随机森林模型训练中参数选择的优化方法、系统、设备
1.本发明属于模型优化技术领域,尤其涉及一种随机森林模型训练中参数选择的优化方法、设备、终端。
背景技术:
2.目前,相对于机器学习中的一些基本学习算法,随机森林算法被证明了拥有更高的分类准确率,而且在非线性分类问题中同样表现出更好的分类性能。因此随机森林算法经常被国内外很多研究者使用在分类预测问题上。zhou等人通过一个选择性集成算法组合多棵决策树构建随机森林模型,并淘汰预测性能低的决策树,提高了模型的准确率。el
‑
adawi r等人提出统计封锁法,使用支持向量机和随机森林来对尾点进行识别分类,结果证明在一定情况下随机森林的分类准确率要比支持向量机好很多。
3.除此之外,随机森林的并行化特点还被研究者们广泛使用在大数据集的处理中。li等人提出在spark平台上使用随机森林算法,并行化的特点使随机森林算法的执行速度大大的加快,但是并没有进行优化算法等方面的研究。刘凯等人同样在spark平台上运行随机森林算法,并且加上了自适应的特征选择方法。在卡方检验的基础上,引入自适应稀疏约束机制来删除冗余特征,并通过实验证明了优化后的随机森林算法对分类结果的准确率有明显的提升。
4.从随机森林被提出,就有不少研究对随机森林进行使用、对比以及优化改进。而更多研究重点则是在随机森林算法的改进上,包含了三个方面,一是数据集上:孟海东通过敏感度的设置来增加决策树对数据集中少数类的分类能力,并利用hadoop实现了算法的更新。杨杰明提出了一种根据类的区分度来实现k
‑
means聚类的方法,降低了少数类的识别错误率。jia j等人通过pca算法对数据集进行预处理,在一定程度上消除了弱决策树。二是特征选择上:lu等人开发了一个数据驱动的框架,用于识别复杂技术的关键组件来匹配特征选择。marie等人将变量聚类与特征选择进行结合,最终选择相关性最高的变量组来完成随机森林的建立。rui yao通过路径选择建模方法来进行特征选择,并结合聚类的方法识别路径特征,实验证明该方法不仅解释力强,而且具有较高的预测精度。kanakarajan n k等人利用随机自适应搜索方法的退火随机性来进行特征选择,提高了分类的准确性。三是参数选择上:probst p等人提出一种参数调整策略用于参数的选择,在实际测试中该方法有效地提高了随机森林算法的分类准确率。周天宁等人首先改进了传统的网格算法,并分析了遗传算法,然后分别用这两种算法对随机森林的两个参数进行优化选择。马骊则是通过混合智能算法,通过将遗传算法,粒子群算法,人工鱼群算法与随机森林算法进行结合,然后进行随机森林的参数选择。实验证明从多个评价指标出发,结果均优于传统的参数取值。
5.综上所述,为了减少分类模型的复杂度和计算成本,实现大规模分布式处理的网络流量分类模型还要进一步的进行研究,这也是目前随机森林算法发展的方向。
6.通过上述分析,现有技术存在的问题及缺陷为:
7.(1)现有针对随机森林算法的技术方案,没有进行优化算法等方面的研究,量子遗
传算法的实现上,根据优化目标的不同,实现的效率可能不同。
8.(2)单一的随机森林算法会出现过拟合的现象以及对少数类的分类不够准确,同时不好在准确率与计算开销上达到一个平衡的问题,需要进行不断地优化与改进。
9.解决以上问题及缺陷的意义为:对随机森林的模型构建具有一定帮助,提高准确率,而且不仅可以优化随机森林算法,还可适用于机器学习的其他算法。
技术实现要素:
10.针对现有技术存在的问题,本发明提供了一种随机森林模型训练中参数选择的优化方法、系统、设备。
11.本发明是这样实现的,一种随机森林模型训练中参数选择的优化方法,所述随机森林模型训练中参数选择的优化方法包括以下步骤:
12.步骤一,确定随机森林的参数影响;掌握随机森林构建中的关键因素,以及影响随机森林分类性能的点,准确有效的对随机森林进行优化。
13.步骤二,构建基于qga
‑
rf的参数优化算法;提出一个算法的执行流程,对整个算法的介绍会更加全面。
14.步骤三,进行基于量子遗传算法的随机森林优化。有实验做对照,帮助进行结果的分析。
15.进一步,步骤一中,所述确定随机森林的参数影响,包括:
16.当使用随机森林算法对网络流量进行分类预测时,在原始数据集一定的情况下,影响模型分类准确率及运算时间的因素包括训练一棵决策树时需要随机选取的特征子集中的特征数量k和最终形成的随机森林模型中决策树的数量n。
17.进一步,使用cart决策树作为随机森林分类模型中的基本学习器,因为cart决策树在分类和回归问题上都有良好的分类性能。cart决策树使用基尼系数作为节点划分时特征选择的指标。假设样本集合为x,其中包含m个类别,第i个类在集合中所占的比例为p
i
(i=1,2,3...,m),则集合x的基尼系数如公式所示:
[0018][0019]
当以特征a划分节点时,在a的条件下,集合x的基尼系数可表示为:
[0020][0021]
其中,v表示a有v个取值,|x
v
|表示在a=v时集合包含的样本数量。
[0022]
进一步,根据随机森林分类模型的实现过程发现:
[0023]
(1)在构建随机森林分类模型时,经过随机取样会得到的n个样本集,每一个样本集会对应的训练一棵决策树。在训练过程中又需要从总的特征集中随机地抽取指定数量的特征来构成决策树划分的特征子集,而k的大小就决定了单个决策树的分类性能以及两两决策树之间的相关程度。当k值越小时,单一决策树的分类能力会下降,但是随机森林的随机性提高,同时决策树之间的相关性会越低,因此整体随机森林模型的分类性能会加强。现有文献计算了几个具有代表性的k值,并得到了一个较好的分类效果。因此一个合适的k值
会使算法有一个更好的表现。
[0024]
(2)由于随机森林分类模型采用的是投票法进行决策,故森林规模即决策树的数量n决定票数和准确率;根据大数定理,当n增大时,模型被证明泛化误差会收敛,模型的分类性能会逐渐稳定,不会出现过训练的问题,且在一定范围内会有一对超参数组合使准确率达到最高,组合中n的值不一定是范围内的最大值,故在考虑时间空间成本的前提下寻找使分类准确率最高的超参数n。
[0025]
超参(k,n)的选择成为随机森林分类模型建立中一个重要的环节,通过使用改进的量子遗传算法对超参数(k,n)进行选择与优化。
[0026]
进一步,步骤二中,所述构建基于qga
‑
rf的参数优化算法,包括:
[0027]
通过介绍量子遗传算法和随机森林算法中需要进行优化的参数,提出基于量子遗传算法的随机森林qga
‑
rf参数优化算法。该算法的目的是探究模型分类性能与超参数(k,n)的关系,寻找最佳的超参数组合来达到最优的分类性能。
[0028]
直接使用模型的分类准确率表现最终模型的泛化能力。其中,根据对随机森林中超参数的了解与分析,以及考虑时间和空间的计算成本,将k和n的取值范围定为:[1,m]和[1,64]。m为数据集中总的特征数量,64是根据计算机的计算能力,与时间成本综合考虑下决定的。
[0029]
进一步,步骤二中,所述构建基于qga
‑
rf的参数优化算法,还包括:
[0030]
(1)确定(k,n)的取值范围,然后根据qga使用多个单量子比特来表示一个染色体x:
[0031][0032]
其中,前i个量子位的组合表示k,后面第i+1位至t位表示n,使用正余弦的方式来编码染色体x:
[0033][0034]
(2)初始化种群:确定种群数量m,最大迭代次数maxgen和量子突变概率p
m
;使用一个随机数r1(r1∈[0,1]),在初始化种群的时候不再等分种群,而是对每一个染色体x的每一个量子位上的θ乘上一个r1,即初始化的染色体x表示为:
[0035][0036]
(3)量子坍缩:在每一轮的迭代中无法直接对一个量子态进行适应度值的计算,需要一个量子坍缩的过程,设置一个随机数r2,若r2>cos2θ
i
,则对应的第i位量子比特坍缩到1,否则为0。以此来进行进制转换得到十进制下的(k,n)。
[0037]
(4)使用随机森林分类模型的分类准确率作为染色体个体的适应度值进行判断,即:
[0038]
fit(x)=accuracy(k,n);
[0039]
(5)量子旋转门更新:使用自适应的旋转角对传统量子旋转门进行改进。
[0040]
(6)量子突变:设置第三个随机数r3,∈[0,1],当r3<p
m
时发生量子突变。
[0041]
使用哈达玛门即hadamard门进行改进,其形式为:
[0042][0043]
相对于量子非门,hadamard门所改变的旋转角小了设置一个控制参数c,并根据下式判断使用哪一种量子门:
[0044][0045]
式中,f
max
代表当代中染色体最佳的适应度值,f
avg
代表当代中所有染色体适应度值的平均值。当公式成立时,认为种群中只有少数个体适应度高,此时需要大幅转变,因此使用量子非门进行突变,反之则使用hadamard门。
[0046]
(7)判断是否达到最大的迭代次数;是,则停止算法给出最优解;否,则进入步骤(3)进行下一轮迭代。
[0047]
进一步,步骤三中,所述量子遗传算法的步骤,包括:
[0048]
(1)编码:qga最大的特点就是用量子态的形式对染色体进行编码,一个量子位上的量子态表示一个特征信息;同时每个量子态用下式表示,且|0>和|1>可作为标准正交基,表示为:
[0049][0050]
叠加态|ψ>则可用下式表示,对一个具有t个基因的染色体x进行量子态编码,其叠加态|ψ>可表示为:
[0051][0052]
其中,|α
i
|2+|β
i
|2=1,i∈{1,2,3...t},因此叠加态|ψ>也可记为:
[0053][0054]
这种编码方式只使用θ一个参数,使得算法更加简洁,并且在进行量子门旋转时也会更加直观。
[0055]
(2)初始化种群:使用叠加态|ψ>公式编码时θ随机产生。
[0056]
(3)量子坍缩:经过量子坍缩,即对量子态进行观测;在区间[0,1]上生成随机数r,判断,若r>|α
i
|2,则对应的第i位量子态坍缩到1,否则为0。
[0057]
(4)适应度函数:确定一个适应度函数,并计算每一个染色体的适应度值,用于每一轮迭代的进化和最终选择。
[0058]
(5)量子旋转门:利用量子旋转门对量子态进行更新,是实现二维希尔伯特空间矢量变换的一种方式。使用量子旋转门来实现个体向最优个体的转变,其形式表示为:
[0059][0060]
其中,θ
′
为旋转角,由公式:θ'=δθ
·
s(cosθsinθ)确定;δθ为旋转角的大小,s(cosθsinθ)决定了旋转的方向。对于任意量子位进行量子旋转门更新操作得:
[0061][0062]
其中,是第i位更新后的量子态。通常旋转角和旋转方向是定好的。通过旋转规则,可以发现若当前个体的适应度值大于当代最佳的个体时,旋转方向会向着有利于当前个体的方向旋转,反之则会向着最佳个体旋转,这确保了更新操作始终是向着最优方向去收敛的。
[0063]
使用自适应方法来动态调整旋转角的大小。当需要更新的个体适应度值与当代中最佳个体的适应度值差距过大时,进行较大角度的旋转,反之则进行小角度的旋转。
[0064]
自适应的δθ调整方案如下:
[0065][0066]
其中,δθ∈[0.01π,0.05π],θ
a
和θ
b
分别表示区间上的最小和最大值。f
max
表示当代最佳的适应度值,f
cur
表示需要进行更新的个体的适应度值。此方案将适应度与旋转角结合在一起,自适应的调节旋转角大小,提高算法的收敛速度。
[0067]
(6)量子突变:在qga中使用一个量子非门,即pauli
‑
x门进行量子突变。量子非门可表示为:
[0068][0069]
对任意一个叠加态|ψ>实施突变操作可得:
[0070][0071]
量子非门的操作效果与ga中的变异基本无异,qga中,突变后的量子位可见是对基本态概率幅的一次交换,使其被观测时得到0或1的概率进行了交换,达到突变的目的。
[0072]
本发明的另一目的在于提供一种应用所述的随机森林模型训练中参数选择的优化方法的随机森林模型训练中参数选择的优化系统,所述随机森林模型训练中参数选择的优化系统包括:
[0073]
参数影响确定模块,用于确定随机森林的参数影响;
[0074]
参数优化算法构建模块,用于构建基于qga
‑
rf的参数优化算法;
[0075]
随机森林优化模块,用于基于量子遗传算法进行随机森林优化。
[0076]
本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器
执行如下步骤:
[0077]
(1)确定随机森林的参数影响;
[0078]
(2)构建基于qga
‑
rf的参数优化算法;
[0079]
(3)进行基于量子遗传算法的随机森林优化。
[0080]
本发明的另一目的在于提供一种信息数据处理终端,所述信息数据处理终端用于实现所述的随机森林模型训练中参数选择的优化系统。
[0081]
结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明提供的随机森林模型训练中参数选择的优化方法,随机森林算法在机器学习中本就有着不错的分类性能,通过实验又证明了经过qga的优化,随机森林算法的分类性能又获得了提升,而且模型的训练时间也在可接受范围内;qga相较于ga有更好的全局搜索能力,且不易陷入局部最优解。本发明使用改进的qga对随机森林分类模型进行优化,给出了随机森林中两个参数对模型分类性能的影响,并通过qga搜索出一对最优的参数解,最后通过实验证明了该方法的有效性。
附图说明
[0082]
为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
[0083]
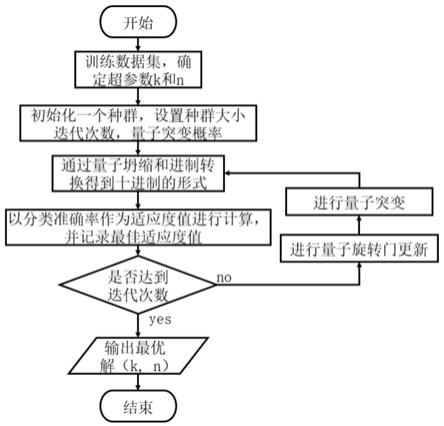
图1是本发明实施例提供的随机森林模型训练中参数选择的优化方法流程图。
[0084]
图2是本发明实施例提供的随机森林模型训练中参数选择的优化系统结构框图;
[0085]
图中:1、参数影响确定模块;2、参数优化算法构建模块;3、随机森林优化模块。
[0086]
图3是本发明实施例提供的随机森林算法流程图。
[0087]
图4是本发明实施例提供的cart决策树算法流程图。
[0088]
图5是本发明实施例提供的ga中交叉操作示意图。
[0089]
图6是本发明实施例提供的ga流程图。
[0090]
图7是本发明实施例提供的qga
‑
rf的参数优化算法流程图。
[0091]
图8是本发明实施例提供的机器学习中不同算法的对比示意图。
[0092]
图9是本发明实施例提供的种群数量为10和20时qga的迭代过程示意图。
[0093]
图10是本发明实施例提供的qga与ga对rf参数优化的迭代过程示意图。
具体实施方式
[0094]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0095]
针对现有技术存在的问题,本发明提供了一种随机森林模型训练中参数选择的优化方法、系统、设备,下面结合附图对本发明作详细的描述。
[0096]
如图1所示,本发明实施例提供的随机森林模型训练中参数选择的优化方法包括以下步骤:
[0097]
s101,确定随机森林的参数影响;
[0098]
s102,构建基于qga
‑
rf的参数优化算法;
[0099]
s103,进行基于量子遗传算法的随机森林优化。
[0100]
如图2所示,本发明实施例提供的随机森林模型训练中参数选择的优化系统包括:
[0101]
参数影响确定模块1,用于确定随机森林的参数影响;
[0102]
参数优化算法构建模块2,用于构建基于qga
‑
rf的参数优化算法;
[0103]
随机森林优化模块3,用于基于量子遗传算法进行随机森林优化。
[0104]
下面结合实施例对本发明的技术方案作进一步描述。
[0105]
1、概述
[0106]
(1)了解了智能优化算法中遗传算法的基本概念,通过该算法的实现流程,分析其存在的问题以及可进行优化的环节。因传统遗传算法在一定情况下会出现过早收敛的问题,所以提出使用量子遗传算法来替换遗传算法。并且在量子遗传算法实现的过程中进行改进,对其编码方式,量子旋转门的更新进化策略以及量子突变过程进行优化,使量子遗传算法的性能得到进一步的提升。
[0107]
(2)将改良后的量子遗传算法用于随机森林模型的训练中,对随机森林中的两个超参数进行优化选择。目的是为了减小随机森林分类模型的训练时间以及提高随机森林分类模型的分类准确率。并通过实验证明了经过量子遗传算法优化后的参数选择对随机森林分类模型的建立具有积极作用。
[0108]
2、随机森林算法概述
[0109]
leo breiman提出的随机森林算法(random forests,rf)是bagging算法的一个扩充,在bagging的基础上引入随机特征选择的方法。随机森林是将一定数目的cart决策树作为基学习器构建组成的分类模型,通过投票法根据多数原则决定分类结果。一般随机森林算法执行的流程图如图3所示。
[0110]
2.1决策树
[0111]
决策树(decision tree)作为随机森林模型中的一个基学习器,是机器学习中常用的一个算法。决策树是一个树形结构,通过从根节点向下传递完成决策,这恰好是研究者们在处理某些问题时,一种很平常的处理方式。决策树的生长中最关键的环节就在于如何去决定节点最佳的划分特征,使末端叶节点上所包含的样本尽量是同一种类别,也就是说决策树中内部节点的纯度会随着分裂程度的加深而越来越高。常用的划分依据有信息熵(information entropy)、信息增益(gain ratio)和基尼指数(gini index),依次对应常用的决策树生成算法id3、c4.5和cart。
[0112]
本发明使用cart决策树作为随机森林分类模型中的基本学习器,因为cart决策树在分类和回归问题上都有良好的分类性能。cart决策树使用基尼系数作为节点划分时特征选择的指标。假设样本集合为x,其中包含m个类别,第i个类在集合中所占的比例为p
i
(i=1,2,3...,m),则集合x的基尼系数如公式所示:
[0113][0114]
当以特征a划分节点时,在a的条件下,集合x的基尼系数可表示为:
[0115][0116]
其中,v表示a有v个取值,|x
v
|表示在a=v时集合包含的样本数量。
[0117]
cart决策树构造简单,计算量小,且具有可读性。同时在很多情况下cart决策树比一般统计方法构造的分类标准更为准确。特别是当数据集十分复杂,特征又很多的情况下该算法越能体现其良好的分类性能。cart决策树的实现步骤见表1所示。
[0118]
表1 cart决策树算法
[0119][0120]
cart决策树算法具体的实现流程图如图4所示。
[0121]
但是cart决策树也存在一定的问题,在分类过程中决策树会容易受噪声的干扰,从而导致错误的分类,而且该算法稳定性不高。这些也都是单一学习器共有的问题。因此,研究者们在单一决策树算法的基础上提出集成学习的思想,以进一步优化算法的稳定性和准确率。
[0122]
2.2随机森林模型
[0123]
集成学习的出现解决了单一学习器所固有的缺陷,通过组合更多的学习器,可以吸收单一学习器的优势,突破自身的局限性。随机森林算法就是集成学习方法下的成果,通过组合任意个随机的基学习器,无限收敛分类问题的泛化误差,提高模型的分类能力。由一定数量的cart决策树组成的随机森林,在随机选择特征子集后以投票法完成分类任务。随机森林中较为重要的内容有随机采样、特征选择、袋外误差率。
[0124]
随机采样:指的是对一个包含有n个数据样本的初始数据集进行有放回的bootstrap随机抽样,即每轮抽样中每个样本被选中的概率都是相同的。经过n次抽取后,可以组成一个新的仍包含n个样本的样本集。通过这样的采样方式,当n趋向于无穷大时,经过计算原始数据集中约有63.2%的数据会出现在新的样本集中。
[0125]
特征选择:体现了随机森林的另一个随机性。在每一棵cart决策树的每一个节点上,从原始特征集中随机选取一个只含有k个特征的子集,然后再从这个子集中挑选最佳的特征进行划分。这个参数k就代表了随机森林随机性的程度。一般情况下k=log
2 m,或
1,m为原始特征集的大小。
[0126]
袋外误差率:随机森林算法使用有放回的bootstrap随机采样,这就意味数据集中有大约36.8%的样本没有参加过学习器的训练。而在随机森林模型中的每一棵cart决策树上,每棵树都会有约36.8%的样本数据未参与到该树的训练过程中,这些为参与该树训练的样本就被称为“袋外数据”(out of bag,oob),可以利用这些“袋外数据”来检验模型的泛化能力和预测效果。而袋外误差率(error
oob
)就是随机森林进行自我检验的度量标准。使用袋外误差率的一个明显优势就在于无需重复训练,只需要找出这些袋外数据即可,而且可以作为随机森林的无偏估计直接使用。
[0127]
2.3存在问题及优化
[0128]
随机森林算法被认为是“代表集成学习技术水平的算法”,具有简洁、易操作等众多优势,在很多现实分类任务中都展现出强大的性能,但也存在一些问题。比如:当训练集中存在部分噪音干扰时,随机森林算法也会出现过拟合的问题;当训练集中的数据不够平衡时,随机森林算法无法对样本数量较小的类进行很好的预测;随机森林要想达到很高的分类准确率就需要扩大森林的规模,但同时也增加了模型的训练时间和不必要的计算开销。这些问题都使得随机森林算法在处理一些现实问题中受到很大的限制。
[0129]
针对训练数据不够均衡的问题,通常从两个方面去解决,一是数据层面,二是算法层面。研究者们一般从数据层面入手,使用重采样的方法来平衡数据集。现有文献通过结合k
‑
means聚类算法和smote过采样技术,在不均衡的数据集上训练随机森林模型,并获得了良好的分类效果。现有文献通过改进模糊c均值算法(fuzzy c
‑
means,fcm),改变度量方式以增加fcm算法的鲁棒性。再结合smote过采样技术提出afcm
‑
smote算法对不平衡数据集进行处理,随机森林的分类性能同样取得了不错的提升。现有文献则选择利用深度学习的生成式对抗网络对数据集进行处理,生成一定数量的少数类样本然后组合原始数据集形成一个分布均匀的数据子集。针对随机森林规模的问题,现有文献提出一种主动随机森林模型构建的方法,通过特定条件来排除精度较低的决策树,以达到降低森林规模的目的。该方法能够平均减少37.5%的随机森林处理时间。现有文献提出一种自适应随机森林算法,该算法可以通过并行操作完成决策树的替换以应对可能发生的概念漂移等问题,在不扩充随机森林规模的前提下保持了良好的分类性能和较少的运算时间。
[0130]
3、量子遗传算法概述
[0131]
本发明详细阐述了遗传算法和量子遗传算法的原理及实现过程,分析了各自的优势和存在的问题,并在量子遗传算法的基础上加以改进。
[0132]
3.1遗传算法
[0133]
遗传算法(genetic algorithm,ga)是于上个世纪六十年代由john holland提出,ga能够模拟自然环境中生物的进化过程,通过“适者生存”的进化理念以及“优胜劣汰”的遗传机理,来建立一种计算模型用于搜索最优解。ga通过多种编码方式将所有的解转化成一条条染色体,这些染色体在进化过程中经过选择(selection)、交叉(crossover)、变异(mutation)的操作不断进化,最终收敛到最佳的群体形态,得到问题的最优解或次优解。
[0134]
ga作为一种智能优化方法包含下面几个特点:一是能直接处理结构化的数据;二是ga的搜索过程是可以并行运算的,而且还能够主动调整搜索方向,具有一定的全局搜寻能力;三是通过染色体的适应度值来进行评价,而且适应度函数不会受连续性函数的影响。
同时ga还是一种非线性的智能优化算法,可以运用到机器学习等多个领域。
[0135]
3.1.1遗传算法基本原理和关键环节
[0136]
1.遗传算法基本原理
[0137]
ga的基本思路是将优化问题的所有解比作自然环境下的一个种群,算法的执行过程就是模拟种群在自然环境下的遗传繁衍过程,通过不断地进化形成最优的种群。
[0138]
在ga中,通过不同的编码方式将染色体进行编码用来表现特征,用适应度值进行评价,这样就构造了染色体编码方式和适应度的映射关系。编码工作实现后,初始化的种群会根据每个染色体的适应度值来进行选择,把每一轮迭代中最适合的基因传递给下一轮,这样优质基因得以留存。染色体的交叉、变异保证了种群的多样性,通过不同的交叉、变异概率能够在一定情况下产生新的染色体,增加ga的全局搜寻能力。经过一定时间的进化,种群会发展到最适合当下环境的一代,此时种群中适应度最佳的染色体就是解决问题的答案,通过解码就可以获得问题对应的最优解或较好的解。
[0139]
2.ga实现的关键环节
[0140]
ga的实现主要包含以下几个关键环节:
[0141]
1)编码
[0142]
ga的种群由染色体构成,每条染色体代表优化问题中的一个解。对于染色体的处理根据实际情况选择合适的编码方式,不同的编码方式会影响后续的运算模式。一般情况下使用二进制编码来简化此过程。除此之外,还有格雷码,浮点数编码等各种形式。一个好的编码方式应具备完整性、鲁棒性和非冗余性等特点。
[0143]
2)确定适应度函数
[0144]
染色体的表现即解的质量由一个适应度函数确定,将解码后的值输入适应度函数,得到的适应度值就代表染色体的适应程度。当优化的问题需求不同时,选择一个恰当适应度函数对算法的执行效率有明显的影响。对于分类问题,可以选择计算交叉验证率和泛化能力作为适应度函数。
[0145]
3)选择(selection)
[0146]
从种群中选择出对环境适应性最好的染色体,并将其优秀基因传递给下一代的过程就是选择。选择的第一步是统计种群中所有染色体的适应度值,以此为基础,适应度较差的被选中的概率就会变小,适应度好的基因会被大概率选中并传递给下一代。常用的选择算子有:轮盘赌方法、随机抽样法、部分选择法等。
[0147]
4)交叉(crossover)
[0148]
类似生物遗传基因的重组,两个随机选择的染色体通过指定的方式和概率进行基因片段的交换,生成两个新的染色体。通过交叉操作可以保证种群的多样性和适应性,ga的搜索能力也得到巨大提升。
[0149]
5)变异(mutation)
[0150]
通过设置的变异概率,某一个染色体会进行变异。染色体上某一基因位的数值会行改变,就相当于发生了基因突变,进而产生一个新的染色体。一般情况下变异概率是比较低的。通过变异可以在保证ga向最优收敛的同时,增加少量新的个体,扩大搜索范围。
[0151]
3.1.2遗传算法实现步骤及流程图
[0152]
1.实现步骤
[0153]
以优化随机森林中特征子集的特征数量k和决策树数量n为例:
[0154]
(a).使用二进制编码方式,例如k=3,n=100时对(k,n)进行二进制编码得到染色体串为[00111100100],串的长度由k和n的最大值决定。
[0155]
(b).初始化种群,设定种群大小pop,以及选择算子,交叉概率p
c
,变异概率p
m
。然后对种群中所有染色体进行编码。确定一个适应度函数,随机森林中一般可使用袋外误差率来作为适应度函数。
[0156]
(c).计算种群中每一个个体的适应度值,并记录。
[0157]
(d).选择。在适应度计算完成后,根据确定的选择算子挑选作为父代的个体,例如:轮盘赌选择,染色体基因的适应度值越大,则该染色体个体被选中的几率就越大。
[0158]
(e).交叉。随机选择两个个体和一个[0,1]之间的随机数r1,当r1<p
c
时发生交叉,交叉位也是随机的。例如:两个染色体a和b分为(3,100)和(2,150),编码后的形式为[001101100100]和[001010010110],交叉后会产生的新染色体a’和b’,过程如图5所示。
[0159]
(f).变异。与交叉一样,生成一个随机数r2,当r2<p
m
时发生变异。变异就是在随机的基因位上将数值进行改变,进而产生一个新的个体。
[0160]
(g).判断算法是否达到停止的条件。可以使用最大的迭代次数作为终止条件,也可以当种群中最佳个体的适应度值达到预期作为条件。输出当代中适应度值最优的个体。若都不成立就进入(c)开始下一轮。
[0161]
(2)遗传算法流程图
[0162]
在图6中给出了实现ga的流程图。
[0163]
3.1.3存在问题及优化
[0164]
ga作为一种优化算法,通过自身优秀的全局能力可以使一般的迭代算法避免陷入局部最优的情况,而且适用范围广,扩展性强。但是在实际使用中,ga自身也不可避免地存在一些问题,比如:编码及解码的过程使算法的实现变得复杂,算法自身包含过多的参数会影响执行效果,在求解复杂问题时也会出现陷入局部最优的情况。
[0165]
针对这些问题对ga进行了不少改进,现有文献在传统ga中引入climbing算法,改进了ga的初始权值和部分阈值,引导和调整ga的搜索方向直到获得全局最优解。现有文献采用精英保留策略,并改进了交叉、变异算子,实验证明该方法提高了求解的精度和效率。现有文献提出了一种基于有效重启和贪心策略的自适应ga,在遗传的不同阶段对交叉、变异算子进行动态调整,并利用重新启动策略克服早熟问题。而mark和ajit二人将量子计算的原理引入ga,形成qga,该算法继承了ga的优势,又增添了量子计算的特点,使得ga得到了更进一步的优化。
[0166]
3.2量子遗传算法
[0167]
上个世纪80年代,美国科学家提出了量子力学以及计算概念,通过利用量子力学的原理进行计算机的仿真,可以突破一些经典计算陷入的困境。随着量子计算的不断发展,充分利用其叠加的特性、相干性等特征可以更好的发挥量子计算的性能。量子计算也被应用到问题优化方面,将量子计算的基本原理通过一定方式融入到遗传算法中就形成了量子遗传算法(quantum genetic algorithm,qga)。
[0168]
3.2.1量子遗传算法原理
[0169]
量子遗传算法中最主要的就是量子计算原理。量子计算中包含量子态、概率幅等
概念。信息的载体被具有双态系统的量子位所表示。借助于量子力学,可以使一个量子位不仅处在0或1的任意状态,还能处于二者的叠加态之中。通过量子计算的各种特性,理论上量子计算在解决某些问题上会比经典计算要快。
[0170]
量子计算中量子比特有很多形式。以单量子比特为例,一个有n个单量子比特的系统,可以表示2
n
种量子态,在量子理论中使用狄拉克符号“| >”来标记量子态。|0>和|1>两个基本态就对应0和1。单量子比特就是这两个基本态的组合,即叠加态|ψ>,可以表示为:
[0171]
|ψ>=α|0>+β|1>
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0172]
其中,α和β满足下列条件:
[0173]
|α|2+|β|2=1
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0174]
除了两个基本态以外,量子位均处于叠加态,用向量形式表示为:
[0175][0176]
因为概率幅α和β满足归一化要求,因此叠加态|ψ>也可以表示为式(6),θ是相位角。
[0177][0178]
本发明使用的qga是将量子计算与遗传算法进行组合,通过综合发挥各自的优势可以获得较好的成果。qga是建立在量子计算上的一种新兴的概率优化算法,具备快速收敛,性能强,全局搜索能力强等优点。
[0179]
3.2.2量子遗传算法步骤
[0180]
qga与ga不同点在于,使用量子态对染色体进行编码,然后初始化种群,在迭代过程中使用量子门对染色体进行更新,突变等操作,直到触发终止条件,输出适应度最佳的染色体,即问题的最优解。接下来将阐述qga的具体实现步骤。
[0181]
第一步:编码。qga最大的特点就是用量子态的形式对染色体进行编码,一个量子位上的量子态表示一个特征信息。同时每个量子态用式(3)表示,且|0>和|1>可作为标准正交基,表示为:
[0182][0183]
叠加态|ψ>则可用式(5)表示。因此对一个具有t个基因的染色体x进行量子态编码,其叠加态|ψ>可表示为:
[0184][0185]
其中,|α
i
|2+|β
i
|2=1,i∈{1,2,3...t},因此叠加态|ψ〉也可记为:
[0186][0187]
这种编码方式只使用θ一个参数,使得算法更加简洁,并且在进行量子门旋转时也
会更加直观。
[0188]
第二步:初始化种群。ga在保证种群多样性的情况下需要增大种群的规模,这就会导致巨大的计算开销,qga则通过使用量子态表示种群中的染色体,在保持多样性的前提下大大减小了种群的规模。使用式(9)编码时θ是随机产生的,因此保证了染色体的多样性,也避免了因概率幅过于平均而导致测量结果集中于某一区域。
[0189]
第三步:量子坍缩。经过量子坍缩,即对量子态进行观测。需要在区间[0,1]上生成一个随机数r,然后做判断,若r>|α
i
|2,则对应的第i位量子态坍缩到1,否则为0。
[0190]
第四步:适应度函数。这里与ga相似,确定一个适应度函数,并计算每一个染色体的适应度值,用于每一轮迭代的进化和最终选择。
[0191]
第五步:量子旋转门。qga中最关键的一个环节,利用量子旋转门对量子态进行更新,是实现二维希尔伯特空间矢量变换的一种方式。一个好的量子旋转门可以完成少量的判断和快速的计算,并完成叠加态的改变。qga中量子位上的概率幅决定进化方向。使用量子旋转门来实现个体向最优个体的转变,其形式表示为:
[0192][0193]
其中,θ
′
为旋转角,由公式:θ'=δθ
·
s(cosθsinθ)确定。δθ为旋转角的大小,s(cosθsinθ)决定了旋转的方向。对于任意量子位进行量子旋转门更新操作可得:
[0194][0195]
其中,是第i位更新后的量子态。通常旋转角和旋转方向是定好的。通过旋转规则,可以发现若当前个体的适应度值大于当代最佳的个体时,旋转方向会向着有利于当前个体的方向旋转,反之则会向着最佳个体旋转,这确保了更新操作始终是向着最优方向去收敛的。
[0196]
一般情况下的量子旋转门的旋转角度在整个迭代过程中是固定不变的,这样对旋转角的选择就有很高的要求,角度过大可能会造成早熟,过小会影响算法的收敛速度,导致不能发挥qga的最佳性能。因此本发明使用一种自适应方法来动态调整旋转角的大小。当需要更新的个体适应度值与当代中最佳个体的适应度值差距过大时,进行较大角度的旋转,反之则进行小角度的旋转,这样既优于寻找最佳个体又可提高收敛速度。
[0197]
自适应的δθ调整方案如下:
[0198][0199]
其中,δθ∈[0.01π,0.05π],θ
a
和θ
b
分别表示区间上的最小和最大值。f
max
表示当代最佳的适应度值,f
cur
表示需要进行更新的个体的适应度值。此方案将适应度与旋转角结合在一起,自适应的调节旋转角大小,提高算法的收敛速度。
[0200]
第六步:量子突变。量子突变与ga中变异操作的目的相同,都是为了保持种群的多样性,同时提高算法的局部搜寻能力。在qga中使用一个量子非门(pauli
‑
x门)来进行量子
突变。量子非门可表示为:
[0201][0202]
对任意一个叠加态|ψ>实施突变操作可得:
[0203][0204]
量子非门的操作效果与ga中的变异基本无异,qga中,突变后的量子位可见是对基本态概率幅的一次交换,使其被观测时得到0或1的概率进行了交换,达到突变的目的。
[0205]
3.2.3量子遗传算法应用
[0206]
随着han等人第一次将量子编码添加进ga中,各方研究者们开始对qga进行大量的研究。qga也开始被广泛地应用到各种实际研究情况中。
[0207]
2018年马莹等人将一种自适应的策略应用到qga中,将实数和量子比特进行组合来完成编码,同时使用自适应旋转角策略,让算法在收敛性和精度上有不错的表现。
[0208]
2019年张秋艳等人提出一种“灾变”概念,当qga在某个局部已经寻找到最优解时,仅通过交叉和突变无法跳出这个局部范围,因此会陷入早熟的可能。通过这个“灾变”思想,使最优染色体包留,其余的全部重新生成,以较大的几率得到远离该局部的新染色体,极大的提高了qga的全局能力,并通过实验证明了该方法在连续空间优化的有效性。
[0209]
2020年刘岩松等人,针对算法可能出现早熟及陷入局部最优的问题,在云环境下采用x条件云发生器来优化量子染色体的交叉和突变方式,并且规定了一个新的算法收敛准则。将qga应用在桥式起重机主梁的设计中。
[0210]
现有文献提出了一种基于qga优化svm的旋转机械故障诊断方法。使用qga来对svm的核函数参数和惩罚系数进行优化,实验证明使用qga优化svm的参数,提高了svm训练的收敛效率和svm的泛化能力。
[0211]
现有文献在能源管理的电力预测方面,结合混沌函数和qga来优化支持向量回归(support vector regression,svr)模型。通过提出的cqga对svr中的损失函数和核函数中的三个参数进行优化选择,提高了模型的分类精度,并为继续探索量子计算概念与混沌映射技术的结合提供了支持。
[0212]
现有文献同样是在qga的基础上优化svr模型,对惩罚因子,核参数以及松弛系数进行选择优化,实现了对svr的深度寻优。并对股票的收益率进行预测,为投资者提供了有效的投资预测模型。
[0213]
综上所述,qga已经在很多领域得到了充分利用,并且在优化机器学习模型方面也得到了认可,所以本发明使用qga来对随机森林算法进行参数的优化。
[0214]
3.3本发明首先具体的介绍了智能算法中ga的基本内容。包括基本原理,实现过程以及实现步骤中的具体细节。然后给出了传统ga中所存在的问题,并介绍一些优化的方法。接着通过量子计算的概念引出qga,并详细阐述了qga对于ga的改进。同时给出qga的实现步骤及应用,为本发明涉及的算法优化概念提供了理论支撑。
[0215]
4、基于量子遗传算法的随机森林优化方法
[0216]
本发明主要介绍使用qga对随机森林分类模型进行优化,选取了随机森林算法中
较为重要的两个参数,经过qga的优化选择,使随机森林分类模型的分类性能得以提高。
[0217]
4.1随机森林的参数影响
[0218]
当使用随机森林算法对网络流量进行分类预测时,在原始数据集一定的情况下,影响模型分类准确率及运算时间的因素主要有两个:训练一棵决策树时需要随机选取的特征子集中的特征数量k,和最终形成的随机森林模型中决策树的数量n。根据随机森林分类模型的实现过程可以发现:
[0219]
1.在构建随机森林分类模型时,经过随机取样会得到的n个样本集,每一个样本集会对应的训练一棵决策树。在训练过程中又需要从总的特征集中随机地抽取指定数量的特征来构成决策树划分的特征子集,而k的大小就决定了单个决策树的分类性能以及两两决策树之间的相关程度。当k值越小时,单一决策树的分类能力会下降,但是随机森林的随机性提高,同时决策树之间的相关性会越低,因此整体随机森林模型的分类性能会加强。现有文献计算了几个具有代表性的k值,并得到了一个较好的分类效果。因此一个合适的k值会使算法有一个更好的表现。
[0220]
2.因为随机森林分类模型采用的是投票法进行决策,因此森林的规模即决策树的数量n决定了票数和准确率。根据john提出的大数定理,当n增大时,模型被证明了泛化误差会收敛,模型的分类性能会逐渐稳定,所以不会出现过训练的问题。但是这并不意味着n越大,模型的准确率就会越高,而是在一定范围内会有一对超参数组合使准确率达到最高,组合中n的值不一定是范围内的最大值。所以应该在考虑时间空间成本的前提下寻找使分类准确率最高的超参数n。
[0221]
于是,超参(k,n)的选择成为随机森林分类模型建立中一个重要的环节。传统的取值只能获得有限的分类性能,而对于超参数的优化方法常见的有:网格法、智能算法等。现有文献通过使用上下两层优化问题来解决超参数的选择。文献首先对类别进行k
‑
means分解,然后使用改进的ga对超参数对进行选择。文献提出了一种经过二次划分,然后进行贪心选择的网格搜索算法。本发明则是通过第三章对量子遗传算法概念的研究,使用改进的量子遗传算法对超参数(k,n)进行选择与优化。
[0222]
4.2基于qga
‑
rf的参数优化算法
[0223]
本发明通过介绍量子遗传算法和随机森林算法中需要进行优化的参数,提出了基于量子遗传算法的随机森林(qga
‑
rf)参数优化算法。该算法的目的是探究模型分类性能与超参数(k,n)的关系,寻找最佳的超参数组合来达到最优的分类性能。
[0224]
一般情况下进行算法验证会使用k折交叉验证,将数据集等分成k份,然后使用其中的一份作为训练集,剩余的作为验证集,重复k次,可以得到k个结果,平均之后的数值就代表模型的泛化能力。但是该方法的计算时间复杂度较高,不适合规模较大的数据集。在随机森林中由于随机采样的方法产生的“袋外数据”恰好解决了这个问题,使用袋外误差率可以很好在模型训练中自主的提升泛化能力,因此直接使用模型的分类准确率(accuracy)来表现最终模型的泛化能力即可。
[0225]
其中,根据4.1节对随机森林中超参数的了解与分析,以及考虑时间和空间的计算成本,将k和n的取值范围定为:[1,m]和[1,64]。m为数据集中总的特征数量,64是根据计算机的计算能力,与时间成本综合考虑下决定的。因此,qga
‑
rf的参数优化算法的流程图如图7所示。
[0226]
具体执行步骤设计如下:
[0227]
step1.确定(k,n)的取值范围,然后根据qga使用多个单量子比特来表示一个染色体x:
[0228][0229]
其中前i个量子位的组合表示k,后面第i+1位至t位表示n。因为α和β符合归一化要求,且为了使算法更简洁,本发明使用正余弦的方式来编码染色体x:
[0230][0231]
step2.初始化种群。确定种群数量m,最大迭代次数maxgen和量子突变概率p
m
。为了使种群可以更加均衡地分布在解空间中,一般qga会将种群进行等分,然后不同子种群的染色体x中量子基础态的概率幅是不一样的。但是同一染色体中每一个量子位上的概率幅是相同的。因此本发明使用一个随机数r1(r1∈[0,1]),在初始化种群的时候不再等分种群,而是对每一个染色体x的每一个量子位上的θ乘上一个r1。即初始化的染色体x表示为:
[0232][0233]
这样既保证种群的均匀分布,又增加了种群的随机多样性,提升收敛速度。
[0234]
step3.量子坍缩。在每一轮的迭代中无法直接对一个量子态进行适应度值的计算,需要一个量子坍缩的过程,设置一个随机数r2,若r2>cos2θ
i
,则对应的第i位量子比特坍缩到1,否则为0。以此来进行进制转换得到十进制下的(k,n)。
[0235]
step4.使用随机森林分类模型的分类准确率作为染色体个体的适应度值进行判断。即:
[0236]
fit(x)=accuracy(k,n)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0237]
step5.量子旋转门更新。本发明使用自适应的旋转角对传统量子旋转门进行改进,具体方法描述在3.2.2中的第五步。通过自适应的旋转角可以有效提高收敛速度,同时避免算法对优质解偏离提高局部搜索性能。
[0238]
step6.量子突变。首先这里需要设置第三个随机数r3,∈[0,1],当r3<p
m
时会发生量子突变。
[0239]
传统qga仅使用量子非门,即式(14)对量子位进行突变,但是这样做会增加算法早熟的可能。因此本发明使用哈达玛门(hadamard门)进行改进,其形式为:
[0240][0241]
相对于量子非门,hadamard门所改变的旋转角小了设置一个控制参数c,并根据下式判断使用哪一种量子门:
[0242]
[0243]
式中,f
max
代表当代中染色体最佳的适应度值,f
avg
代表当代中所有染色体适应度值的平均值。当式(20)成立时,认为种群中只有少数个体适应度高,此时需要大幅转变,因此使用量子非门进行突变,反之则使用hadamard门。这样做的目的可以保证种群的稳定性,不会对优秀个体发生巨大的偏移。
[0244]
step7.判断是否达到最大的迭代次数。是,则停止算法给出最优解。否,则进入step3进行下一轮迭代。
[0245]
4.3仿真实验与分析
[0246]
使用量子遗传算法对随机森林的参数选择进行优化,实现网络流量分类模型的建立,实验环境为windows操作系统,在一台win10 pro的pc机上,内存大小为16g,规格为ddr4,使用gtx1050的显卡,七代i57300hq的处理器,使用mingw+g++的模式完成在windows下对代码的编译。
[0247]
4.3.1实验数据与参数设置
[0248]
首先本发明使用剑桥大学在文献上发布的数据集进行随机森林模型的训练与验证。该数据集是从两个站点的三个不同时间段进行收集的,其中包含总共11个小时的tcp和udp网络流量,并且有来自812k个流的107m个包。本发明从这个数据集中综合选取第一天的一个数据子集作为训练集d1,来训练随机森林模型。然后从第二天和第三天的数据集中各选取一个子集作为验证集d2,d3,来验证模型的分类性能。本发明通过对文献的研究以及对数据集的分析,挑选了7个应用程序的类型,这7个类别基本涵盖了网络用户日常所使用的全部应用程序,具体见表2。然后通过对moore等人提取的248个特征进行分析,并参考各类研究中使用的特征子集以及特征选择方法,本发明挑选了12个特征组成训练集中的特征子集。这12个特征与流量在网络中的位置无关,且容易通过直接读取或简单计算获得,几乎完全依赖于终端主机上的实际应用程序,表3列出这个特征子集。
[0249]
表2训练集包含的类别及对应的应用程序和数量
[0250][0251]
表3特征选择后的特征子集
[0252][0253]
在基于随机森林算法的网络流量分类模型训练中,先使用固定的参数k=4和n=10,近似于一般随机森林算法的默认参数,进行随机森林分类模型的训练,然后使用量子遗传算法对(k,n)进行优化选择,量子遗传算法中的部分参数见表4。
[0254]
表4量子遗传算法的参数设置
[0255][0256]
同时为了验证量子遗传算法的有效性,将种群的数量进行了调整,又分别对10和20的种群做了测试。并且通过实现遗传算法来完成算法的对比,遗传算法中的相关参数见表5。
[0257]
表5遗传算法的参数设置
[0258][0259]
4.3.2实验结果与分析
[0260]
在使用固定参数k=4和n=10进行训练的随机森林分类模型中,实验使用数据集d1作为训练集,并使用另外两个数据集d2,d3作为验证集。在这种情况下随机森林分类模型的平均准确率为92.812%。
[0261]
为了验证随机森林分类模型相较于其它机器学习算法具有更好的分类性能。实验在python编程中又建立了支持向量机,knn,朴素贝叶斯和决策树的分类模型。各模型中参数为默认值,得到的平均分类准确率见表6,实验过程如图8所示。
[0262]
表6不同分类算法的准确率
[0263][0264]
首先在对比实验中,每一次测试各算法的训练集和测试集是一样的,但各次之间由于划分时的随机性,训练集和测试集又是变化的。在表6和图8中可以发现,svm和naive bayes算法的分类准确率较低,且波动较大。knn与决策树准确率较高,且决策树的准确率十分接近随机森林算法。
[0265]
量子遗传算法的种群参数为50时,对随机森林模型进行优化后可以得到一对最佳的参数解,其中k=12,n=46。使用这对参数解来进行训练的随机森林分类模型,其分类准确率最高可达97.845%。
[0266]
在种群数量不同时,量子遗传算法中最佳适应度值的迭代过程如图9所示。
[0267]
从图9中可以发现,当种群数量为10,最佳适应度值在第23次迭代时收敛到一个最优解,当种群数为20,则在第15代作左右便收敛到一个最优解。可见当种群数量增加时,算法的全局搜索能力会加强,并能快速收敛到一个最优解。
[0268]
另外,实验又使用种群数为50的ga作为对比,对随机森林进行了优化选择,在ga中,当k=3,n=48时,随机森林的分类模型准确率可达:96.817%。两种优化算法qga和ga在种群数为50的实验中迭代过程如图10所示。
[0269]
由图10可以清晰地发现,在两个算法的优化过程中,二者的最佳适应度值都在向着一个方向收敛。其中ga_rf的优化过程中,平均适应度在前七次迭代中快速向最佳适应度值靠近,但是在之后平均适应度与最佳适应度之间还存在较大的波动,表明ga在一般情况下会缺乏稳定性。在qga_rf的优化过程中,最佳适应度基本收敛在97.8%左右,并且平均适应度基本在均匀的上升。这说明了qga在保证种群多样性的同时,完成了全局最优解的探索,同时最大限度地将算法避开了陷入局部最优的问题。
[0270]
综上所述,随机森林算法在机器学习中本就有着不错的分类性能,通过实验又证明了经过qga的优化,随机森林算法的分类性能又获得了提升,而且模型的训练时间也在可接受范围内。qga相较于ga有更好的全局搜索能力,且不易陷入局部最优解。
[0271]
本发明综合了对于随机森林算法和qga的基本原理的研究,使用改进的qga对随机森林分类模型进行优化,给出了随机森林中两个参数对模型分类性能的影响,并通过qga搜索出一对最优的参数解,最后通过实验证明了该方法的有效性。
[0272]
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用全部或部分地以计算机程序产品的形式实现,所述计算机程序产品包括一个或多个计算机指令。在计算机上加载或执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(dsl)
或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输)。所述计算机可读取存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,dvd)、或者半导体介质(例如固态硬盘solid state disk(ssd))等。
[0273]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1