视觉问答模型训练、视觉问答方法和装置与流程
1.本技术涉及人工智能技术领域,特别是涉及一种视觉问答模型训练、视觉问答方法、装置、计算机设备和存储介质。
背景技术:
2.视觉问答(visual question answer,vqa)即针对给定的图片及其相关的用自然语言描述的问题,生成问题的答案。
3.目前的视觉问答是通过视觉问答模型对图片和问题进行识别来实现的。在构建视觉问答模型时,通常基于神经网络从若干个训练样本中提取图片特征和问题特征,并将图片特征和问题特征进行融合,针对融合后的特征进行训练。当进行视觉问答时,将图片和问题输入训练好的视觉问答模型,通过视觉问答模型从若干候选答案中筛选出正确答案。
4.然而,上述视觉问答模型通常只能处理语言描述清楚的问题,对于一些诸如“上述问题如何解决”的模糊问题,生成的答案准确率较低。
5.因此,目前的视觉问答模型存在生成的答案准确率较低的问题。
技术实现要素:
6.基于此,有必要针对上述技术问题,提供一种能够提高答案准确率的视觉问答模型训练、视觉问答方法、装置、计算机设备和存储介质。
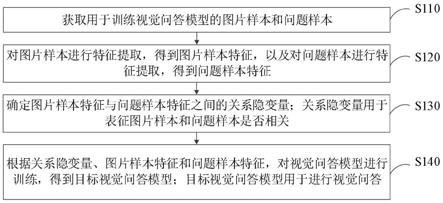
7.一种视觉问答模型训练方法,所述方法包括:
8.获取用于训练视觉问答模型的图片样本和问题样本;
9.对所述图片样本进行特征提取,得到图片样本特征,以及对所述问题样本进行特征提取,得到问题样本特征;
10.确定所述图片样本特征与所述问题样本特征之间的关系隐变量;所述关系隐变量用于表征所述图片样本和所述问题样本是否相关;
11.根据所述关系隐变量、所述图片样本特征和所述问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型;所述目标视觉问答模型用于进行视觉问答。
12.在其中一个实施例中,所述确定所述图片样本特征与所述问题样本特征之间的关系隐变量,包括:
13.根据所述图片样本特征生成图片样本节点,以及根据所述问题样本特征生成问题样本节点;
14.根据所述图片样本节点和所述问题样本节点生成关系图;所述关系图包括多个节点和多条节点关系边;所述节点包括所述图片样本节点和所述问题样本节点;所述节点关系边用于记录所述节点之间的关系;
15.将所述关系图输入至注意力引导图卷积网络模型,得到关系矩阵;
16.根据所述关系矩阵,得到所述图片样本特征和所述问题样本特征之间的关系隐变量。
17.在其中一个实施例中,所述根据所述关系矩阵,得到所述图片样本特征和所述问题样本特征之间的关系隐变量,包括:
18.根据所述关系矩阵,得到所述问题样本对于所述图片样本的第一权重和所述图片样本对于所述问题样本的第二权重;所述第一权重用于表征所述问题样本对于所述图片样本的注意力程度,所述第二权重用于表征所述图片样本对于所述问题样本的注意力程度;
19.根据所述第一权重更新所述图片样本特征,得到更新后图片样本特征,以及根据所述第二权重更新所述问题样本特征,得到更新后问题样本特征;
20.对所述更新后图片样本特征和所述更新后问题样本特征进行拼接,得到第一拼接向量;
21.对所述第一拼接向量进行二分类,得到所述关系隐变量。
22.在其中一个实施例中,所述根据所述关系隐变量、所述图片样本特征和所述问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型,包括:
23.对所述关系隐变量、所述更新后图片样本特征和所述更新后问题样本特征进行拼接,得到第二拼接向量;
24.基于所述第二拼接向量对视觉问答模型进行训练,得到所述目标视觉问答模型。
25.在其中一个实施例中,所述基于所述第二拼接向量对视觉问答模型进行训练,得到所述目标视觉问答模型,包括:
26.将所述第二拼接向量输入至所述视觉问答模型,得到预测答案;
27.根据所述预测答案、所述图片样本和所述问题样本,得到所述视觉问答模型的第一损失值;
28.根据所述预测答案和预设的样本标签,得到所述视觉问答模型的第二损失值;
29.通过对所述第一损失值和所述第二损失值求和,得到视觉问答损失值;
30.若所述视觉问答损失值不超过预设阈值,则根据所述视觉问答模型得到所述目标视觉问答模型。
31.在其中一个实施例中,所述对所述图片样本进行特征提取,得到图片样本特征,包括:
32.将所述图片样本输入至区域卷积神经网络模型,得到至少一个图片样本特征;每一个所述图片样本特征对应于所述图片样本上的一个区域。
33.在其中一个实施例中,所述对所述问题样本进行特征提取,得到问题样本特征,包括:
34.将所述问题样本输入至基于转换器的双向编码表征模型,得到所述问题样本特征。
35.一种视觉问答方法,所述方法包括:
36.获取待识别图片和待回答问题;
37.对所述待识别图片进行特征提取,得到待识别图片特征,以及对所述待回答问题进行特征提取,得到待回答问题特征;
38.确定所述待识别图片特征与所述待回答问题特征之间的关系隐变量;
39.将所述关系隐变量、所述待识别图片特征和所述待回答问题特征输入至目标视觉问答模型,得到问题的答案。
40.一种视觉问答模型训练装置,所述装置包括:
41.样本获取模块,用于获取用于训练视觉问答模型的图片样本和问题样本;
42.样本特征提取模块,用于对所述图片样本进行特征提取,得到图片样本特征,以及对所述问题样本进行特征提取,得到问题样本特征;
43.样本隐变量确定模块,用于确定所述图片样本特征与所述问题样本特征之间的关系隐变量;
44.模型训练模块,用于根据所述关系隐变量、所述图片样本特征和所述问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型;所述目标视觉问答模型用于进行视觉问答。
45.一种视觉问答装置,所述装置包括:
46.获取模块,用于获取待识别图片和待回答问题;
47.特征提取模块,用于对所述待识别图片进行特征提取,得到待识别图片特征,以及对所述待回答问题进行特征提取,得到待回答问题特征;
48.隐变量确定模块,用于确定所述待识别图片特征与所述待回答问题特征之间的关系隐变量;
49.识别模块,用于将所述关系隐变量、所述待识别图片特征和所述待回答问题特征输入至目标视觉问答模型,得到问题的答案。
50.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
51.获取用于训练视觉问答模型的图片样本和问题样本;
52.对所述图片样本进行特征提取,得到图片样本特征,以及对所述问题样本进行特征提取,得到问题样本特征;
53.确定所述图片样本特征与所述问题样本特征之间的关系隐变量;所述关系隐变量用于表征所述图片样本和所述问题样本是否相关;
54.根据所述关系隐变量、所述图片样本特征和所述问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型;所述目标视觉问答模型用于进行视觉问答。
55.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
56.获取用于训练视觉问答模型的图片样本和问题样本;
57.对所述图片样本进行特征提取,得到图片样本特征,以及对所述问题样本进行特征提取,得到问题样本特征;
58.确定所述图片样本特征与所述问题样本特征之间的关系隐变量;所述关系隐变量用于表征所述图片样本和所述问题样本是否相关;
59.根据所述关系隐变量、所述图片样本特征和所述问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型;所述目标视觉问答模型用于进行视觉问答。
60.上述视觉问答模型训练、视觉问答方法、装置、计算机设备和存储介质,通过获取用于训练视觉问答模型的图片样本和问题样本,对图片样本进行特征提取得到图片样本特征,对问题样本进行特征提取得到问题样本特征,可以分别用图片样本特征和问题样本特征来描述图片样本和问题样本,确定图片样本特征与问题样本特征之间的关系隐变量,可
以用关系隐变量来表征图片样本和问题样本是否相关,根据关系隐变量、图片样本特征和问题样本特征对视觉问答模型进行训练,得到目标视觉问答模型,由于在模型训练过程中除了考虑图片特征和问题特征对模型训练的影响,还考虑到了关系隐变量对模型训练的影响,即图片和问题是否相关对模型训练的影响,能够在回答模糊问题时仍然给出准确率较高的答案。
附图说明
61.图1为一个实施例中视觉问答模型训练方法的流程示意图;
62.图2为一个实施例中图片特征提取的示意图;
63.图3为一个实施例中问题特征提取的示意图;
64.图4为一个实施例中注意力引导图卷积网络的示意图;
65.图5为一个实施例中注意力引导图卷积网络密集连接层的示意图;
66.图6为一个实施例中利用关系隐变量进行模型训练的示意图;
67.图7为一个实施例中视觉问答方法的流程示意图;
68.图8为一个实施例中视觉问答模型训练装置的结构框图;
69.图9为一个实施例中视觉问答装置的结构框图;
70.图10为一个实施例中计算机设备的内部结构图。
具体实施方式
71.为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
72.本技术提供的视觉问答模型训练方法和视觉问答方法,可以应用于终端或服务器。其中,终端可以但不限于是各种个人计算机、笔记本电脑、智能手机、平板电脑和便携式可穿戴设备,服务器可以用独立的服务器或者是多个服务器组成的服务器集群来实现。
73.在一个实施例中,如图1所示,提供了一种视觉问答模型训练方法,以该方法应用于终端为例进行说明,包括以下步骤:
74.步骤s110,获取用于训练视觉问答模型的图片样本和问题样本。
75.具体实现中,可以向终端输入多幅图片,作为图片样本,并相应地为每幅图片配置用自然语言描述的问题,作为问题样本,图片样本和问题样本可以用于进行视觉问答模型训练,其中,可以选取最常见的问题作为问题样本,并将相应的回答作为样本标签。还可以收集客户在遇到问题时所输入的截图及相应的问题描述,作为图片样本和问题样本。
76.步骤s120,对图片样本进行特征提取,得到图片样本特征,以及对问题样本进行特征提取,得到问题样本特征。
77.具体实现中,可以通过将每一个图片样本输入至区域卷积神经网络(region convolutional neural networks,rcnn)来进行图片样本的特征提取,区域卷积神经网络输出图片样本特征,还可以通过将每一个问题样本输入至基于转换器的双向编码表征(bidirectional encoder representations from transformers,bert)模型来进行问题样本的特征提取,基于转换器的双向编码表征模型输出问题样本特征。
78.图2提供了一个图片特征提取的示意图,根据图2,可以将一个图片样本输入至rcnn,经过rcnn的深度残差网络和区域生成网络(region proposal network,rpn)进行处理,输出图片样本不同区域的特征信息。
79.其中,每一个区域对应一个特征图(feature map),每一个特征图可以作为一个图片样本特征。
80.其中,rcnn可以为fast rcnn(快速的区域卷积神经网络)或faster rcnn(更快速的区域卷积神经网络),深度残差网络可以为resnet
‑
50、resnet
‑
101或resnet
‑
152。
81.例如,可以将图片样本输入至faster
‑
rcnn,经过faster
‑
rcnn的resnet
‑
101和rpn进行处理,输出不同候选区域的特征信息,每一个候选区域对应一个特征图,其中,rpn可以生成若干区域,可以从若干区域中选择部分区域作为候选区域,例如,可以根据区域包含目标的概率大小,来选择候选区域。
82.图3提供了一个问题特征提取的示意图,根据图3,可以将问题样本输入至bert模型,对问题样本进行编码,经过多个转换器层层进行特征处理,输出问题样本对应的特征信息,作为问题样本特征。
83.步骤s130,确定图片样本特征与问题样本特征之间的关系隐变量;关系隐变量用于表征图片样本和问题样本是否相关。
84.具体实现中,图片样本特征和问题样本特征可以为相同维度的向量,图片样本特征作为图片样本节点,问题样本特征可作为问题样本节点,然后在图片样本节点和问题样本节点间设置初始的连接边,以代表节点间的关系,将由图片样本节点和问题样本节点及其连接边构成的图作为节点关系图,并将该节点关系图输入至注意力引导图卷积网络(attention guided graph convolutional networks,aggcn),得到注意力矩阵,注意力矩阵中的各个元素可以用于表征问题对图片、或图片对问题的注意力程度。
85.具体的,用表示一图像样本的第i(i=1,
……
,i)个图片样本特征,i为一图像样本包含的特征图总数,用h
q
表示问题样本特征,可以根据下式更新图片样本特征和问题样本特征:
[0086][0087]
其中,h
v
′
为更新后的图片样本特征,α
i
为问题特征对第i个特征图的注意力程度,h
q
′
为更新后的问题样本特征,α
j
为图片对问题特征的注意力程度。由注意力矩阵a可以得到a=[α1ꢀ…ꢀ
α
k
‑1],其中,α1为问题特征对第1个特征图的注意力程度,α
k
为问题特征对第k个特征图的注意力程度,且α
j
=∑α
i
。
[0088]
针对每一图片样本,在得到更新后的图片样本特征和更新后的问题样本特征后,可以对二者进行拼接,得到联合表达为:
[0089]
h
conv
=[h
q
′
;h
v
′
]。
[0090]
将h
conv
输入二分类函数可得到关系隐变量,关系隐变量可用于表征图片样本和问题样本是否相关。示例性的,可将sigmoid函数作为二分类函数,将h
conv
输入该sigmoid函数,若得到sigmoid函数输出的结果为0,则表示图片样本和问题样本不相关,若得到sigmoid函数输出的结果为1,则表示图片样本和问题样本相关。
[0091]
对于前述节点关系图,图4提供了一个注意力引导图卷积网络的示意图,根据图4,
可以将每一个图片样本特征作为一个图片样本节点,将问题样本特征作为问题样本节点,图片样本节点和问题样本节点具有相同的特征维度,在图片样本节点和问题样本节点间设置初始的连接边组成一个节点关系图,节点关系图中的连接边表示其所连接的节点间的关系,在图4中为了简化,省略了节点自连接的边。aggcn模型由m个相同的块构成,每一个块将节点的特征作为输入,包括若干个图片样本节点和一个问题样本节点,通过将节点特征输入至m个块,可以使aggcn学习到更多的图片与问题之间的交互信息,例如,图片中的哪些区域与问题具有更强的关系,每一个块的输出都是图片与问题相互学习后的特征信息,得到的注意力矩阵可以从数值上反映出图片中各区域之间,以及各区域与问题之间的相关程度。
[0092]
其中,aggcn模型的每一个块可以由如下三部分组成:
[0093]
(1)注意引导层(attention guided layer):通过使用多头注意力机制,根据下式计算得到n个注意力矩阵:
[0094][0095]
n个注意力矩阵中的每一个注意力矩阵为节点关系图的邻接矩阵,使aggcn模型能够联合处理来自不同表示子空间的信息。该n个注意力矩阵中,a
t
为对应第t个头的基于注意力的邻接矩阵,w
iq
和w
ik
为对应的参数矩阵,该参数矩阵表示节点关系图中各图片样本节点和问题样本节点间的连接边的权重,可表征各节点之间关系强弱程度的度量,q和k都等于aggcn模型的第r
‑
1层的集合表示h(r
‑
1),d和v为注意引导层参数。
[0096]
(2)密集连接层(densely connected gcn,dcgcn):可以捕捉图中的结构化信息,密集连接可以使得能够训练更深的模型,捕捉局部和非局部信息,学习到一个更好的图表述。具体的,对于注意引导层提供的n个注意力矩阵,相应使用n个dggcn模型进行处理,每个注意力矩阵输入至一个dggcn模型中获得n个dggcn模型的输出结果,dggcn模型的详细结构信息如图5所示,该图5所示的dggcn模型的密集连接层的层数为3层。
[0097]
(3)线性组合层(linear combination layer):该层用于集成来自前述n个不同的密集连接层(dcgcn)的输出结果。该线性组合层的输出可用下式定义:
[0098][0099]
其中,h
outj
是第j个密集连接层(dcgcn)的输出结果,h
comb
为图卷积网络(aggcn)最后输出的特征矩阵作为最终的注意力矩阵。
[0100]
步骤s140,根据关系隐变量、图片样本特征和问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型;目标视觉问答模型用于进行视觉问答。
[0101]
具体实现中,用latent表示关系隐变量,可以将关系隐变量与更新后图片样本特征和更新后问题样本特征进行拼接,得到:
[0102]
h=[latent;h
conv
],
[0103]
将h作为视觉问答模型的输入,并将输出与预设的样本标签,即预设的问题的答案相比对,根据比对结果调整视觉问答模型参数,通过多次调整参数,可以得到最终的目标视觉问答模型。
[0104]
对于视觉问答模型的训练,示例性的,图6提供了一个利用关系隐变量进行模型训
练的示意图,根据图6,视觉问答模型可以主要由softmax函数组成,用net_2表示,可以在net_2之前设计一个隐变量计算模块,主要由sigmoid函数组成,用net_1表示。对问题样本特征和图片样本特征进行拼接,得到h
conv
,作为net_1的输入,通过sigmoid函数可以输出关系隐变量l,将关系隐变量l与h
conv
进行拼接,得到h=[latent;h
conv
]作为net_2的输入,其后连接softmax层,对问题样本的答案进行预测。
[0105]
视觉问答模型的损失函数可以为:
[0106][0107]
其中,i表示图片样本和问题样本索引,n表示图片样本和问题样本的个数,i
i
和q
i
分别表示第i个图片样本和第i个问题样本,a
i
表示视觉问答模型预测的第i个答案。
[0108]
通过net_1可以得到隐变量l,为了提高回答模糊问题的准确率,可以在训练样本中设置一些诸如对给定图片提出“上述问题如何解决?”问题的样本,对于这类样本,可以将重点放在图片上,因此可以将训练样本划分为两类,一类是问题与图片互补或者共同描述同一个问题,图片与问题具有很强的关系,另一类是问题与图片关系不大,重点在图片上。在训练样本的处理上,可以以概率p将图片匹配模糊问题,并在其之后增加一个逻辑层(logistic layer),得到一个隐变量,该隐变量表达了图片与问题之间的相关性。考虑隐变量的视觉问答模型损失函数可以为:
[0109][0110]
其中,y
i
为样本标签值,p
i
为答案预测值,具体实现中,可对样本标签进行编码得到对应的样本标签值,答案预测值为视觉问答模型直接输出的数值结果,该答案预测值可按相应的编码方式转化为对应的答案。
[0111]
因此,视觉问答模型总的损失函数可以为:
[0112]
loss=loss1+loss2。
[0113]
上述视觉问答模型训练方法,通过获取用于训练视觉问答模型的图片样本和问题样本,对图片样本进行特征提取得到图片样本特征,对问题样本进行特征提取得到问题样本特征,可以分别用图片样本特征和问题样本特征来描述图片样本和问题样本,确定图片样本特征与问题样本特征之间的关系隐变量,可以用关系隐变量来表征图片样本和问题样本是否相关,根据关系隐变量、图片样本特征和问题样本特征对视觉问答模型进行训练,得到目标视觉问答模型,由于在模型训练过程中除了考虑图片特征和问题特征对模型训练的影响,还考虑到了关系隐变量对模型训练的影响,即图片和问题是否相关对模型训练的影响,能够在回答模糊问题时仍然给出准确率较高的答案。
[0114]
在一个实施例中,上述步骤s130,可以具体包括:
[0115]
步骤s131,根据图片样本特征生成图片样本节点,以及根据问题样本特征生成问题样本节点;
[0116]
步骤s132,根据图片样本节点和问题样本节点生成关系图;关系图包括多个节点和多条节点关系边;节点包括图片样本节点和问题样本节点;节点关系边用于记录节点之间的关系;
[0117]
步骤s133,将关系图输入至注意力引导图卷积网络模型,得到关系矩阵;
[0118]
步骤s134,根据关系矩阵,得到图片样本特征和问题样本特征之间的关系隐变量。
[0119]
具体实现中,图片样本特征和问题样本特征可以为相同维度的向量,可以根据图片样本特征对应的空间点坐标得到图片样本节点,根据问题样本特征对应的空间点坐标得到问题样本节点,将图片样本节点和问题样本节点组成关系图,关系图可以由若干图片样本节点和若干问题样本节点组成,当节点之间存在关系时,通过节点关系边相连,节点也可以自连接。可以将关系图输入至aggcn模型,并将输出的注意力矩阵作为关系矩阵,关系矩阵中的各个元素可以用于表征问题对图片或者图片对问题的注意力程度。根据下式更新图片样本特征和问题样本特征
[0120][0121]
h
q
′
=α
j
h
q
,
[0122]
其中,表示第i(i=1,
…
,i)个原始图片样本特征,其中i为特征图个数,h
q
表示原始问题样本特征,α
i
为问题特征对特征图的注意力程度,α
j
为特征图对问题特征的注意力程度,h
v
′
为更新后图片样本特征,h
q
′
为更新后问题样本特征。
[0123]
对更新后图片样本特征和更新后问题样本特征进行拼接,得到h
conv
=[h
q
′
;h
v
′
]。将h
conv
输入二分类函数,可以得到图片样本特征和问题样本特征之间的关系隐变量。
[0124]
本实施例中,通过根据图片样本特征生成图片样本节点以及根据问题样本特征生成问题样本节点,根据图片样本节点和问题样本节点生成关系图,可以构建图片样本和问题样本之间的关系,将关系图输入至注意力引导图卷积网络模型得到关系矩阵,可以对图片样本与问题样本之间的注意力程度进行表征,根据关系矩阵得到图片样本特征和问题样本特征之间的关系隐变量,可以用关系隐变量来表征图片样本对问题样本的注意力程度,以及问题样本对图片样本的注意力程度,便于在处理模糊问题时引入图片样本和问题样本之间的关系。
[0125]
在一个实施例中,上述步骤s134,可以具体包括:根据关系矩阵,得到问题样本对于图片样本的第一权重和图片样本对于问题样本的第二权重;第一权重用于表征问题样本对于图片样本的注意力程度,第二权重用于表征图片样本对于问题样本的注意力程度;根据第一权重更新图片样本特征,得到更新后图片样本特征,以及根据第二权重更新问题样本特征,得到更新后问题样本特征;对更新后图片样本特征和更新后问题样本特征进行拼接,得到第一拼接向量;对第一拼接向量进行二分类,得到关系隐变量。
[0126]
具体实现中,在获取到关系矩阵后,可以根据关系矩阵a=[α1ꢀ…ꢀ
α
k
‑1]得到问题样本对于图片样本的第一权重α
i
(i=1,
…
,k
‑
1),以及图片样本对于问题样本的第二权重α
j
=∑α
i
,其中,α
i
可以表征问题特征对于特征图的注意力程度,α
j
可以表征特征图对于问题特征的注意力程度。
[0127]
利用α
i
来更新图片样本特征,得到更新后图片样本特征,具体公式可以为
[0128][0129]
利用α
j
来更新问题样本特征,得到更新后问题样本特征,具体公式可以为
[0130]
h
q
′
=α
j
h
q
。
[0131]
对h
v
′
和h
q
′
进行拼接,可以得到第一拼接向量
[0132]
h
conv
=[h
q
′
;h
v
′
]。
[0133]
将h
conv
输入二分类函数,得到关系隐变量,例如,可以将h
conv
输入sigmoid函数,若得到0,则表示图片样本和问题样本不相关,若得到1,则表示图片样本和问题样本相关。
[0134]
本实施例中,通过根据关系矩阵得到问题样本对于图片样本的第一权重和图片样本对于问题样本的第二权重,可以用第一权重和第二权重来表征问题样本对图片样本或图片样本对问题样本的注意力程度,根据第一权重更新图片样本特征得到更新后图片样本特征,根据第二权重更新问题样本特征得到更新后问题样本特征,可以使更新后的图片样本特征和问题样本特征中包含图片与问题之间的关系,对更新后图片样本特征和更新后问题样本特征进行拼接得到第一拼接向量,对第一拼接向量进行二分类得到关系隐变量,可以通过关系隐变量来表征图片样本与问题样本之间是否相关,便于在处理模糊问题时引入图片样本和问题样本之间的关系。
[0135]
在一个实施例中,上述步骤s140,可以具体包括:
[0136]
步骤s141,对关系隐变量、更新后图片样本特征和更新后问题样本特征进行拼接,得到第二拼接向量;
[0137]
步骤s142,基于第二拼接向量对视觉问答模型进行训练,得到目标视觉问答模型。
[0138]
具体实现中,在得到关系隐变量后,可以将关系隐变量与更新后图片样本特征和更新后问题样本特征进行拼接,得到第二拼接向量,具体公式可以为
[0139]
h=[latent;h
conv
],
[0140]
h
conv
=[h
q
′
;h
v
′
],
[0141]
其中,latent表示关系隐变量,h
q
′
表示更新后问题样本特征,h
v
′
标识更新后图片样本特征,h表示第二拼接向量。
[0142]
将第二拼接向量h输入至视觉问答模型进行训练,视觉问题模型可以输出预测的答案,将其与预设的样本标签,即预设的答案相比对,根据比对结果调整视觉问答模型参数,通过多次调整参数,可以得到最终的目标视觉问答模型。
[0143]
本实施例中,通过对关系隐变量、更新后图片样本特征和更新后问题样本特征进行拼接得到第二拼接向量,可以使第二拼接向量中包含图片样本和问题样本之间的关系,基于第二拼接向量对视觉问答模型进行训练得到目标视觉问答模型,可以使目标视觉问题模型根据图片样本和问题样本之间的关系训练得到,在回答模糊问题时仍然能够给出准确率较高的答案。
[0144]
在一个实施例中,上述步骤s142,可以具体包括:将第二拼接向量输入至视觉问答模型,得到预测答案;根据预测答案、图片样本和问题样本,得到视觉问答模型的第一损失值;根据预测答案和预设的样本标签,得到视觉问答模型的第二损失值;通过对第一损失值和第二损失值求和,得到视觉问答损失值;若视觉问答损失值不超过预设阈值,则根据视觉问答模型得到目标视觉问答模型。
[0145]
其中,样本标签可以为预先根据输入的,与图片样本和问题样本相对应的答案。
[0146]
具体实现中,在进行模型训练时,可以将第二拼接向量h输入至视觉问答模型,视觉问答模型可以输出预测的答案,根据预测答案得到视觉问答模型的第一损失值,具体公式可以为
[0147]
[0148]
其中,i表示图片样本和问题样本索引,n表示图片样本和问题样本个数,i
i
和q
i
分别表示第i个图片样本和第i个问题样本,a
i
表示视觉问答模型预测的第i个答案。
[0149]
还可以根据关系隐变量得到第二损失值,具体公式可以为
[0150][0151]
其中,y
i
为样本标签值,p
i
为答案预测值。
[0152]
视觉问答模型总的损失函数可以为
[0153]
loss=loss1+loss2。
[0154]
loss即为视觉问答损失值,将loss与预设阈值相比较,若loss超过预设阈值,则根据loss来调整视觉问答模型参数,否则,若loss不超过预设阈值,则无需调整参数,可以将当前的视觉问答模型作为目标视觉问答模型。
[0155]
本实施例中,通过将第二拼接向量输入至视觉问答模型得到预测答案,根据预测答案、图片样本和问题样本得到视觉问答模型的第一损失值,根据预测答案和预设的样本标签得到视觉问答模型的第二损失值,通过对第一损失值和第二损失值求和得到视觉问答损失值,可以使视觉问答模型的损失值中同时包含训练样本和样本之间关系的影响,提高模型训练的准确性,若视觉问答损失值不超过预设阈值,则根据视觉问答模型得到目标视觉问答模型,可以根据损失值来快速判断模型训练是否收敛,提高模型训练的效率。
[0156]
在一个实施例中,上述步骤s120,可以具体包括:将图片样本输入至区域卷积神经网络模型,得到至少一个图片样本特征;每一个图片样本特征对应于图片样本上的一个区域。
[0157]
具体实现中,可以通过将每一个图片样本输入至rcnn来进行图片样本的特征提取,rcnn可以输出至少一个图片样本特征,每一个图片样本特征为图片样本上一个区域的特征。
[0158]
例如,可以将图片样本输入至faster
‑
rcnn,经过faster
‑
rcnn的resnet
‑
101和rpn进行处理,输出不同候选区域的特征信息,每一个候选区域对应一个特征图,其中,rpn可以生成若干区域,可以从若干区域中选择部分区域作为候选区域,例如,可以根据区域包含目标的概率大小,来选择候选区域。
[0159]
本实施例中,通过将图片样本输入至区域卷积神经网络模型得到至少一个图片样本特征,可以高效提取图片样本特征,提高视觉问答模型训练的效率。
[0160]
在一个实施例中,上述步骤s120,可以具体包括:将问题样本输入至基于转换器的双向编码表征模型,得到问题样本特征。
[0161]
具体实现中,可以通过将每一个问题样本输入至bert来进行问题样本的特征提取,bert可以输出问题样本特征。
[0162]
例如,可以将问题样本输入至bert模型,对问题样本进行编码,经过多个转换器层层进行特征处理,输出问题样本对应的特征信息,作为问题样本特征。
[0163]
本实施例中,通过将问题样本输入至基于转换器的双向编码表征模型得到问题样本特征,可以高效提取问题样本特征,提高视觉问答模型训练的效率。
[0164]
在一个实施例中,如图7所示,提供了一种视觉问答方法,以该方法应用于终端为例进行说明,包括以下步骤:
[0165]
步骤s710,获取待识别图片和待回答问题;
[0166]
步骤s720,对待识别图片进行特征提取,得到待识别图片特征,以及对待回答问题进行特征提取,得到待回答问题特征;
[0167]
步骤s730,确定待识别图片特征与待回答问题特征之间的关系隐变量;
[0168]
步骤s740,将关系隐变量、待识别图片特征和待回答问题特征输入至目标视觉问答模型,得到问题的答案。
[0169]
具体实现中,当客户遇到问题时,可以向终端输入截图和相应的问题描述,其中截图可以为待识别图片,问题描述可以为待回答问题。将待识别图片输入至rcnn网络进行特征提取,得到待识别图片特征,将待回答问题输入至bert模型进行特征提取,得到待回答问题特征。待识别图片特征和待回答问题特征可以为相同维度的向量,根据待识别图片特征对应的空间点坐标得到待识别图片节点,根据待回答问题特征对应的空间点坐标得到待回答问题节点,将待识别图片节点和待回答问题节点组成关系图,输入至aggcn网络,得到注意力矩阵,根据注意力矩阵可以得到待识别图片特征与待回答问题特征之间的关系隐变量,通过对关系隐变量、待识别图片特征和待回答问题特征进行拼接,输入至训练好的目标视觉问答模型,通过目标视觉问答模型对拼接后的关系隐变量、待识别图片特征和待回答问题特征进行分类,可以根据分类结果得到问题的答案。
[0170]
由于视觉问答方法的具体处理过程在前述实施例中已有详细说明,在此不再赘述。
[0171]
上述视觉问答方法,通过获取待识别图片和待回答问题,对待识别图片进行特征提取得到待识别图片特征,对待回答问题进行特征提取得到待回答问题特征,可以分别用待识别图片特征和待回答问题特征来描述待识别图片和待回答问题,确定待识别图片特征与待回答问题特征之间的关系隐变量,可以用关系隐变量来表征待识别图片和待回答问题是否相关,将关系隐变量、待识别图片特征和待回答问题特征输入至目标视觉问答模型,得到问题的答案,由于在模型识别过程中除了考虑图片特征和问题特征对识别结果的影响,还考虑到了图片和问题是否相关对识别结果的影响,能够在回答模糊问题时仍然给出准确率较高的答案。
[0172]
而且,通过使用bert对问题进行embedding(嵌入),使用faster
‑
rcnn提取出图片不同候选区域的object embedding(目标嵌入)信息,为了得到问题与图片不同目标之间的关系信息,使用aggcn网络,将问题的embedding与图片的object embedding作为图的节点,通过多头注意力机制计算出不同节点之间的关系矩阵,并将其作为每一个图的邻接矩阵,通过dcgcn学习到这些节点之间的交互信息,最终得到每个节点的特征信息,并根据数据集的特点,设计多任务学习方式,使用辅助任务进一步提高特征提取的质量,从而提高主任务即vqa的准确率。实验表明,采用本技术的技术方案,平均回答准度可以由20.65%提高到30.33%。
[0173]
应该理解的是,虽然图1和图7的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1和图7中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次
进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
[0174]
在一个实施例中,如图8所示,提供了一种视觉问答模型训练装置800,包括:样本获取模块810、样本特征提取模块820、样本隐变量确定模块830和模型训练模块840,其中:
[0175]
样本获取模块810,用于获取用于训练视觉问答模型的图片样本和问题样本;
[0176]
样本特征提取模块820,用于对所述图片样本进行特征提取,得到图片样本特征,以及对所述问题样本进行特征提取,得到问题样本特征;
[0177]
样本隐变量确定模块830,用于确定所述图片样本特征与所述问题样本特征之间的关系隐变量;
[0178]
模型训练模块840,用于根据所述关系隐变量、所述图片样本特征和所述问题样本特征,对视觉问答模型进行训练,得到目标视觉问答模型;所述目标视觉问答模型用于进行视觉问答。
[0179]
在一个实施例中,上述样本隐变量确定模块830,可以具体包括:
[0180]
样本节点生成模块,用于根据所述图片样本特征生成图片样本节点,以及根据所述问题样本特征生成问题样本节点;
[0181]
关系图生成模块,用于根据所述图片样本节点和所述问题样本节点生成关系图;所述关系图包括多个节点和多条节点关系边;所述节点包括所述图片样本节点和所述问题样本节点;所述节点关系边用于记录所述节点之间的关系;
[0182]
关系矩阵模块,用于将所述关系图输入至注意力引导图卷积网络模型,得到关系矩阵;
[0183]
关系隐变量模块,用于根据所述关系矩阵,得到所述图片样本特征和所述问题样本特征之间的关系隐变量。
[0184]
在一个实施例中,上述关系隐变量模块,还用于根据所述关系矩阵,得到所述问题样本对于所述图片样本的第一权重和所述图片样本对于所述问题样本的第二权重;所述第一权重用于表征所述问题样本对于所述图片样本的注意力程度,所述第二权重用于表征所述图片样本对于所述问题样本的注意力程度;根据所述第一权重更新所述图片样本特征,得到更新后图片样本特征,以及根据所述第二权重更新所述问题样本特征,得到更新后问题样本特征;对所述更新后图片样本特征和所述更新后问题样本特征进行拼接,得到第一拼接向量;对所述第一拼接向量进行二分类,得到所述关系隐变量。
[0185]
在一个实施例中,上述样模型训练模块840,可以具体包括:
[0186]
拼接模块,用于对所述关系隐变量、所述更新后图片样本特征和所述更新后问题样本特征进行拼接,得到第二拼接向量;
[0187]
拼接后训练模块,用于基于所述第二拼接向量对视觉问答模型进行训练,得到所述目标视觉问答模型。
[0188]
在一个实施例中,上述拼接后训练模块,还用于将所述第二拼接向量输入至所述视觉问答模型,得到预测答案;根据所述预测答案、所述图片样本和所述问题样本,得到所述视觉问答模型的第一损失值;根据所述预测答案和预设的样本标签,得到所述视觉问答模型的第二损失值;通过对所述第一损失值和所述第二损失值求和,得到视觉问答损失值;若所述视觉问答损失值不超过预设阈值,则根据所述视觉问答模型得到所述目标视觉问答
模型。
[0189]
在一个实施例中,上述样本特征提取模块820,还用于将所述图片样本输入至区域卷积神经网络模型,得到至少一个图片样本特征;每一个所述图片样本特征对应于所述图片样本上的一个区域。
[0190]
在一个实施例中,上述样本特征提取模块820,还用于将所述问题样本输入至基于转换器的双向编码表征模型,得到所述问题样本特征。
[0191]
在一个实施例中,如图9所示,提供了一种视觉问答装置900,包括:获取模块910、特征提取模块920、隐变量确定模块930和识别模块940,其中:
[0192]
获取模块910,用于获取待识别图片和待回答问题;
[0193]
特征提取模块920,用于对所述待识别图片进行特征提取,得到待识别图片特征,以及对所述待回答问题进行特征提取,得到待回答问题特征;
[0194]
隐变量确定模块930,用于确定所述待识别图片特征与所述待回答问题特征之间的关系隐变量;
[0195]
识别模块940,用于将所述关系隐变量、所述待识别图片特征和所述待回答问题特征输入至目标视觉问答模型,得到问题的答案。
[0196]
关于视觉问答模型训练、视觉问答装置的具体限定可以参见上文中对于视觉问答模型训练、视觉问答方法的限定,在此不再赘述。上述视觉问答模型训练、视觉问答装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0197]
在一个实施例中,提供了一种计算机设备,该计算机设备可以是终端,其内部结构图可以如图10所示。该计算机设备包括通过系统总线连接的处理器、存储器、通信接口、显示屏和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的通信接口用于与外部的终端进行有线或无线方式的通信,无线方式可通过wifi、运营商网络、nfc(近场通信)或其他技术实现。该计算机程序被处理器执行时以实现一种视觉问答模型训练、视觉问答方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
[0198]
本领域技术人员可以理解,图10中示出的结构,仅仅是与本技术方案相关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0199]
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,计算机程序被处理器执行时,使得处理器执行上述一种视觉问答模型训练、视觉问答方法的步骤。此处一种视觉问答模型训练、视觉问答方法的步骤可以是上述各个实施例的一种视觉问答模型训练、视觉问答方法中的步骤。
[0200]
在一个实施例中,提供了一种计算机可读存储介质,存储有计算机程序,计算机程序被处理器执行时,使得处理器执行上述一种视觉问答模型训练、视觉问答方法的步骤。此
处一种视觉问答模型训练、视觉问答方法的步骤可以是上述各个实施例的一种视觉问答模型训练、视觉问答方法中的步骤。
[0201]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(read
‑
only memory,rom)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(random access memory,ram)或外部高速缓冲存储器。作为说明而非局限,ram可以是多种形式,比如静态随机存取存储器(static random access memory,sram)或动态随机存取存储器(dynamic random access memory,dram)等。
[0202]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0203]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1