基于联合特征选择的网络流量异常检测方法
1.本发明属于网络安全技术领域,更进一步涉及一种网络流量异常检测方法,可用于故障检测、恶意软件检测、数据外泄及恶意挖矿。
背景技术:
2.随着互联网技术的快速发展和网络规模的不断扩大,各种新技术蓬勃爆发,互联网已经成为人类生活中不可缺少的一部分,人们利用互联网进行社交、购物、工作等。但是同时,人们在享受互联网便利的过程中,不可避免地遭受网络异常的危害。目前普遍存在的多种网络异常,网络扫描,ddos攻击,网络蠕虫病毒等,都可以通过网络流量的异常表现出来,网络流量异常能较全面地反映网络的实时状况。目前,网络流量异常检测已经作为一种有效的网络安全防护手段。但是,随着网络流量数据量的增加,主流的异常检测模型的识别效率越来越低,因为这些流量数据不仅规模庞大,而且有较高的维度,流量数据中存在着大量的噪声信息和冗余信息,这些信息极大降低了异常检测的效果。对网络流量进行有效的特征选择可以有效解决这一问题,良好的特征选择算法可以高效地剔除流量数据中的噪声特征和冗余特征,提升异常检测的效率和性能。因此,选择有效且高效的特征选择算法对异常流量检测是非常重要的。
3.华北电力大学和国家电网公司在专利申请号202011313089.9,申请公开号cn 112511519 a的专利申请文献中提出“一种基于特征选择算法的网络入侵检测方法”。该方法的实施步骤是:第一步,从物联网设备中获得网络流量数据;第二步,使用qbso
‑
fs算法,对获得的网络流量数据在多种机器学习模型上的分类效果进行优化,获得优化子集;第三步,使用优化子集,利用决策策略,联合决策出新的特征子集;第四步,使用新的特征子集在复杂机器学习模型上进行分类训练,得出检测结果。该方法由于特征选择算法单一,不能剔除噪声或冗余的特征,导致检测模型的性能不佳。
4.中国科学院深圳先进技术研究院在专利申请号201911268314.9,申请公开号cn 111064721 a的专利文献中提出“网络流量异常检测模型的训练方法及检测方法”。该方法的实施步骤是:第一步,根据训练样本确定隐藏层的层数和每层隐藏层中的神经元个数;第二步,根据所述隐藏层的层数和每层隐藏层中的神经元个数构建初始的特征提取网络;第三步,利用训练样本对所述的特征提取网络进行训练,得到训练完成的特征提取网络;第四步,去除所述训练完成的特征提取网络中的分类层,得到优化的特征提取网络;第五步,利用优化的特征提取网络提取训练样本的高级抽象特征数据,训练分类网络,完成网络流量检测模型的训练。由于网络流量数据具有较高的维度,该方法采用固定阈值的方法提取特征,导致原始流量数据的部分重要特征丢失,不能快速有效地进行网络流量检测,降低了检测模型的准确率和性能。
技术实现要素:
5.本发明的目的在于针对上述现有技术的不足,提出一种基于联合特征选择的网络
流量异常检测方法,以更加准确地选择网络流量的不同特征,提高网络异常流量检测准确率和性能。
6.为实现上述目的,本发明基于联合特征选择的网络流量异常检测方法,其特征在于,包括如下:
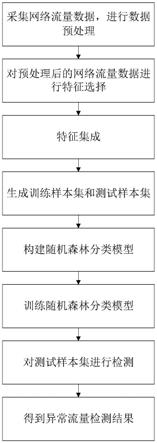
7.a)采集网络流量数据,进行数据预处理:
8.a1)从互联网网站上采集流量数据,提取能够反映流量特性的基本流量数据,包括数值型特征数据和字符型特征数据;
9.a2)对提取到的基本流量数据进行特征数据类型转换,并对转换后的数据进行标准化处理,得到预处理后的网络流量数据;
10.b)对预处理后的网络流量数据进行特征选择:
11.b1)利用基于相关性的特征选择算法和最佳优先搜索方法,从预处理后的网络流量数据中选出属性特征和类别特征相关性最大的特征序列集合m;
12.b2)利用基于互信息的特征选择算法和前向搜索方法,从预处理后的网络流量数据中选出属性特征和类别特征互信息最大的特征序列集合s;
13.c)对相关性最大的特征序列集合m与互信息最大的特征序列集合s进行特征集成,得到特征筛选集合q:
14.c1)对相关性最大的特征序列集合m按照特征重要性从高到低进行排序,将其均分为优先特征子集m1、有用特征子集m2和无用特征子集m3;
15.c2)对互信息最大的特征序列集合s按照特征重要性从高到低进行排序,将其均分为优先特征子集s1、有用特征子集s2和无用特征子集s3;
16.c3)根据c1)和c2)的结果,对两个优先特征子集m1和s1进行并操作,得到优先特征集合u;对两个有用特征子集m2和s2进行交操作,得到有用特征集合i;删除无用特征子集m3和s3;
17.c4)对优先特征集合u和有用特征集合i进行并操作,得到特征筛选集合q;
18.d)对预处理后的网络流量数据,利用特征筛选集合q进行特征筛选,随机选取70%组成训练样本集,剩下的30%组成测试样本集;
19.e)以决策树作为个体分类器,将d个决策树进行组合构成随机森林分类模型,其中5≤d≤20;
20.f)训练随机森林分类模型:
21.从训练样本集中利用自助采样方法生成d个训练样本子集,分别对d个训练样本子集,选择其基尼指数最小的特征进行分裂,对获得的特征,重复上述操作,直到分裂停止时结束,得到d个训练好的决策树,输出d个分类结果;
22.对d个分类结果利用多数投票法得到最终的检测结果,即构成训练好的随机森林分类模型;
23.g)将测试样本集中的数据输入已经训练好的随机森林分类模型中,得到流量异常检测的检测结果。
24.本发明与现有技术相比,具有以下优点:
25.第一:本发明由于利用基于相关性特征选择算法和基于互信息特征选择算法分别提取网络流量数据的重要特征,减少了数据处理的时间和空间资源的消耗,降低了数据维
度,剔除了噪声特征和冗余特征,保证了提取的特征的准确性;
26.第二:本发明由于对相关性最大的特征序列集合和互信息最大的特征序列集合,按照特征重要性排序并分为六个特征子集,并分别对其进行了并或交操作,使最终选择的特征集合对流量数据的表征更准确,提升模型检测结果的准确率;
27.第三:本发明由于采用决策树作为个体分类器构成随机森林分类模型,运算复杂度低,速度快,有效减少了模型检测的时间,提升了模型检测的效率。
附图说明
28.图1为本发明的实现流程图;
29.图2为随机森林分类模型图。
具体实施方式
30.下面结合附图对本发明的实施例和效果做进一步详细的描述。
31.参照图1,本实施例的实施包括如下步骤:
32.步骤1,采集网络流量数据,进行数据预处理。
33.1.1)从互联网网站上采集流量数据,提取能够反映流量特性的基本流量数据,包括数值型特征数据和字符型特征数据;
34.1.2)对提取到的基本流量数据进行特征数据类型转换:
35.本实例采取但不限于用独热编码技术,将基本流量数据中的字符型特征转换成数值型特征,比如将有4个取值的类别特征转换为(1,0,0,0)、(0,1,0,0)、(0,0,1,0)、(0,0,0,1);
36.1.3)对转换后的数据进行标准化处理,得到预处理后的网络流量数据:
[0037][0038]
其中,x'
i
代表第i个特征标准化后的值,x
i
代表第i个特征标准化前的值,min(x(i))代表第i个特征中的最小值,max(x(i))代表第i个特征中的最大值。
[0039]
该网络流量数据中含有属性特征和类别特征,其中属性特征包括:tcp连接基本特征、tcp连接内容特征、基于时间的网络流量统计特征和基于主机的网络流量统计特征。
[0040]
步骤2,对预处理后的网络流量数据进行特征选择。
[0041]
2.1)利用基于相关性的特征选择算法和最佳优先搜索方法,从预处理后的网络流量数据中选出属性特征和类别特征相关性最大的特征序列集合m:
[0042]
2.1.1)利用初始的属性特征集合f={f1,f2,
…
f
i
,
…
,f
j
,
…
,f
n
},计算第i个属性特征f
i
分别与第j个属性特征f
j
的相关系数和与类别特征c的相关系数
[0043][0044]
[0045]
其中,n为属性特征的数量,f'
i
为第i个属性特征的值,f'
j
为第j个属性特征的值,c'为类别特征的值;
[0046]
2.1.2)利用上述两个相关系数和分别计算第i个属性特征f
i
与第j个属性特征f
j
的平均相关度和与类别特征c的平均相关度
[0047][0048][0049]
其中,k代表集合m中的特征个数;
[0050]
2.1.3)利用上述两个平均相关度和计算集合m的启发式估计值m
s
:
[0051][0052]
其中,m
s
为集合m的启发式估计值;
[0053]
2.1.4)选择启发式估计值最大的一个特征加入集合m,随后选择启发式估计值次大的特征加入集合m,重复步骤2.1.1)至2.1.3),计算出新的启发式估计值m'
s
;
[0054]
2.1.5)将新的启发式估计值m'
s
与原来的启发式估计值m
s
进行比较:
[0055]
如果m'
s
<m
s
则去除这个启发式估计值次大的特征,然后再选择下一个,直到特征被选择完,得到属性特征和类别特征相关性最大的特征序列集合m;
[0056]
否则,保留此启发式估计值次大的特征,返回2.1.1);
[0057]
2.2)利用基于互信息的特征选择算法和前向搜索方法,从预处理后的网络流量数据中选出属性特征和类别特征互信息最大的特征序列集合s:
[0058]
2.2.1)利用初始的候选属性特征集合g={g1,g2,
…
,g
i
,
…
,g
n
},计算属性特征集合g中每个属性特征和类别特征c的互信息i(g;c):
[0059][0060]
其中,p(g
i
,c)表示第i个属性特征g
i
和类别特征c的联合概率密度函数,p(g
i
)和p(c)分别表示第i个属性特征g
i
和类别特征c的边缘概率密度函数;
[0061]
2.2.2)利用上述互信息i(g;c),计算已选属性特征集合s与类别特征c之间的互信息i(s;c):
[0062]
i(s;c)=i(g;c)
‑
∑{i(g;s)
‑
i(g;s|c)},
[0063]
其中,i(g;s)代表候选属性特征集合g和已选属性特征集合s之间的互信息,i(f;s|c)代表给定类别特征c条件下,候选属性特征集合g和已选属性特征集合s之间的互信息;
[0064]
2.2.3)将互信息i(s;c)最高的属性特征放入已选属性特征集合s中,并从候选属性特征集合g中删除此属性特征,重复2.2.1)至2.2.2),直到候选属性特征集合g中的特征被删除完,得到属性特征和类别特征互信息最大的特征序列集合s。
[0065]
步骤3,对相关性最大的特征序列集合m与互信息最大的特征序列集合s进行特征集成,得到特征筛选集合q。
[0066]
3.1)对相关性最大的特征序列集合m按照特征重要性从高到低进行排序,将其均分为优先特征子集m1、有用特征子集m2和无用特征子集m3;
[0067]
3.2)对互信息最大的特征序列集合s按照特征重要性从高到低进行排序,将其均分为优先特征子集s1、有用特征子集s2和无用特征子集s3;
[0068]
3.3)根据3.1)和3.2)的结果,对两个优先特征子集m1和s1进行并操作,即将两个优先特征子集中所有的特征进行组合,得到优先特征集合u;
[0069]
3.4)根据3.1)和3.2)的结果,对两个有用特征子集m2和s2进行交操作,即将两个有用特征子集中共有的特征进行组合,得到有用特征集合i,并删除无用特征子集m3和s3;
[0070]
3.5)根据3.3)和3.4)的结果,对优先特征集合u和有用特征集合i进行并操作,即将优先特征集合u和有用特征集合i中所有的特征进行组合,得到特征筛选集合q。
[0071]
步骤4,对预处理后的网络流量数据,利用特征筛选集合q进行特征筛选,随机选取70%组成训练样本集,剩下的30%组成测试样本集。
[0072]
步骤5,以决策树作为个体分类器,将d个决策树进行组合构成随机森林分类模型,其中5≤d≤20,本实例采取d=10。
[0073]
所述个体分类器不限于决策树,还可以采用信息增益最大的id3分类器,信息增益比最大的c4.5分类器。
[0074]
步骤6,训练随机森林分类模型。
[0075]
参照图2,本步骤通过训练构成训练好的随机森林分类模型,其包括从训练样本集中生成d个训练样本子集;分别训练d个决策树,输出d个分类结果;对d个分类结果利用多数投票法得到最终的检测结果这三部分,具体实现如下:
[0076]
6.1)利用自助采样方法从训练样本集中生成d个训练样本子集{d1,d2,
…
d
i
,
…
,d
d
},其中d
i
是第i个训练样本子集,i∈(1,d);
[0077]
6.2)分别利用d个训练样本子集,训练d个决策树:
[0078]
6.2.1)输入训练样本子集d
i
,从训练样本子集的所有属性特征中随机选择m个属性特征构成特征子集,其中1≤m≤41,本实例采取m=20;
[0079]
6.2.2)计算特征子集中每个特征可能取值的基尼指数gini_index(d
i
,a):
[0080][0081]
其中,a是对训练样本子集d
i
进行划分的特征,a有v个可能取值{a1,a2,
…
,a
i
,
…
,a
v
},d
iv
即是第v个子节点所包含的样本集,gini(d
iv
)是第v个子节点所包含的样本集的基尼值:
[0082][0083]
其中,p
k
是第k类样本在第v个子节点所包含的样本集d
iv
中所占的比例,k=1,2,
…
,|y|,y是样本类别的总数;
[0084]
6.2.3)选择具有最小基尼指数的特征进行分裂;
[0085]
6.2.4)对获得的特征,重复6.2.2)和6.2.3),直到分裂停止时结束,得到一个训练好的决策树,输出一个分类结果;
[0086]
6.3)重复6.2.1)至6.2.4)共d次,得到d个训练好的决策树,对应d个分类结果;
[0087]
6.4)对d个分类结果,利用多数投票法得到最终的检测结果,即构成训练好的随机森林分类模型。
[0088]
步骤7,将测试样本集中的数据输入已经训练好的随机森林分类模型中,得到流量异常检测的检测结果。
[0089]
下面结合仿真实验,对本发明的效果做进一步的说明。
[0090]
1.仿真实验条件:
[0091]
本发明的仿真实验运行环境是:处理器为interl(r)core(tm)i5
‑
5200 cpu@2.20ghz,内存为4.00gb,硬盘为457g,操作系统为windows 8.1,编程环境为python 3.8,编程软件为pycharm edition 2020.1.2x64。
[0092]
本发明采用nsl
‑
kdd数据集,是公认的网络流量数据集,为构建检测模型提供了数据基准,其中包括41个属性特征字段和1个类别特征字段。
[0093]
2.仿真内容及其结果分析:
[0094]
仿真实验:用本发明与现有3种差异化方法对nsl
‑
kdd数据集的异常情况进行检测,对比其检测准确率和检测时间,结果如表1:
[0095]
现有差异化方法有以下3种:
[0096]
1、使用全部特征进行检测,不进行特征选择处理。
[0097]
2、单独使用基于相关性的特征选择算法。
[0098]
3、单独使用基于互信息的特征选择算法。
[0099]
表1各差异化方法的准确率和检测时间
[0100]
差异化方法准确率(%)检测时间(s)不进行特征选择70.564利用基于相关性的特征选择算法78.173利用基于互信息的特征选择算法78.903本发明方法82.591.5
[0101]
表中的准确率是利用不同检测方法对nsl
‑
kdd数据集进行分类异常检测,通过得到各自被正确划分为正常的样本数tp、被错误划分为正常的样本数fp、被错误划分为异常的样本数fn、被正确划分为异常的样本数tn,计算得到其各自的准确率为
[0102]
表中检测时间是指利用python语言的time.clock()函数对不同检测方法的开始检测时间starttime及检测结束时间endtime进行记录,计算得到不同检测方法的检测时间为:检测结束时间endtime减开始检测时间starttime。
[0103]
由表1可以看出,现有3种差异化方法进行网络流量异常检测的准确率低,本发明方法较高,且本发明的检测时间均比3种差异化方法的检测时间短。表明本发明方法的采用决策树作为个体分类器构建随机森林分类模型,节省了时间消耗,检测的效率高于现有的差异化方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1