预训练对偶注意力神经网络语义推断对话检索方法及系统、检索设备、存储介质与流程
1.本发明是一种预训练对偶注意力神经网络语义推断对话检索方法及系统、检索设备、存储介质,属于人机语言交互领域。
背景技术:
2.一般来说,有两种类型的对话系统:面向任务的对话和开放域对话。面向任务的对话系统是为特定领域或任务而设计的,如航班预订、酒店预订、客户服务和技术支持等,并已成功地应用于一些实际应用中。构建智能的开放域对话系统,使之能够与人类进行连贯而有吸引力的对话,一直是人工智能(ai)的一个长期目标。早期的对话系统,如eliza、 parry和alice,尽管显著提高了机器智能,但仅在受限的固定场景下工作良好。开放域对话代理的目标是最大化用户的长期参与。这在数学上很难优化,因为有许多不同的方法(称为对话技巧)来提高参与度(例如,提供娱乐、推荐、谈论有趣的话题),它要求系统对对话环境和用户的情感需求有深刻的理解,在正确的时间选择正确的技能,并产生具有一致个性的人际反应。
3.而且,现阶段中先进的对话系统多以英文对话为主,由于中文与英文之间,在语法结构、语言表达的习惯上存在大量差异,所以,中文对话系统的发展仍然面临着更多挑战,现存的中文系统所展示出的一般智能仍然远远落后于人类。因此,建立开放领域的对话系统,可以像人类一样就各种话题进行对话,仍然是一项极具挑战性的工作。
4.来自开放域对话的挑战主要有三点:
5.第一是语义,语义是任何对话系统的核心,因为对话是一种语义活动。要求系统通过语义理解用户,例如用户的个性、情感、情绪甚至要结合用户的概况和背景。从技术角度看,语义主要涉及自然语言理解和用户理解的关键技术,包括命名实体识别、实体链接、领域检测、主题和意图检测、用户情绪、情感、观点检测和知识、常识推理等技术分类;
6.第二是一致性,为了获得用户的长期信心和信任,对话系统必须在给定用户输入和对话历史的情况下做出与对话属性一致的响应,从而呈现一致的行为。这是当今聊天系统的一大痛点。例如,一个社交机器人不应该提供一个与ta预先设定的角色冲突的响应,或者 ta以前在时间依赖性、因果关系或逻辑上的响应。具体来说,系统的反应需要在三个方面保持一致。第一是人物角色一致性,即响应需要符合对话系统的预定义个性。第二是文体的一致性,即表现出一致的说话风格。第三是语境的一致性,即回应需要与对话语境保持一致。从技术角度看,一致性主要涉及个性化、文体生成和多回合语境建模。当前的对话系统需要在一致性和系统性能之间做出权衡,性能的瓶颈导致了多轮对话技术很难应用于工业实践当中;
7.第三是交互性,为了满足用户社会需求,加强用户社会归属感,是开放领域对话系统的主要设计目标。为了提高交互性,重要的是了解用户的情绪状态或情感,不单单对用户输入作出反应,而且要主动作出反应,控制话题的维持或转换,并优化交互策略,以最大限
度地提高用户的长期参与。从技术角度看,交互主要涉及情感检测、对话状态跟踪、话题检测和推荐、对话策略学习和可控响应生成。
8.总结近年来出现在ccf推荐会议上的聊天机器人技术方案如下:
9.其一,检索式框架:
10.给定一个对话语料库和用户的帖子,基于检索的系统可以使用任何检索算法从语料库中选择合适的响应。在这种设置中,系统检索与给定用户帖子最相似的帖子,对检索到的帖子的响应作为对用户帖子的响应返回。文献1:zongcheng ji,zhengdong lu,and hang li. 2014.an information retrieval approach to short text conversation.arxiv preprintarxiv:1408.6988(2014).引入了传统的学习排序方法,用于从大规模的反应后储存库中选择反应。随后,许多神经网络模型被提出。
11.其二,深交互神经网络:
12.对于深度交互网络,文献2:yu wu,wei wu,chen xing,ming zhou,and zhoujun li. 2017.sequential matching network:a new architecture for multi
‑
turn response selection inretrieval
‑
based chatbots.in proceedings of acl 2017,vancouver,canada,july 30
‑
august 4, 2017.496
–
505.提出了一个用于多回合对话的顺序匹配网络(sequential matching network, smn),通过gru顺序连接,从而生成一个特征向量,在不同的抽象层次上保留所有查询
‑ꢀ
响应交互信息。然后使用另一个神经网络从向量中导出匹配分数。
13.其三,浅交互神经网络:
14.对于浅层交互网络,人们致力于学习更加优秀的查询表示和候选表示。文献3:po
‑
senhuang,xiaodong he,jianfeng gao,li deng,alex acero,and larry p.heck.2013.learningdeep structured semantic models for web search using clickthrough data.in 22nd acminternational conference on information and knowledge management,cikm’13,san francisco, ca,usa,october27
‑
november 1,2013.2333
–
2338.提出使用深层结构相似模型(deepstructured similarity models,dssm)从查询和文档中独立提取语义特征,然后再计算其相关性。dssm通过引入卷积层和具有长
‑
短期记忆(lstm)单元的递归层得到进一步增强。
15.其四,生成式模型以及混合式模型:
16.该方法可以分为pipeline系统或端到端对话建模,但无一例外,都需要一个自然语言生成(nlg)模块,该模块在生成过程中,搜索空间巨大,他们往往是巨大的黑盒子。采用该模块,可控性极差,而且由于中文的连续性较强,该模型的长句子生成需要很高的模型和硬件要求,很难满足工业应用的算力和及时性要求。
17.基于此,亟需一种语义推断对话检索方法,应用了快速文本分类,分块检索等技术,来支持对不同主题对话的检索并针对nli(natural language inference),自然语言推理进行检索。
技术实现要素:
18.为解决目前现有技术针对不同主题对话的检索没有自然语言推理进行检索以及没有完整检索系统处理三大挑战的问题,本发明提出预训练对偶注意力神经网络语义推断
对话检索方法及系统、检索设备、存储介质,本发明的技术方案如下:
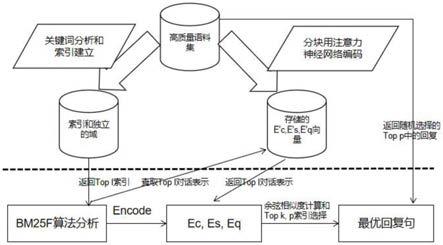
19.方案一:预训练对偶注意力神经网络语义推断对话检索方法,该方法通过首先数据预处理、对话分块和预编码、关键词分析和检索建立,其次利用bm25f算法选取检索分数为top l的对话并对话分块,再次,将语义文本编码和向量化余弦相似度交互,通过用户状态追踪中的对偶注意力学习结合学习排序、对话检索nli,最终,生成预训练模型,完成预训练对偶注意力神经网络语义推断对话检索方法。
20.进一步地,该方法的具体步骤如下:
21.步骤一,在网络论坛上爬取多轮主题数据,将所有对话者的聊天内容的每一条作为节点完成初始化过程;
22.步骤二,按照对话文本的特点,对语料库中的对话文本进行分块,并使用预训练注意力神经网络进行编码,并将编码结果按照文本的分块组织成句向量表示为矩阵向量;
23.步骤三,使用了bert分词技术,对每一条数据建立了不同的检索域;
24.步骤四,采用bm25f算法,获得用户查询的上下文之后,采用相同的检索域分析即状态分析与追踪,选取出检索分数为top l的对话;
25.步骤五,将对话分块并处理编码和向量化余弦相似度交互后进行比较;
26.步骤六,对语义蕴含关系建模,进行语义推断的,最终形成对话检索的模型,完成基于预训练对偶注意力神经网络语义推断。
27.进一步地,在步骤一中,所述初始化过程细化为:
28.在公开匿名网络论坛上爬取多轮主题数据,按照主题分类设置不同的标签,将所有对话者的聊天内容的每一条作为节点,对于每一条节点,与其周围的最近的那一或两组不同身份发言者的聊天内容之间有且仅有一条边,记录从主题开始到结束的每一条路径,得到由该论坛主题的对话。
29.进一步地,在步骤五中,所述交互后进行比较的过程,包括基于分类算法的用户状态追踪、学习排序和客户服务对话检索nli。
30.进一步地,所述基于分类算法的用户状态追踪,具体细化为:分类算法是基于electratransformer的深度学习的分类算法预测当前聊天领域、用户的烦恼类型和心理状况危险等级,在数据集上进行训练和验证,采用了self
‑
attention解决方案,让每个time step 的输出考虑了全局的输入,并可以并行计算;之后形成多个子空间,将查询句q,候选对话的历史信息组成的键值k和需要查询的对话句v各自切成多个来进行细粒度的 self
‑
attention。
31.进一步地,所述学习排序,具体指把对话视作文档,经过对话分类以及关键词分析之后,每个文档都会被分析成多个独立的域,并分配权重利用bm25f对每一个单词在各个field中分值的加权求和。
32.进一步地,所述客户服务对话检索nli过程,先将训练集中的对话进行分块,然后将对话结构进行nli建模,具体步骤如下:
33.步骤五一,nli中文训练,对模型生成概率进行定义,其中θ为注意力模型参数,和余弦相似度组成的回归规则;
34.步骤五二,对于长对话的最后若干轮次进行满足几何分布的运算,得到预训练参数;
35.步骤五三,对于数据集中对话,利用余弦相似度的形式拟合蕴含关系的概率期望,采取均方差损失计算损失函数,由此得到了全部预训练目标;
36.步骤五四,先根据最后一句话,根据余弦相似度计算最好的结果,之后分别选择与客户序列具有语义上的关联性,与服务序列具有一致性的回复,然后根据根据每一句的得分(scorep)选出p个备选句(top p),最后随机选择备选句中的一个,完成一次检索。
37.方案二:预训练对偶注意力神经网络语义推断对话检索系统,该系统包括数据预处理模块、预编码模块、检索建立模块、对话分块模块、排序模块、nli训练模块和模型生成模块;
38.预处理模块将对话进行收录,传输至预编码模块进行初步编码,通过检索模块筛选对话并发送至对话分块模块进行区分、排序模块进行数据整理后传输至nli训练模块利用对偶注意力机制进行神经网络训练,最后由模型生成模块建立预训练对偶注意力神经网络语义推断对话检索系统。
39.方案三:预训练对偶注意力神经网络语义推断对话检索设备,其特征在于:包括存储器和处理器,存储器存储有计算机程序,所述的处理器执行所述计算机程序时实现上述的预训练对偶注意力神经网络语义推断对话检索方法的步骤。
40.方案四:一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述的预训练对偶注意力神经网络语义推断对话检索方法及系统。
41.本发明有益效果体现在:
42.相比于现有技术提出的深交互神经网络需要大量的相应时间,在实际应用中,使用intel(r)core(tm)i5
‑
8250u cpu@1.60ghz,1800mhz,4个内核,8个逻辑处理器的处理器,这些方法最快仅能达到2it/s,而本发明通过预编码,向量化等方法,采取浅交互神经网络的思想,同样的cpu下能够达到46it/s以上的速度,在速度上提升了23 倍,并且能够在短时间内处理大量的对话。
43.传统使用了cnn,lstm等层数与表示能力有限的神经网络,而本发明采用了目前基于注意力机制的最快的electra神经网络,通过对对话历史中单句对应对话总体的语义蕴含关系期望建模、对话历史以及查询句对回复的语义蕴含关系的建模,提升长对话检索效果,该神经网络做语义文本相似任务sts[semantic text similarity i.e. nli(nature language inference)]的准确度能够达到80%,而现有技术准确率至多能达到 76%。
[0044]
另外,本发明借鉴了深交互神经网络的一些优点,对于对话当中的nli任务进行了更符合中文对话逻辑的设计。即基于用户状态,学习排序方法,单轮对话检索nli,多轮服务检索nli,多轮客户检索nli的5个阶段的检索,通过满足五个阶段分别所需的条件,从而检索出能够很好的解决三大挑战的回复句。
附图说明
[0045]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
[0046]
图1为五个阶段的检索方法总架构图;
[0047]
图2为multi
‑
head注意力神经网络结构图;
[0048]
图3为两种注意力效果对比图;
[0049]
图4为electra transformer模型示意图;
[0050]
图5为es为electra模型的编码结果图;
[0051]
图6为中文nli预训练模型图;
[0052]
图7为利用几何分布对dialogue nli技术建模训练过程示意图;
[0053]
图8为预训练对偶注意力神经网络语义推断对话检索系统结构图。
具体实施方式
[0054]
通过参照附图更详细地描述本公开的示例性实施例。虽然附图中显示示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解各个实施方式,并且能够将技术涵盖的范围完整的传达给本领域的技术人员。
[0055]
具体实施方式一:预训练对偶注意力神经网络语义推断对话检索系统,该系统包括数据预处理模块、预编码模块、检索建立模块、对话分块模块、排序模块、nli训练模块和模型生成模块;
[0056]
预处理模块将对话进行收录,传输至预编码模块进行初步编码,通过检索模块筛选对话并发送至对话分块模块进行区分、排序模块进行数据整理后传输至nli训练模块利用对偶注意力机制进行神经网络训练,最后由模型生成模块建立预训练对偶注意力神经网络语义推断对话检索系统。
[0057]
具体实施方式二:预训练对偶注意力神经网络语义推断对话检索方法,该方法包括:
[0058]
1.数据预处理:
[0059]
首先在公开匿名网络论坛上爬取多轮主题数据,将所有对话者的聊天内容的每一条作为节点,楼主,非楼主两个身份的对话总是交替出现,对于每一条节点,与其周围的最近的那一或两组不同身份发言者的聊天内容之间有且仅有一条边,且其方向指向发言顺序。则如图1所示中从主题开始到结束的每一条路径都是由该论坛主题得到的对话。
[0060]
网络论坛中的主题可以按照不同的标签进行分类,将电影,美食,数码设备,时尚等领域中的数据集分别进行融合。对于用户情感,这里去匿名公开心理咨询论坛中进行了相似的处理。将对话按照心里状况危险等级和烦恼类型进行了对应主题的分类,心理状况等级包括,
①
无烦恼,
②
有烦恼,
③
心理疾病,
④
伤害自己或他人,四个等级,烦恼类型有个人成长,情感问题,人际交往,工作学习压力等。
[0061]
通过开发了人工标注脚本,进行了严格的数据清洗,将不符合开放域聊天要求的数据筛选掉,不符合群体价值观的言论筛选掉。得到了高质量语料集。
[0062]
2.对话分块和预编码:
[0063]
按照对话文本的特点,对语料库中的对话文本进行分块,并使用预训练注意力神经网络即经历多次nli(自然语言推断)任务训练的预训练模型进行编码。并将编码结果按照文本的分块组织成句向量表示矩阵向量。该步骤在离线系统下分批完成,以减小线上搜索的性能开销。
[0064]
3.关键词分析和检索建立:
[0065]
使用了bert分词技术,将单轮对话查询句拆分成词汇集合,将停用词表中的词汇从这个词汇集合中删除,并将多轮对话查询上下文中的每一句话进行收尾连接,做类似的分析,对每一条数据建立了不同的检索域,检索域包括:文本检索域,关键词检索域,若存在单轮对话,则定义对话主题检索域。
[0066]
4.bm25f算法:
[0067]
至此线上推理阶段已经完成,在线下推理阶段,获得用户查询的上下文之后,采用相同的检索域分析即状态分析与追踪过程。包括分词,关键词召回,和文本分类技术。之后数据库中进行多检索域的bm25f算法,选出检索分数为top l的对话。
[0068]
5.对话分块、编码和向量化余弦相似度交互:
[0069]
本部分使用了前面描述的预训练模型对用户查询上下文分块进行编码,余弦相似度计算,由于句向量已经预编码完毕,只需在检索过程中利用索引查表,在加以向量化操作并进行比较,大幅度提升了检索性能。需要注意的是,不同的分块会采取不同的顺序进行top k,top p检索,具体过程描述如下:
[0070]
对于对话当中的nli任务进行了更符合中文对话逻辑的设计。即:基于分类算法的用户状态追踪、学习排序方法、单轮对话检索nli、多轮服务句检索nli和多轮客户句检索nli;通过满足上述四个阶段分别所需的条件,从而检索出能够很好的解决三大挑战的回复句,以下是方法描述:
[0071]
5.1基于分类算法的用户状态追踪:
[0072]
分类算法是基于electra transformer的深度学习的分类算法,能够预测当前聊天领域,用户的烦恼类型,心理状况危险等级,在数据集上进行训练和验证,宏f1准确度平均值达到95%。
[0073]
首先,对于语言模型,最早的也是最常见的处理是使用rnn和cnn来处理。
[0074]
如图2所示,rnn是对序列进行一个线性的流线型处理。那么它的缺点也很明显,即,它的计算很难并行化,从而使处理速度变慢。
[0075]
所以,为了解决这个问题,采用了“attention is all you need”的self
‑
attention解决方案:让每个时间步(time step)的输出考虑了全局的输入,并可以并行计算。下面详细描述multi
‑
head self
‑
attention(对偶自注意力机制):
[0076]
为了能够多角度的理解对话者的问题,采取了attention routing的做法,形成多个子空间,可以让模型去关注不同方面的信息。
[0077]
具体做法是将查询句q,候选对话的历史信息组成的键值k和需要查询的对话句v 各自切成多个来进行细粒度的self
‑
attention,相较于self
‑
attention,它的表现能力更加的优秀。
[0078]
采取了electra transformer模型,具有以下的特点:
[0079]
提出了新的模型预训练的框架,采用生成者和辨别者的结合方式,但又不同于 gan将masked language model的方式改为了分辨已替换的代文。
[0080]
因为masked language model能有效地学习到上下文的信息,所以能很好地学习编码,所以使用了共享参数的方式将生成者的编码的信息共享给辨别者,辨别者预测了生成者输出的每个代文是不是原有的,从而高效地更新transformer的各个参数,使得模型的
熟练速度加快
[0081]
该模型采用了小的生成者以及辨别者的方式共同训练,并且采用了两者loss相加,使得辨别者的学习难度逐渐地提升,学习到更难的代文。模型在微调的时候,丢弃生成者,只使用分辨者
[0082]
在小模型的表现上,electra的效果更好,所以electra的目前的作用主要在于使用小的electra模型,在不能使用gpu的场景,或者性能要求高的场景,可以得到好的结果。
[0083]
根据聊天主题,用户心理状态,心理危险等级将对话分成多个范畴,并在每个范畴内对模型参数进行多标签分类优化,分类损失函数为交叉熵损失。
[0084]
5.2学习排序方法:
[0085]
bm25f是对bm25的修改,该文档被认为是由几个可能不同重要程度、术语相关度和长度规范化的字段(如标题、主文本、锚文本)组成的。bm25f是典型bm25的改进算法。bm25在计算相关性时把文档当做总体来考虑。
[0086]
把对话视作文档,经过对话分类以及关键词分析之后,每个文档都会被分析成多个独立的域,尤其是垂直化的搜索。这些域对对话主题的贡献不能同等对待,所以权重就要有所偏重。bm25没有考虑这点。所以bm25f在此基础上做了一些改进,就是不再单单的将单词作为个体考虑,并且将文档也依照field划分为个体考虑,所以 bm25f是每一个单词在各个field中分值的加权求和。
[0087]
5.3客户服务对话检索nli:
[0088]
这一方法仍然使用了electra transformer模型进行微调,但是采取了bi
‑
encoder结构,进行文本相似度和文本蕴含计算。
[0089]
在对话检索中,判断蕴含或是矛盾的关系十分必要,例如信息检索、语义分析、常识推理等方面都会用到。评价标准简单有效,可以直接在对话检索中专注于语义理解和语义表示,将对话表示向量投影到正交空间中,用余弦相似度衡量对话表示的蕴含或矛盾关系。
[0090]
而对于单多轮nli,实现过程如下:
[0091]
s1.先将训练集中的对话进行分块:
[0092]
c:多轮客户查询序列,该段序列将用户对聊天系统的后k条输入首尾相连,用“,”分隔;
[0093]
s:多轮服务查询序列,该段序列将系统对用户的回复后k条输入首尾相连,用“,”分隔;
[0094]
q:单轮查询序列,该段序列即为用户目前的最后一句输入;
[0095]
a:期望回复序列,该段序列即为系统期望回复。
[0096]
对语料库中的多轮对话t,由用户对话ci,和系统回复si组成,即:
[0097]
t={c0,s0,c1,s1
…
,cn,sn}
……
(1)
[0098]
特别的,将用户短时间内连续的分段对话拼接成一段对话ci。那么,抽取所有的用户对话序列集合:
[0099]
c={c0,c1
…
,cn
‑
1},s={s0,s1
…
,sn
‑
1}
……
(2)
[0100]
由于采用序列模型,为了融合,提取集合c、s中的信息,通过拼接获得,
[0101]
[0102][0103]
其中为字符串拼接符。
[0104]
那么用户请求:
[0105]
q=cn
……
(5)
[0106]
系统回复:
[0107][0108]
那么多轮对话的t数据可以重新组织为:
[0109]
t’={c’,s’,c,s,q,a,a’}
……
(7)
[0110]
经过electra预训练模型,将t编码为:
[0111]
t’e={c’e,s’e,c e,s e,q e,a’e}
……
(8)
[0112]
s2.对话结构进行nli建模:
[0113]
对于任意的c∈c,即每条客户输入,都蕴含于c,但是c中的越靠后的输入,与 c有着更强的关联。
[0114]
假设c对c的蕴含关系沿着对话顺序的逆序符合几何分布,倒数第i条输入ci对于c的蕴含关系期望为p(1
‑
p)i
‑
1其中p是经验参数,这里,采用p=0.3。
[0115]
s有着与c相同的组织形式和任务描述。
[0116]
s,c,q都应该与a中的语义在查询,回复过程中存在蕴含关系,因此需要将a 加一个前缀,如“[sentencea]”代文,electra transformer在编码这个代文的时候,会将a投影在s,c,q所在的空间中。因此可以通过余弦相似度计算a与s,c,q表示的蕴含关系。
[0117]
用electra transformer bi
‑
encoder模型做中文nli预训练,然后微调拟合c和s的蕴含关系期望,在此之后,用a与s,c,q表示的蕴含关系训练微调模型。得到的模型可以从学习排序后的备选句中高速地选择最符合多轮语境的回复。
[0118]
以上部分的数学描述如下:
[0119]
(a)nli中文训练:
[0120]
首先对模型生成概率进行定义,其中θ为注意力模型参数,和余弦相似度组成的回归规则。
[0121]
pθ(q;ae)=1
……
(9)
[0122]
pθ(q;ac)=0
……
(10)
[0123]
pθ(q;as)=0.5
……
(11)
[0124]
其中ae表示与q有蕴含关系的句子,ac表示矛盾关系,as表示中立关系,至此得到与训练的模型参数θ”。
[0125]
(b)建立对用户
‑
模型的nli任务:
[0126]
对于长对话的最后n个轮次来说,蕴含关系期望满足几何分布:
[0127]
x~ge(p)
……
(12)
[0128]
于是:
[0129]
pθ’(x=i)=pθ’(c;ci)=p(1
‑
p)i
‑1……
(13)
[0130]
至此得到预训练参数θ”。
[0131]
(c)单轮nli:
[0132]
对于数据集中第j,k个对话
[0133]
pθ”(ck;ak)=pθ”(sk;ak)=pθ”(qk;ak)=1
……
(14)
[0134]
pθ”(ck;aj)=pθ”(sk;aj)=pθ”(qk;aj)=0
……
(15)
[0135]
由于上面的(9)
‑
(15)式都是用余弦相似度的形式拟合蕴含关系的概率期望,于是损失函数要采取均方差损失:
[0136]
l=(pθ
‑
pt)2
……
(16)
[0137]
在(c)节中使用的对比学习方法的训练损失如下:
[0138][0139]
其中k为训练一步时的一批训练集数据,φ代表模型参数,得到了全部预训练目标。
[0140]
(d)nli top k,p检索:
[0141]
在对话过程中,对话者通常更加在意上下文中的最后一句话,并且忽视这句话会导致怪异的检索结果,因此需要先根据这个最后一句话来选取最好的一批top k结果。
[0142]
计算:
[0143]
scorek=sim(qe,qe’)
……
(18)
[0144]
则根据余弦相似度选出top k。
[0145]
然后需要分别选择与客户序列具有语义上的关联性,与服务序列具有一致性的回复。上面的预训练,使得该语义推断得以进行。
[0146]
scorep=sim(ce,ce’)*λ+sim(se,se’)(1
‑
λ)
……
(19)
[0147]
然后根据scorep选出top p,最后随机选择备选句中的一个,即完成一次检索。
[0148]
6.生成预训练模型:
[0149]
可以使用bert,albert等各种预训练模型替换electra预训练模块,electra只是当前状况下效率最高的预训练模型。使用位置编码,代文类型编码提升类似本方法效果,使用其他经典概率模型对语义蕴含关系建模,进行语义推断的。
[0150]
具体实施方式三:本领域内的技术人员通过上述实施例提及的方法,本实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式,模块之间也可根据计算机逻辑结构进行重新组织。而且,本实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等) 上实施的计算机程序产品的形式。
[0151]
根据本实施例的方法、设备(系统)、和计算机程序产品的流程图或方框图来描述的。应理解可由计算机程序指令实现流程图或方框图中的每一流程或方框、以及流程图或方框图中的流程或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程或方框图一个方框或多个方框中指定的功能的装置。
[0152]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指
令装置的制造品,该指令装置实现在流程图一个流程或多个流程或方框图一个方框或多个方框中指定的功能。
[0153]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程或方框图一个方框或多个方框中指定的功能的步骤。
[0154]
在一个典型的配置中,计算设备包括一个或多个处理器(cpu)、输入/输出接口、网络接口和内存。
[0155]
存储器可能包括计算机可读介质中的非永久性存储器,随机存取存储器(ram)和/或非易失性内存等形式,如只读存储器(rom)或闪存(flash ram)。存储器是计算机可读介质的示例。
[0156]
计算机可读介质包括永久性和非永久性、可移动和非可移动媒体可以由任何方法或技术来实现信息存储。信息可以是计算机可读指令、数据结构、程序的模块或其他数据。计算机的存储介质的例子包括,但不限于相变内存(pram)、静态随机存取存储器(sram)、动态随机存取存储器(dram)、其他类型的随机存取存储器(ram)、只读存储器 (rom)、电可擦除可编程只读存储器(eeprom)、快闪记忆体或其他内存技术、只读光盘只读存储器(cd
‑
rom)、数字多功能光盘(dvd)或其他光学存储、磁盒式磁带,磁带磁盘存储或其他磁性存储设备或任何其他非传输介质,可用于存储可以被计算设备访问的信息。按照本文中的界定,计算机可读介质不包括暂存电脑可读媒体(transitory media),如调制的数据信号和载波。
[0157]
以上仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1