一种社交网络假流量黑灰产自动挖掘方法和系统
1.本发明涉及网络黑灰产中的安全技术领域,尤其涉及一种社交网络假流量黑灰产自动挖掘方法和系统。
背景技术:
2.社交网络黑灰产是危害互联网生态安全的重大问题之一。传统技术能够对虚假评论、传统虚假用户等作弊行为进行检测,但随着作弊行为不断变化和转移,现有的模型和方法很快就失去适用性。
3.蜜罐技术本质上是一种对攻击方进行欺骗的技术,通过布置一些作为诱饵的主机、网络服务或者信息,诱使攻击方对其实施攻击,从而可以对攻击行为进行捕获和分析,了解攻击方所使用的工具与方法,推测攻击意图和动机,能够让防御方清晰地了解他们所面对的安全威胁,并通过技术和管理手段来增强实际系统的安全防护能力。因此利用蜜罐捕捉虚假用户账号,对社交网络黑灰产进行实时的分析和监控,有利于从源头上发现和打击社交网络黑灰产。
4.不同于传统的社交网络黑灰产,社交网络假流量黑灰产是最近5年才兴起的一种新型黑灰产,通常是指通过虚假转发含有特定话题的微博将特定话题推送上社交网络中的实施热榜等违反社交网络平台相关规范的作弊行为。从虚假账号的创建到虚假账号的运维,再到执行具体的攻击,社交网络假流量黑灰产已经形成完整的产业链,且随着社交网络领域反作弊机制的完善,社交网络流量作弊行为也趋向于专业化,然而企业内部对黑灰产的分布和现状大部分靠人工分析,无法应对日益扩大的黑灰产规模。
5.公开号为cn111917601a的中国专利文献公开了一种虚假流量识别方法及用户品牌价值的量化计算方法,涉及互联网技术领域。其中虚假流量识别方法定义了社交网络中用户的影响力和易被影响特性,通过爬取整个社交网络中一时间段内用户间的交互数据,根据该时间段内用户间的交互数据计算用户的影响力和易被影响特性,据此标记出虚假用户,识别出虚假流量。
6.公开号为cn110913396a的中国专利文献公开了一种虚假流量识别方法、装置、服务器及可读存储介质,涉及数据处理技术领域。该虚假流量识别方法通过预先建立的白名单对获取到的每个移动终端中各应用软件网络通信时的流量数据进行第一标识,通过预先建立的黑名单对获取到的每个移动终端中各应用软件网络通信时的流量数据进行第二标识,根据各流量数据是否具有所述第一标识和第二标识,判断各流量数据是否为虚假流量。
技术实现要素:
7.本发明提供了一种社交网络假流量黑灰产自动挖掘方法和系统,可及时发现、预警和治理社交网络流量作弊事件,实现对社交网络假流量黑灰产进行实时多维度监控。
8.本发明的技术方案如下:
9.一种社交网络假流量黑灰产自动挖掘方法,包括以下步骤:
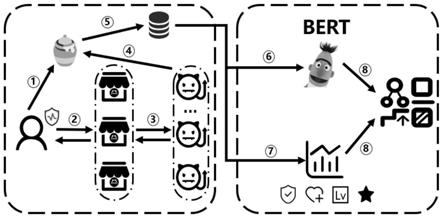
10.(1)创建“蜜罐”用户,在社交网络中对参与假流量攻击的恶意用户进行诱捕;
11.(2)采用自然语言处理技术对诱捕得到的恶意用户的微博内容进行数据分析,获得恶意用户的微博内容层面的特征;
12.(3)对诱捕得到的恶意用户的个人信息进行分析,获得恶意用户的个人信息层面的特征;
13.(4)在社交网络中随机选取正常用户,根据步骤(2)和(3)的方法分别提取正常用户的微博内容层面和个人信息层面的特征;
14.(5)运用机器学习算法,根据步骤(2)~(4)中提取的特征,训练分类器使之能区分正常用户与恶意用户;
15.(6)对于任意的社交网络中的微博用户,根据步骤(2)和(3)的方法分别提取用户的微博内容层面和个人信息层面的特征,并运用步骤(5)中训练好的分类器进行识别;
16.(7)对于步骤(6)中被识别为恶意用户的微博用户,基于规则对该微博用户所发的微博进行筛选,挖掘出涉及假流量黑灰产的微博。
17.所述的社交网络可以为新浪微博、大众点评、twitter、tuenti等,所述的微博是指社交网络用户在社交网络上所发表的博客。
18.步骤(2)中,运用自然语言处理技术提取用户的微博内容层面的特征,包括:
19.(2
‑ⅰ
)对于诱捕得到的参与假流量攻击的恶意用户,选取其所有不包含任何话题的微博,标记为正样本;
20.在社交网络中随机采集正常用户所发的微博,标记为负样本;
21.将所有样本打乱后分割成训练样本、验证样本和测试样本;
22.(2
‑ⅱ
)将训练样本输入双向自编码表示变形器(bert)中进行向量计算,得到其输出层第一个变形器(transformer)的输出向量;
23.(2
‑ⅲ
)将输出向量作为多层感知机(mlp)的输入,将多层感知机输出结果作为softmax层的输入,计算每条微博属于恶意用户所发的概率或正常用户所发的概率;
24.(2
‑ⅳ
)使用随机梯度下降算法更新双向自编码表示变形器和多层感知机的网络参数;
25.(2
‑ⅴ
)采用验证集测试双向自编码表示变形器和多层感知机的精确率,若所述精确率达到要求,则结束训练,否则继续训练;
26.(2
‑ⅵ
)对于一个用户来说,采用双向自编码表示变形器和多层感知机对该用户所发的所有微博进行预测,计算该用户所发的所有微博中被识别为恶意用户用于伪装自身的微博的比例,将该比例作为该用户在微博内容层面的特征。
27.双向自编码表示变形器(bert,bidirectional encoder representations from transformers)是一个语言表示模型。bert将transformer模型中的encoder部分进行双向链接。bert模型是一个预训练模型,其预训练任务由masked language model(mlm)和next sentence prediction(nsp)任务组成,而本发明需要的任务是句子分类任务,识别出一个句子是否属于虚假账户发送的用于隐藏自己的微博。因此,不能直接运用bert模型来达成本技术的任务,需要对bert模型进行一些定制化的操作与微调。具体来说是:将bert模型作为特征提取器,选取bert模型最后一层的第一个单元作为输入一个句子的句子向量,之后再把这个句子向量输入进添加前馈式神经网络与softmax层进行分类,最终判断这个句子
的类型。
28.优选的,所述的训练样本、验证样本和测试样本的数量比为6:3:1。
29.优选的,步骤(2
‑ⅳ
)中,使用随机梯度下降(stochastic gradient descent,sgd)更新双向自编码表示变形器和多层感知机的网络参数,学习率(learning rate)初始时为0.00002,每次在数据集上训练一轮后通过验证集计算一下模型的损失,并存储检查点,训练若在验证集上模型预测准确率下降则停止训练。
30.步骤(3)中,所述的用户的个人信息层面的特征包括:
31.(a)该用户是否认证;
32.(b)该用户的粉丝数量;
33.(c)该用户的关注数量;
34.(d)该用户的微博数量;
35.(e)该用户的账号等级。
36.步骤(5)包括:
37.(5
‑
i)将参与假流量攻击的恶意用户标记为正样本,将正常用户标记为负样本,构建训练集和验证集;
38.(5
‑
ii)提取训练样本的微博内容层面的特征和个人信息层面的特征;
39.(5
‑
iii)将提取的训练样本的特征值归一化后作为xgboost模型的输入,对xgboost模型进行训练;通过训练好的xgboost模型对可疑微博用户进行预测,识别获取参与假流量攻击的恶意用户。
40.步骤(7)中,所述的规则为:对于一条微博,若其中含有话题,则将该微博分类为涉及假流量黑灰产的微博。
41.可通过分析涉及假流量黑灰产的微博和执行假流量攻击的恶意用户,设计相应的反作弊测量;可将相关涉及假流量的话题反馈给相关部门进行处理。
42.本发明同时还提供了一种社交网络假流量黑灰产自动挖掘系统,包括系统显示组件、数据采集组件和模型决策组件;
43.所述的系统显示组件负责整个系统与使用者的交互;使用者通过系统显示组件输入目标用户的id号码,由系统显示组件将id号码发送给数据采集组件;
44.所述的数据采集组件负责对目标用户的数据进行采集;数据采集组件在收到系统显示组件发送来的id号码之后执行数据采集程序,采集模型决策组件所需要的目标用户的数据,对采集到的数据处理后以合适的格式发送给模型决策组件;
45.所述的模型决策组件负责对目标用户以及目标用户所发的微博进行预测;所述的模型决策组件包括训练好的双向自编码表示变形器和xgboost模型;模型决策组件收到数据采集组件发送来的用户数据后,首先调用训练好的双向自编码表示变形器对目标用户所发的微博进行预测,其次调用xgboost模型对目标用户进行预测,最后将所有的预测结果传回给系统显示组件进行渲染显示。
46.所述的社交网络假流量黑灰产自动挖掘系统根据上述方法对社交网络假流量黑灰产进行自动挖掘。
47.与现有技术相比,本发明的有益效果为:
48.(1)能够实时获取多渠道的外部信息,构建社交网络假流量黑灰产纵深防御体系;
representations from transformers)中进行向量计算,得到输出层第一个变形器(transformer)的输出向量。将输出向量作为多层感知机(mlp)的输入,将输出结果作为softmax层的输入,计算每条微博属于恶意用户伪装自身的微博的概率和社交网络中正常用户所发的微博的概率。使用随机梯度下降算法更新双向自编码表示变形器和多层感知机的网络参数。采用验证集测试双向自编码表示变形器和多层感知机的精确率,若所述精确率达到要求,则结束训练,否则继续训练;对于一个用户来说,采用双向自编码表示变形器和多层感知机对每一条微博进行预测,给出对应的预测标签。之后计算预测标签为“伪装微博”,占所有标签的比例作为微博内容层面的特征。
66.(3)个人信息层面的特征包括以下几种:
67.(a)该用户是否认证;
68.(b)该用户的粉丝数量;
69.(c)该用户的关注数量;
70.(d)该用户的微博数量;
71.(e)该用户账号的等级;
72.(4)将参与假流量攻击的恶意用户标记为正样本,将正常用户标记为负样本,按照7:3的比例构建训练集和验证集,其中训练集中有2793个用户,测试集中有1197个用户;
73.(4
‑
1)提取训练样本的微博内容层面的特征和个人信息层面的特征;
74.(4
‑
2)将训练样本特征值归一化后作为xgboost模型的输入,对xgboost模型进行训练;
75.(4
‑
3)通过训练好的xgboost模型对可疑微博用户进行预测,识别获取参与假流量攻击的恶意用户。
76.步骤(4
‑
2)中,所述的微博内容层面的特征为一个用户中所有微博中被bert模型预测出标签为“伪装微博”的比例;所述的个人信息层面的特征包括该用户是否认证、该用户的粉丝数量、该用户的关注数量、该用户的微博数量和该用户账号的等级。
77.(5)采用的基于规则筛选其中涉及假流量黑灰产的微博中的规则为:对于一条微博若其中含有话题则将该微博分类为涉及假流量黑灰产的微博。
78.以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1