一种基于深度学习的票据OCR识别方法与流程
一种基于深度学习的票据ocr识别方法
技术领域
1.本发明涉及光学字符识别技术领域,特别指一种基于深度学习的票据ocr识别方法。
背景技术:
2.传统上,将文字输入到电子设备主要采用人工目视并录入的方法,但是该方法无法满足海量的文字输入,不仅效率低下,且人工成本高。随着信息化的日渐发展和普及,ocr(optical character recognition,光学字符识别)技术应运而生,ocr技术是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测不同文字的纹理特征差异确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,而ocr技术主要包括ocr检测技术和ocr识别技术。
3.ocr检测技术主要利用图像中文字与背景区域的差异,确定图像中文字或文本行的位置。基于文字的ocr检测算法是先通过检测单个文字的区域,然后通过文字之间的位置关系将单个文字区域合并为文本行区域,例如经典的ctpn检测算法,但由于很多文字与文字之间的间隔较小,很难精确的检测出文字的边界,且文字之间需要根据上下文进行组合,流程复杂。基于文本行的ocr检测算法主要通过目标检测算法或者语义分割算法识别出整行的文字区域。
4.ocr识别技术指利用不同方法识别出不同图像块中的文字信息或者文本行信息,主要通过模板匹配对比不同模板文字与待识别图像的灰度差异得到最相似的文字,这种方法无法利用文本的上下文信息,检测速度慢且精度低。
5.由于传统的ocr技术存在的识别精度低、操作流程复杂、检测速度慢的缺点,无法适用于种类繁多、数量庞大的票据的识别。因此,如何提供一种基于深度学习的票据ocr识别方法,实现提升票据文字识别的精度以及效率,成为一个亟待解决的问题。
技术实现要素:
6.本发明要解决的技术问题,在于提供一种基于深度学习的票据ocr识别方法,实现提升票据文字识别的精度以及效率。
7.本发明是这样实现的:一种基于深度学习的票据ocr识别方法,包括:
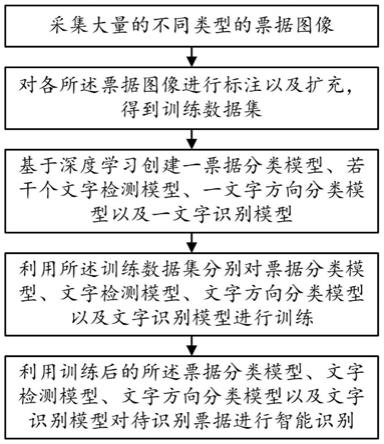
8.步骤s10、采集大量的不同类型的票据图像;
9.步骤s20、对各所述票据图像进行标注以及扩充,得到训练数据集;
10.步骤s30、基于深度学习创建一票据分类模型、若干个文字检测模型、一文字方向分类模型以及一文字识别模型;
11.步骤s40、利用所述训练数据集分别对票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练;
12.步骤s50、利用训练后的所述票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型对待识别票据进行智能识别。
13.进一步地,所述步骤s10具体为:
14.在不同光照强度以及背景颜色的环境下,采集大量的不同类型的票据图像。
15.进一步地,所述步骤s20具体为:
16.通过图像检测标注工具对采集的各所述票据图像进行票据类型、文字区域、文字方向以及文字内容的标注,对标注后的各所述票据图像进行随机偏转、平移或者缩放的样本扩充操作,得到训练数据集。
17.进一步地,所述步骤s30中,所述票据分类模型用于对票据进行分类,采用vgg16网络作为主干特征提取网络,采用交叉熵函数作为损失函数;
18.所述文字检测模型用于检测文本区域并进行截取,为dbnet网络,采用resnet网络作为主干特征提取网络,采用可变性卷积提取特征,使卷积和的视野大小随特征变化;
19.所述文字方向分类模型用于识别文字的排列方向,采用rcnn网络作为主干特征提取网络,采用二分类交叉熵函数作为损失函数;
20.所述文字识别模型用于识别文字,先通过cnn网络提取底层图像特征,再通过rnn网络提取文本行的上下文表征,并采用ctc函数作为损失函数。
21.进一步地,所述步骤s40具体包括:
22.步骤s41、将所述训练数据集按预设的比例划分为训练集和验证集;
23.步骤s42、利用所述训练集分别对票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练预设次数;
24.步骤s43、利用所述验证集分别对票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行验证,验证通过则进入步骤s50;验证不通过则扩充所述训练数据集后,进入步骤s41。
25.进一步地,所述步骤s50具体包括:
26.步骤s51、基于各票据类型分别创建一票据模板;
27.步骤s52、利用训练后的所述票据分类模型对待识别票据进行分类,并输入对应的文字检测模型;
28.步骤s53、所述文字检测模型识别待识别票据里的文本区域并进行截取,得到文本图片并输入文字方向分类模型;
29.步骤s54、所述文字方向分类模型对文本图片的文字排列方向进行识别,并对所述文本图片进行校正以使文字水平排列,并将校正后的所述文本图片输入文字识别模型;
30.步骤s55、所述文字识别模型识别文本图片中的文字,并将识别的文字自动填入对应所述票据模板的对应位置;
31.步骤s56、保存并展示填入文字的所述票据模板,完成待识别票据的智能识别。
32.进一步地,所述步骤s51中,所述票据模板至少包括字段名称、参考字段名称以及字段值填入位置。
33.本发明的优点在于:
34.1、通过采集大量的不同类型的票据图像并进行标注和扩充,得到训练数据集,再利用训练数据集对基于深度学习创建的票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练,最终依次利用训练过的票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行票据分类、文本区域识别和截取、文字排列方向校正、文
字识别,以完成票据的智能识别,由于扩充了样本量对各模型进行训练,票据识别过程进行了分类和校正,且基于深度学习创建的模型能够抽取高层语义特征,并结合文本行的上下文语义信息克服拍摄不清晰等造成的影响,最终极大的提升了票据文字识别的精度。
35.2、通过票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型即可自动对待识别票据进行识别,并将识别内容自动填入对应的票据模板,相对于人工识别并录入票据信息,极大的提升了票据文字识别的效率。
附图说明
36.下面参照附图结合实施例对本发明作进一步的说明。
37.图1是本发明一种基于深度学习的票据ocr识别方法的流程图。
38.图2是本发明一种基于深度学习的票据ocr识别系统的电路原理框图。
39.标记说明:
40.100
‑
一种基于深度学习的票据ocr识别系统,1
‑
摄像头,2
‑
工控机,3
‑
显示器。
具体实施方式
41.本技术实施例中的技术方案,总体思路如下:通过采集大量的不同类型的票据图像并进行标注和扩充,得到训练数据集,再利用训练数据集对基于深度学习创建的票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练,最终依次利用训练过的票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行票据分类、文本区域识别和截取、文字排列方向校正、文字识别,以完成票据的智能识别,并将识别内容自动填入对应的票据模板,以提升票据文字识别的精度以及效率。
42.请参照图1至图2所示,本发明需使用如下一种基于深度学习的票据ocr识别系统100,包括一摄像头1、一工控机2、一显示器3、一工作台(未图示)以及一支架(未图示);所述工控机2的一端与摄像头1连接,另一端与显示器3连接;所述摄像头1通过支架架设于工作台上。
43.所述摄像头1用于对待识别票据进行拍摄并传输给工控机2,可变分辨率范围为宽:1000~2000,高:1000~8000;所述工控机2用于对待识别票据进行识别;所述显示器3用于显示工控机2的识别结果;所述工作台用于放置待识别票据以便摄像头1的拍摄。
44.本发明一种基于深度学习的票据ocr识别方法的较佳实施例,包括:
45.步骤s10、采集大量的不同类型的票据图像;
46.步骤s20、对各所述票据图像进行标注以及扩充,得到训练数据集;
47.步骤s30、基于深度学习创建一票据分类模型、若干个文字检测模型、一文字方向分类模型以及一文字识别模型;
48.步骤s40、利用所述训练数据集分别对票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练;
49.步骤s50、利用训练后的所述票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型对待识别票据进行智能识别。
50.通过所述识别方法,即使待识别票据存在弯曲、变形、偏转等情况,均能进行很好的识别。
51.所述步骤s10具体为:
52.在不同光照强度以及背景颜色的环境下,采集大量的不同类型的票据图像,以提升所述票据图像的多样性。具体实施时,还可使用不同规格的摄像头采集票据图像。
53.所述步骤s20具体为:
54.通过图像检测标注工具对采集的各所述票据图像进行票据类型、文字区域、文字方向以及文字内容的标注,对标注后的各所述票据图像进行随机偏转、平移或者缩放的样本扩充操作,得到训练数据集。具体实施时,还可在不同票据图像的背景图案中加入不同格式和大小的文本行来扩充样本量。所述票据类型包括增值税发票、动车票、汽车票等。所述图像检测标注工具优选为labelme。
55.所述步骤s30中,所述票据分类模型用于对票据进行分类,采用vgg16网络作为主干特征提取网络,采用交叉熵函数作为损失函数;
56.所述文字检测模型用于检测文本区域并进行截取,为dbnet网络(可微阈值网络),采用resnet网络作为主干特征提取网络,采用可变性卷积提取特征,使卷积和的视野大小随特征变化,适用于扭曲变形等不同形状的文本区域检测;
57.所述文字方向分类模型用于识别文字的排列方向,采用rcnn网络作为主干特征提取网络,采用二分类交叉熵函数作为损失函数;
58.所述文字识别模型用于识别文字,先通过cnn网络提取底层图像特征,再通过rnn网络提取文本行的上下文表征,并采用ctc函数作为损失函数,即所述文字识别模型采用rcnn
‑
ctc网络。
59.所述步骤s40具体包括:
60.步骤s41、将所述训练数据集按预设的比例划分为训练集和验证集;
61.步骤s42、利用所述训练集分别对票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练预设次数;
62.步骤s43、利用所述验证集分别对票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行验证,验证通过则进入步骤s50;验证不通过则扩充所述训练数据集后,进入步骤s41。
63.所述步骤s50具体包括:
64.步骤s51、基于各票据类型分别创建一票据模板;
65.步骤s52、利用训练后的所述票据分类模型对待识别票据进行分类,并输入对应的文字检测模型;
66.步骤s53、所述文字检测模型识别待识别票据里的文本区域并进行截取,得到文本图片并输入文字方向分类模型;
67.步骤s54、所述文字方向分类模型对文本图片的文字排列方向进行识别,并对所述文本图片进行校正以使文字水平排列,并将校正后的所述文本图片输入文字识别模型;即判断所述本文图片是否存在颠倒、翻转、倾斜等情况,若存在则进行修正;
68.步骤s55、所述文字识别模型识别文本图片中的文字,并将识别的文字自动填入对应所述票据模板的对应位置;
69.步骤s56、保存并展示填入文字的所述票据模板,完成待识别票据的智能识别。
70.所述步骤s51中,所述票据模板至少包括字段名称、参考字段名称以及字段值填入
位置;由于所述字段名称为人为规定的,不存在于ocr识别结果中,无法进行所述字段值填入位置的匹配,因此设置所述参考字段名称进行匹配。
71.综上所述,本发明的优点在于:
72.1、通过采集大量的不同类型的票据图像并进行标注和扩充,得到训练数据集,再利用训练数据集对基于深度学习创建的票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行训练,最终依次利用训练过的票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型进行票据分类、文本区域识别和截取、文字排列方向校正、文字识别,以完成票据的智能识别,由于扩充了样本量对各模型进行训练,票据识别过程进行了分类和校正,且基于深度学习创建的模型能够抽取高层语义特征,并结合文本行的上下文语义信息克服拍摄不清晰等造成的影响,最终极大的提升了票据文字识别的精度。
73.2、通过票据分类模型、文字检测模型、文字方向分类模型以及文字识别模型即可自动对待识别票据进行识别,并将识别内容自动填入对应的票据模板,相对于人工识别并录入票据信息,极大的提升了票据文字识别的效率。
74.虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1