里面存储了源端发送和备端发送的数据,由于存储的数据有类型,因此可以区分源端和备端,然后对其中的数据执行普通的表比较操作。因为是读取的文件操作,不会有数据延迟的问题,在某一个key对应的文件比较时如果其差异数据已经大于预设的阈值,则表示当前比较结果出错,那么则不比较其他key了,避免内存撑满,因为差异数据太多意义也不大,此时表比较结束,需返回重新进行表比较操作。
[0062]
实施例
[0063]
在本发明实施例中,数据库表进行的差异比较操作是在备端的节点程序中进行的,在备端节点程序中进行数据行比较时,备端节点程序中设置一个二维整型数组,该数组用来记录未进行匹配,和匹配失败的源端和备端的数据行数,无论此时传过来的该行是源端数据还是备端数据,如果没有匹配的对应的数据,也就是md5没有相同的,那么该数据对应端的数据行数就会加1。
[0064]
数据库表比较时除了记录源端和备端的行数,源端发送的数据和备端发送的数据也都存储在一个二维哈希数组中。因为行数据md5的每一个值有256种,使用key函数对行数据代表的md5加密获取一个key值,表比较时匹配无效的数据将存到数组中对应的。由于key是根据数据行的md5计算的,所以每次保存的也是随机的,而且有效数据不会是相同的,可以均匀地保存数据
[0065]
当某一批数据比较之后将源端和备端缓存数据行数相加,如果大于某个极限值(此极限值为固定值,是内存缓存数据的最大行数)进行数据缓存操作,如果不大那么继续比较处理一下批数据。
[0066]
保存缓存数据之前首先将缓存的源端数据行数和备端的数据行数进行比较,确定哪端行数更大,存储行数更大的一端。
[0067]
当匹配失败的数据行过大时,则准备从缓存集合中获取数据存成文件。具体地,首先确定一个key,然后对需要缓存的数据根据key从缓存集合中每次遍历增加256的方法获取存储数据。
[0068]
在需要存储的数据获取之后开始文件存储操作,文件名之根据之前获取的 key,
和表的objn创建,然后将缓存写入对应目录的文件。缓存是否进行了存储的标志设置为true。
[0069]
因为数据存储文件时已经从内存中删除了那些行数,如果某时数据再超量继续按照此步骤进行存储。
[0070]
在源端数据和备端数据都发送结束之后,判断当前文件存储标志是否为 true,如果为ture,那么将读取文件。
[0071]
读取文件前,先将现有数据(指内存缓存集合中剩余的从源备端发过来比较之后未匹配的数据)存储到文件,之后读取文件,每次读取一个文件(即objn_key 文件,其存储的是源端和备端的未匹配成功的行数据)的,也就是比较一个key 对应的文件中的数据,某一个key对应的文件中的数据比较结束之后再比较下一key对应的文件。因为只是某一个key对应的文件撑满内存的几率也不大。具体地,读取对应key文件的内容,里面存储了源端发送和备端发送的数据,由于存储的数据有类型,因此可以区分源端和备端,然后对其中的数据执行普通的表比较操作。因为是读取的文件操作,不会有数据延迟的问题,在某一个key 对应的文件比较时如果其差异数据已经大于预设的阈值,则表示当前比较结果出错,那么则不比较其他key了,避免内存撑满,因为差异数据太多意义也不大,此时表比较结束,需返回重新进行表比较操作。
[0072]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1