基于改进YOLOv3算法的粮库人员不规范作业检测法
基于改进yolov3算法的粮库人员不规范作业检测法
技术领域
1.本发明涉及计算机视觉领域和图像识别领域,具体是一种基于改进yolov3算法的粮库人员不规范作业检测方法。
背景技术:
2.目标检测作为计算机视觉中的一个重要领域,在现实中的应用很广泛,它的目标是在给定图像中检测出需要识别的物体目标,并且确定物体的类别以及在图像中的位置。在深度学习于计算机视觉领域大规模应用前,目标检测精度的进步比较缓慢,诸如采用hog特征、haar特征等传统手工构造特征算法加上svm算法、adaboost算法等分类算法的方式来提高精度已是比较困难的事。而在imagenet图像分类大赛出现的卷积神经网络——alexnet展现了强大性能,吸引着学者们将卷积神经网络迁移到了其他的任务,包括目标检测。近年来,出现了很多目标检测的方法,其中比较有代表性的算法就有以ssd系列、yolo系列为代表的单次(one
‑
stage)算法。
3.yolo(you only look once)算法的检测流程比较简洁。调整输入图像为固定尺寸后馈送到主干卷积网络中提取特征,而后直接在输出层完成目标分类、边界框回归等操作。通过yolo,每张图像只需要看一眼就能得出图像中都有哪些物体和这些物体的位置,其中yolov3是在yolo与yolov2的基础上改进的算法,相比之下可以达到更快的运行速度,更高的检测准确率,是当前工业界较为流行的单次目标检测算法。但yolov3算法中的先验框数量是预先选定,并且其尺寸大小是针对imagenet数据集上的检测物体进行聚类获得,并不适用于粮库作业场景,另外在粮库作业场景下对不同尺度、不同位置的目标预测方面yolov3也存在网络表征能力不足,检测效果不佳的情况,并且yolov3在网络的特征融合阶段直接将全局性的小尺度特征与细粒度特征采用级联(concatenation)的方式融合,在检测小目标时无法较好地考虑到全局场景性。
4.因此需要一种能够改进上述问题的方法。
技术实现要素:
5.本发明要解决的技术问题是提供基于改进yolov3算法的粮库人员不规范作业检测方法,克服现有技术中存在的缺陷,提供一种更加适合粮库场景检测且网络表征能力更强的基于改进yolov3算法的粮库人员不规范作业检测方法。
6.为了解决上述技术问题,本发明提供基于改进yolov3算法的粮库人员不规范作业检测方法,包括步骤如下:
7.对粮库人员不规范作业行为进行图像的采集,然后将采集的图像输入上位机中的具有在线生产能力的粮库不规范作业行为检测网络,输出有人员不规范作业行为的准确标记的结果图片,并在上位机中显示、存储结果;
8.所述粮库不规范作业行为检测网络包括基于yolov3网络构建的主干层和特征融合输出层,并在特征融合输出层的y2层和y3层分别中嵌入尺度上下文选择注意力模块sca。
9.作为本发明的基于改进yolov3算法的粮库人员不规范作业检测方法的改进:
10.所述主干层包括输入的图片经过两倍下采样的卷积层,然后依次经过四个阶段stage1、stage2、stage3和stage4,每个阶段均由下采样卷积层以及残差结构组成,其中stage1包含3个残差结构,stage2包含5个残差结构,stage3包含10个残差结构,stage4包含4个残差结构;
11.所述特征融合输出层包含三个尺度检测输出,y1层为经过32倍下采样的stage4层输出特征进行卷积后输出小尺度特征的检测结果;在y2层,将来自y1层的特征进行2倍上采样与stage3输出的特征通过一个尺度上下文选择注意力模块sca进行融合,输出中尺度特征的检测结果;在y3层,将来自y2层的特征进行2倍上采样,然后与stage2、stage3输出的特征通过另一个尺度上下文选择注意力模块sca进行融合输出大尺度特征的检测结果。
12.作为本发明的基于改进yolov3算法的粮库人员不规范作业检测方法的进一步改进:
13.所述sca模块的输入端包含多个尺度的特征集x
l
={x
l
,l=1,...,l},首先每部分尺度特征x
l
分别通过1x1卷积层实现维度变换,表示为:
14.x
l
=f(x;w
l
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
15.其中,表示卷积层参数,x
l
为第l尺度的尺度上下文特征;
16.然后将所有的尺度上下文特征x
l
,l=1,...,l通过双线性插值将采样为相同的大小,然后以级联的方式被联合为特征作为注意力门的输入,生成注意力关注图α,包含α
l
,l∈{1,...,l},生成过程可以表述为:
[0017][0018][0019]
其中,注意力门由一组参数θ
att
表示,它的输入包含l个尺度,w
x
,b
x
为密集卷积的运算参数,为线性变换参数,σ(x)为relu激活函数;
[0020]
然后对注意力关注图α应用softmax来计算第l尺度上的权重q
l
:
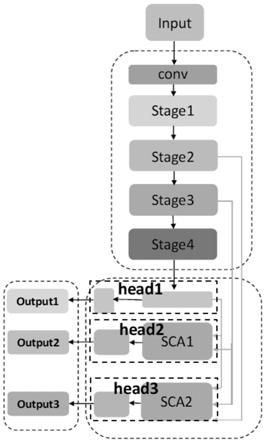
[0021][0022]
同时将尺度上下文特征x
l
,l=1,...,l通过特征变换得到尺度特征f
l
,并与尺度l上对应的权重q
l
相乘后执行逐元素求和,获得特征图e:
[0023][0024][0025]
其中ψ
l
表示用于匹配特征的特征变换的函数,w
i
是l变换层的参数,其中变换包含卷积层,仿射变换和插值运算。
[0026]
作为本发明的基于改进yolov3算法的粮库人员不规范作业检测方法的进一步改进:
[0027]
所述具有在线生产能力的粮库不规范作业行为检测网络的建立过程为:
[0028]
1.1)、建立训练测试数据集
[0029]
通过网络资源,或者通过粮库单位获取内部各种作业环境下的监控视频,搜集粮库人员不规范作业的图片构建数据集,然后对数据集进行标注和数据增强操作,获得训练集和测试集;
[0030]
1.2)、基于k
‑
means聚类算法,对所构建的数据集中目标对象的真实边框尺寸分布进行聚类分析,通过统计聚类规律得到目标建议框个数和尺寸;
[0031]
1.3)、将训练集输入所述粮库不规范作业行为检测网络,然后使用测试集进行测试,从而获得所述具有在线生产能力的粮库不规范作业行为检测网络。
[0032]
作为本发明的基于改进yolov3算法的粮库人员不规范作业检测方法的进一步改进:
[0033]
所述聚类算法流程如下:
[0034]
2.1)、设置样本数据为所述训练集数据中有标注目标真实边框的数据,标注数据生成一个包含标注框位置和类别的文件,其中每个标注框样本数据为(x
j
,y
j
,w
j
,h
j
),j∈{1,2,...,n},ground truth boxes相对于原图的坐标,(x
j
,y
j
)是框的中心点,(w
j
,h
j
)是框的宽和高,n是所有标注框的个数;
[0035]
2.2)、给定k个聚类中心点(w
i
,h
i
),i∈{1,2,...,k},这里的w
i
,h
i
是anchor boxes的宽和高尺寸,由于anchor boxes位置不固定,所以没有(x,y)的坐标,只有宽和高;
[0036]
2.3)、计算每个标注框和每个聚类中心点的距离d=1
‑
iou(box,centroid),计算时每个标注框的中心点都与聚类中心重合:
[0037]
d=1
‑
iou[(x
j
,y
j
,w
j
,h
j
),(x
j
,y
j
,w
i
,h
i
)],j∈{1,2,...,n},i∈{1,2,...,k}
ꢀꢀ
(7)
[0038]
将标注框分配给“距离”最近的聚类中心;
[0039]
2.4)、所有标注框分配完毕以后,对每个簇重新计算聚类中心点,计算方式为:
[0040][0041]
n
i
是第i个簇的标注框个数,就是求该簇中所有标注框的宽和高的平均值;
[0042]
2.5)、重复步骤2.3)、步骤2.4),直到聚类中心改变量小于阈值得到更加适合的粮库场景的目标建议框个数和尺寸,然后按照尺度越大选取的框面积越小的原则,将建议框分为三组,分别对应到3个不同的检测尺度上。
[0043]
本发明的有益效果主要体现在:
[0044]
1、本发明对所构建的数据集中目标对象的真实边框尺寸分布进行聚类分析,通过统计聚类规律得到更加适合的目标建议框个数和尺寸,优化了原yolov3检测网络的结构与方法,使其更加适应在本场景下的检测任务,在保证了精度的同时又简化了网络。
[0045]
2、本发明针对场景优化问题提出了尺度选择注意力模块,并在在特征融合处嵌入了注意力模块,利用不同尺度特征的适应性融合进一步提升了网络的表征能力。
附图说明
[0046]
图1为本发明的粮库不规范作业行为检测网络的结构示意图;
[0047]
图2为yolov3主体网络结构图;
[0048]
图3为本发明的实施例1中yolo
‑
base基础检测网络结构示意图;
[0049]
图4为本发明的尺度上下文选择注意力模块的结构示意图。
具体实施方式
[0050]
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
[0051]
实施例1、基于改进yolov3算法的粮库人员不规范作业检测方法,如图1
‑
4所示,该方法包括以下步骤:
[0052]
s1、构建粮库不规范作业行为检测网络,基于yolov3网络改进并构建粮库不规范作业行为检测网络应用于粮库作业场景,粮库不规范作业行为检测网络构建过程包括yolo
‑
base基础检测网络的构建、将尺度上下文选择注意力模块(scale context selection attention,简称sca模块)嵌入到yolo
‑
base基础检测网络中;
[0053]
s101、所述yolo
‑
base基础检测网络对yolov3的darknet
‑
53网络结构进行了调整,整体采用了全卷积网络,主要由主干层(backbone)和特征融合输出层(multi
‑
scale output)组成。其中主干层网络主要通过多阶段(stage)卷积与下采样操作获得深度特征,输出层对不同阶段的特征进行融合,并最终以三个不同尺度的特征层进行回归预测;
[0054]
yolo
‑
base基础检测网络具体结构顺序为:
[0055]
主干层中的卷积层(conv)均由卷积操作(convolution)、归一化操作(batch normalization,bn)和激活函数leaky relu构成。输入经过两倍下采样的卷积层,然后是四个阶段(stage),每个阶段均由下采样卷积层以及若干个残差结构(residual block)组成,残差结构可以增强梯度传播以及网络的泛化能力;其中stage1包含3个残差结构,stage2包含5个残差结构,stage3包含10个残差结构,stage4包含4个残差结构。
[0056]
特征融合输出层包含三个尺度检测输出,y1层为经过32倍下采样的stage4层输出特征进行卷积后输出,用于小尺度特征的检测;y2层将来自y1层的特征进行2倍上采样与stage3输出的特征进行融合而输出,用于中尺度特征的检测;y3层将来自y2层的特征进行2倍上采样的输出与stage2输出的特征进行融合输出,用于大尺度特征的检测,如图3所示;
[0057]
s102、将sca模块,嵌入到yolo
‑
base基础检测网络中,优化网络中不同层次不同尺度特征的融合,以产生更具全面且有效的特征;
[0058]
所述sca模块输入端包含多个尺度的特征。这些特征可以用特征集x
l
表示,其中每个元素表示为x
l
,l=1,...,l。首先每部分尺度特征x
l
分别通过1x1卷积层实现维度变换,每个尺度l上的变换运算可以表示为函数而第l尺度的输出特征x
l
计算公式为:
[0059]
x
l
=f(x;w
l
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0060]
其中表示卷积层参数;所有的尺度上下文特征,即,第(1,...,l)尺度的输出特征x
l
,l=1,...,l通过双线性插值将其采样为相同的大小,然后以级联的方式(concatenation)被联合为特征作为注意力门(attention gate)的输入,生成注意力关注图(attention map)α,包含α
l
,l∈{1,...,l},生成过程可以表述为:
[0061]
[0062][0063]
其中注意力门由一组参数θ
att
表示,它的输入包含l个尺度,w
x
,b
x
为密集卷积(dense convolution)运算参数,为线性变换参数,σ(x)为relu激活函数。
[0064]
接下来,为了归一化每个维度的注意力特征图,对注意力关注图α应用softmax来计算第l尺度上的权重q
l
,过程表示为:
[0065][0066]
同时将尺度上下文特征x
l
,l=1,...,l通过特征变换(feature transformation)得到尺度特征f
l
,并与尺度l上对应的权重q
l
相乘后执行逐元素求和,获得特征图e,整个过程表述为:
[0067][0068][0069]
其中ψ
l
表示用于匹配特征的特征变换的函数,w
i
是l变换层的参数,其中变换包含卷积层,仿射变换和插值运算,sca模块结构如图4所示;
[0070]
将sca模块嵌入步骤s101中构建的yolo
‑
base基础检测网络两特征融合处,在yolo
‑
base基础检测网络的head2分支处的sca1模块,融合了head1分支的特征和stage3阶段的输出特征用于中尺度特征的检测;在head3分支处的sca2模块,融合了head1分支的特征,stage3阶段的输出特征和stage2阶段的输出特征用于大尺度特征的检测,添加sca模块后的网络结构如图1;
[0071]
s2、训练粮库不规范作业行为检测网络;
[0072]
s201、对所研究的粮库人员不规范作业行为进行数据集的采集与构建;
[0073]
针对所研究人员数量以及安全帽佩戴情况的检测进行数据集的采集与构建,数据的采集主要通过两个途径:一是通过谷歌、百度、搜狗等网络资源进行搜集相关图片;二是通过和浙江省内相关粮库单位合作获取,这些数据来自粮库内部各种作业环境下的监控视频;为使得相关的图片更加接近真实的粮库环境,加入了噪声、模糊等数据增强方式。构建的数据集利用labelimg标注工具对目标对象进行标注,主要包含三个待检测类别:人体(person),佩戴安全帽正例(helmet),未佩戴安全帽负例(head)。具体的数据集信息如下表1所示:
[0074]
表1
[0075]
数据集人员及安全帽佩戴类别数目3类别明细person、helmet、head图片数量5400人体数目12483安全帽佩戴7523
未佩戴头部5134
[0076]
s202、数据集预处理,所构建数据集共5400张图片,其中训练集4320张,测试集1080张。为了提高模型的鲁棒性以及泛化能力,对训练数据采用了常规数据增强操作,包括随机镜像操作、随机旋转(
‑
10,10)度,随机裁剪及添加噪声等方式;
[0077]
然后基于k
‑
means聚类算法,在粮库安全作业检测场景下,对所构建的数据集中目标对象的真实边框尺寸分布进行聚类分析,通过统计聚类规律得到更加适合的粮库场景的目标建议框个数和尺寸,可以实现对预测对象范围进行约束,增加数据中尺度先验信息,有助于快速收敛并提升模型效果。聚类算法流程如下:
[0078]
1)、设置样本数据为原始训练集数据中有标注目标真实边框的数据,标注数据生成一个包含标注框位置和类别的文件,其中每个标注框样本数据为(x
j
,y
j
,w
j
,h
j
),j∈{1,2,...,n},即ground truth boxes相对于原图的坐标,(x
j
,y
j
)是框的中心点,(w
j
,h
j
)是框的宽和高,n是所有标注框的个数;
[0079]
2)、首先给定k个聚类中心点(w
i
,h
i
),i∈{1,2,...,k},这里的w
i
,h
i
是anchor boxes的宽和高尺寸,由于anchor boxes位置不固定,所以没有(x,y)的坐标,只有宽和高;
[0080]
3)、计算每个标注框和每个聚类中心点的距离d=1
‑
iou(box,centroid),计算时每个标注框的中心点都与聚类中心重合,这样才能计算iou值,即:
[0081]
d=1
‑
iou[(x
j
,y
j
,w
j
,h
j
),(x
j
,y
j
,w
i
,h
i
)],j∈{1,2,...,n},i∈{1,2,...,k};(7)
[0082][0083]
将标注框分配给“距离”最近的聚类中心;
[0084]
4)、所有标注框分配完毕以后,对每个簇重新计算聚类中心点,计算方式为:
[0085][0086]
n
i
是第i个簇的标注框个数,就是求该簇中所有标注框的宽和高的平均值。
[0087]
5)、重复步骤3)、步骤4),直到聚类中心改变量小于某个阈值。得到更加适合的粮库场景的目标建议框个数和尺寸,然后按照尺度越大选取的框面积越小的原则,将建议框分为三组,分别对应到3个不同的检测尺度上;
[0088]
s203、训练环境配置,此检测网络的训练在centos操作系统服务器进行,利用tesla p4gpu加速实验,开发环境基于pytorch深度学习框架。具体的软硬件配置如下表2:
[0089]
表2
[0090]
名称环境配置操作系统centos7.3.1611处理器12*e5
‑
2609v3@1.9ghz,15m cache显卡tesla p4 8gb(384.81)内存125gb开发环境python3.7 pytorch1.4.0
[0091]
将训练集输入步骤s1建立的粮库不规范作业行为检测网络,采用adam优化器对网络进行优化,可以动态调整学习率,适用于包含噪声及稀疏优化问题,采用动量(momentum)系数为0.9,权重衰减(weight decay)为0.0001。优化器的初始学习率(learning rate,lr)设置为0.01,并按照余弦衰减的形式对学习率进行衰减。受制于显存问题一个批次的输入
图片大小为32,共训练100次迭代,然后使用测试集对训练完成后粮库不规范作业行为检测网络进行测试,平均正确率均值(mean average precision,map)达到93.9%,从而获得得到可在线使用的粮库不规范作业行为检测网络。
[0092]
s3、粮库不规范作业行为检测网络模型实际使用过程具体为:
[0093]
按步骤s1对粮库人员不规范作业行为进行图像的采集,然后在上位机中,将采集的图像输入步骤s2获得的具有在线生产能力的粮库不规范作业行为检测网络,输出准确标记人员不规范作业行为的结果图片,并在上位机中显示、存储结果;
[0094]
实验1:
[0095]
为了进一步验证所提出的方法对人员以及安全帽情况的检测能力,本实验将最终改进后的yolo
‑
sca网络模型与另外2篇相关文献的算法模型在本发明上述所构建的数据集上进行了对比实验。文献1(参见吴迪.基于计算机视觉的施工人员安全状态监测技术研究[d].哈尔滨工业大学,2019.)中同样以yolov3网络为主干设计了模型,并增加了一个尺度检测分支,通过跨尺度检测的方式进行检测。文献2(参见wu,fan&jin,guoqing&gao,mingyu&he,zhiwei&yang,yuxiang.(2019).helmet detection based on improved yolo v3 deep model.363
‑
368.10.1109/icnsc.2019.8743246.基于改进的yolo v3深度模型的头盔检测)以yolov3算法为基础,增加了focal loss损失来优化前后景不平衡问题。
[0096]
实验评价指标如下:
[0097]
1)交并比(intersection over union,iou)
[0098]
iou是对于衡量预测样本坐标与真实样本坐标重叠程度的函数,并且是评价检测算法重要性能指标平均正确率均值(mean average precision,map)的基础。iou用来计算“预测的目标边框”和“真实的目标边框”的交集与并集比值,即两个区域重叠部分面积占二者总面积的比例。其定义如下:
[0099][0100]
在检测任务中,模型输出的矩形框与人工标注的矩形框的iou值大于某个阈值时(一般为0.5)即认为模型预测为正样本。
[0101]
2)精确率(precision)和召回率(recall)
[0102]
在检测问题的分类预测中,将模型的预测结果与样本的真实标签使用混淆矩阵来表示四种组合,其中分别是真阳性(true positive,tp)、假阳性(false positive,fp)、真阴性(true negative,tn)、假阴性(false negative,fn)这四种情况,混淆矩阵具体如下表3所示:
[0103]
表3
[0104][0105]
精确度也可以称为查准率,是针对预测结果中表示预测为正的样本有多少为真正的正样本,其定义如下:
[0106][0107]
召回率又被称为查全率,用来说明分类器预测结果中判定为真的正样本占总正样本的比例,其定义如下:
[0108][0109]
3)平均正确率(average precision,ap)和平均正确率均值(mean average precision,map)
[0110]
平均正确率(average precision,ap),既考虑获取较高的精确率也考虑获取较高的召回率。某一类别ap值的计算需要对检测结果设定置信度阈值和iou阈值,首先对于算法最终的预测结果按照置信度分数进行降序排列,并按照设定的置信度阈值划分正负样本,将置信度大于阈值的检测框定义为正样本,对正样本计算该置信度阈值下的精确度和召回率坐标,即精确率
‑
召回率(precision
‑
recall,pr)曲线上的一点。然后固定iou阈值,继续改变置信度阈值计算pr曲线上的其他点,从而得到变化曲线,曲线与坐标轴围成的面积即为当前iou下的ap值。
[0111]
而平均正确率均值(mean average precision,map)就是对多个类别检测好坏的结果,将所有类别的ap值取平均,计算得到的就是map的值,map的大小一定在[0,1]区间,数值越大反应模型检测效果越好。
[0112]
本实验中设置阈值iou=0.5来计算ap。由于精确度和召回率受到设置iou阈值的影响较大,在目标检测任务中不仅要衡量检测出正确目标的数量,还应该评价模型是否能以较高的精确度检测出目标,所以将map作为评价模型性能重要的指标。对模型运行速度评估上,采用每秒传输帧数(frames per second,fps)作为定量指标,该指标与硬件性能相关,因此本实验中不同模型在统一的硬件环境下进行测试。
[0113]
对比实验结果如下表4所示:
[0114]
表4
[0115]
模型recall(%)map(%)fps本发明95.293.940文献193.891.534文献292.689.738
[0116]
结果可以看出,相比于另外两篇参考文献中的模型,本发明的模型调整了网络结构以及先验框尺寸,同时引入了sca模块,进一步优化了多尺度特征融合,有效地实现了对上下文信息和浅层细节特征的结合,因此模型在召回率和map指标上表现更好,在检测速度方面,本文提出的算法能够达到40fps,是对比实验中表现效果最好的。
[0117]
最后,还需要注意的是,以上列举的仅是本发明的若干个具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1