一种大规模商品销售中核心用户和核心物品的挖掘方法
本发明属于数据挖掘推荐技术领域,具体涉及一种大规模商品销售中核心用户和核心物品的挖掘方法。
背景技术:
基于邻域的协同过滤,其核心思想是向用户推荐与他喜爱物品相似的物品,因此推荐的准确性由两方面决定:首先是对用户喜爱物品的度量,即判断出用户的喜爱物品是什么;其次是物品间的相似性度量。在日常生活中,人们经常观察到某个用户更喜欢某些物品,而有些用户对某项物品更加忠诚,即物品对这些用户更重要。由于偏好的存在,那每个用户也存在其最喜爱的物品、每个物品存在对其最重要的用户。将这两种偏好应用到常见的相似度度量中可提高相似度的准确度,进一步地可通过制定合适的策略求出用户的核心物品和物品的核心用户,提高推荐的准确度。但由于知识的缺乏,无法直接求出用户或物品的偏好程度。
技术实现要素:
本发明提出一种大规模商品销售中核心用户和核心物品的挖掘方法,提高相似度度量准确度及后续推荐准确度。
本发明所采用的技术方案为:
一种大规模商品销售中核心用户和核心物品的挖掘方法,包括如下步骤:
步骤一、初始化物品对用户重要性权重矩阵
步骤二、依次循环迭代更新用户对物品的喜爱权重矩阵
进一步地,步骤一包括:
以初始物品对用户重要性权重矩阵
其中,
选择相似度度量,将权重矩阵
对于每个用户u,以用户u为中心的总体加权相似度和为
当用户满足
时,被选作为物品i的核心用户,表示物品i的最大总体加权相似度和为
进一步地,步骤二包括:
步骤201、更新用户对物品的喜爱权重矩阵
对于每个物品i,权重系数
步骤202、更新核心物品
对于每个用户u和每对物品
用户u的核心物品
表示用户u的最大总体相似度和为
即以
步骤203、更新物品对用户的重要性权重矩阵
对于每个用户u,通过归一化的加权相似度来量化每个物品i的重要性;
步骤204、更新核心用户
基于已经更新的权重系数
以用户u为中心,总体加权相似度和
当
表示物品i的第l轮最大总体加权相似度和
步骤205、设置收敛条件,并重复步骤201至205,当满足收敛条件时,停止迭代,输出最优的核心用户、核心物品、权重矩阵
进一步地,步骤205中,所述收敛条件为
进一步地,所述相似度度量包括欧氏距离取反、余弦相似度和皮尔逊相关系数。
本发明的有益效果在于:
本发明中通过依次循环迭代更新用户对物品的喜爱权重矩阵、每个用户的核心物品、物品对用户的重要性权重矩阵和每个物品的核心用户,能够在较少的迭代次数收敛,挖掘出两种权重矩阵的最优值、以及核心用户、核心物品,为后续推荐生成提供更多知识,提高推荐准确度。
附图说明
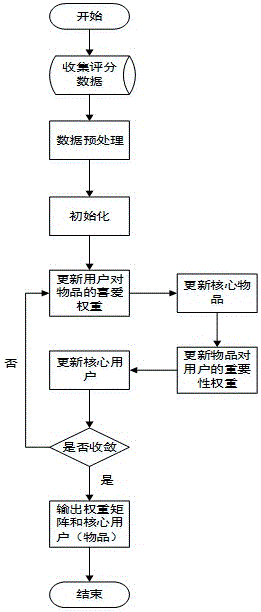
图1为本发明的方法流程图;
图2为本发明的方法模型原理图;
图3为本发明在两个数据集的运行效果图。
具体实施方式
本发明的挖掘方法通过顺序迭代更新用户对物品的喜爱权重矩阵
下面结合附图和具体的实施例对本发明的大规模商品销售中核心用户和核心物品的挖掘方法作进一步地详细说明。
如图1所示,一种大规模商品销售中核心用户和核心物品的挖掘方法,在该挖掘方法前,需预先收集用户对物品的交互行为,将其量化为评分形式,对异常值进行删除,缺失值进行填充,并转换成用户-物品评分矩阵形式。
本发明的挖掘方法包括如下步骤:
步骤一、初始化物品对用户重要性权重矩阵
以初始物品对用户重要性权重矩阵
其中,
选择相似度度量(如欧氏距离取反、余弦相似度、皮尔逊相关系数),将权重矩阵
对于每个用户u,以用户u为中心的总体加权相似度和为
当用户满足
时,被选作为物品i的核心用户,表示物品i的最大总体加权相似度和为
步骤二、依次循环迭代更新用户对物品的喜爱权重矩阵
步骤二包括:
步骤201、更新用户对物品的喜爱权重矩阵
对于每个物品i,权重系数
步骤202、更新核心物品
对于每个用户u和每对物品
用户u的核心物品
表示用户u的最大总体相似度和为
即以
步骤203、更新物品对用户的重要性权重矩阵
对于每个用户u,通过归一化的加权相似度来量化每个物品i的重要性。
步骤204、更新核心用户
基于已经更新的权重系数
以用户u为中心,总体加权相似度和
当
表示物品i的第l轮最大总体加权相似度和为
步骤205、设置收敛条件,并重复步骤201至205,当满足收敛条件时,停止迭代,输出最优的核心用户、核心物品、权重矩阵
步骤205中,收敛条件为
图2为本发明的方法模型原理图,其中,m表示物品数,n表示用户数,其中矩阵中的元素1表示对应用户对物品感兴趣。
下面以一个例子作示例性说明。考虑一个四个物品(行)和四个用户(列)构成的系统,其评分矩阵为
表1权重矩阵
表2核心物品、核心用户、最大总体加权相似度
首先,容易看出物品i4只被用户u3喜爱,用户u4只喜爱一个物品i1,那么i4的核心用户必然是u3,u4的核心物品必然是i1,可在表2中得到。其次,尽管物品i1被u1和u4同时喜爱,用户u4是更重要的,因为u4是更忠实于它,所以u4是i1的核心用户。对于系统来说,研究用户的概况和了解他的独特需求是有用的,特别是对于i1。同样地,尽管用户u3喜爱三个物品i2,i3,i4,u3选择了i4作为他的独特品味(其他用户都没有关注i4),所以有理由相信i4是对u3更重要的,即是他的核心物品。
图3为本发明在两个数据集的运行收敛效果图,其中,图3(a)为数据集ml100k的运行收敛效果图,图3(b)为数据集ml1m的运行收敛效果图。实验中,使用两个真实电影评分数据集,movielens100k(缩写为ml100k)和movielens1m(缩写为ml1m),两个数据集的特征如下表3所示。
表3数据集及其特征
在初始数据集中,每个用户至少对20部影片评分,评分为整数1-5。为了方便运行,将评分4和5映射为
为了证明算法的收敛性,评估了每个用户相邻迭代的总加权相似和
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术方法范围内,可轻易想到的替换或变换方法,都应该涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!