基于自适应上下文注意力机制的口罩遮挡人脸恢复方法
1.本发明属于计算机视觉技术领域,尤其涉及一种遮挡人脸恢复方法,可用于人脸检测及人脸识别。
背景技术:
2.人脸恢复是计算机视觉中的一项重要任务,其目的是填补被遮挡人脸的缺失区域,在遮挡人脸检测、遮挡人脸识别等方面有着广泛的应用。近年来,大多数基于深度学习的人脸恢复方法取得了显著的成效。这些方法通常使用最新的网络架构如u
‑
net,或者设计新的损失函数如重构损失来恢复被遮挡的面部图像。然而,由于人脸姿态多变、遮挡种类繁多等问题,现有的人脸恢复方法得到的恢复图像质量仍然不尽如人意。
3.在呼吸道类传染病爆发的形势下,越来越多的人在公共场所外出时开始戴口罩,口罩遮挡问题对人脸修复工作提出了新的挑战。不同类型的口罩会对人脸造成严重的遮挡,给与人脸相关的识别工作带来很大的困难。传统的图像恢复方法大多利用生成对抗网络gan恢复被遮挡区域的图像,然而,它们的恢复结果往往带有很多的边界伪影,且生成的图像质量差。为了生成具有视觉真实感的图像,人们提出了基于上下文图像恢复模型的方法,该类方法采用非局部的图像进行恢复,利用图像中无遮挡区域的上下文关系来填充遮挡区域的缺失像素。然而,这些模型只能处理比较规则的遮挡图像如矩形遮挡,圆形遮挡,难以恢复现实中形态各异的口罩遮挡人脸图像。因此,有必要使用能够检测不同类型的口罩分割fcn网络结合自适应上下文注意力机制与全局和口罩遮挡区域判别网络,来准确的恢复被口罩遮挡的人脸图像。
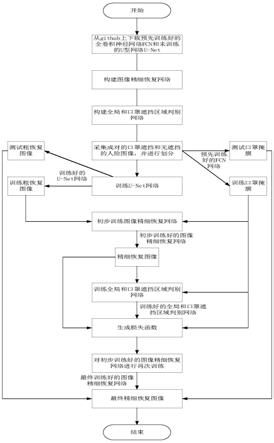
4.浙江大华技术股份有限公司在其申请号为:cn201810608192.2的专利申请中提出“一种基于循环神经网络的人脸图像恢复方法及装置”,以对被遮挡的图像进行恢复,其实现步骤为:1)将待恢复的人脸图像,输入到预先训练完成的图像分割模型中,确定所述人脸图像中被遮挡的第一区域;2)在所述人脸图像中标注步骤1)得到的人脸图像中被遮挡的第一区域,确定第一输入图像;3)将步骤2)得到的第一输入图像,输入到预先训练完成的生成式对抗网络的生成模型中,确定第一输入图像的第一重构图像;4)将步骤2)得到的第一输入图像和步骤3)得到的第一重构图像输入到生成式对抗网络的判别模型中,确定第一重构图像为完整人脸图像的第一概率;5)判断步骤4)得到的第一概率是否超过预设的第一概率阈值:如果是,根据步骤3)得到的第一重构图像,对所述人脸图像进行恢复;如果否,将步骤3)得到的第一重构图像作为第一输入图像,输入到所述生成模型中,直至对所述人脸图像进行恢复。该方法的不足之处有两点:其一是没有利用图像的遮挡区域和无遮挡区域之间的上下文相关信息,会使遮挡区域的恢复图像和图像的无遮挡区域产生色彩、纹理不一致的问题。其二是仅针对小面积遮挡有效,对像口罩这样大面积遮挡的恢复效果很差,恢复区域的图像模糊且存在伪影。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基于自适应上下文注意力机制的口罩遮挡人脸恢复方法,以保持图像恢复区域和无遮挡区域的色彩和纹理一致,减少恢复区域的伪影,提高对口罩遮挡人脸图像的恢复效果。
6.为实现上述目的,本发明的技术方案包括如下:
7.1)从互联网上下载预先训练好分割口罩图像的全卷积神经网络fcn网络和未训练的u型网络u
‑
net;
8.2)构建由两个卷积层和一个反卷积层级联组成的自适应上下文注意力机制模块,并将该自适应上下文注意力机制模块与四层卷积层级联和四层级联的卷积层并联,得到的结果和五层反卷积层级联,组成图像精细恢复网络;
9.3)构建由两个依次连接的六个卷积层和两个全连接层级联组成的全局和口罩遮挡区域判别网络;
10.4)采集成对的口罩遮挡和无遮挡的人脸图像,并将这两部分图像分别放置于无遮挡图像文件夹w1和有口罩遮挡图像文件夹w2,按照1:1的近似比将无遮挡图像文件夹w1和有口罩遮挡图像文件夹w2中的图片对划分为训练集和测试集;
11.5)将有口罩遮挡图像文件夹w2中的训练集和测试集图像输入到预先训练好的fcn网络中,分别得到训练口罩掩膜和测试口罩掩膜;
12.6)将有口罩遮挡图像文件夹w2中的训练集图像输入u型网络u
‑
net中,利用随机梯度下降的方式对其进行训练,得到训练好的u型网络u
‑
net模型;
13.7)将有口罩遮挡图像文件夹w2中的训练集和测试集图像输入到训练好的u型网络u
‑
net中,分别得到训练粗恢复图像和测试粗恢复图像;
14.8)将训练粗恢复图像和训练口罩掩膜输入图像精细恢复网络中,利用随机梯度下降的方式对图像精细恢复网络进行训练,得到初步训练好的图像精细恢复网络;
15.9)将训练粗恢复图像和训练口罩掩膜输入到初步训练好的图像精细恢复网络中,得到精细恢复图像;
16.10)将精细恢复图像、训练口罩掩膜和无遮挡图像文件夹w1中与精细恢复图像对应的训练集图像输入到全局和口罩遮挡区域判别网络中,利用随机梯度下降的方式对其进行训练,得到训练好的全局和口罩遮挡区域判别网络;
17.11)将精细恢复图像和训练口罩掩膜输入到训练好的全局和口罩遮挡区域判别网络中,利用得到的判别值对初步训练好的图像精细恢复网络进行再一次训练,得到最终训练好的图像精细恢复网络;
18.12)将测试粗恢复图像和测试口罩掩膜输入到最终训练好的图像精细恢复网络中,得到最终精细恢复图像。
19.本发明与现有技术相比,具有以下优点:
20.1.本发明通过对口罩遮挡区域和无遮挡区域的注意力图进行自适应的更新,保持了图像恢复区域和无遮挡区域的色彩和纹理的一致性,提高了恢复图像的质量和真实性,使恢复的图像在视觉上更加接近自然界中采集的真实无遮挡图像;
21.2.本发明通过使用全局和口罩遮挡区域判别网络的判别功能,使恢复的图像更加清晰且具有更少的伪影干扰,提高了恢复图像的细节性;
22.3.本发明所提出的基于自适应上下文注意力机制的口罩遮挡人脸图像恢复模型结构简单且运行速度快,可满足在真实场景中实时使用的要求。
附图说明
23.图1是本发明的实现流程图;
24.图2是本发明中的图像精细恢复网络模型图;
25.图3是本发明中的全局和口罩遮挡区域判别网络模型图;
26.图4是用本发明对所采集的口罩遮挡人脸图像进行恢复的仿真结果图。
具体实施方式
27.以下结合附图对本发明的实施例和效果作进一步的详细说明。
28.参照图1,本实例的实现步骤如下:
29.步骤1:获取全卷积神经网络fcn和u型网络u
‑
net。
30.现有github代码库存有预先训练好分割口罩图像的全卷积神经网络fcn网络和u型网络u
‑
net,可直接从github代码库里下载预先训练好分割口罩图像的全卷积神经网络fcn网络和未训练的u型网络u
‑
net并保存下来。
31.步骤2:构建图像精细恢复网络。
32.参照图2,图像精细恢复网络的结构如下:
33.2.1)构建自适应上下文注意力机制模块:
34.将两个卷积层conv1和conv2和一个反卷积层dconv1级联构成自适应上下文注意力机制模块,其中:
35.卷积层conv1和conv2的大小均为3
×
3、步长为1、激活函数为relu,卷积层conv1和conv2用于对获取的图像注意力图attention
map1
的数值进行更新,
36.反卷积层dconv1的大小为4
×4×
96,步长为1、激活函数为relu,
37.relu函数的表达式为:x表示输入,f(x)表示输出。
38.在本实例中将训练口罩掩膜进行维度变换,得到大小为1
×
64
×
64
×
96的图像mask
r
,将mask
r
与输入特征c相乘,得到前景区域f
f
=mask
r
×
c和背景区域f
b
=(1
‑
mask
r
)
×
c,计算大小为1
×1×
96的前景区域像素块和大小为1
×1×
96的背景区域像素块的余弦相似度,选出与前景区域像素块相似度最大的背景区域像素块b
max
,将b
max
乘上余弦相似度取值后,与该前景区域像素块进行加和,余弦相似度的计算公式为:
39.其中a
i
和b
i
分别代表前景区域像素和背景区域第i个像素块的值,n表示一个前景像素块中的像素个数,similarity表示求得的相似度取值;
40.对前景区域所有像素块按此方式进行处理,得到前景区域f
f
和背景区域f
b
的注意力图attention
map1
;
41.在本实例中利用大小为4
×
4的滑动窗口依次经过数值更新后的图像注意力图attention
map1
的各个位置,得到256个4
×4×
96的反卷积核w
d
,将w
d
作为反卷积层dconv1的卷积核,对输入特征c进行反卷积的操作,得到大小为1
×
64
×
64
×
96的上下文特征f
ca
;
42.2.2)构建三条支路:
43.第一支路:由第1卷积层
‑
>第2卷积层
‑
>第3卷积层
‑
>第4卷积层
‑
>自适应上下文注意力机制模块级联组成,
44.第二支路:由第5卷积层
‑
>第6卷积层
‑
>第7卷积层
‑
>第8卷积层依次级联组成,
45.第三支路:由第1反卷积层
‑
>第2反卷积层
‑
>第3反卷积层
‑
>第4反卷积层
‑
>第5反卷积层级联组成;
46.2.3)将第一支路与第二支路并联,再与第三支路级联,组成图像精细恢复网络,该网络中除自适应上下文注意力机制模块外,每个卷积层和反卷积层的卷积核大小均为3
×
3。
47.步骤3:构建全局和口罩遮挡区域判别网络。
48.如图3所示,全局和口罩遮挡区域判别网络的结构为:第一卷积层
‑
>第二卷积层
‑
>第三卷积层
‑
>第四卷积层
‑
>第五卷积层
‑
>第六卷积层
‑
>第一全连接层
‑
>第二全连接层
‑
>sigmoid函数,其中:
49.每个卷积层的卷积核大小均为3
×
3,步长为2;
50.第一全连接层的大小为1
×
512;
51.第二全连接层的大小为1
×
1;
52.sigmoid函数的表达式为:x表示输入,s(x)表示输出。
53.步骤4:采集成对的口罩遮挡和无遮挡的人脸图像,并对其进行处理和划分。
54.4.1)使用相机采集数千对口罩遮挡和无遮挡人脸图像图片对,并将这两部分图像分别放置于无遮挡图像文件夹w1和有口罩遮挡图像文件夹w2中;
55.4.2)将无遮挡图像文件夹w1和有口罩遮挡图像文件夹w2中所有图像进行维度变换,将其变换成大小为256
×
256
×
3的图像;
56.4.3)将无遮挡图像文件夹w1和有口罩遮挡图像文件夹w2中经过维度变换后的图像对按照1:1的比例进行划分,得到训练集图像和测试集图像,
57.本实例采集了5000对图像,经过处理和划分后得到2500对训练集图像和2500对测试集图像。
58.步骤5:将图像输入预先训练好的fcn网络中,得到训练口罩掩膜和测试口罩掩膜。
59.将有口罩遮挡图像文件夹w2中的训练集图像输入到预先训练好的fcn网络中,得到大小为256
×
256
×
1的训练口罩掩膜;
60.将有口罩遮挡图像文件夹w2中的测试集图像输入到预先训练好的fcn网络中,得到大小为256
×
256
×
1的测试口罩掩膜;
61.训练口罩掩膜和测试口罩掩膜在口罩遮挡区域的像素值取值为1,无口罩遮挡区域的像素值取值为0。
62.步骤6:用梯度下降法训练u型网络u
‑
net。
63.6.1)设置训练的学习率为0.001,最大迭代次数为1000,选择梯度下降法中的随机
梯度下降算法sgd,并将sgd中的动能系数设置为0.8,权重衰减系数设置为0.0001;
64.6.2)将有口罩遮挡图像文件夹w2中的训练集图像按每批次4张输入到u型网络u
‑
net中,生成粗图像;
65.6.3)计算粗图像和无遮挡图像文件夹w1中与粗图像对应的训练集图像的重构损失函数l
rec1
:
[0066][0067]
其中,i表示像素的索引,n0表示一张粗图像的像素总数,表示粗图像中第i个像素点的取值,表示无遮挡图像文件夹w1中与粗图像对应的训练集图像的第i个像素点的取值,|
·
|表示取绝对值的操作;
[0068]
6.4)重复6.2)~6.3),迭代优化重构损失函数l
rec1
,直到达到最大迭代次数或重构损失函数l
rec1
的数值小于0.8时,得到训练好的u型网络u
‑
net网络模型,保存训练好的u
‑
net模型。
[0069]
步骤7:将有口罩遮挡图像文件夹w2中的训练集和测试集图像输入到步骤6得到的训练好的u型网络u
‑
net中,分别得到训练粗恢复图像和测试粗恢复图像。
[0070]
步骤8:用梯度下降法训练步骤2中的图像精细恢复网络。
[0071]
8.1)设置训练的学习率为0.000015,最大迭代次数为30000,选择梯度下降法中的随机梯度下降算法sgd,将sgd中的动能系数设置为0.95,权重衰减系数设置为0.0005;
[0072]
8.2)将训练粗恢复图像与训练口罩掩膜相乘输入图像精细恢复网络的第一支路得到上下文特征f
ca
,将训练粗恢复图像输入图像精细恢复网络的第二支路得到第二支路特征c8;
[0073]
8.3)将第二支路特征c8和上下文特征f
ca
进行合并拼接,得到合并拼接后的特征c
n
;
[0074]
8.4)将合并拼接后的特征c
n
输入第三支路,得到细图像;
[0075]
8.5)计算细图像与无遮挡图像文件夹w1中与细图像对应的训练集图像的l2损失函数l
rec2
:
[0076][0077]
其中,i表示像素的索引,n表示一张细图像的像素总数,表示细图像的第i个像素点的取值,表示无遮挡图像文件夹w1中与细图像对应的训练集图像的第i个像素点的取值,(
·
)2表示取平方的操作;
[0078]
8.6)重复8.2)~8.5),迭代优化损失函数,直到达到最大迭代次数或l2损失函数l
rec2
的数值小于0.3时,得到初步训练好的图像精细恢复网络,保存初步训练好的图像精细恢复网络;
[0079]
步骤9:将训练粗恢复图像和训练口罩掩膜输入到步骤8得到的初步训练好的图像精细恢复网络中,得到精细恢复图像;
[0080]
步骤10:用梯度下降法训练步骤3中的全局和口罩遮挡区域判别网络。
[0081]
10.1)设置训练的学习率为0.000015,最大迭代次数为3000,选择梯度下降法中的随机梯度下降算法sgd,将sgd中的动能系数设置为0.9,权重衰减系数设置为0.0005;
[0082]
10.2)将精细恢复图像输入到全局和口罩遮挡区域判别网络中,得到精细恢复图像的判别值g
id
,将无遮挡图像文件夹w1中与精细恢复图像对应的训练集图像输入到全局和口罩遮挡区域判别网络中,得到其判别值g
sd
;
[0083]
10.3)将精细恢复图像与训练口罩掩膜相乘并输入到全局和口罩遮挡区域判别网络中,得到精细恢复图像口罩遮挡区域的判别值g
id
‑
mask
,将无遮挡图像文件夹w1中与精细恢复图像对应的训练集图像与训练口罩掩膜相乘并输入到全局和口罩遮挡区域判别网络中,得到其判别值g
sd
‑
mask
;
[0084]
10.4)计算精细恢复图像与无遮挡图像文件夹w1中与精细恢复图像对应的训练集图像的判别损失函数l
d
:
[0085][0086]
10.5)重复10.2)~10.4),迭代优化损失函数,直到达到最大迭代次数或判别损失函数l
d
小于0.2时,得到训练好的全局和口罩遮挡区域判别网络,保存训练好的全局和口罩遮挡区域判别网络。
[0087]
步骤11:用梯度下降法对步骤8中初步训练好的图像精细恢复网络进行再一次训练。
[0088]
11.1)设置训练的学习率为0.000015,最大迭代次数为50000,选择梯度下降法中的随机梯度下降算法sgd,将sgd中的动能系数设置为0.9,权重衰减系数设置为0.0001;
[0089]
11.2)将精细恢复图像输入到训练好的全局和口罩遮挡区域判别网络中,得到精细恢复图像的判别值g
ri
,将精细恢复图像与训练口罩掩膜相乘并输入到训练好的全局和口罩遮挡区域判别网络中,得到精细恢复图像口罩遮挡区域的判别值g
ri
‑
mask
;
[0090]
11.3)计算精细恢复图像的生成损失函数l
g
:
[0091][0092]
11.4)使用精细恢复图像的生成损失函数l
g
和反向传播算法对初步训练好的图像精细恢复网络中所有卷积核的参数进行更新;
[0093]
11.5)重复11.2)~11.4),迭代优化损失函数,直到达到最大迭代次数或生成损失函数小于0.1时,得到最终训练好的图像精细恢复网络,保存最终训练好的图像精细恢复网络;
[0094]
步骤12:将测试粗恢复图像和测试口罩掩膜输入到步骤11得到的最终训练好的图像精细恢复网络中,得到最终精细恢复图像。
[0095]
本发明的效果可通过以下仿真进一步说明:
[0096]
一、仿真条件
[0097]
以步骤4获得的测试集的部分图片作为仿真图片进行仿真验证,仿真基于python、tensorflow
‑
gpu 1.13软件进行。
[0098]
二、仿真内容与结果
[0099]
将仿真图片分别输入到现有的patchmatch模型和现有训练好的pix2pix模型,将
仿真图片输入到本发明训练好的基于自适应上下文注意力机制的口罩遮挡人脸图像恢复模型,得到恢复结果如图4,其中:
[0100]
图4(a)为仿真图片;
[0101]
图4(b)为真值图片;
[0102]
图4(c)为用现有patchmatch模型的恢复的结果;
[0103]
图4(d)为用现有pix2pix模型的恢复的结果;
[0104]
图4(e)为用本发明基于自适应上下文注意力机制的口罩遮挡人脸图像恢复模型的恢复结果。
[0105]
从图4可以看出,本发明基于自适应上下文注意力机制的口罩遮挡人脸恢复方法的恢复结果与真值图像接近,且相较于现有patchmatch模型和现有pix2pix模型,本发明可改善现有技术生成图像模糊,存在伪影且遮挡区域和无遮挡区域色彩纹理不一致的问题,表明本实例有着较好的恢复效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1