一种基于混合算法的物品推荐方法、装置及设备与流程
1.本技术物品推荐领域,具体涉及一种基于混合算法的物品推荐方法、装置及设备。
背景技术:
2.随着人们对于物品的个性化需求的增加,各类物品推荐方法应运而生。大多数物品推荐是根据用户对于物品的行为,通过一些数学算法预测得到用户喜欢的物品,并将得到的物品推荐给用户。
3.协同过滤推荐是目前应用较为广泛的推荐技术,已经成功应用于多个领域。协同过滤推荐算法通常使用用户的隐性反馈数据(例如用户的购买记录),或者显性反馈数据(例如用户对于物品的评分),主要根据用户的历史行为信息,寻找用户或者物品的近邻集合,获得用户对物品的偏好值,以此为用户推荐用户需要的物品。然而,传统协同过滤算法主要利用用户对于物品的评分这一类物品的外在信息得到推荐结果,并未充分考虑到物品的内在信息,导致得到的物品推荐结果准确性较低。
技术实现要素:
4.有鉴于此,本技术实施例提供一种基于混合算法的物品推荐方法、装置及设备,用以提高物品推荐结果的准确性。为解决上述问题,本技术实施例提供的技术方案如下:
5.第一方面,本技术提供一种基于混合算法的物品推荐方法,所述方法包括:
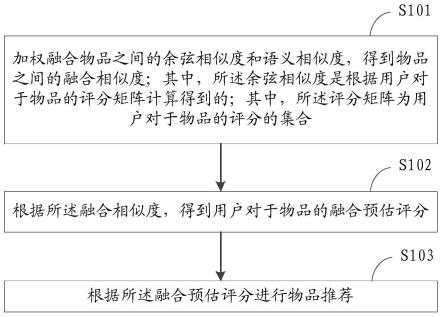
6.加权融合物品之间的余弦相似度和语义相似度,得到物品之间的融合相似度;其中,所述余弦相似度是根据用户对于物品的评分矩阵计算得到的;其中,所述评分矩阵为用户对于物品的评分的集合;
7.根据所述融合相似度,得到用户对于物品的融合预估评分;
8.根据所述融合预估评分进行物品推荐。
9.在一种可能的实现方式中,计算得到物品之间的所述余弦相似度包括:计算得到物品之间的场景相似度;其中,所述场景相似度为对应于场景的物品之间的相似度;以所述场景相似度作为偏置项,计算得到所述余弦相似度。
10.在一种可能的实现方式中,所述计算得到物品之间的所述场景相似度,包括:获取物品对应的一个或多个场景;计算得到所述一个或多个场景所对应的物品的场景向量;根据物品的场景向量,通过相似度计算得到物品之间的所述场景相似度。
11.在一种可能的实现方式中,计算得到物品之间的所述余弦相似度包括:根据所述评分矩阵,得到物品的平均评分;其中,所述物品的平均评分为多个用户对于同一个物品的评分的平均值;以所述平均评分作为余弦相似度的修正值,计算得到所述余弦相似度。
12.在一种可能的实现方式中,计算得到物品之间的所述余弦相似度包括:基于相似性收缩系数和相关用户人数,计算得到所述余弦相似度;其中,所述相关用户人数为对物品均进行评分的用户人数;其中,所述物品为计算所述余弦相似度过程中涉及到的两个物品。
13.在一种可能的实现方式中,所述根据所述融合相似度,得到用户对于物品的融合
预估评分,包括:加权融合预估评分和矩阵分解结果,得到所述融合预估评分;其中,所述预估评分是根据所述融合相似度计算得到的,所述矩阵分解结果是根据用户矩阵和物品矩阵的点积计算结果得到的;其中,以用户矩阵和物品矩阵的点积计算结果作为所述矩阵分解结果;所述用户矩阵的一个维度为所述评分矩阵中用户的数量,所述物品矩阵的一个维度为所述评分矩阵中物品的数量。
14.在一种可能的实现方式中,根据所述用户矩阵和所述物品矩阵的点积计算结果得到所述矩阵分解结果,包括:加权融合所述点积计算结果、物品的平均评分和偏置系数,得到所述矩阵分解结果;其中,所述物品的平均评分为多个用户对于同一个物品的评分的平均值,所述偏置系数是通过上下文感知技术得到的。在一种可能的实现方式中,通过加权融合得到所述矩阵分解结果,包括:设置所述点积计算结果、所述物品的平均评分和所述偏置系数的权重值分别为0.5、0.3和0.2。
15.第二方面,本技术提供一种基于混合算法的物品推荐装置,所述装置包括计算模块和推荐模块,其中:
16.所述计算模块,用于加权融合物品之间的余弦相似度和语义相似度,得到物品之间的融合相似度;其中,所述余弦相似度是根据用户对于物品的评分矩阵计算得到的;其中,所述评分矩阵为用户对于物品的评分的集合;根据所述融合相似度,得到用户对于物品的融合预估评分;
17.所述推荐模块,用于根据所述融合预估评分进行物品推荐。
18.第三方面,本技术提供一种基于混合算法的物品推荐设备,所述设备包括:处理器、存储器;所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述的方法。
19.由此可见,本技术实施例具有提高物品推荐结果准确性的有益效果。在现有技术中,物品推荐算法并未充分考虑物品的内在信息,在本技术实施例中,通过对物品之间的余弦相似度和语义相似度进行加权融合处理,基于混合算法得到物品之间的融合相似度,并根据所述融合相似度得到的用于对于物品的预估评分进行物品推荐,在根据用户历史行为(评分矩阵)得到所述余弦相似程度的基础上,也通过计算物品之间的语义相似度,利用物品的语义信息,在语义层面增强物品推荐的效果,从而较为全面地反映被推荐物品的属性,提高推荐结果的准确性。
20.另外,本技术实施例还具有其他有益效果。
21.由于在实际情况中,用户对于物品的兴趣通常会受到例如物品应用环境等因素的影响,以场景相似度作为计算余弦相似度过程中的偏置项,通过这种方法将和物品相关的环境信息融入到推荐算法中,利用物品和环境相关的内在属性,进一步提高推荐结果的准确性。混合推荐算法能够融合单个算法的优势,在一定程度上弥补单一推荐算法的不足,提高推荐结果的准确性。本技术实施例在物品推荐算法中加入场景相似度作为物品之间相似度计算的偏置项,实现用户、物品和场景相关信息的融合,能够结合物品应用场景为特定用户进行个性化推荐,提高物品推荐结果的个性化程度;而且通过较全面地反映物品属性,也能够提高物品推荐结果的召回率和覆盖率。
22.本技术的实施例还能够在一定程度上解决推荐系统冷启动的问题。在现有技术中利用传统协同过滤算法实现物品推荐时,会存在冷启动问题,即当有新用户加入,由于新用
户的历史行为信息较少,新用户和物品之间的相关数据较少,物品推荐系统会存在数据稀疏性问题,导致推荐结果的准确性受到较大的影响。而本技术的实施例在进行余弦相似度计算的过程中,通过引入相似性收缩系数,在物品推荐过程中加入相似相权重重要性的策略,减少数值过分偏移的问题。当对物品进行评分的用户人数较少时,相似性收缩系数起到对相似度收缩的作用,从而在一定程度上解决冷启动问题。
附图说明
23.图1为本技术实施例提供的一种基于混合算法的物品推荐方法的流程图;
24.图2为本技术实施例提供的一种基于混合算法的物品推荐装置的结构示意图;
25.图3为本技术实施例提供的一种基于混合算法的物品推荐设备的结构示意图。
具体实施方式
26.为了便于理解和解释本技术实施例提供的技术方案,下面将先对本技术实施例中的技术术语进行说明。
27.协同过滤推荐算法是一种基于最近邻的推荐系统算法,是目前应用较为广泛的一种推荐算法。协同过滤推荐算法主要基于以下假设:用户倾向于喜欢相似的物品。在推荐系统中,根据用户对物品的行为信息,生成用户-物品评分矩阵,利用余弦相似度计算物品之间的相似性并进行相似度排序,选出相似度数值高的物品推荐给用户。
28.知识图谱技术可以通过有向图表示三元组,以及三元组之间的相互连接构成网状的知识集合,这种三元组携带者实体自身的语义信息。在知识图谱的可视化表示中,实体被视作是节点,实体之间的关系被视作是节点之间的边。通常,在知识图谱中相似的两个节点,具有语义接近的特征。
29.上下文感知推荐技术:上下文感知技术指的是在人与计算机的交互过程中,计算机获取与用户需求相关的上下文信息,用以确认为用户提供哪些服务,主要涉及的问题包括上下文信息的获取、上下文信息的融合,以及上下文信息的处理。上下文感知推荐算法即是基于上下文感知技术的推荐算法。
30.矩阵分解(matrix factorization)技术是一种推荐算法,简称mf矩阵分解算法。mf矩阵分解算法是将m*n维的用户对于物品的评分矩阵r分解为将m*k维的用户矩阵u和k*n维的物品矩阵v相乘的形式,其中,m为用户的数量,n为物品的数量,k为隐向量的维度,k的大小决定了隐向量表达能力的强弱。
31.为了便于理解本技术实施例提供的技术方案,下面结合附图对本技术实施例提供的方法和装置进行说明。
32.虽然附图中显示了本技术的示例性实施例,然而应当理解,可以以各种形式实现本技术而不应被这里阐述的实施例所限制。基于本技术中的实施例,本领域技术人员在没有作出创造性贡献前提下所获得的其他实施例,都属于本技术的保护范围。在本技术的权利要求书和说明书以及说明书附图中,术语“包括”和“具有”以及它们的任何变形,目的在于覆盖不排他的包含。
33.现有技术中物品推荐方法主要利用用户对于物品的评分这一类物品的外在信息,并未充分考虑到物品自身的内在信息。本技术实施例通过融合由评分矩阵得到的物品之间
的余弦相似度,以及物品之间的语义相似度,得到物品与物品之间的融合相似度,并利用融合相似度得到用户对于物品的融合预估评分,根据所述融合预估评分进行物品推荐。本技术实施例在根据用户历史行为(评分矩阵)得到物品之间的相似程度的基础上,在语义层面上增强了物品推荐的效果,能够提高物品推荐结果的准确性。
34.请参阅图1,图1是本技术实施例提供的一种基于混合算法的物品推荐方法的流程图。如图1所示,本技术实施例中基于混合算法的物品推荐方法包括以下步骤:
35.s101、加权融合物品之间的余弦相似度和语义相似度,得到物品之间的融合相似度;其中,所述余弦相似度是根据用户对于物品的评分矩阵计算得到的;其中,所述评分矩阵为用户对于物品的评分的集合;
36.在s101中,所述加权融合物品之间的余弦相似度和语义相似度,得到物品之间的融合相似度的作用,是基于物品的内在和外在信息,得到物品和物品之间的相似程度,该相似程度可以用于评估用户对于物品的喜好程度。所述评分矩阵为用户对于物品的评分的集合,用户对于物品的评分用于量化用户对于物品的喜好程度,评分高则为所述用户对所述物品的喜好程度高,评分低则为所述用户对所述物品的喜好程度低。由于余弦相似度可以用于度量矩阵中元素之间的相似性,计算矩阵元素的余弦相似度,可以得到物品与物品之间的相似程度,这种用余弦相似度表示的相似程度是基于用户历史行为得到的(评分矩阵)。而通过语义相似度的计算,可以量化两个物体之间在语义上的相似程度,通常情况下,在语义上相似程度高的两个物品,用户对于这两个物品的喜好程度的相似性高。通过加权融合得到所述融合相似度,利用所述融合相似度表示两个物品之间的相似程度,融合相似度越高,表明这两个物品之间的相似程度越高,意味着用户对于两个物品的喜好程度的相似性越高。通过多个相似度的融合计算,也能够在一定程度上避免单一相似度计算结果带来的误差,从而提高推荐结果的准确性。
37.s102、根据所述融合相似度,得到用户对于物品的融合预估评分;
38.在s102中,所述根据所述融合相似度,得到用户对于物品的融合预估评分的作用,是将物品与物品之间的相似度,转化为用户对于物品的喜好程度(通过融合预估评分量化表示),为后续的物品推荐过程提供推荐依据。两个物品之间的融合相似度越大,表明这两个物品的相似程度越高,则用户对于这两个物品的喜好程度也就越接近,利用这个原理,得到用户对于物品的融合预估评分。在s102中,可以根据某两个物品之间的融合相似度,分别得到用户对于这两个物品的融合预估评分,例如,根据第一物品和第二物品的融合相似度,可以得到用户对于所述第一物品/第二物品的融合预估评分;或者,也可以根据物品之间的融合相似度组成的融合相似度矩阵,得到多个物品的融合预估评分,这多个物品的融合相似度组成了融合相似度矩阵。
39.s103、根据所述融合预估评分进行物品推荐。
40.在s103中,所述根据所述融合预估评分进行物品推荐的作用是得到较为准确的物品推荐结果,完成物品推荐过程。
41.进一步地,在本技术实施例中,所述物品指的是被推荐给用户的对象,而并非特指无生命的物体,也并非仅指无生命的物体。例如,在本技术实施例中,所述物品可以为不具有生命特征的歌曲、服饰等推荐对象,也可以为具有生命特征的明星、宠物等。例如,本技术实施例应用于车载音乐的推荐,此时应用场景为车载,被推荐的对象为音乐。可以理解地
是,所述物品为何种类型,应用于何种场景均不影响本技术实施例的实现。
42.进一步地,在本技术实施例s101中,所述评分矩阵的数据来源可以是已经发布的数据集,也可以是在具体应用场景中采集得到的数据,或者其他能够实现本技术实施例的数据。在这里本技术提供一种具体的数据来源。数据集可以采用文献《in car music:context-aware music recommendations in a car》中公开的车载音乐推荐数据集,该数据集包括的数据集体特征为:用户id(包含42个用户)、歌曲id(包含514首歌曲)、评分(用户对歌曲的评分,1-5个等级评分)、驾驶风格(包括轻松驾驶、运动模式驾驶)、风景线(包括海岸线、乡村、山地/丘陵、城市)、心情(包括激动、高兴、悲伤、慵懒)、自然现象(包括白天、早上、晚上、下午)、道路类型(包括城市、高速、蜿蜒)、睡眠情况(包括清醒、睡着)、交通情况(包括公路畅通、车多、交通堵塞)、天气(包括多云、下雪、晴天、下雨)、歌曲类型(包括蓝调音乐、古典音乐、乡村音乐、嘻哈音乐、爵士音乐、摇滚音乐、金属音乐、流行音乐、饶舌音乐、迪斯科音乐)。可以理解地是,所述评分矩阵的数据来源于何处不影响本技术实施例的实现。
43.进一步地,在本技术实施例s101中,对于根据用户对于物品的评分矩阵计算得到所述余弦相似度,可以包括以下实现方式:计算得到物品之间的场景相似度,其中,所述场景相似度为对应于场景的物品之间的相似度;以所述场景相似度作为偏置项,计算得到所述余弦相似度。可以结合上下文感知技术得到所述场景相似度。例如用户的历史行为数据,获取物品的上下文信息,将上下文信息融入物品推荐算法。结合上下文信息相当于是在推荐算法中增加了上下文约束条件,能够提高物品推荐结果的准确性;将场景相似度作为物品相似度的一个偏置项,基于用户对附加场景偏置的预测评分,还能够实现对不同用户的个性化推荐。本技术实施例提供一种具体计算过程:对于物品ii和物品ij,物品之间未添加偏置项的余弦相似度为sim
′c(ii,ij),物品之间的所述场景相似度为sim
con
(ii,ij),得到物品之间的所述余弦相似度sim(ii,ij)=p
·
sim
′c(ii,ij)+q
·
sim
con
(ii,ij),其中,融合系数p和q可以通过实验进行设定。物品之间的所述语义相似度为sim
kg
(ii,ij),得到物品之间的融合相似度sim(ii,ij)为
44.sim(ii,ij)=α
·
[p
·
sim
′c(ii,ij)+q
·
sim
con
(ii,ij)]+(1-α)
·
sim
kg
(ii,ij)其中,融合系数α的取值可以通过实验进行设定。进一步地,所述场景相似度sim
con
(ii,ij)可以通过对上下文场景特征的短文本通过word2vec作embedding的词向量嵌入,或者利用bert算法,得到场景的向量化表示,物品ii和物品ij分别对应的场景的向量化表示,进行相似度的计算,从而得到物品之间的所述场景相似度。可以理解地是,是否以上述实现方式计算得到所述余弦相似度,不影响本技术实施例的实现。
[0045]
在上述的实现方式中,进一步地,对于计算得到物品之间的场景相似度,可以包括以下实现方式:获取物品对应的一个或多个场景;计算得到所述一个或多个场景所对应的物品的场景向量;根据物品的场景向量,通过相似度计算得到物品之间的所述场景相似度。
[0046]
进一步地,如果物品对应于多个场景,场景包括多个子场景,对于所述计算得到所述一个或多个场景所对应的物品的场景向量,本技术实施例提供以下三种实现方法。可以理解地是,是否以这三种实现方式计算得到所述物品的场景向量,不影响本技术实施例的实现。对于物品ii和物品ij,所述场景相似度sim
con
(ii,ij)对应于三个场景“天气”“车况”“车速”。对于场景“天气”而言,对应有两个子场景“晴”“阴”,子场景“晴”对应有3条数据,子
场景“阴”对应有1条数据;对于场景“车况”,对应有两个子场景“拥堵”“通畅”,子场景“拥堵”对应有3条数据,子场景“通畅”对应有1条数据;对于场景“车速”而言,对应有两个子场景“低速”“高速”,子场景“低速”对应有2条数据,子场景“高速”对应有2条数据。上述子场景包含的数据条数为4条。上述子场景的向量表示可以记为v(晴)、v(阴)、v(拥堵)、v(通畅)、v(低速)、v(高速)。
[0047]
第一种计算方法,首先针对多个场景中的某一个场景,对所述场景包含的子场景(例如所对应的向量表示进行平均值的计算,得到对应于该场景的场景平均向量,将所述多个场景的场景平均向量进行拼接,得到所述物品的场景向量。例如,对于物品ii对应的“天气”场景,子场景“晴”和“阴”对应的向量分别为v(晴)和v(阴),所述场景平均向量为以相同的计算过程得到针对“车况”和“车速”的场景平均向量;得到物品对应的ii三个场景的场景平均向量之后,将上述三个场景的三个场景平均向量进行拼接,得到物品ii的场景向量;以相同的计算过程得到对于物品ij的场景向量。
[0048]
第二种计算方法,首先将多个子场景进行拼接得到多个子场景拼接向量,每个子场景拼接向量是由所述多个场景的其中一个子场景组成的,再对多个子场景拼接向量进行平均值的计算,得到所述物品的场景向量。例如,对于物品ii,将多个子场景进行拼接得到多个子场景拼接向量为:concat(v(晴)||v(拥堵)||v(高速))、concat(v(晴)||v(通畅)||v(低速))、concat(v(晴)||v(拥堵)||v(高速))、concat(v(阴)||v(拥堵)||v(低速));再对上述四个子场景拼接向量进行平均值的计算,以计算结果作为物品ii的场景向量;以相同的计算过程得到对于物品ii的场景向量。
[0049]
第三种计算方法,首先针对多个场景中的某一个场景,获取该场景中数据条数最多的一个子场景,以该子场景的向量表示作为该场景对应的分场景向量;以上述方法得到多个场景对应的分场景向量;将多个场景的分场景向量进行拼接得到所述物品的场景向量。例如,对于物品ii,对于“天气”场景,如果天气场景下的子场景“晴”出现的条数最多,基于子场景“晴”的数据得到“天气”场景的分场景向量为v(晴);以相同的计算过程分别得到场景“车况”和“车速”的分场景向量;再将三个场景的分场景向量进行拼接,得到对于物品ii的场景向量;以相同的计算过程得到对于物品ij的场景向量。第三种计算方法的原理是用特定的某个场景的子场景代替特定的某个场景。如果对于某一个场景,出现数据条数相同的多个子场景的情况,优先采用第一种或第二种计算方式。
[0050]
进一步地,在本技术实施例s101中,对于根据用户对于物品的评分矩阵计算得到所述余弦相似度,还可以包括以下实现方式:根据所述评分矩阵,得到物品的平均评分;其中,所述用户的平均评分为一个用户对于多个物品的评分的平均值;以所述平均评分作为余弦相似度的修正值,计算得到所述余弦相似度。以所述平均评分作为余弦相似度的修正值的作用,是在计算所述余弦相似度时,考虑用户评分的差异性,通过将用户对物品的评分减去用户的历史评分平均值,减小了用户给出评分时标准不一致的问题。本技术实施例提供一种具体计算过程:对应于用户集合u={u1,u2,...,um}和物品集合i={i1,i2,...,in},
有评分矩阵其中,c
m,n
为用户um对物品in的评分,基于所述评分矩阵r,得到物品ii和物品ij之间的余弦相似度其中,所述为用户的平均评分,具体为用户u对于多个物品的评分的平均值,是基于所述评分矩阵r得到的。可以理解地是,是否以上述实现方式计算得到所述余弦相似度,不影响本技术实施例的实现。
[0051]
进一步地,在本技术实施例s101中,对于根据用户对于物品的评分矩阵计算得到所述余弦相似度,还可以包括以下实现方式:基于相似性收缩系数和相关用户人数,计算得到所述余弦相似度;其中,所述相关用户人数为对物品均进行评分的用户人数;其中,所述物品为计算所述余弦相似度过程中涉及到的两个物品。本技术实施例提供一种具体计算过程:对于物品ii和物品ij的计算,所述相关用户人数为同时对物品ii和物品ij进行评分的用户的人数。对应于用户集合u={u1,u2,...,um}和物品集合i={i1,i2,...,in},有评分矩阵其中,c
m,n
为用户um对物品in的评分,基于所述评分矩阵r,得到用户u对于物品的评分的平均值以及对物品ii和物品ij均进行评分的用户人数|u
i,j
|,从而得到物品ii和物品ij之间的余弦相似度其中,β为所述相似性收缩系数。所述基于所述平均评分和所述用户人数|u
i,j
|得到所述余弦相似度simc(ii,ij)的作用,是降低评分矩阵r中评分数据稀疏对于推荐结果的影响。通过在计算余弦相似度时引入相似性收缩系数β,在物品推荐过程中加入相似相权重重要性的策略。当对物品进行评分的用户人数|u
i,j
|较小时,相似性收缩系数β起到收缩的作用,减少数值过分偏移的问题;当|u
i,j
|较大时,相似性收缩系数β对相似度计算过程产生的影响较小。因此,通过在相似度计算的过程中引入相似性收缩系数β,能够在一定程度上解决当评分矩阵r中评分数据稀疏时,数值过分偏倚而导致推荐结果不准确的问题。可以理解地是,是否以上述实现方式计算得到所述余弦相似度,不影响本技术实施例的实现。
[0052]
进一步地,在本技术实施例s101中,获得物品之间的所述语义相似度可以包括以下实现方式:通过训练知识图谱的三元组,得到物品的向量化表示;其中,所述评分矩阵中的多个物品作为所述知识图谱中的实体进行嵌入;根据物品的向量化表示,计算得到所述语义相似度。通过知识图谱三元组训练的过程,以向量的形式数学化表示物品,物品的向量化表示含有物品的语义,通过物品之间的语义相似度,能够表示出物品之间在语义上的相似程度。基于在知识图谱中相近的两个物品被判定为近邻,计算得到物品与物品之间的语
义相似度,在根据用户评分这种历史行为得到物品相似程度的基础上,在语义层面上增强了物品推荐的效果。另外知识图谱技术具有可视化的特点,能够提高物品推荐过程的可解释性。本技术实施例提供一种具体计算过程:利用知识图谱技术得到物品的向量表示,可以通过transe翻译方法完成。具体计算过程如下:物品集合i={i1,i2,...,in}作为实体嵌入知识图谱s,针对所述知识图谱s,计算物品ii和物品ij之间语义相似度sim
kg
(ii,ij)。利用损失函数公式训练知识图谱s中的三元组(h,r,t);其中,h为头实体向量,t为尾实体向量,r为关系向量;所述三元组(h,r,t)满足限定条件|h+r|≈t;所述使用损失函数公式进行训练的过程为:l=∑
(h,r,t)
∑
(h
′
,r,t
′
)
[γ+||h+r+t||-||h
′
+r+t
′
||]
+
;其中,γ为间距大小,设置γ=1;符号[]
+
为是和合页损失函数,(h
′
,r,t
′
)为负样本,是通过三元组(h,r,t)的头实体或尾实体随机替换成其他实体得到的;范数||
·
||为l1范数或l2范数;将所述物品集合i作为物品实体嵌入所述知识图谱s,得到物品的向量表示ii=(e
1i
,e
2i
,...,e
di
)
t
;利用和所述训练过程的同等范数的欧几里得距离公式计算实体和实体之间的知识图谱相似度sim
kg
(ii,ij),
[0053]
其中,所述d(ii,ij)为欧几里得距离,)为欧几里得距离,可以理解地是,是否以上述实现方式计算得到所述语义相似度,不影响本技术实施例的实现。
[0054]
进一步地,在本技术实施例s101中,对于所述加权融合物品之间的余弦相似度和语义相似度,得到物品之间的融合相似度,可以包括以下实现方式:对于物品ii和物品ij,物品之间的所述余弦相似度为simc(ii,ij),所述语义相似度为sim
kg
(ii,ij),计算得到所述融合相似度为sim(ii,ij)=(1-α)
·
simc(ii,ij)+α
·
sim
kg
(ii,ij)。融合系数的取值可以通过实验获得,通常融合系数α的取值范围为[0,1]。可以理解地是,是否以上述实现方式计算得到所述融合相似度,不影响本技术实施例的实现。
[0055]
进一步地,在本技术实施例s102中,对于所述根据所述融合相似度,得到用户对于物品的融合预估评分,可以包括以下实现方式:加权融合预估评分和矩阵分解结果,得到所述融合预估评分;其中,所述预估评分是根据所述融合相似度计算得到的,所述矩阵分解结果是根据用户矩阵和物品矩阵的点积计算结果得到的;其中,以用户矩阵和物品矩阵的点积计算结果作为所述矩阵分解结果;所述用户矩阵的一个维度为所述评分矩阵中用户的数量,所述物品矩阵的一个维度为所述评分矩阵中物品的数量。本技术实施例提供一种具体计算过程:对应于用户集合u={u1,u2,...,um}和物品集合i={i1,i2,...,in},有评分矩阵其中,c
m,n
为用户um对物品in的评分,计算用户u对于物品ii的融合预估评分p
′
u,i
。
[0056]
用户u对于物品ii的预估评分p
u,i
可以根据物品ii和物品ij之间的融合相似度获得,
[0057][0058]
其中,c
u,j
为用户u对物品ij的评分,n(u)为用户u对于物品的评分的集合。
[0059]
对于m*n维的用户对于物品的评分矩阵r,在矩阵分解算法中对应有m*k维的用户矩阵u和k*n维的物品矩阵v,所述评分矩阵r可以表示为用户矩阵u和物品矩阵v相乘的形式,其中,m为用户的数量,n为物品的数量,k为隐向量的维度,k的大小决定了隐向量表达能力的强弱。用户矩阵u和物品矩阵v相乘的结果为所述矩阵分解结果mf。
[0060]
上述计算得到所述矩阵分解结果的过程即为基于矩阵分解的过程,将矩阵分解推荐算法融合到推荐算法中,进一步提高物品推荐结果的准确性。根据用户u对于物品ii的预估评分p
u,i
,和所述矩阵分解结果mf,得到用户u对于物品ii的融合预估评分p
′
u,i
=γ
·
p
u,i
+(1-γ)
·
mf,其中,γ为权重值,具体取值可以基于实验结果设定。可以理解地是,可以理解地是,是否通过以上述实现方式计算得到所述融合预估评分,不影响本技术实施例的实现。
[0061]
在上述的实现方式中,进一步地,对于所述根据所述用户矩阵和所述物品矩阵的点积计算结果得到所述矩阵分解结果,可以包括以下实现方式:加权融合所述点积计算结果、物品的平均评分和偏置系数,得到所述矩阵分解结果;其中,所述物品的平均评分为多个用户对于同一个物品的评分的平均值,所述偏置系数是通过上下文感知技术得到的。本技术实施例提供一种具体计算过程:对于m*n维的用户对于物品的评分矩阵r,在矩阵分解算法中对应有m*k维的用户矩阵u和k*n维的物品矩阵v,所述评分矩阵r可以表示为用户矩阵u和物品矩阵v相乘的形式,其中,m为用户的数量,n为物品的数量,k为隐向量的维度,k的大小决定了隐向量表达能力的强弱。用户矩阵u和物品矩阵v相乘的结果为mf。对于用户u和物品ii,对应有用户向量(c
u,1
,c
u,2
,...,c
u,n
)和物品向量(c
1,i
,c
2,i
,...,c
m,i
);这里的物品向量,指的是所有用户对某个物品的评分,用户向量指的是某个用户对所有物品的评分;这里的用户向量和物品向量区别于上文中的用户矩阵和物品矩阵;对所述物品向量(c
1,i
,c
2,i
,...,c
m,i
)进行平均值的计算,得到所述物品ii的平均评分对于物品ii有所述偏置系数bi,所述矩阵分解结果mf=ρ1·
mf+ρ2·
μi+ρ3·bi
,其中,ρ1、ρ2和ρ3是权重值,可以通过实验进行设定。进一步地,通过加权融合得到所述矩阵分解结果,可以设置所述点积计算结果、所述物品的平均评分和所述偏置系数的权重值分别为0.5、0.3和0.2,即mf=0.5mf+0.3μi+0.2bi。进一步地,所述偏置系数bi可以通过上下文感知技术,根据物品ii的类型,或者其他上下文条件进行设置,即所述偏置系数可以包括环境偏置系数和/或物品类型偏置系数。可以理解地是,是否通过以上述实现方式计算得到所述矩阵分解结果,不影响本技术实施例的实现。
[0062]
进一步地,在本技术实施例s103中,所述基于所述预估评分进行物品推荐,本技术实施例提供一种实现方式。所述对用户进行物品推荐的方式可以是基于所述融合预估评分组成的矩阵设置top-n推荐模式,即基于所述融合预估评分组成的矩阵,生成对应用户的n个物品组成的推荐列表。生成对应该用户的n个物品组成的推荐列表的依据是:针对该用户,在所述矩阵中的评分越高,则表明该用户对该物品的喜好程度越高,以排名前n的物品
为内容生成top-n推荐列表并将该推荐列表推荐给该用户。进一步地,获得排名前n的物品的方式,可以通过将对应于该用户的融合预估评分进行降序排列,选取前n个物品。进一步地,将该推荐列表推荐给用户的方式,可以采用根据列表依次推荐,也可以一次性将列表内容推荐给该用户。进一步地,对于需要推荐的每个用户均可以采用top-n推荐模式。可以理解地是,以何种方式对用户进行物品推荐不影响本技术实施例的实现。
[0063]
进一步地,对于本技术实施例,可以利用python的flask框架作为transe+cf+mf算法的前端展示技术,结合transe+cf+mf后端算法引擎及数据库,以物品场景特征和用户标识作为输入,得到物品推荐结果。可以理解地是,以何种方式实现所述推荐方式不影响本技术实施例的实现。
[0064]
请参阅图2,图2为本技术实施例提供的一种基于混合算法的物品推荐装置的结构示意图,该装置200包括计算模块201和推荐模块202,其中:
[0065]
所述计算模块201,用于加权融合物品之间的余弦相似度和语义相似度,得到物品之间的融合相似度;其中,所述余弦相似度是根据用户对于物品的评分矩阵计算得到的;其中,所述评分矩阵为用户对于物品的评分的集合;根据所述融合相似度,得到用户对于物品的融合预估评分;所述推荐模块202,用于根据所述融合预估评分进行物品推荐。
[0066]
请参阅图3,图3为本技术实施例提供的一种基于混合算法的物品推荐设备的结构示意图,该设备300包括:处理器301、存储器302;所述存储器301用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器302执行时使所述处理器302执行上述方法。
[0067]
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1