一种基于负载均衡的流式计算引擎调度方法及系统与流程
international conference on data engineering(icde).ieee,2016:589-600.)等都提出了一种基于数据分发策略的在线任务调度方法,但他们把每个算子上就绪未完成计算的元组数量作为该算子的当前负载,忽略了不同算子处理数据能力差异性带来的负载不均衡问题。
技术实现要素:
6.针对现有流式计算调度方法的不足,本发明提出了一种基于负载均衡的流式计算引擎调度方法及系统,根据负载监测信息使用基于遗传算法的负载均衡算法制定新的调度策略,重新分配系统资源使系统达到负载均衡,可以解决集群发生负载不均衡的问题。
7.为实现上述目的,本发明采用以下技术方案:
8.一种基于负载均衡的流式计算引擎调度方法,包括以下步骤:
9.从流式计算引擎的每个物理节点上收集过去一段时间的负载统计数据,并存储到内存数据库中;
10.根据当前节点的最大负载maxl和全部节点的平均负载计算负载不均衡程度计算负载不均衡程度
11.如果负载不均衡程度超出预设阈值,则判定当前处于负载不均衡状态,从内存数据库中取出过去一段时间的负载统计数据,再根据遗传算法(galb算法)生成新的数据分发策略;
12.将新的数据分发策略传递给流式计算引擎的主节点,并由主节点分发至各个分支节点,在线更新数据分发策略,完成调度。
13.进一步地,根据galb算法生成新的数据分发策略的步骤包括:
14.流式计算引擎的物理节点集合表示为n={n1,...ni,...nm},m为全部物理节点的数量,物理节点ni处理的算子表示为oi,算子oi的状态表示为si;
15.将负载统计数据的全部元祖以key进行分组,得到k={k1,...ki,...ka},ki表示第i个元组分组,a为全部元组分组数量,单个元祖e在算子oi上占用的cpu处理时间为ci,将对每个key数据的处理作为一个任务,单个任务执行时间ci=ci*ki,则任务集合表示为t={c1,...ci,...c
p
},p表示任务集合t中的任务数量;
16.通过t
t
×
n构建任务处理时间矩阵taskmat,t
t
表示任务矩阵t转置,taskmat[i][j]表示第i个任务分到第j个节点上处理需要的处理时间;
[0017]
通过随机函数生成初始的染色体chromo,chromo[i]表示在上游算子到下游算子的数据分发过程中第i个key被分发到算子o
chromo[i]
上,chromo数组的长度为通过key进行分组时key的数量a;
[0018]
设定种群数量u,生成u条染色体x,组成种群p={x1,x2,x3,...xu},通过贪心策略计算每一条染色体的每个编码位的编号,再将该染色体加入到该种群中;
[0019]
通过任务处理时间矩阵taskmat来计算每条染色体的适应度其中为针对当前染色体的所有节点的平均负载,maxl为针对当前染色体的节点最大
负载,maxl=max{l1,...li,...lm};每个节点的负载通过计算得出,其中i表示第i个节点,k是临时变量,xk=i表示将第k个任务分配到第i个节点上;
[0020]
计算种群中所有染色体的适应度,通过轮盘赌算法生成一个新的种群;
[0021]
对新种群中的染色体进行交叉操作,交换任意两条染色体的指定编码位;
[0022]
对经过交叉操作的染色体进行变异操作,对要进行变异的染色体随机选择编码位进行随机变异;
[0023]
循环执行上述步骤直至设定的次数,找出最优染色体,得到新的数据分发策略。
[0024]
进一步地,贪心策略的执行步骤包括:
[0025]
将所有的任务根据任务处理时间降序排序,依次放入一队列q中;
[0026]
从队列q中取出队首的任务作为当前的任务即第i个任务;
[0027]
将当前任务分配到当前负载最小的节点即第j个节点上去,每个节点的当前负载表示为被分配到该节点的所有任务的处理时间之和,然后将该任务从队列中删除,更新当前负载最小的节点的负载,更新公式为:lj=lj+taskmat[i][j],l表示负载;
[0028]
继续从队列q中取出下一个任务进行上一步骤的处理,重复进行,直至队列q为空。
[0029]
进一步地,通过轮盘赌算法生成一个新的种群的步骤包括:
[0030]
计算种群的最大适应度和最小适应度,根据该最大适应度和最小适应度对每条染色体的适应度进行归一化处理,得到归一化的种群适应度;
[0031]
计算每个染色体的适应度占全部染色体的适应度之和的比值,得到每个染色体的选择概率;
[0032]
计算每个染色体的选择概率与其之前所有染色体的选择概率之和,得到所有染色体的累积概率qi;
[0033]
生成一个0~1之间的随机数r1,若满足qi>r1∧q
i-1
<r1,则选择该染色体加入到一新的种群中;
[0034]
重复执行上一个步骤,直到新的种群中的染色体数目达到前一种群的规模。
[0035]
进一步地,对新种群中的染色体进行交叉操作的步骤包括:
[0036]
设置种群的交叉概率η,使用随机函数生成0~1之间的随机数r2,选择r2≤η的两条染色体;
[0037]
使用随机函数生成要交叉的编码位,将上述选择的两条染色体对所述要交叉的编码位进行编码交换;
[0038]
重复上述步骤,直至遍历完该种群中的全部染色体。
[0039]
进一步地,对染色体进行变异操作的步骤包括:
[0040]
设置变异概率ζ,使用随机函数生成0~1之间的随机数r3,若r3≤ζ,则进行变异;
[0041]
对于要进行变异的染色体随机选择编码位作为变异位进行变异,变异值为随机的节点编号且与当前值不同。
[0042]
进一步地,在对负载统计数据的全部元祖以key进行分组后,先对负载统计数据进行降维处理,降维处理步骤包括:
[0043]
获取当前时间作为哈希函数的随机种子,利用哈希函数h1(e)对所有的key进行散列操作,将其散列到b个哈希槽上去,每个key被散列到的哈希槽为s=h1(e)%m;
[0044]
将被哈希到同一个哈希槽s上的key进行聚合操作,将聚合之后的哈希槽上的所有的元组看作一个新的key,生成一个新的数据集合k
′
=[k
′1,k
′2,k
′i,...,k
′b],b为哈希槽数量;
[0045]
对所有哈希槽中所存储的元组按照数量从高到底的顺序进行排序,若某个哈希槽上聚合之后的元组的数量k
′i与所有哈希槽总元组数量的比值超过了所有下游算子数量z的倒数,则将该哈希槽中的数据使用哈希函数进行二次散列。
[0046]
一种基于负载均衡的流式计算引擎调度系统,包括:
[0047]
负载均衡检测模块,用于从流式计算引擎的每个物理节点上收集过去一段时间的负载统计数据,并存储到内存数据库中;根据当前节点的最大负载maxl和全部节点的平均负载计算负载不均衡程度
[0048]
调度模块,用于当超出一预设阈值时,从内存数据库中取出过去一段时间的负载统计数据,根据galb算法生成新的数据分发策略;
[0049]
在线调度策略更新模块,用于在线更新新的数据分发策略;
[0050]
数据分发模块,用于将新的数据分发策略传递给流式计算引擎的主节点,并由主节点分发至各个分支节点,在线更换数据分发策略。
[0051]
本发明的有益效果:
[0052]
本发明可以实时监测流式引擎中各个节点中处理的数据信息,并判断当前的流式计算引擎的负载均衡程度是否超过了阈值。若超过阈值,使用基于遗传算法的数据分发策略来解决算子被分发的元组数量以及处理单个元组的时间不同带来的负载不均衡问题。从而提升流式计算引擎的吞吐量,降低端到端的数据处理延迟。该方法适用于各种对实时性要求比较高的物联网应用,可以充分提升物联网应用的智能化程度。
附图说明
[0053]
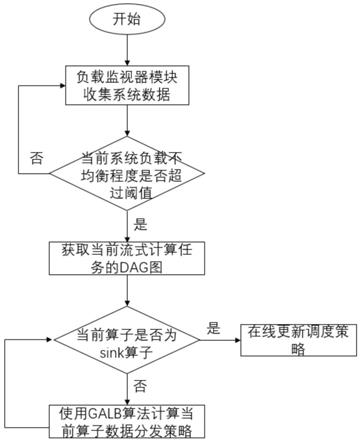
图1是一种基于负载均衡的流式计算引擎调度方法流程图。
[0054]
图2是一种基于负载均衡的流式计算引擎调度系统架构图。
[0055]
图3是上游算子向下游算子进行数据分发操作的示意图。
具体实施方式
[0056]
下面将结合实施例和附图,对本发明的技术方案进行清楚、完整的描述,可以理解的是,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0057]
本实施例公开一种基于负载均衡的流式计算引擎的调度方法,总体分为检测和调度两个部分,检测部分负责监测和统计系统的数据信息,并将信息保存到数据库中,调度部分根据统计信息不断生成新的调度策略,如图1所示,具体步骤包括:
[0058]
1、所述负载均衡检测模块分布在流式计算引擎系统的每个物理节点上,收集过去一段时间的数据处理信息并将其存储到内存数据库中。通过来判断当前系统是否处
于负载均衡的状态,其中maxl表示当前系统节点的最大负载,表示系统的平均负载。当超过了预先设定的阈值,则判定当前系统出现了负载不均衡的情况。
[0059]
2、当系统中出现了负载不均衡问题后,调度模块会从数据库中取出过去一段时间内的负载统计数据,然后根据galb算法进行建模。生成新的数据分发策略。
[0060]
3、新的数据分发策略生成后,传递给流式计算引擎的主节点,并由其分发至各个物理节点,在线更换数据分发策略,并继续转到步骤一进行监控工作。
[0061]
本发明方法采用以下方式实现:
[0062]
流式计算引擎系统中的物理节点集合可以表示为n={n1,...ni,...nm},1≤i≤m,m为节点的个数,使用oi表示流式计算中的算子,si表示算子oi的状态,q
i,k
表示是否将单个元组e分发到算子oi上,其值为1时表示分发,为0时表示不分发。在进行有状态计算时,元组在算子oi上占用的cpu处理时间为ci,t时刻,节点ni上的负载可以表示为:li=|{《τ,k,v》:q
i,k
=1∧τ<t}|*ci,所有节点的平均负载可以表示为:节点的最大负载表示为:maxl=max{l1,l2,l3,...lm}。
[0063]
当流式计算引擎运行之后,负载监测模块检测到系统出现负载不均衡情况后,调度模块通过使用galb算法计算出新的数据分发策略q
i,k
,生成路由表并更新数据分发策略。
[0064]
galb算法的具体步骤如下:
[0065]
1、流式计算引擎发生负载不均衡时,调度模块从系统的内存数据库中读取过去一段时间的统计数据,该统计数据对元组以key进行分组,可以表示为k={k1,k2,k3,...ka},a为全部元组分组数量,分别代表在过去一段时间内数据源算子发送的不同key对应的元组的数量。当a大于预先设的阈值ξ时,使用聚合方法对数据进行降维(数据降维方法见步骤10)。
[0066]
2、将对每个key最近一段时间t数据的处理看作一个任务,其执行时间ci与其最近这段时间执行的元组的数量有关,可以表示为ci=ci*ki,其中处理时间ci与该元组被处理的算子上的状态si有关。任务集合可以表示为t={c1,c2,c3,...c
p
},p表示任务集合t中的任务数量,节点的集合可以表示为n={n1,n2,n3,...nm},每个节点的处理能力与该节点上的算子的状态大小有关。
[0067]
3、通过t
t
×
n构建任务处理时间矩阵taskmat,其中t
t
表示任务矩阵t转置(上角标t表示矩阵转置),taskmat[i][j]表示第i个任务分到第j个节点(算子)上处理,需要的处理时间。
[0068]
4、通过随机函数生成初始的染色体chromo,chromo[i]表示在上游算子到下游算子的数据分发过程中,第i个key被分发到算子o
chromo[i]
上,chromo数组的长度为通过key进行分组时key的数量a,染色体的每个编码位的数据范围是通过dag图得出的下游算子的并发度。
[0069]
5、设定种群数量u(该数目的具体值可以由用户进行设置),生成u条染色体组成种群p={x1,x2,x3,...xu}。通过使用贪心策略来计算一条染色体每个编码位的编号,然后将该染色体加入到种群中去。设初始种群中的染色体数目为u,对于初始种群中的其他u-1条染色体,每条染色体可以通过将各个编码位设置为随机的节点编号来实现,贪心策略的具体步骤如下:
[0070]
5.1、将所有的任务根据任务处理时间降序排序并依次放入队列q中,任务的计算量可以通过按照key来统计的元组的数量来表示。
[0071]
5.2、从队列q中取出队首的任务作为当前的任务即第i个任务。
[0072]
5.3、将当前任务分配到当前负载最小的节点即第j个节点上去,每个节点的当前负载可以表示为被分配到该节点的所有任务的处理时间之和,然后将该第i个任务从队列中删除,更新节点的负载,第j个节点的更新公式为:lj=lj+taskmat[i][j]。
[0073]
5.4、重复执行5.2-5.4,直至队列q为空。
[0074]
6、对于每条染色体x,通过任务处理时间矩阵taskmat来计算该染色体的适应度fi(i表示第i个染色体),fi的计算公式可以表示为其中为针对当前染色体的所有节点的平均负载,可以表示为:n为节点集合,maxl为针对当前染色体的节点最大负载,表示为:maxl=max{l1,...li,...lm},每个算子节点的负载可以通过},每个算子节点的负载可以通过来计算得出,其中li式子中的i表示第i个节点,k是临时变量,xk=i表示将第k个任务分配到第i个节点上。
[0075]
7、通过步骤六得出整个种群所有染色体的适应度为f={f1,f2,f3,...fu},u为染色体总数量,通过轮盘赌算法生成一个新的种群,对于每个染色体个体x执行如下操作:
[0076]
7.1、进行归一化处理,适应度表示负载均衡程度,适应度越低,在下一轮迭代中被选中的概率应该越高,计算种群的最大适应度与最小适应度为:maxfitness=max{f1,f2,f3,...fu},minfitness=min{f1,f2,f3,...fu},则对于染色体x对应的适应度f
x
归一化后为:
[0077]f′
x
=(maxfitness+minfitness-f
x
)/(maxfitness-minfitness)
[0078]
进而得到归一化后的种群适应度为f
′
={f
′1,f
′2,f
′3,...f
′u)。
[0079]
7.2、计算适应度比例,即每个染色体个体的选择概率式中,f(xi)为当前染色体的适应度,f(xj)为任意染色体的适应度,xi表示第i个染色体,xj表示第j个染色体,该式子的意思是:每个染色体的适应度占总适应度的比例。
[0080]
7.3、然后计算所有个体的累积概率,即每个染色体个体与其之前所有个体的选择概率之和其相当于概率论中的概率分布函数f(x)。
[0081]
7.4、接下来使用随机生成函数生成r1∈[0,1],若满足qi>r1∧q
i-1
<r1,则选择该染色体加入新的种群中。
[0082]
7.5、重复7.4的步骤,直至新的种群中的染色体数目再次达到之前的规模。
[0083]
8、通过步骤7生成一个新的种群,在该种群基础上进行交叉操作。
[0084]
8.1、设置种群的交叉概率为η(该值可以由用户进行自主设置,根据实验经验设置在0.6左右效果比较好),判断两条染色体是否继续交叉操作的方法为:使用随机函数生成0~1之间的随机数r2,若r2≤η,则记录该染色体,并用同样的方式选择另一条染色体。
[0085]
8.2、使用随机函数生成交叉的编码位的位置(范围为染色体的长度)。
[0086]
8.3、将两条选择出来的染色体的指定编码位进行交换,并继续执行步骤8.1-8.2
直到遍历完整个种群。
[0087]
9、在步骤8的基础上对种群进行变异操作,设置种群的变异概率为ζ(可由用户设置,根据实验经验取0.1左右效果比较好),使用随机函数生成0~1之间的随机数r3,若r3≤ζ则对该染色体进行变异,否则不变异,对于要进行变异的染色体随机选择编码位作为变异位,变异值为随机的节点编号(不能与当前值相同)。
[0088]
10、重复执行步骤6-9,直到达到用户设定的循环次数,找出最优染色体,得到新的数据分发策略。
[0089]
11、对数据按照key进行分组后,若key的数量过大,会导致算法求解时间开销过大,因此先对数据进行降维处理,步骤如下。
[0090]
11.1、获取当前系统时间作为哈希函数的随机种子,使用h1(e)哈希函数(e表示单个元组)对所有的key进行散列操作,将其散列到b个哈希槽(b为哈希槽数量)上去,每个key被散列到的哈希槽为s=h1(e)%m。
[0091]
11.2、将被哈希到同一个哈希槽s上的key进行聚合操作,将聚合之后的哈希槽上的所有的元组看作一个新的key。此时生成一个新的数据集合k
′
=[k
′1,k
′2,k
′i,...,k
′b],b为哈希槽数量。
[0092]
11.3、对所有哈希槽中所存储的元组按照数量从高到底的顺序进行排序,若某个哈希槽上聚合之后的元组的数量k
′i与所有哈希槽总元组数量的比值超过了所有下游算子数量z的倒数,即时,将该哈希槽中的数据使用h2(e)哈希函数进行二次散列。
[0093]
与上面方法相对应的,本发明提供了一种基于负载均衡的流式计算引擎调度系统,包括负载均衡检测模块、调度模块、在线调度策略更新模块和数据分发模块,图2所示为实现该系统的一种具体架构。所述负载均衡检测模块通过在每个节点的worker工作进程中启动一个监控线程,通过快照的方式收集每个物理节点(算子)中处理的不同key的元组的数量。若通过负载统计数据计算的负载不均衡程度即负载不均衡程度未超过阈值,则持续监控,若超出阈值则激活调度模块进行数据调度,并将生成的新的数据调度方法传给在线调度策略更新模块进行在线更新操作;所述在线调度策略更新模块可以在线更新通过galb算法生成的数据分发策略,首先其通过主节点向所有的工作节点发送新的数据分发策略,每个实际工作的物理节点worker进程收到新的分发策略后,每个上游算子在对相关的元组进行过计算操作之后,先暂时停止向下游算子分发元组,并在此过程中向数据分发模块进行订阅操作,当新的数据分发策略替换完成后,数据分发模块会通过分发消息的方式告知所有的算子,每个算子按照新的数据分发策略向下游算子进行数据分发。本系统的四个模块按照所具有的负载均衡检测、数据调度、在线调度策略更新和数据分发等功能对应执行上述的基于负载均衡的流式计算引擎调度方法的各个技术手段,通过这四个模块组合成的系统来实现上述方法,这四个模块具体分别执行上述哪些技术手段对于本领域技术人员很容易辨识,不再重复赘述上述技术手段,本领域技术人员应可理解。
[0094]
下面结合单词统计的例子和相关数据,对本发明进行说明。
[0095]
1、如图3所示,该图代表一个单词统计在流式计算中的dag图。在计算过程中,上游
算子按照指定的概率生成相应的单词,然后向下游算子进行数据分发,其中相同的单词会被分发到同一个下游算子。下游算子根据收到的元组对单词进行计数统计,并将统计的中间结果以数组的形式保存在自己的算子状态中。最终下游算子将统计的结果进行输出。
[0096]
2、下面结合具体的实例对galb算法进行演示
[0097]
设当前流式计算任务中下游算子的任务并发度为3,分布在3个物理节点中,节点编号为1,2,3。上游算子通过指定概率生成8个单词发送给下游算子,将对每个单词的处理看作一个任务,一共8个任务,每个任务的长度如以下表1所示:
[0098]
表1
[0099]
编号12345678任务长度1515126918219
[0100]
负载检测模块通过统计每个算子处理相同数量的元组所花费的时间,进一步的可以计算出不同算子对于数据的处理能力如以下表2所示:
[0101]
表2
[0102]
节点123处理能力123
[0103]
galb算法的基本运算过程如下:
[0104]
1)生成任务处理时间矩阵,根据每个任务与不同节点的处理能力的比值,可以计算出不同任务在每个节点运行所需要的cpu时间片的时间,将其作为该任务分配到该节点后给其带来的负载增量。计算出来的任务处理时间矩阵如以下表3所示:
[0105]
表3
[0106] 12345678节点11515126918219节点27.57.5634.5910.54.5节点355423673
[0107]
2)染色体的编码方式采用整型数组编码,编码长度等于任务个数8,每个编码位上的基因值的变化范围为所有的节点的编号{1,2,3},表示将该任务分配到对象的节点上进行处理。例如:
[0108]
1,3,2,2,1,2,3,1
[0109]
表示将编号为1,5,8的任务分配到节点1上去执行,将编号为2,7的任务分配到节点3上去执行,将编号为3,4,6的任务分配到节点2上去执行。
[0110]
3)使用贪心策略初始化种群的一条染色体
[0111]
将所有的任务按照降序进行排序:
[0112]
21,18,15,15,12,9,9,6
[0113]
按照上述排列依次处理各个任务,将各个任务分配到当前负载最低的节点上进行处理,若存在负载相同的节点,则将其分配到任务处理时间矩阵对应的处理时间更少的节点。初始时假设所有的节点负载为0:
[0114]
a.将编号为7的任务分配到3号节点,当前每个节点的负载情况如以下表4所示:
[0115]
表4
[0116]
节点编号123负载情况
ꢀꢀ7[0117]
b.将编号为6的任务分配到2号节点,当前每个节点的负载情况如以下表5所示:
[0118]
表5
[0119]
节点编号123负载情况 97
[0120]
c.将编号为1的任务分配到1号节点,当前每个节点的负载情况如以下表6所示:
[0121]
表6
[0122]
节点编号123负载情况1597
[0123]
d.将编号为2的任务分配到3号节点,当前每个节点的负载情况如以下表7所示:
[0124]
表7
[0125]
节点编号123负载情况15912
[0126]
e.将编号为3的任务分配到2号节点,当前每个节点的负载情况如以下表8所示:
[0127]
表8
[0128]
节点编号123负载情况151512
[0129]
f.将编号为5的任务分配到3号节点,当前每个节点的负载情况如以下表9所示:
[0130]
表9
[0131]
节点编号123负载情况151515
[0132]
g.将编号为8的任务分配到3号节点,当前每个节点的负载情况如以下表10所示:
[0133]
表10
[0134]
节点编号123负载情况151518
[0135]
h.将编号为4的任务分配到3号节点,当前每个节点的负载情况如以下表11所示:
[0136]
表11
[0137]
节点编号123负载情况151718
[0138]
最终,根据贪心策略得出的一个初始染色体的编码为:
[0139]
1,3,2,3,3,2,3,3
[0140]
将该染色体作为一条初始染色体加入种群。
[0141]
4)以步骤3中得到的初始染色体为例,可以计算出该染色体的适应度为:
[0142]
节点的平均负载为
[0143]
节点的最大负载为maxl=18
[0144]
进而可以求得该染色体的种群适应度(负载均衡程度)为:
[0145]
5)对适应度进行归一化处理。在每一轮的种群选择过程中,染色体的选择概率与其种群适应度成反比,适应度越高,该染色体被选择的概率越大。假设种群中有五条染色体,其适应度分别为:0.1,0.2,0.3,0.4,0.5。则
[0146]
maxfitness=0.5,minfitness=0.1
[0147]f′1=(maxfitness+minfitness-f1)/(maxfitness-minfitness)=1.25
[0148]f′2=(maxfitness+minfitness-f2)/(maxfitness-minfitness)=1
[0149]f′3=(maxfitness+minfitness-f3)/(maxfitness-minfitness)=0.75
[0150]f′4=(maxfitness+minfitness-f4)/(maxfitness-minfitness)=0.5
[0151]f′5=(maxfitness+minfitness-f5)/(maxfitness-minfitness)=0.25
[0152]
归一化后的种群适应度为1.25,1,0.75,0.5,0.25。则染色体的选择概率计算如以下表12所示:
[0153]
表12
[0154]
染色体12345适应度1.2510.750.50.25选择概率0.3330.2670.20.1330.067累计概率0.3330.60.80.9331
[0155]
使用随机函数生成0~1之间的随机浮点数,根据该浮点数所属的概率区间来选择染色体,例如若随机函数产生的浮点数为0.68,则3号染色体被选中加入到新的种群中去(0.8≤0.68≤0.8),继续生成随机数进行选择直至新的种群中染色体数目与之前相同。
[0156]
6)对步骤5生成的新的种群进行交叉操作,假设种群的交叉概率为0.5,通过随机函数生成5个0~1之间的随机浮点数,来选择进行交叉操作的染色体。例如若生成的随机数为0.28,0.51,0.89,0.64,0.43。则选择编号为1,5的两条染色体进行交叉,假设其父代染色体如下:
[0157]
1,2,2,3,1,3,3,1
[0158]
2,3,3,2,3,1,2,3
[0159]
随机生成交叉点,交叉点的范围为染色体编码位的总长度,即任务的总数。假设随机生成的交叉点位2,则交叉后产生的子代染色体如下:
[0160]
1,3,2,3,1,3,3,1
[0161]
2,2,3,2,3,1,2,3
[0162]
7)变异操作:根据设定的种群变异概率确定需要进行变异操作的染色体,变异后的编码为在节点编号范围内生成的随机值(不能与当前编码相同),假设变异之前的染色体为:
[0163]
1,2,2,3,1,3,3,1
[0164]
若随机产生的变异编码位为7,在1~3之间随机生成的数字为2,则变异后的染色体为:
[0165]
1,2,2,3,1,3,2,1
[0166]
8)重复执行步骤4~7,直到执行了预先设定的指定轮数,或者种群的平均适应度
达到了阈值,则停止。
[0167]
上述实施例仅为例示性说明本发明的原理及其功效,而非用于限制本发明的范围。任何熟于此技术的本领域技术人员均可在不违背本发明的技术原理及精神下,对实施例作修改与变化。本发明的保护范围应以权力要求书所述为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1