一种利用语音信息的实时视频人脸区域时空一致合成方法
1.本发明涉及深度学习和三维人脸重建、人脸合成等技术领域,尤其是涉及一种利用语音信息的实时视频人脸区域时空一致合成方法。
背景技术:
2.传统的人脸区域生成算法局限于单张人脸图像,存在以下问题:(1)输入信息单一,无法确定图像中被人脸区域的表情,也无法合成与语音相一致的人脸视频。(2)缺乏身份信息约束,无法保证对同一个人在不同姿态表情下合成人脸区域后还像同一个人,应用于视频上会出现前后身份形象不一致的问题。(3)缺乏时序信息间的关联与约束,应用于视频上会出现时序抖动的现象。(4)所需网络结构复杂,计算资源消耗巨大,推理时间过长,无法满足实时需求。传统算法缺少时序上的上下文约束信息,用于视频容易出现纹理抖动现象,效果较差。最后,传统算法所需的神经网络架构较复杂,推理时间成本较高,无法满足实时需求。
技术实现要素:
3.本发明的目的在于针对现有技术存在的上述问题,提供一种利用语音信息的实时视频人脸区域时空一致合成方法。利用三维人脸重建算法从视觉特征提取人脸身份信息、人脸形状信息、人脸姿态信息和人脸纹理信息,并利用深度学习技术从音频特征提取人脸表情信息,融合前者的视觉信息和后者的听觉信息,能够增强神经网络合成人脸表情的丰富性,使其快速准确地合成与当前说话内容相一致的人脸说话视频。
4.本发明包括以下步骤:
5.s1:人工选取人脸身份参考图像,提取其人脸身份参数、人脸纹理参数;
6.s2:对于实时视频流的每一帧图像,使用人脸三维重建技术提取每帧对应的人脸姿态参数、人脸形状参数;
7.s3:对于实时音频流提取每帧视频对应的音频特征,对第一网络输入音频特征,输出视频流每帧对应的人脸表情参数;
8.s4:输入人脸身份参数、人脸姿态参数、人脸形状参数、人脸纹理参数、人脸表情参数,使用三维人脸模型渲染技术渲染出对应的三维人脸模型渲染图像。
9.s5:对第二网络输入视频流原图帧、三维人脸渲染图像、人脸身份参考图像以及第二网络上一帧合成图像,输出人脸区域合成后的图像。
10.在步骤s1中,所述人脸三维重建技术为人脸3d形变统计模型(3dmm)方法。
11.在步骤s2中,所述第一网络为人脸表情估计网络;所述人脸表情估计网络分为音频特征提取模块和人脸表情参数回归模块。
12.在步骤s3中,所述三维人脸模型渲染技术受语音驱动。
13.在步骤s5中,所述第二网络为人脸纹理合成网络,且为生成对抗网络;所述人脸纹理合成网络包括人脸身份编码模块、人脸身份编码投影模块、人脸纹理合成模块、判别器模
块;
14.所述人脸纹理合成网络所使用约束包括时序一致性约束、判别器约束、人脸身份一致性约束。
15.所述人脸身份一致性约束用于保证前后生成的人脸身份形象一致,具体地,将人脸身份编码使用自适应实例标准化引入人脸纹理合成模块,并对合成结果进行约束。
16.所述时序一致性约束用于保证前后生成的人脸纹理变化自然,具体地,将上一帧的合成结果引入人脸纹理合成模块,并对前后帧纹理抖动进行约束。
17.本发明融合属于视觉信息的人脸形状姿态等信息和属于听觉信息的音频特征信息等多模态的信息,从而实现信息互补,使得算法可以合成表情神态丰富,与说话内容相一致的人脸视频。在身份形象一致性方面,本发明引入参考人脸身份参数,可以约束输出前后视频帧身份形象一致。同时本发明引入时序上的上下文信息和平滑约束,有效抑制纹理抖动的出现,使得人脸生成算法能够适用于视频。最后本发明采用更为精简的神经网络结构,使得该算法可以实时生成人脸说话视频或去掉人脸遮挡物,可以用于视频会议中去除人脸遮挡物、合成虚拟人主播视频等场景,在安防监控、视频会议、虚拟形象、动画驱动等领域有着极高的实用价值和良好的经济效益。
附图说明
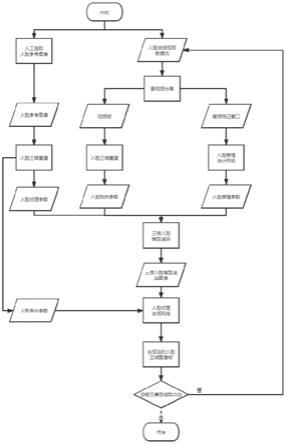
18.图1为本发明实施例的整体流程图。
19.图2为本发明实施例的三维人脸模型渲染过程图。
20.图3为本发明实施例的人脸遮档去除过程图。
具体实施方式
21.以下实施例将结合附图对本发明作进一步的说明。
22.实施例
23.参考图1~3,本实施例提出一种利用语音信息的实时视频人脸区域时空一致合成方法,包括以下步骤:
24.s1:人工选取人脸身份参考图像,使用人脸三维重建技术提取其人脸身份参数、人脸纹理参数;
25.s2:输入一段人脸说话视频数据流并进行音视频分离,对于实时视频流的每一帧图像,使用人脸三维重建技术提取每帧对应的人脸相关参数,所述人脸相关参数包括人脸姿态参数、人脸形状参数;
26.s3:对于实时音频流提取每帧视频对应的音频特征,对第一网络输入音频特征,输出视频流每帧对应的人脸表情参数;
27.s4:输入人脸身份参数、人脸纹理参数、人脸姿态参数、人脸形状参数、人脸表情参数,使用三维人脸模型渲染技术渲染出对应的三维人脸模型渲染图像;
28.s5:对第二网络输入视频流原图帧、三维人脸渲染图像、人脸身份参考图像以及第二网络上一帧合成图像,输出人脸区域合成后的图像;
29.s6:检查视频流是否读取完毕,若否,则返回s1,若是,则完成实时视频人脸区域时空一致合成。
30.本发明输入为一段人脸说话视频流,输出为实时的人脸区域合成视频流,可以用于人脸区域遮挡去除等场景,以下实施例以人脸区域去除遮挡为例,但本发明可应用场景并不局限于此。
31.本实施例包括2个关键部分:(1)语音驱动的三维人脸模型渲染算法,包括步骤s1~s4;(2)人脸区域合成算法,包括步骤s5。其中,语音驱动的三维人脸模型渲染算法使用语音进行约束生成渲染图像,用于为人脸区域合成提供三维模型形状及纹理等先验信息。人脸区域合成使用对抗网络技术实时生成时序上纹理变化平滑的去遮挡后的人脸纹理。
32.1)语音驱动的三维人脸模型渲染算法
33.为了生成由语音驱动的人脸说话视频,使得合成的视频中人脸嘴型、表情等与语音内容相一致,采用语音驱动的三维人脸模型渲染图像作为先验信息指导人脸区域图像的生成。其中,语音信号用来约束人脸模型表情参数的变化,其他纹理参数、形变参数等与原人脸区域图像帧保持一致;此算法的过程包括上述步骤s1~s4,其中,步骤s2过程图参考图2,步骤s2关键部分为人脸表情估计网络,所述人脸表情估计网络分为音频特征提取模块和人脸表情参数回归模块,具体步骤如下:
34.(1)对当前实时音频流提取音频特征,本实施例采用梅尔倒谱系数。
35.(2)对当前音频特征序列进行分帧加窗。
36.(3)对音频特征提取模块输入每个窗口的音频特征,输出更深层次的音频特征。
37.(4)对人脸表情参数回归模块输入步骤(3)得到的更深层次的音频特征,输出人脸表情参数。
38.(5)依时序循环步骤(1)~(4),输出每个视频帧对应的人脸表情参数,直至运行到输出序列的最后一帧。
39.2)人脸区域合成算法:
40.人脸区域合成为实际合成与语音内容一致的人脸说话视频的过程,包括步骤s5(本实施例的人脸遮档去除过程图参考图3)。本实施例采用对抗网络技术实现人脸纹理合成网络,神经网络模块包括人脸纹理合成模块和判别器模块,具有2个关键约束:人脸身份一致性约束和时序一致性约束。
41.所述人脸身份一致性约束用于确保合成视频人脸前后身份特征一致,约束合成视频人脸前后身份特征保持不变。本实施例采用自适应实例标准化将身份信息编码入神经网络生成器中,从而使得神经网络能够基于身份信息编码合成前后身份特征一致的视频帧序列;主要分为人脸身份编码提取模块和人脸身份编码投影模块、人脸身份验证模块;所述人脸身份一致性约束的实施过程(参考图3)如下:
42.(1)、人脸身份编码提取模块三维人脸重建技术提取目标说话人的人脸身份编码。本实施例采用人脸3d形变统计模型作为身份编码提取模块。
43.(2)、对人脸身份编码投影模块输入步骤1得到的人脸身份编码,输出投影后的人脸身份特征。
44.(3)、使用自适应实例标准化将步骤2得到的人脸身份特征编码入生成器,并输入原图像、3d人脸模型渲染图像,输出去遮挡后的人脸图像。
45.(4)、使用人脸身份验证模块计算原图像与合成图像的身份特征差异,作为指导用于优化生成器。本实施实例采用人脸识别模型。
46.(5)、循环步骤(1)~(4),直至生成器收敛。
47.所述时序一致性约束用于确保合成视频人脸前后纹理变化相对平滑,变化自然,防止抖动现象的发生;本实施例采取向网络引入上一帧生成的图像作为先验信息,使得网络合成纹理变化自然的人脸说话视频;具体实施过程如下:(参考图3)
48.(1)、在生成器的输入过程中,在以上基础上增加上一帧合成的人脸区域视频帧,输出当前帧对应的人脸视频帧;
49.(2)、计算前后帧生成器合成的人脸区域纹理变化抖动程度,作为指导用于优化生成器;本实施例采用像素间的颜色差异变化速率进行衡量;
50.(3)、循环步骤(1)、(2)直至生成器收敛。
51.本实施例中,人脸身份一致性约束和时序一致性约束应和判别器判别损失约束组合使用共同用于优化生成器。本实施例人脸表情估计网络和人脸纹理合成网络分别采用简单的卷积网络架构和层数较少的生成对抗网络,所需的计算量较小,可满足实时人脸区域合成的需求,在安防监控、视频会议、虚拟形象、动画驱动等领域有着极高的实用价值和良好的经济效益。
52.以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1