基于AdaptGAN的低照度语义分割方法
基于adaptgan的低照度语义分割方法
技术领域
1.本发明涉及生成对抗网络gan(generative adversarial networks,简称gan)技术、无监督领域自适应技术和图像语义分割技术,具体是一种基于适应性生成对抗网络adaptgan(adaptive generative adversarial networks,简称adaptgan)的低照度语义分割方法。
背景技术:
2.语义分割技术具有非常广泛的应用范围,在自动驾驶、人机交互和遥感图像等方面都有非常重要的作用,语义分割技术是计算机视觉领域一个非常重要的研究课题。随着人工智能技术的高速发展,深度学习技术提升了图像语义分割的分割精度和泛化性。
3.领域自适应技术作为迁移学习中的一种代表性方法,其解决的主要问题是当源域和目标域数据分布不同或存在域漂移时,能够充分利用源域的数据学习到一个目标域上的预测函数,使得该预测函数在目标域上也拥有最小的预测误差。此外,采用生成对抗网络的对抗学习方法能有效的实现领域自适应。
4.现有的语义分割方法主要是针对正常光照场景下进行设计,但是在夜间驾驶时,由于光照条件差、照度较低,会导致待分割的目标成像较暗、模糊和分辨不清等,最后造成分割精度较低。
技术实现要素:
5.本发明的目的是为了弥补现有图像语义分割技术的不足,提供了一种基于adaptgan的低照度语义分割方法。这种方法能够对低照度的图片进行语义分割,让语义分割的特征图视觉表征能力更强,提高分割精度。
6.实现本发明目的的技术方案是:
7.一种基于adaptgan的低照度语义分割方法,包括如下步骤:
8.1)整合数据集:基于公开的cityscapes数据集,采用模拟低照度环境下的成像特点,得到低照度环境下的数据集cityscapes
‑
night,依据领域自适应技术的特点,将cityscapes数据集作为源域,cityscapes
‑
night数据集作为目标域;
9.2)训练光照正则化网络,包括如下步骤:
[0010]1‑
2)将所有的正常光照图片和低照度图片进行预处理,即将正常光照图片和低照度图片的高度和宽度统一缩放至960
×
960像素,从而获得更优的精度;
[0011]2‑
2)将正常照度图像和低照度图像输入到光照正则化网络进行处理,首先光照正则化网络从两种不同照度图像的共同潜在空间中提取到目标域和源域的共同表征,然后用光照正则化网络提取到的特征图与输入图像相加得到光照正则化图像;
[0012]3‑
2)计算输入图像与光照正则化图像之间的亮度损失,损失函数如公式(1)所示:
[0013]
l
light
=l
tv
+l
ssim
ꢀꢀ
(1),
[0014]
其中l
light
为亮度损失,l
tv
为全变差损失,l
ssim
为结构相似度损失,全变差损失如公
式(2)所示:
[0015][0016]
其中i∈{i
s
,i
t
}表示输入的图片,i
s
是源域的输入图片,i
t
是目标域输入图片,r∈{r
s
,r
t
}表示光照正则化网络的输出,r
s
是源域图片对应的输出,r
t
是目标域图片对应的输出,n为图片对应的像素点个数,和分别代表相邻像素之间沿x和y方向的强度梯度,||
·
||1是l1范数即每个像素点计算得到的值的绝对值求和;
[0017]
结构相似度损失如公式(3)所示:
[0018][0019]
其中,u
i
和u
r
分别表示i和r的均值,σ
i
和σ
r
表示标准差,σ
ir
表示协方差,c1=0.012,c2=0.032;
[0020]
3)训练语义分割网络:
[0021]
语义分割网络设有顺序连接的高分辨率残差网络、并行的多尺度特征聚合模块及自注意力模块、上采样和分类预测模块,其中,自注意力模块包括并行的通道自注意力模块和空间自注意力模块,过程包括如下步骤:
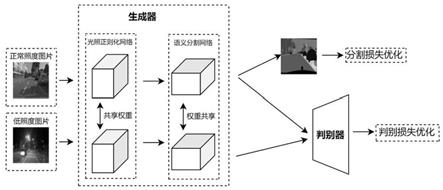
[0022]1‑
3)训练高分辨率残差网络:将光照正则化图像送入高分辨率残差网络进行特征提取,高分辨率残差网络从源领域和目标领域共同的潜在空间中提取特征;
[0023]2‑
3)训练多尺度特征聚合模块:首先将高分辨率残差网络产生的特征图经过一个1
×
1卷积块进行通道降维,再将降维后的特征图送入多尺度特征聚合模块进行多尺度上下文特征提取和特征融合;
[0024]3‑
3)训练空间自注意力模块:将高分辨率残差网络的输出特征图送入空间自注意力模块进行空间位置上下文关系建模;
[0025]4‑
3)训练通道自注意力模块:将高分辨率残差网络的输出特征图送入通道自注意力模块进行通道之间上下文关系建模;
[0026]5‑
3)将通道自注意力模块得到的特征图与空间自注意力模块的输出特征图进行相加融合,获得自注意力模块的最终输出特征图,然后用多尺度特征聚合模块的输出特征图与自注意力模块的输出特征图进行通道拼接;
[0027]6‑
3)首先将5
‑
3)过程得到的输出特征图用大小为1
×
1卷积块进行特征融合,并将输出通道数调整到数据集的类别数,然后对特征图进行上采样,将特征图的分辨率恢复到与输入图片相同,最后采用softmax函数归一化输出,对于每个像素位置,选取softmax后最大概率的那个类别作为预测类别,从而得到最终的语义分割结果;
[0028]7‑
3)计算源域正常照度图像的分割预测结果与源域正常照度图像的标签之间的损失,损失函数如公式(4)所示:
[0029][0030]
其中n是像素点个数,c是类别数,是二值指示器,表示第i个像素点以及第c个类别的真实标签,表示网络的预测值;
[0031]
4)训练判别器网络:包括:
[0032]1‑
4)将正常照度图像和低照度图像的语义分割结果送入判别器,判别器对输入的分割结果进行识别,判断出结果是正常照度图像还是低照度图像;
[0033]2‑
4)计算判别器的判断结果与输入图像的正确判别标签之间的损失,损失函数如公式(5)所示:
[0034][0035]
其中,d表示判别器,p
s
表示源域的预测,p
t
表示目标域的预测,r为源域的标签,f为目标域的标签。
[0036]
步骤2)中所述的光照正则化网设有顺序连接的第一卷积块、第一下采样卷积块、第二下采样卷积块、2个堆叠的残差块、第一转置卷积块、第二转置卷积块、第三卷积块和tanh激活层,其中,
[0037]
第一卷积块的卷积核大小为7
×
7、输入通道数为3、输出通道数为64、填充为3、步长为1,卷积之后为批归一化层和relu激活层;
[0038]
第一下采样卷积块的卷积核大小为3
×
3、输入通道数为64、输出通道数为128、步长为2、填充为1,卷积之后为批归一化层和relu激活层;
[0039]
第二下采样卷积块的卷积核大小为3
×
3、步长为2、输入通道数为128、输出通道数为256,卷积之后为批归一化层和relu激活层;
[0040]
每个残差块设有2个第二卷积块,每个第二卷积块设有大小为3
×
3、填充为1、输入特征图通道数和输出通道数都为256的卷积,以及批归一化层和relu激活层;
[0041]
第一个转置卷积块的卷积核大小为3
×
3、步长为2、填充为1、输出填充为1、输入通道数为256、输出通道数为128,卷积块之后为批归一化层和relu激活层;
[0042]
第二转置卷积块的卷积核大小为3
×
3、输入特征图通道数为128、输出特征图通道数为64、步长为2、填充为1、输出填充为1,卷积块之后为批归一化层和relu激活层;
[0043]
第三卷积块的卷积核大小为5
×
5、填充为2、输入通道数64、输出通道数为3,实现过程为:
[0044]4‑
2)将输入图片读取为rgb的3通道格式,首先经过一个卷积块,卷积块的卷积核大小为7
×
7、输入通道数为3、输出通道数为64、填充为3、步长为1,卷积块之后为批归一化层和relu激活层,然后采用卷积核大小为3
×
3、输入通道数为64、输出通道数为128、步长为2、填充为1的下采样卷积块将特征图分辨率降低为输入图片的一半,卷积之后为批归一化层和relu激活层;接着再采用卷积核大小为3
×
3、步长为2、输入通道数为128、输出通道数为256的下采样卷积块将分辨率降低为输入图片的四分之一,卷积之后为批归一化层和relu激活层;
[0045]5‑
2)将步骤4
‑
2)的输出特征图传递给2个堆叠的残差块,每个残差块设有2个卷积块,每个卷积块设有大小为3
×
3、填充为1、输入特征图通道数和输出通道数都为256的卷积,以及批归一化层和relu激活层;
[0046]6‑
2)将步骤5
‑
2)得到的低分辨率特征图用2个转置卷积块进行上采样恢复到与输入图片相同的分辨率,第一个转置卷积的卷积核大小为3
×
3、步长为2、填充为1、输出填充为1、输入通道数为256、输出通道数为128,卷积之后为批归一化和relu函数激活;第二个转
置卷积的卷积核大小为3
×
3、输入特征图通道数为128、输出特征图通道数为64、步长为2、填充为1、输出填充为1,卷积后接着采用批归一化层和relu激活层;
[0047]7‑
2)将步骤6
‑
2)得到的特征图用卷积层提取特征,卷积层的卷积核大小为5
×
5、填充为2、输入通道数64、输出通道数为3,然后采用tanh激活函数进行非线性激活得到最终的特征图,最后将最终的特征图与步骤4
‑
2)中3通道的rgb图像逐元素相加,获得光照正则化后的图像。
[0048]
步骤3)中所述的高分辨率残差网络依次设有:
[0049]
第四卷积块,第四卷积块包含一个卷积、批归一化层和relu激活层,其中卷积的卷积核大小为7x7、输入通道数为3、输出通道数为64、步长为2,第四卷积块之后为最大池化层,最大池化层的池化大小3
×
3、步长为2、填充为1;
[0050]
其次设有堆叠的3个卷积组,对于每个卷积组,首先是一个卷积核大小为1
×
1、输入特征图通道数为64、输出特征图通道数为64、步长为1的卷积,然后再接一个卷积核大小为3
×
3、输出特征图通道数为64的卷积,最后使用卷积核大小为1x1、输出特征图通道数为256的卷积核,每一个卷积之后都接批归一化层和relu激活层;
[0051]
然后设有堆叠的4个卷积组,每个卷积组包含3个卷积层,第一个卷积层的卷积核大小为1
×
1、输出特征图通道数为128、输入通道数为256,第二个卷积层的卷积核大小为3
×
3、输出通道数为128,第三个卷积层的卷积核大小为1
×
1、输出通道数为512,每一个卷积之后紧接着用批归一化和relu激活层;
[0052]
接着设有堆叠的23个空洞卷积残差块,每一个空洞卷积残差块包含3个卷积层,第一个卷积层为输出通道数为256、卷积核大小为1
×
1的卷积,第二个卷积层为输出通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2以及步长为1的卷积,第三个卷积层为卷积核大小为1
×
1、输出特征图通道数为1024的卷积,在每一个卷积之后都使用批归一化层和relu激活层;
[0053]
最后设有堆叠的3个空洞卷积残差块,对于每一个空洞卷积残差块,首先为一个卷积核大小为1
×
1、输出特征图通道数为512的卷积,然后为卷积核大小为3
×
3、空洞率为4、填充为4、输出通道数为512的空洞卷积,最后为一个输出通道数为2048、卷积核的大小为1
×
1的卷积,在每个卷积层之后紧接着设有批归一化层和relu激活层,实现过程为:
[0054]8‑
3)将光照正则化后的图像送入一个卷积核大小为7
×
7、输入通道数为3、输出通道数为64、步长为2的卷积,卷积之后接着为批归一化层和relu激活层,卷积后的特征图分辨率降低为输入图片的二分之一,然后采用最大池化层进行下采样,池化大小为3
×
3、步长为2、填充为1,最大池化后的输出特征图分辨率降低为输入图片的四分之一;
[0055]9‑
3)将步骤8
‑
3)中的输出特征图用堆叠的3个卷积组进行进一步的特征提取,对于每个卷积组,首先是一个卷积核大小为1
×
1、输入特征图通道数为64、输出特征图通道数为64的卷积,然后再接一个卷积核大小为3
×
3、输出特征图通道数为64的卷积,最后使用卷积核大小为1x1、输出特征图通道数为256的卷积,此外,每个卷积之后都接批归一化层和relu激活层;
[0056]
10
‑
3)将步骤9
‑
3)的输出特征图用4个堆叠的卷积组提取特征,从而增强网络的视觉表征能力,每个卷积组包含3个卷积层,第一个卷积层采用卷积核大小为1
×
1、输出特征图通道数为128、输入通道数为256的卷积,第二个卷积层采用卷积核大小为3
×
3、输出通道
数为128的卷积,第三个卷积层采用卷积核大小为1
×
1、输出通道数为512的卷积,每一个卷积之后紧接着采用批归一化层和relu激活层;此外,通过将第一个卷积组的第二个卷积的卷积步长设置为2,从而将特征图的分辨率降低为输入图片的八分之一;
[0057]
11
‑
3)将步骤10
‑
3)得到的特征图用堆叠的23个空洞卷积残差块继续进行特征提取,每个空洞卷积残差块由3个卷积层、批归一化层和relu激活层构成,第一个卷积层为输出通道数为256、卷积核大小为1
×
1的卷积,第二个卷积层为输出通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2以及步长为1的卷积,第三个卷积层采用大小为卷积核大小1
×
1、输出特征图通道数为1024的卷积,在每一个卷积之后都使用批归一化层和relu激活;
[0058]
12
‑
3)最后将步骤11
‑
3)得到的特征图用堆叠的3个空洞卷积残差块进一步提取特征,对于每一个空洞卷积残差块,首先用一个卷积核大小为1
×
1、输出特征图通道数为512的卷积,然后采用卷积核大小为3
×
3、空洞率为4、填充为4、输出通道数为512的空洞卷积,最后使用一个输出通道数为2048、卷积核的大小为1
×
1的卷积,每个卷积之后紧接着使用批归一化层和relu激活层。
[0059]
步骤3)中所述的多尺度特征聚合模块设有并行的五个卷积块与一个全局平均池化层,其中第一个卷积层的卷积核大小为1
×
1、输入通道数和输出通道数都为256;第二个卷积层的输入特征图通道数和输出特征图通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2;第三个卷积层的卷积核大小为3
×
3、空洞率为4、填充为4、输入通道数和输出通道数都为256;第四个卷积层的输入通道数以及输出通道数都为256、卷积核大小为3
×
3、空洞率为8、填充据为8;第五个卷积层的卷积核大小为3
×
3、空洞率为16、填充为16;然后为卷积核大小为1
×
1、输入通道数为1536、输出通道数为256的卷积层,
[0060]
实现过程为:
[0061]
13
‑
3)将高分辨率残差网络得到的特征图送入多尺度特征聚合模块后,多尺度特征聚合模块首先采用并行的五个卷积块与一个全局平均池化层对输入的特征图进行处理,第一个卷积块的卷积核大小为1
×
1、输入通道数和输出通道数都为256;第二个卷积块的输入特征图通道数和输出特征图通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2;第三个卷积的卷积核大小为3
×
3、空洞率为4、填充为4、输入通道数和输出通道数都为256;第四个卷积块的输入通道数和输出通道数都为256、卷积核大小为3
×
3、空洞率为8、填充为8;第五个卷积块的卷积核大小为3
×
3、空洞率为16、填充为16;此外,全局平均池化后,再采用双线性插值将池化后的特征图分辨率上采样到与池化前的大小一致;
[0062]
14
‑
3)首先将步骤13
‑
3)中五个卷积块和全局平均池化层得到的特征图按通道维度进行拼接,然后再使用一个卷积核大小为1
×
1、输入通道数为1536、输出通道数为256的卷积进行通道降维。
[0063]
步骤3)中所述的空间自注意力模块实现过程为:
[0064]
15
‑
3)将高分辨率残差网络得到的特征图记为特征图其中c为特征图通道数、h为特征图的高、w为特征图的宽,首先用3个并行的卷积层对特征图a分别进行卷积操作,3个卷积层的超参数相同即输入通道数为2048、输出通道数为512、卷积核大小为1
×
1,经过卷积处理后得到3个新的输出特征图,分别记为特征图其次将特征图d调整形状变换为矩阵其
中n=h
×
w,再对矩阵k进行转置得到矩阵同时将e调整形状变为矩阵然后用矩阵k
t
与矩阵q相乘得到新的矩阵再用softmax函数对矩阵o进行归一化后可得空间注意力矩阵接着将特征图f改变形状变为矩阵用矩阵v与自注意力矩阵s相乘得到矩阵最后将矩阵m调整到与特征图a相同的形状,记为特征图
[0065]
16
‑
3)将特征图a与特征图b对应位置元素相加,再使用一个卷积核大小为1
×
1、输出通道数为256的卷积进行通道降维,卷积后的输出特征图为空间自注意力模块的最终输出。
[0066]
步骤3)中所述的通道自注意力模块实现过程为:
[0067]
17
‑
3)将高分辨率残差网络得到的特征图记为特征图首先分别对特征图a改变形状后得到3个新的矩阵,分别记为矩阵其中n=h
×
w;其次将矩阵n转置得矩阵再用矩阵l与矩阵n
t
相乘得到新的矩阵然后用softmax函数对矩阵u进行归一化后可得通道自注意力矩阵最后用自注意力矩阵z与矩阵p相乘得到矩阵再将i调整到与特征图a相同的形状,记为特征图
[0068]
18
‑
3)将特征图a与特征图g按对应位置元素进行相加,再将相加的结果用一个卷积核大小为1
×
1、输出通道数为256的卷积进行通道降维,把降维后的输出特征图作为通道自注意力模块的最终输出。
[0069]
步骤4)中所述的判别器网络为:
[0070]
包括串联的4个卷积层和1个分类器,第一个卷积层的卷积核大小为4
×
4、步长为2、填充为1、输入通道数为类别数、输出通道数为64;第二个卷积层的卷积核大小为4
×
4、输入特征图通道数为64、输出特征图通道数为128、步长为2、填充为1;第三个卷积层的卷积核尺寸为4
×
4、输入通道数为128、输出通道数为256、填充为1、步长为2;第四个卷积层的卷积核大小为4
×
4、输入通道数和输出通道数都为256、步长为2、填充为1,在每一个卷积层之后都接上一个负数区域激活值为0.2的泄露修正线性单元leakyrelu激活函数,最后采用一个输出通道数为1、卷积核大小为4
×
4的卷积作为分类器。
[0071]
本技术方案解决的是低照度语义分割中,由于低照度环境下,图片对比度和目标可见度低,导致图像分割精度欠佳的问题。在本技术方案中,首先使用光照正则化网络对源域正常照度图片和目标域低照度图片进行亮度等方面的对齐,从而弥补源域与目标域的差距;然后使用语义分割网络对正常照度图片和低照度图片进行语义分割,计算正常照度的分割结果与标签之间的损失;最后将正常照度图片和低照度图片的分割结果输入到判别器,判别器对图片进行识别,区分图片是来自正常照度还是低照度,并计算损失;此外,采用对抗学习方法和随机梯度下降算法来优化网络,进而得到精确的低照度图片语义分割结果。
[0072]
这种方法能够对低照度的图片进行语义分割,让语义分割的特征图视觉表征能力更强,改善语义分割的分割效果,提高分割精度。
附图说明
[0073]
图1为实施例中的adaptgan网络结构示意图;
[0074]
图2为实施例中的光照正则化网络结构示意图;
[0075]
图3为实施例中的语义分割网络结构示意图;
[0076]
图4为实施例中的多尺度特征聚合模块结构示意图;
[0077]
图5为实施例中的空间自注意力模块结构示意图;
[0078]
图6为实施例中通道自注意力模块结构示意图;
[0079]
图7为实施例中的判别器网络结构示意图。
具体实施方式
[0080]
下面结合附图和实施例对本发明的内容作进一步的阐述,但不是对本发明的限定。
[0081]
实施例:
[0082]
参照图1,一种基于adaptgan的低照度语义分割方法,包括如下步骤:
[0083]
1)整合数据集:基于公开的cityscapes数据集,采用模拟低照度环境下的成像特点,得到低照度环境下的数据集cityscapes
‑
night,依据领域自适应技术的特点,将cityscapes数据集作为源域,cityscapes
‑
night数据集作为目标域;
[0084]
2)训练光照正则化网络,光照正则化网络使源域和目标域在亮度方面进行领域自适应,将源域和目标域图片映射到一个新的特征空间,弥补源域和目标域图像的差距,降低网络对光照变化的敏感性,从而提升算法对光照条件的鲁棒性,包括如下步骤:
[0085]1‑
2)将所有的正常光照图片和低照度图片进行预处理,即将正常光照图片和低照度图片的高度和宽度统一缩放至960
×
960像素,从而获得更优的精度;
[0086]2‑
2)将正常照度图像和低照度图像输入到光照正则化网络进行处理,首先光照正则化网络从两种不同照度图像的共同潜在空间中提取到目标域和源域的共同表征,然后用光照正则化网络提取到的特征图与输入图像相加得到光照正则化图像;
[0087]3‑
2)计算输入图像与光照正则化图像之间的亮度损失,损失函数如公式(1)所示:
[0088]
l
light
=l
tv
+l
ssim
ꢀꢀ
(1),
[0089]
其中l
light
为亮度损失,l
tv
为全变差损失,l
ssim
为结构相似度损失,全变差损失如公式(2)所示:
[0090][0091]
其中i∈{i
s
,i
t
}表示输入的图片,i
s
是源域的输入图片,i
t
是目标域输入图片,r∈{r
s
,r
t
}表示光照正则化网络的输出,r
s
是源域图片对应的输出,r
t
是目标域图片对应的输出,n为图片对应的像素点个数,和分别代表相邻像素之间沿x和y方向的强度梯度,||
·
||1是l1范数即每个像素点计算得到的值的绝对值求和;
[0092]
结构相似度损失的作用是保障光照正则化后产生的图片能够维持原图的结构,结构相似度损失如公式(3)所示:
[0093][0094]
其中,u
i
和u
r
分别表示i和r的均值,σ
i
和σ
r
表示标准差,σ
ir
表示协方差,c1=0.012,c2=0.032;
[0095]
3)训练语义分割网络:语义分割网络设有顺序连接的高分辨率残差网络、并行的多尺度特征聚合模块及自注意力模块、上采样和分类预测模块,其中,自注意力模块包括并行的通道自注意力模块和空间自注意力模块,如图3所示,过程包括如下步骤:
[0096]1‑
3)训练高分辨率残差网络:将光照正则化图像送入高分辨率残差网络进行特征提取,高分辨率残差网络从源领域和目标领域共同的潜在空间中提取特征;
[0097]2‑
3)训练多尺度特征聚合模块:首先将高分辨率残差网络产生的特征图经过一个1
×
1卷积块进行通道降维,再将降维后的特征图送入多尺度特征聚合模块进行多尺度上下文特征提取和特征融合;
[0098]3‑
3)训练空间自注意力模块:将高分辨率残差网络的输出特征图送入空间自注意力模块进行空间位置上下文关系建模;
[0099]4‑
3)训练通道自注意力模块:将高分辨率残差网络的输出特征图送入通道自注意力模块进行通道之间上下文关系建模;
[0100]5‑
3)将通道自注意力模块得到的特征图与空间自注意力模块的输出特征图进行相加融合,获得自注意力模块的最终输出特征图,然后用多尺度特征聚合模块的输出特征图与自注意力模块的输出特征图进行通道拼接;
[0101]6‑
3)首先将5
‑
3)过程得到的输出特征图用大小为1
×
1卷积块进行特征融合,并将输出通道数调整到数据集的类别数,然后对特征图进行上采样,将特征图的分辨率恢复到与输入图片相同,最后采用softmax函数归一化输出,对于每个像素位置,选取softmax后最大概率的那个类别作为预测类别,从而得到最终的语义分割结果;
[0102]7‑
3)计算源域正常照度图像的分割预测结果与源域正常照度图像的标签之间的损失,损失函数如公式(4)所示:
[0103][0104]
其中n是像素点个数,c是类别数,是二值指示器,表示第i个像素点以及第c个类别的真实标签,表示网络的预测值;
[0105]
4)训练判别器网络:包括:
[0106]1‑
4)将正常照度图像和低照度图像的语义分割结果送入判别器,判别器对输入的分割结果进行识别,判断出结果是正常照度图像还是低照度图像;
[0107]2‑
4)计算判别器的判断结果与输入图像的正确判别标签之间的损失,损失函数如公式(5)所示:
[0108][0109]
其中,d表示判别器,p
s
表示源域的预测,p
t
表示目标域的预测,r为源域的标签,f为目标域的标签。
[0110]
步骤2)中所述的光照正则化网设有顺序连接的第一卷积块、第一下采样卷积块、第二下采样卷积块、2个堆叠的残差块、第一转置卷积块、第二转置卷积块、第三卷积块和tanh激活层,其中,
[0111]
第一卷积块的卷积核大小为7
×
7、输入通道数为3、输出通道数为64、填充为3、步长为1,卷积之后为批归一化层和relu激活层;
[0112]
第一下采样卷积块的卷积核大小为3
×
3、输入通道数为64、输出通道数为128、步长为2、填充为1,卷积之后为批归一化层和relu激活层;
[0113]
第二下采样卷积块的卷积核大小为3
×
3、步长为2、输入通道数为128、输出通道数为256,卷积之后为批归一化层和relu激活层;
[0114]
每个残差块设有2个第二卷积块,每个第二卷积块设有大小为3
×
3、填充为1、输入特征图通道数和输出通道数都为256的卷积,以及批归一化层和relu激活层;
[0115]
第一个转置卷积块的卷积核大小为3
×
3、步长为2、填充为1、输出填充为1、输入通道数为256、输出通道数为128,卷积块之后为批归一化层和relu函数层;
[0116]
第二转置卷积块的卷积核大小为3
×
3、输入特征图通道数为128、输出特征图通道数为64、步长为2、填充为1、输出填充为1,卷积块之后为批归一化层和relu激活层;
[0117]
第三卷积块的卷积核大小为5
×
5、填充为2、输入通道数64、输出通道数为3;
[0118]
如图2所示,实现过程为:
[0119]4‑
2)将输入图片读取为rgb的3通道格式,首先经过一个卷积块,卷积块的卷积核大小为7
×
7、输入通道数为3、输出通道数为64、填充为3、步长为1,卷积块之后为批归一化层和relu激活层,然后采用卷积核大小为3
×
3、输入通道数为64、输出通道数为128、步长为2、填充为1的下采样卷积块将特征图分辨率降低为输入图片的一半,卷积之后为批归一化层和relu激活层;接着再采用卷积核大小为3
×
3、步长为2、输入通道数为128、输出通道数为256的下采样卷积块将分辨率降低为输入图片的四分之一,卷积之后为批归一化层和relu激活层;
[0120]5‑
2)将步骤4
‑
2)的输出特征图传递给2个堆叠的残差块,每个残差块设有2个卷积块,每个卷积块设有大小为3
×
3、填充为1、输入特征图通道数和输出通道数都为256的卷积,以及批归一化层和relu激活层;
[0121]6‑
2)将步骤5
‑
2)得到的低分辨率特征图用2个转置卷积块进行上采样恢复到与输入图片相同的分辨率,第一个转置卷积的卷积核大小为3
×
3、步长为2、填充为1、输出填充为1、输入通道数为256、输出通道数为128,卷积之后为批归一化和relu函数激活;第二个转置卷积的卷积核大小为3
×
3、输入特征图通道数为128、输出特征图通道数为64、步长为2、填充为1、输出填充为1,卷积后接着采用批归一化层和relu激活层;
[0122]7‑
2)将步骤6
‑
2)得到的特征图用卷积层提取特征,卷积层的卷积核大小为5
×
5、填充为2、输入通道数64、输出通道数为3,然后采用tanh激活函数进行非线性激活得到最终的特征图,最后将最终的特征图与步骤4
‑
2)中3通道的rgb图像逐元素相加,获得光照正则化后的图像。
[0123]
步骤3)中所述的高分辨率残差网络结构如表1所示,依次设有:
[0124]
第四卷积块,第四卷积块包含一个卷积、批归一化层和relu激活层,其中卷积的卷积核大小为7x7、输入通道数为3、输出通道数为64、步长为2;第四卷积块之后为最大池化
层,该最大池化层的池化大小3
×
3、步长为2、填充为1;其次为堆叠的3个卷积组,对于每个卷积组,首先是一个卷积核大小为1
×
1、输入特征图通道数为64、输出特征图通道数为64、步长为1的卷积,然后再接一个卷积核大小为3
×
3、输出特征图通道数为64的卷积,最后使用卷积核大小为1x1、输出特征图通道数为256的卷积核,此外,每一个卷积之后都接批归一化层和relu激活层;然后为堆叠的4个卷积组,每个卷积组包含3个卷积层,第一个卷积层的卷积核大小为1
×
1、输出特征图通道数为128、输入通道数为256,第二个卷积层的卷积核大小为3
×
3、输出通道数为128,第三个卷积层的卷积核大小为1
×
1、输出通道数为512,同时,每一个卷积之后紧接着用批归一化和relu激活层;接着为堆叠的23个空洞卷积残差块,每一个空洞卷积残差块包含3个卷积层,第一个卷积层为输出通道数为256、卷积核大小为1
×
1的卷积,第二个卷积层为输出通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2以及步长为1的卷积,第三个卷积层为卷积核大小为1
×
1、输出特征图通道数为1024的卷积,同时,在每一个卷积之后都使用批归一化层和relu激活层;最后为堆叠的3个空洞卷积残差块,对于每一个空洞卷积残差块,首先为一个卷积核大小为1
×
1、输出特征图通道数为512的卷积,然后为卷积核大小为3
×
3、空洞率为4、填充为4、输出通道数为512的空洞卷积,最后为一个输出通道数为2048、卷积核的大小为1
×
1的卷积,在每个卷积层之后紧接着为批归一化层和relu激活层;
[0125]
表1高分辨率残差网络
[0126][0127]
实现过程为:
[0128]8‑
3)将光照正则化后的图像送入一个卷积核大小为7
×
7、输入通道数为3、输出通道数为64、步长为2的卷积,卷积之后接着为批归一化层和relu激活层,卷积后的特征图分辨率降低为输入图片的二分之一,然后采用最大池化层进行下采样,池化大小为3
×
3、步长为2、填充为1,最大池化后的输出特征图分辨率降低为输入图片的四分之一;
[0129]9‑
3)将步骤8
‑
3)中的输出特征图用堆叠的3个卷积组进行进一步的特征提取,对于每个卷积组,首先为一个卷积核大小为1
×
1、输入特征图通道数为64、输出特征图通道数
为64的卷积,然后再接一个卷积核大小为3
×
3、输出特征图通道数为64的卷积,最后使用卷积核大小为1
×
1、输出特征图通道数为256的卷积,每个卷积之后都接批归一化层和relu激活层;
[0130]
10
‑
3)将步骤9
‑
3)的输出特征图用4个堆叠的卷积组提取特征,从而增强网络的视觉表征能力,每个卷积组包含3个卷积层,第一个卷积层采用卷积核大小为1
×
1、输出特征图通道数为128、输入通道数为256的卷积,第二个卷积层采用卷积核大小为3
×
3、输出通道数为128的卷积,第三个卷积层采用卷积核大小为1
×
1、输出通道数为512的卷积,每一个卷积之后紧接着采用批归一化层和relu激活层;此外,通过将第一个卷积组的第二个卷积的卷积步长设置为2,从而将特征图的分辨率降低为输入图片的八分之一;
[0131]
11
‑
3)将步骤10
‑
3)得到的特征图用堆叠的23个空洞卷积残差块继续进行特征提取,每个空洞卷积残差块由3个卷积层、批归一化层和relu激活层构成,第一个卷积层为输出通道数为256、卷积核大小为1
×
1的卷积,第二个卷积层为输出通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2以及步长为1的卷积,第三个卷积层采用大小为卷积核大小1
×
1、输出特征图通道数为1024的卷积,在每一个卷积之后都使用批归一化层和relu激活;
[0132]
12
‑
3)最后将步骤11
‑
3)得到的特征图用堆叠的3个空洞卷积残差块进一步提取特征,对于每一个空洞卷积残差块,首先用一个卷积核大小为1
×
1、输出特征图通道数为512的卷积,然后采用卷积核大小为3
×
3、空洞率为4、填充为4、输出通道数为512的空洞卷积,最后使用一个输出通道数为2048、卷积核的大小为1
×
1的卷积,在每一个卷积之后紧接着使用批归一化层和relu激活层。
[0133]
步骤3)中所述的多尺度特征聚合模块如图4所示为:多尺度特征聚合模块设有并行的5个卷积层与1个全局平均池化层,其中第一个卷积层的卷积核大小为1
×
1、输入通道数和输出通道数都为256;第二个卷积层的输入特征图通道数和输出特征图通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2;第三个卷积层的卷积核大小为3
×
3、空洞率为4、填充为4、输入通道数和输出通道数都为256;第四个卷积层的输入通道数以及输出通道数都为256、卷积核大小为3
×
3、空洞率为8、填充据为8;第五个卷积层的卷积核大小为3
×
3、空洞率为16、填充为16;然后为卷积核大小为1
×
1、输入通道数为1536、输出通道数为256的卷积层,
[0134]
实现过程为:
[0135]
13
‑
3)将高分辨率残差网络得到的特征图送入多尺度特征聚合模块后,多尺度特征聚合模块首先采用并行的五个卷积块与一个全局平均池化层对输入的特征图进行处理,第一个卷积块的卷积核大小为1
×
1、输入通道数和输出通道数都为256;第二个卷积块的输入特征图通道数和输出特征图通道数为256、卷积核大小为3
×
3、空洞率为2、填充为2;第三个卷积的卷积核大小为3
×
3、空洞率为4、填充为4、输入通道数和输出通道数都为256;第四个卷积块的输入通道数和输出通道数都为256、卷积核大小为3
×
3、空洞率为8、填充为8;第五个卷积块的卷积核大小为3
×
3、空洞率为16、填充为16;此外,全局平均池化后,再采用双线性插值将池化后的特征图分辨率上采样到与池化前的大小一致;
[0136]
14
‑
3)首先将步骤13
‑
3)中五个卷积块和全局平均池化层得到的特征图按通道维度进行拼接,然后再使用一个卷积核大小为1
×
1、输入通道数为1536、输出通道数为256的卷积进行通道降维。
[0137]
如图5所示,步骤3)中所述的空间自注意力模块实现过程为:
[0138]
15
‑
3)将高分辨率残差网络得到的特征图记为特征图其中c为特征图通道数、h为特征图的高、w为特征图的宽,首先用3个并行的卷积层对特征图a分别进行卷积操作,3个卷积层的超参数相同即输入通道数为2048、输出通道数为512、卷积核大小为1
×
1,经过卷积处理后得到3个新的输出特征图,分别记为特征图其次将特征图d调整形状变换为矩阵其中n=h
×
w,再对矩阵k进行转置得到矩阵同时将e调整形状变为矩阵然后用矩阵k
t
与矩阵q相乘得到新的矩阵再用softmax函数对矩阵o进行归一化后可得空间注意力矩阵接着将特征图f改变形状变为矩阵用矩阵v与自注意力矩阵s相乘得到矩阵最后将矩阵m调整到与特征图a相同的形状,记为特征图
[0139]
16
‑
3)将特征图a与特征图b对应位置元素相加,再使用一个卷积核大小为1
×
1、输出通道数为256的卷积进行通道降维,卷积后的输出特征图为空间自注意力模块的最终输出。
[0140]
如图6所示,步骤3)中所述的通道自注意力模块实现过程为:
[0141]
17
‑
3)将高分辨率残差网络得到的特征图记为特征图首先分别对特征图a改变形状后得到3个新的矩阵,分别记为矩阵其中n=h
×
w;其次将矩阵n转置得矩阵再用矩阵l与矩阵n
t
相乘得到新的矩阵然后用softmax函数对矩阵u进行归一化后可得通道自注意力矩阵最后用自注意力矩阵z与矩阵p相乘得到矩阵再将i调整到与特征图a相同的形状,记为特征图
[0142]
18
‑
3)将特征图a与特征图g按对应位置元素进行相加,再将相加的结果用一个卷积核大小为1
×
1、输出通道数为256的卷积进行通道降维,把降维后的输出特征图作为通道自注意力模块的最终输出。
[0143]
如图7所示,步骤4)中所述的判别器网络为:
[0144]
包括串联的4个卷积层和1个分类器,第一个卷积层的卷积核大小为4
×
4、步长为2、填充为1、输入通道数为类别数、输出通道数为64;第二个卷积层的卷积核大小为4
×
4、输入特征图通道数为64、输出特征图通道数为128、步长为2、填充为1;第三个卷积层的卷积核尺寸为4
×
4、输入通道数为128、输出通道数为256、填充为1、步长为2;第四个卷积层的卷积核大小为4
×
4、输入通道数和输出通道数都为256、步长为2、填充为1,在每一个卷积层之后都接上一个负数区域激活值为0.2的泄露修正线性单元leakyrelu激活函数,最后采用一个输出通道数为1、卷积核大小为4
×
4的卷积作为分类器。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1