基于改进拉丁超立方抽样的虚拟驾驶场景要素重组方法与流程
1.本发明涉及智能驾驶测试场景用例的编制,具体涉及一种基于改进拉丁超立方抽样的虚拟驾驶测试场景要素重组方法,用于汽车智能驾驶系统的测试和评价。
背景技术:
2.近年来,伴随着汽车智能驾驶系统的不断发展,为保证其安全性和合规性的测试也越发重要,汽车在上市之前必须经过充分的测试与验证,以保证智能控制系统在其设计运行域内可以安全地运行。
3.虚拟仿真测试相对于场地测试和道路测试,具有高效性和安全性,是一种重要的测试方法和手段。搭建能够反映真实交通特点的虚拟场景是仿真测试的基础,备受研究人员重视。搭建虚拟场景的一种重要方法,是基于真实交通数据,进行场景关键要素的分析和统计,然后根据场景要素的概率特性进行不同维度要素的采样和重组,获得与真实交通场景及其相近的随机测试样本。
4.数据重采样的场景方法是蒙特卡洛采样算法,如m
‑
h采样和gibbs采样。然而传统的蒙特卡洛采样算法需要进行大量的模拟实验才能获得效果较好的样本,在原始数据存在较多大概率样本时,容易发生聚集现象。而拉丁超立方采样是作为一种典型的分层抽样方法,基于累计概率分布进行抽样,可以通过较少的迭代次数获得效果更佳的随机样本集。
5.根据《latin hypercube sampling techniques for power systems reliability analysis with renewable energy sources》、《基于改进核密度估计和拉丁超立方抽样的电动汽车负荷模型》、《基于改进拉丁超立方抽样的概率潮流计算》等研究成果,拉丁超立方采样一般包含样本生成和相关性控制两个步骤。样本生成的基础一般是进行随机要素的概率建模,但是实际工程应用中,随机要素的分布一般很难符合典型的分布函数特征,而如果使用非参数估计建立概率密度函数则难以获得其累计概率分布的反函数,同时当原始数据既包含连续要素也包含离散要素时,概率分布的建立也会遇到困难。而在相关性控制方面,《a distribution
‑
free approach to inducing rank correlation among input variables》提出了cholesky分解法,通过矩阵计算可以大大提高计算效率,是一种相对成熟的重要方法。
6.综上,如何基于实际数据进行样本生成是拉丁超立方采样的关键基础。
技术实现要素:
7.针对现有拉丁超立方采样无法有效的基于原始数据进行样本生成的问题,本发明基于非参数估计的思想,提出一种基于改进拉丁超立方抽样方法进行的虚拟驾驶场景要素重组方法。
8.本发明所采用的技术方案如下:一种基于改进拉丁超立方抽样的虚拟驾驶场景要素重组方法,基于原始数据,所述原始数据中包括有离散要素和连续要素,其特征在于,包括如下步骤:
9.1)统计原始数据中所有离散要素组合;
10.2)确定抽样的离散要素组合在累计概率分布中的采样点位置;
11.3)确定抽样的离散要素组合属性;
12.4)确定各离散要素组合的抽样次数;
13.5)从每种离散要素组合对应的原始数据中提取连续要素;
14.6)计算连续要素的累计概率分布;
15.7)根据离散要素组合的抽样次数,确定抽样的连续要素在累计概率分布中的采样点位置;
16.8)确定连续要素值;
17.9)连续要素相关性控制;
18.10)全部抽样的离散要素和连续要素重组,构成虚拟驾驶场景数据;
19.其中,步骤1)中,包括统计所有离散要素组合的相对概率和累计概率分布;
20.其中,步骤2)和步骤3)中,基于式(1)计算抽样的离散要素组合在累计概率分布中的采样点位置:
[0021][0022]
p
s
代表第s组抽样数据中离散要素组合对应的累计概率,
[0023]
当0<p
s
≤p(d1)时,确定p
s
对应的离散要素组合归属为d1,
[0024]
当p(d
i
)<p
s
≤p(d
i+1
)时,确定p
s
对应的离散要素组合归属为d
i+1
,
[0025]
d
i
表示第i组离散要素组合;
[0026]
其中,步骤7)和步骤8)中,同样基于式(1)计算抽样的连续要素在累计概率分布中的采样点位置,然后根据步骤6)计算的累计概率分布,分别在小于所述累计概率的范围内和在大于所述累计概率的范围内各取最接近的5个样本点,然后通过三次样条插值法计算对应的连续要素的值。
[0027]
进一步地,在步骤4)中,根据离散要素组合属性和概率统计,确定各离散要素组合的抽样次数。
[0028]
进一步地,在步骤6)中,以离散要素组合分类为基础统计连续要素的累计概率分布,方法如下:
[0029]
从某种离散要素组合对应的原始数据中,提取第k种连续要素数据,构成样本集c
1k
;然后将样本集c
1k
中的连续要素按照值升序进行排序,并去除重复的值,再次获得样本集c
1k
‑
unique
;
[0030]
分析c
1k
‑
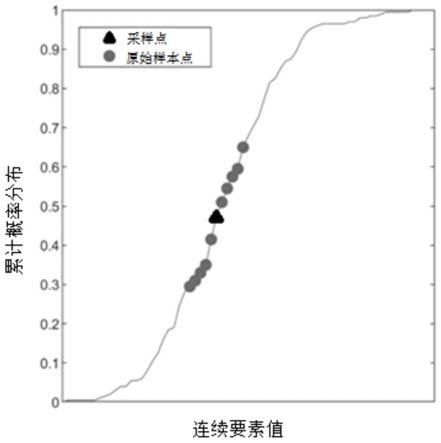
unique
中相邻值的间隔,如果某相邻值的间隔大于所有间隔的平均值,则在该相邻值区间内插入一个新的样本点,再次获得新样本集c
1k
‑
unique’,在新样本集中所有相邻值的间隔均小于平均间隔;
[0031]
基于c
1k
‑
unique’,统计第k种连续要素的所有值在c
1k
中出现的次数,获得其相对概率分布,再根据相对概率分布获得其累计概率分布p
c1k
。
[0032]
进一步地,在步骤7)中,如果小于所述累计概率的范围内,或者大于所述累计概率的范围内的样本点不超过5个,则全部提取。
[0033]
进一步地,在步骤9)中,对每种离散要素组合对应的所有连续要素,构成抽样矩阵
c
1s
,采用cholesky分解法进行相关性控制,
[0034]
首先,随机生成一个与c
1s
同样行列数的顺序矩阵r,r的每一列由整数随机排列而成;然后计算r的spearman相关系数矩阵cm
r
,并进行cholesky分解,获得分解后的下三角矩阵q,如式(2)所示;
[0035]
然后,对c
1s
的spearman相关系数矩阵cm
in
同样进行cholesky分解,获得下三角矩阵p,然后根据式(3)计算输出顺序矩阵g,并使c
1s
中每一列的数据按照g的每一列数据的顺序进行重新排序,重新排序后的c
1s’即为得到控制后的数据,
[0036]
cm
r
=q*q
t
ꢀꢀ
(2)
[0037]
g=p*q
‑1*r
ꢀꢀ
(3)。
[0038]
本发明采用改进的拉丁超立方抽样方法进行虚拟驾驶场景要素重组,在该方法中,以离散要素的组合情况为基础进行连续要素的概率分布统计;通过连续要素的插值保证有效跳出数据缺失区域;基于三次样条插值法根据概率密度确定采样点位置,在复现原始概率概率分布函数特征的基础上,通过采用cholesky分解法保证要素之间的相关性,在保证采样有效性的前提下大大提高了计算效率。本发明基于真实的数据,对场景关键要素进行分析和统计,然后根据场景要素的概率特性进行不同维度要素的采样和重组,获得与真实交通场景概率分布相近的随机测试样本,鲁棒性好,非常适用于汽车智能驾驶系统的测试和评价。
附图说明
[0039]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制。
[0040]
图1为本发明实施例的离散要素组合的相对概率分布图;
[0041]
图2为本发明实施例的离散要素组合的累计概率分布图;
[0042]
图3为本发明实施例的离散要素组合在累计概率分布中的采样点位置图;
[0043]
图4为本发明实施例的连续要素在累计概率分布中的采样点位置图。
具体实施方式
[0044]
下面通过附图和实施例对本发明技术方案进一步说明。
[0045]
以邻车切入工况为例,假设采集的邻车切入场景原始数据共有1000组,每组数据中都包含有5种要素,借用矩阵x
m*n
表示,则m=1000就代表数据的组数(矩阵的行),n=5就代表要素的种类数(矩阵的列)。
[0046]
在这个实施例中,假设这5种要素中有2种为离散要素,位于矩阵的前两列,分别是天气和道路等级,具体的要素值用表示;其余3种要素为连续要素,位于矩阵的后3列,分别是邻车切入时刻的主车速度、目标车速度和相对纵向距离,具体的要素值用表示。
[0047]
假设预从这1000组原始数据中随机抽取100组数据重组,以构建典型虚拟驾驶场景,本发明采用改进拉丁超立方采样的要素重组方法,其中包括以下步骤:
[0048]
1)统计离散要素组合的步骤
[0049]
这一步就是统计原始数据中所有的离散要素组合形式,然后计算这些离散要素组合的相对概率和累计概率。方法为:
[0050]
首先基于原始数据,取出全部离散要素构成样本集,统计所有出现的不同离散要
素组合形式,假设统计出共存在有[d1=(雨天,高速公路),d2=(晴朗,高速公路),d3=(晴朗,城市道路)]三种离散要素组合类型;
[0051]
然后统计不同离散要素组合在原始数据中出现的次数,获得其相对概率分布,假设经统计上述三种离散要素组合的相对概率分布为[p(d1)=0.2,p(d2)=0.5,p(d3)=0.3],如图1所示;
[0052]
则再基于相对概率分布计算累计概率分布,上述三种离散要素组合的累计概率分布为[p(d1)=0.2,p(d2)=0.7,p(d3)=1],如图2所示。
[0053]
2)确定离散要素组合采样点的步骤
[0054]
这一步就是确定离散要素组合在累计概率分布中的采样点位置。根据预设采样数,从1000组原始数据中随机抽取出100组数据,对这100组数据中的离散要素组合确定其在累计概率分布中的采样点位置。
[0055]
基于式(1)确定每种离散要素组合在累计概率分布中的采样点位置,如图3所示:
[0056][0057]
其中,p
s
代表第s组抽样数据中的离散要素组合对应的累计概率,1≤s≤抽样数,本实施例中抽样数是100。
[0058]
3)确定离散要素组合属性的步骤
[0059]
根据每组数据中离散要素组合在累计概率分布中的采样点位置(p
s
决定),确定每种离散要素组合的属性,对于p(d
i
)<p
s
≤p(d
i+1
)的采样点(1≤i≤2),确定p
s
对应的离散要素组合应归属为d
i+1
,对于0<p
s
≤p(d1)的采样点,确定p
s
对应的离散要素组合应归属为d1。
[0060]
4)确定离散要素组合采样次数的步骤
[0061]
根据上一步确定的离散要素组合属性,经过统计,确定每种离散要素组合的采样次数。上述100组数据中,d1的采样次数为20次,d2的采样次数为50次,d3的采样次数为30次,记为[sn1=20,sn2=50,sn3=30]。
[0062]
5)连续要素提取的步骤
[0063]
这一步是从每一组离散要素对应的原始数据中提取出全部相关的连续要素。以离散要素组合d1为例,从d1对应的原始数据中取出全部连续要素,构成样本集c1,按照相对概率,d1对应的原始数据共有200组,c1的连续要素数据也就有200组,以此作为连续要素采样的基础数据。
[0064]
6)连续要素累计概率计算的步骤
[0065]
从c1中抽取第k种连续要素数据(例如主车速度),构成样本集,记为c
1k
,c
1k
也是200组原始数据(按照本实施例,连续要素种类有三种,所以k取三个值分别标记)。将第k种连续要素样本集c
1k
中的连续要素值按照升序进行排序,并去除重复的值,再次获得样本集c
1k
‑
unique
。为使采样算法可以有效处理数据分散分布的情况,分析c
1k
‑
unique
中相邻值的间隔,如果某相邻值的间隔大于所有间隔的平均值,则在该相邻值区间内插入一个新的样本点,使新产生的c
1k
‑
unique’中任一相邻值的间隔均小于平均间隔就行。基于最终的c
1k
‑
unique’,统计第k种连续要素的所有值在c
1k
中出现的次数,获得其相对概率分布,再根据相对概率分布获得其累计概率分布p
c1k
。
[0066]
7)确定连续要素采样点的步骤
[0067]
按照前述离散要素组合的100组抽样数据,离散要素组合d1的采样次数是sn1=20,所以第k种连续要素对应的采样次数也应该是20次。
[0068]
在这些抽样数据中,同样基于式(1)的方式确定连续要素在累计概率分布中的采样点位置。对于计算的某一采样点的累计概率p
sk
:
[0069]
抽样数=20
[0070]
根据连续要素样本集c
1k
的累计概率分布p
c1k
,在[p
c1k
<p
sk
]的范围内查找累计概率分布与p
sk
最接近的c
1k
‑
unique
中的5个样本点(5个是自定义数量,也可以取其他数量),如果不足5个样本点,则选取满足条件的全部样本点;
[0071]
同理,在[p
c1k
≥p
sk
]的范围内查找累计概率分布与p
sk
最接近的c
1k
‑
unique
中的5个样本点,如果不足5个样本点,则选取满足条件的全部样本点。
[0072]
8)确定连续要素值的步骤
[0073]
根据查找到的10个样本点(不足10个则为全部),及其累计概率分布,通过三次样条插值法计算p
sk
对应的连续要素的值,如图4所示。
[0074]
基于上述6)~8)步,分别计算出c1的抽样数据(20组)中三种连续要素的所有值。
[0075]
9)连续要素相关性控制的步骤
[0076]
如上实施例,对c1中三种连续要素抽样数据构成抽样矩阵c
1s
(20行3列),采用cholesky分解法进行相关性控制。
[0077]
首先,随机生成20行3列的一个顺序矩阵r,r的每一列由[1,20]的整数随机排列而成;然后计算r的spearman相关系数矩阵cm
r
,并进行cholesky分解,获得分解后的下三角矩阵q,如式(2)所示。
[0078]
然后,对c
1s
的spearman相关系数矩阵cm
in
同样进行cholesky分解,获得下三角矩阵p,然后根据式(3)计算输出顺序矩阵g,并使c
1s
中每一列的数据按照g的每一列数据的顺序进行重新排序,重新排序后的c
1s’即为得到控制后的场景要素数据。
[0079]
cm
r
=q*q
t
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0080]
g=p*q
‑1*r
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0081]
c1和c
1s
的spearman相关系数矩阵分别如表1和表2所示,可见相关性较强的要素在经过采样和重组后,相关性保持的效果较好。
[0082]
表1原始数据相关系数矩阵
[0083] 主车速度目标车速度切入时间主车速度10.90010.1752目标车速度0.90011
‑
0.0134切入时间0.1752
‑
0.01341
[0084]
表2重组数据相关系数矩阵
[0085] 主车速度目标车速度切入时间主车速度10.86790.2049目标车速度0.90011
‑
0.0626切入时间0.2049
‑
0.06261
[0086]
以上仅是基于离散要素组合d1对连续要素进行相关性控制,对于离散要素组合d2、
d3也同样采用步骤5)~8)的过程对连续要素进行相关性控制。
[0087]
10)全部要素重组的步骤
[0088]
最后,基于获得的所有离散要素和连续要素的抽样数据,整合起来,就获得100组既包含有离散要素又包含有连续要素的数据样本。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1