1.本发明涉及深度学习训练方法技术领域,更具体地,涉及一种实时生成对抗样本的深度学习训练数据增广、装置、电子设备及介质。
背景技术:2.在深度学习模型训练中,由于带标注的训练数据获取不易,常见的作法是对训练数据进行缩放、旋转、裁剪、加噪声、投影变换、叠加等方式处理后,充实到训练集中。这些常见的充实训练集的操作称为数据增广。数据增广是为了利用有限的训练数据,让模型尽可能学习到与位置、角度、噪声无关的图中物体本身的视觉特征。
3.上述常见的数据增广方法虽然可以利用有限的带标注图片生成大量的训练数据,但其存在几个缺点。
4.一是这些数据增广方法无法模拟实际使用中可能出现的图像扭曲模糊等情况。使得模型在训练和实际使用中面对的图像存在差异。这也是过拟合现象产生的原因之一,所谓过拟合现象,是指模型在训练集上能够达到较高的训练准确度,但在实际使用中准确度无法达到要求。例如,如果一个模型在训练中只应用了高斯噪声、椒盐噪声作为数据增广方式,当它在应用中遇到视频编解码带来的画面失真时,就会产生严重的准确性下降。
5.二是由于深度学习模型的黑盒特性,模型训练者并不能完全了解模型学习到的特征。常见的数据增广方法是随机选取一种或几种图片处理算法,处理图片后送入训练,无法针对模型的弱点针对性的生成训练图片。在训练过程中,传统图像增广方法与模型训练是完全没有交互的。举个简单的例子,当一个模型已经完全能够应对图像缩放,却还没有充分学习到图像的旋转不变性时,传统数据增广方法无法探测到模型的这种特性,仍然是均匀的应用各种增广方式来处理训练图片。
6.三是深度学习模型在训练中,由于其参数空间维度极高,会在有限的训练数据上收敛到局部最优。局部最优点有个明显的特点,就是对输入的扰动极为敏感,输入图片上极小的变化(小到人眼无法感知)就会导致模型输出产生非常大的改变。而传统的数据增广方法是有限种图片处理方法的组合,无法覆盖到所有的图片扰动情况,这也就使得传统数据增广方法总会使模型收敛到局部最优,导致模型不够鲁棒。以ocr模型为例子,在论文《fooling ocr systems with adversarial text images》、《what machines see is not what they get:fooling scene text recognition models with adversarial text images》中已经就这种微扰攻击带来的识别错误问题进行过讨论。
7.针对以上缺点,已经出现了一些技术试图解决问题。
8.生成式对抗网络(gan)是一种利用深度学习网络来生成图片的技术,这种技术通过在训练中引入对抗手段,来让模型生成特定风格的图片。这种技术可以用于数据增广,利用网络生成的虚假图片扩充训练集,部分程度上可以缓解训练集不足的问题。但生成式对抗网络本身并不是用于数据增广的技术,它生成的图片用于训练其他模型,也无法保证被
训练的模型收敛到它的局部最优。
9.公开日为2020年06月26日,公开号为cn111340180a的中国专利公开了指定标签的对抗样本生成方法、装置、电子设备及介质,方法包括:将原始图像样本输入预设多标签分类网络,得到用于对原始图像样本进行多标签分类的各个标签的预测分数值;从各个标签的预测分数值中抽取指定标签对应的预测分数值;根据指定标签对应的预测分数值,采用动量快速梯度迭代mi fgsm方法生成第一攻击扰动;利用梯度权值类别响应图grad cam方法对第一攻击扰动进行裁剪,得到第二攻击扰动;将第二攻击扰动叠加到所述原始图像样本上,生成与所述指定标签对应的对抗样本。但其缺点是,这种方法生成的对抗样本是针对一个已经训练好的网络的,且其算法复杂性较高,无法与模型训练过程结合在一起,也无法在训练中动态的根据变化的网络参数,不断的针对性的生成对抗样本,因此应用范围有限。
技术实现要素:10.本发明的首要目的是提供一种实时生成对抗样本的深度学习训练数据增广方法,根据模型当前训练阶段实时针对性地生成对抗样本以训练深度学习网络,使模型鲁棒性提高。
11.本发明的进一步目的是提供一种实时生成对抗样本的深度学习训练数据增广装置。
12.本发明的第三个目的是提供一种电子设备和一种计算机可读介质。
13.为解决上述技术问题,本发明的技术方案如下:
14.一种实时生成对抗样本的深度学习训练数据增广方法,包括以下步骤:
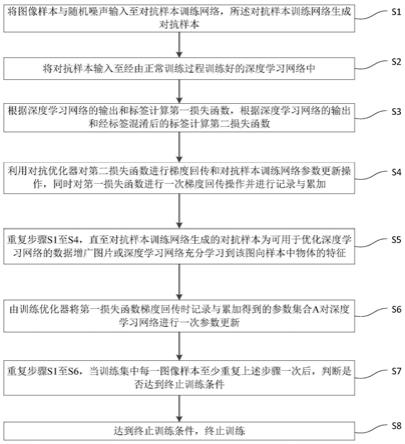
15.s1:将图像样本与随机噪声输入至对抗样本训练网络,所述对抗样本训练网络生成对抗样本;
16.s2:将对抗样本输入至经由正常训练过程训练好的深度学习网络中;
17.s3:根据深度学习网络的输出和标签计算第一损失函数,根据深度学习网络的输出和经标签混淆后的标签计算第二损失函数;
18.s4:利用对抗优化器对第二损失函数进行梯度回传和对抗样本训练网络参数更新操作,同时对第一损失函数进行一次梯度回传操作并进行记录与累加;
19.s5:重复步骤s1至s4,直至对抗样本训练网络生成的对抗样本为可用于优化深度学习网络的数据增广图片或深度学习网络充分学习到该图像样本中物体的特征;
20.s6:由训练优化器将第一损失函数梯度回传时记录与累加得到的参数集合a对深度学习网络进行一次参数更新;
21.s7:重复步骤s1至s6,当训练集中每一图像样本至少重复上述步骤一次后,判断是否达到终止训练条件;
22.s8:达到终止训练条件,终止训练。
23.优选地,所述对抗样本训练网络设置于所述深度学习网络的输入层前面,为一个对抗参数层,所述对抗参数层的形状为b x h x w x c,其中b为训练的一个批次的图像数量,h与w对应输入的训练图像的高和宽,c为输入图像的通道数,在所述对抗参数层中,输入图像首先与对抗参数层参数相加,输出截取0至255的值,再经过归一化,转为浮点数后输出,此时对抗参数层的参数集合为g。
24.优选地,步骤s3中根据深度学习网络的输出和经标签混淆后的标签计算第二损失函数中,根据深度学习网络的训练任务不同,标签混淆的操作方法包括:
25.对于单分类任务可以将one
‑
hot做随机循环移位操作;
26.对于多分类任务可以直接对multi
‑
hot向量取反,或者全部置零;
27.对于分割任务可以将标签掩码置零,或者做随机类别变换;
28.对于文本识别任务可以将其中的字符变成形状相似的字符。
29.优选地,所述步骤s4中优化对抗器采用sgd并配以0动量。
30.优选地,步骤s5中直至对抗样本训练网络生成的对抗样本为可用于优化深度学习网络的数据增广图片或深度学习网络充分学习到该图像样本中物体的特征,具体为:
31.若原始图像经过对抗样本训练网络后生成的对抗样本,经过深度学习网络以后被误识别为经标签混淆后的标签,则表示生成的对抗样本为可用于优化深度学习网络的数据增广图片;
32.若重复了一定次数以后,第二损失函数不再发生显著变化,,则表示深度学习网络充分学习到该图像样本中物体的特征。
33.优选地,所述步骤s7中训练集中每一图像样本至少重复上述步骤一次,应使简单样本出现的概率小,而难样本出现的概率大,所述简单样本指经过网络前向后,输出的结果极为接近标签,对网络训练起不到较大作用的样本,所述难样本为经过数个周期的训练后,网络仍然不能很好识别的样本。
34.优选地,所述步骤s7中终止训练条件,具体包括:
35.损失函数长时间不降低;
36.验证集准确率长时间无明显提升;
37.设定固定的数个周期以后停止;
38.每个周期结束时,对验证集中的每张图像做一次对抗扰动和识别,统计其中简单样本的比例,当简单样本比例达到指定条件时,终止训练;
39.验证集中的样本对抗后输出到屏幕显示,当人工观察发现对抗样本在人看来无法识别时,终止训练。
40.一种实时生成对抗样本的深度学习训练数据增广装置,包括:
41.对抗样本生成模块,所述输入模块用于将图像样本与随机噪声输入至对抗样本训练网络,所述对抗样本训练网络生成对抗样本;
42.输入模块,所述输入模块用于将对抗样本输入至经由正常训练过程训练好的深度学习网络中;
43.损失函数计算模块,所述损失函数计算模块根据深度学习网络的输出和标签计算第一损失函数,根据深度学习网络的输出和经标签混淆后的标签计算第二损失函数;
44.梯度回传模块,所述梯度回传模块利用对抗优化器对第二损失函数进行梯度回传和对抗样本训练网络参数更新操作,同时对第一损失函数进行一次梯度回传操作并进行记录与累加;
45.第一循环模块,所述第一循环模块用于将同一批次的图像样本重复经上述模块处理,直至对抗样本训练网络生成的对抗样本为可用于优化深度学习网络的数据增广图片或深度学习网络充分学习到该图像样本中物体的特征;
46.深度学习网络参数更新模块,所述深度学习网络参数更新模块由训练优化器将第一损失函数梯度回传时记录与累加得到的参数集合a对深度学习网络进行一次参数更新;
47.第二循环模块,所述第二循环模块用于将训练集中每一图像样本至少重复经上述模块处理一次后,判断是否达到终止训练条件;
48.终止模块,所述终止模块用于在达到终止训练条件时,终止训练。
49.一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行以实现如上述所述的方法。
50.一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现如上述所述的方法。
51.与现有技术相比,本发明技术方案的有益效果是:
52.本发明使用网络梯度回传修改输入图片,生成对抗样本,并实时用生成的对抗样本来训练深度学习网络;使用两个优化器,在训练中分别对对抗样本训练网络和深度学习网络参数进行优化,以达到一次循环迭代中就可以同时优化对抗参数和网络参数的效果,加速了对抗与训练,只需要在原有的网络结构的基础上,增加一个对抗参数层,一个损失函数,以及一个优化器即可;有效提升训练出来的深度学习模型鲁棒性,提升模型在实际应用时的精度和召回,能有效避免模型在未知数据上出现的不可解释的误判现象。本发明占用的额外资源较少,只需要多占用约20%的显存,以及减慢大约50%的训练速度,与其他将对抗样本生成与模型训练分开的方案相比,有效的节省了资源。
附图说明
53.图1为本发明的方法流程示意图。
54.图2为本发明的方法训练结构图。
55.图3为实施例中使用本方法经过数次对抗调整后的随机图片示意图。
56.图4为实施例中识别例子的示意图。
57.图5为本发明的装置示意图。
具体实施方式
58.附图仅用于示例性说明,不能理解为对本专利的限制;
59.为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
60.对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
61.下面结合附图和实施例对本发明的技术方案做进一步的说明。
62.实施例1
63.本实施例提供一种实时生成对抗样本的深度学习训练数据增广方法,如图1和图2所示,包括以下步骤:
64.s1:将图像样本与随机噪声输入至对抗样本训练网络,所述对抗样本训练网络生成对抗样本;
65.s2:将对抗样本输入至经由正常训练过程训练好的深度学习网络中;
66.s3:根据深度学习网络的输出和标签计算第一损失函数,根据深度学习网络的输出和经标签混淆后的标签计算第二损失函数;
67.s4:利用对抗优化器对第二损失函数进行梯度回传和对抗样本训练网络参数更新操作,同时对第一损失函数进行一次梯度回传操作并进行记录与累加;
68.s5:重复步骤s1至s4,直至对抗样本训练网络生成的对抗样本为可用于优化深度学习网络的数据增广图片或深度学习网络充分学习到该图像样本中物体的特征;
69.s6:由训练优化器将第一损失函数梯度回传时记录与累加得到的参数集合a对深度学习网络进行一次参数更新;
70.s7:重复步骤s1至s6,当训练集中每一图像样本至少重复上述步骤一次后,判断是否达到终止训练条件;
71.s8:达到终止训练条件,终止训练。
72.步骤s1至s4为对抗阶段,对抗阶段包括数次前向与后向操作。在对抗阶段开始时,将对抗样本训练网络全部清零,以及网络中所有梯度全部清零。然后读入一个批次的原始训练图片,送入网络进行一次前向操作,分别计算步骤s4中的两个损失函数得到结果。此时对抗优化器对标签混淆后的第二损失函数进行一次梯度回传与参数更新操作。在梯度回传时将网络设置为只更新对抗样本训练网络的梯度,而网络参数的梯度则不记录(常见的pytorch和tensorflow框架均有api可以实现这个操作)。由于对抗优化器只负责优化参数集合g,此时只有对抗样本训练网络的参数被改变。重复上述过程,直到s5所述的条件被满足。另外值得一提的时,训练用的图片,还包括一些随机生成的噪声图,或者纯色图,或者随机生成的形状图,这些图片本身并不包含任何需要网络识别的物体,但是在经过几轮对抗操作后,虽然人眼看起来它们仍然是噪声,但网络会以很高的置信度将它们识别为某个物体。例如图3中所示,在数次对抗修改后,深度学习网络认为图中能够检测到一段文字。
73.步骤s6为训练阶段,在对抗阶段中每次第二损失函数执行梯度回传操作时,第一损失函数也执行一次梯度回传操作,与第二损失函数不同的是,第一损失函数回传的参数集合a的梯度要记录并累加,参数集合g(对抗参数层)则忽略第一损失函数回传的梯度。此时深度学习网络中参数的梯度只是先累加起来,暂时不用于更新深度学习网络参数。直到步骤s5达到停止条件,再由训练优化器对深度学习网络参数进行一次更新。这样,网络每进行一次前向操作,就进行两次后向操作,一次后向用于对抗样本生成,另一次后向则用于网络训练。对抗样本生成和网络训练紧密的结合在了一起,而不是完全独立的两个步骤,节省了大量的运算,也使得对抗和网络训练实时绑定,能够针对性的优化。步骤s6中积累梯度后一次更新的操作,相当于将对抗阶段的数次迭代中的图片全部组成了一个批次,这使得对抗阶段生成的每张图片都得到了利用,并不止是最终生成的那一张图片。
74.所述对抗样本训练网络设置于所述深度学习网络的输入层前面,为一个对抗参数层,所述对抗参数层的形状为b x h x w x c,其中b为训练的一个批次的图像数量(batch size),h与w对应输入的训练图像的高和宽,c为输入图像的通道数,一般为3,对应红绿蓝三个颜色分量通道;在所述对抗参数层中,输入图像首先与对抗参数层参数相加,输出截取0至255的值,再经过归一化,转为浮点数后输出,此时对抗参数层的参数集合为g。
75.步骤s3中根据深度学习网络的输出和经标签混淆后的标签计算第二损失函数中,根据深度学习网络的训练任务不同,标签混淆的操作方法包括:
76.对于单分类任务可以将one
‑
hot做随机循环移位操作;
77.对于多分类任务可以直接对multi
‑
hot向量取反,或者全部置零;
78.对于分割任务可以将标签掩码置零,或者做随机类别变换;
79.对于文本识别任务可以将其中的字符变成形状相似的字符。
80.所述步骤s4中优化对抗器可采用sgd并配以0动量,或者任何其他类型的优化器,对抗优化器优化的参数范围是对抗样本训练网络中的参数集合g,不包括深度学习网络中的参数;训练优化器就是在步骤s2中使用的训练过程中深度学习网络的优化器,这个训练优化器优化的参数范围是深度学习网络中的参数,不包括对抗样本训练网络的参数集合g。
81.步骤s5中直至对抗样本训练网络生成的对抗样本为可用于优化深度学习网络的数据增广图片或深度学习网络充分学习到该图像样本中物体的特征,具体为:
82.若原始图像经过对抗样本训练网络后生成的对抗样本,经过深度学习网络以后被误识别为经标签混淆后的标签,则表示生成的对抗样本为可用于优化深度学习网络的数据增广图片;
83.若重复了一定次数以后,第二损失函数不再发生显著变化,则表示深度学习网络充分学习到该图像样本中物体的特征。
84.所述步骤s7中训练集中每一图像样本至少重复上述步骤一次,应使简单样本出现的概率小,而难样本出现的概率大,所述简单样本指经过网络前向后,输出的结果极为接近标签,对网络训练起不到较大作用的样本,所述难样本为经过数个周期的训练后,网络仍然不能很好识别的样本。
85.所述步骤s7中终止训练条件,具体包括:
86.损失函数长时间不降低;
87.验证集准确率长时间无明显提升;
88.设定固定的数个周期以后停止;
89.每个周期结束时,对验证集中的每张图像做一次对抗扰动和识别,统计其中简单样本的比例,当简单样本比例达到指定条件时,终止训练;
90.验证集中的样本对抗后输出到屏幕显示,当人工观察发现对抗样本在人看来无法识别时,终止训练,能够更直观的让人判定网络当前的收敛状态,在训练完毕以后能够对模型给出直观评价,能够预知模型在什么样本上能够正常工作。
91.在具体实施过程中,在需要对一些pdf文件进行自动识别的业务中,pdf可能有一些较小或不清晰的文字,另外其中常有水印干扰,使得市面上的ocr模型的识别词准率只有90%左右,人工校验时需要花费较多时间来处理这些识别错误。这些错误中有相当多的错误是类似《what machines see is not what they get:fooling scene text recognition models with adversarial text images》论文中提到的,人看起来毫无问题的文字,但模型就是无法识别。
92.使用本实施例提供的方法,训练出了能够提升识别效果的模型。
93.在识别图4所示的文字时,某著名ai厂商的ocr识别结果是出现了识别错误或大小写有误的情况,在训练集词库中加入了专业名词,例如ferritin,hiv,pregnancy等后,图3中以前识别错误的地方正确了,但在其他地方又会出现问题,例如ae/cm中间的斜杠未能识别出来,hcg识别成lcg等;使用了本发明的训练方法后,上面图片中的文字绝大部分均识别
正确,只有个别标点符号识别错误。使用这种训练方法,综合看来训练时间增加了50%,但获得的效果提升是值得的。
94.实施例2
95.本实施例提供一种实时生成对抗样本的深度学习训练数据增广装置,如图5所示,所述装置应用实施例1所述的实时生成对抗样本的深度学习训练数据增广方法,包括:
96.对抗样本生成模块,所述输入模块用于将图像样本与随机噪声输入至对抗样本训练网络,所述对抗样本训练网络生成对抗样本;
97.输入模块,所述输入模块用于将对抗样本输入至经由正常训练过程训练好的深度学习网络中;
98.损失函数计算模块,所述损失函数计算模块根据深度学习网络的输出和标签计算第一损失函数,根据深度学习网络的输出和经标签混淆后的标签计算第二损失函数;
99.梯度回传模块,所述梯度回传模块利用对抗优化器对第二损失函数进行梯度回传和对抗样本训练网络参数更新操作,同时对第一损失函数进行一次梯度回传操作并进行记录与累加;
100.第一循环模块,所述第一循环模块用于将同一批次的图像样本重复经上述模块处理,直至对抗样本训练网络生成的对抗样本为可用于优化深度学习网络的数据增广图片或深度学习网络充分学习到该图像样本中物体的特征;
101.深度学习网络参数更新模块,所述深度学习网络参数更新模块由训练优化器将第一损失函数梯度回传时记录与累加得到的参数集合a对深度学习网络进行一次参数更新;
102.第二循环模块,所述第二循环模块用于将训练集中每一图像样本至少重复经上述模块处理一次后,判断是否达到终止训练条件;
103.终止模块,所述终止模块用于在达到终止训练条件时,终止训练。
104.实施例3
105.本实施例提供一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行以实现如实施例1所述的方法。
106.实施例4
107.本实施例提供一种计算机可读介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现如实施例1所述的方法。
108.相同或相似的标号对应相同或相似的部件;
109.附图中描述位置关系的用语仅用于示例性说明,不能理解为对本专利的限制;
110.显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。