静默式人脸活体检测模型及方法
1.本发明涉及计算机视觉和图像处理领域,更具体地,涉及一种静默式人脸活体检测模型及方法。
背景技术:
2.随着视频监控数据的日渐积聚,硬件平台的不断发展和计算视觉相关技术的迅猛突破,基于深度学习的人脸识别算法在城市安防和智慧社区等领域中大展神威,持续发力。但是随着多媒体设备和互联网的普及,高质量的人脸图像和视频越来越容易被获取,使得传统的人脸识别算法面临着严重的人脸欺诈攻击,如照片、面具、遮挡以及屏幕翻拍等,因此在人脸识别中对用户活体与否的辨别变得异常重要。
3.鉴于视频交互式的人脸活体检测方案的低效率和低人性化设计,一般仅应用于极少数严苛场景,如支付验证等等。在更为广泛的视频监控、智能门禁场景下,静默式的人脸活体检测方案通行效率更高、用户体验更佳。又由于红外摄像头、多目摄像头和3d结构光摄像头成本高昂,现实中极少布控,因此基于深度(rgbd)图的人脸活体检测也鲜有应用。故而基于一般rgb人脸图像的静默式人脸活体检测技术得到工业界和学术界的广泛青睐,应用前景广阔。
4.一般利用rgb图像的静默式人脸活体检测方法仅仅基于某一种局部细节特征,如纹理、光流、3d信息或者传统手工特征等,极易对某种场景过拟合,造成误检和漏检,实用性较差。因此,设计一种准确鲁棒的基于rgb图像的静默式人脸活体检测模型很有必要。
技术实现要素:
5.为了解决上述问题,本发明实施例提供一种克服上述问题或者至少部分地解决上述问题的静默式人脸活体检测模型及方法。
6.根据本发明实施例的第一方面,提供一种静默式人脸活体检测模型,该模型包括:人脸检测模块、骨架网络模块和中心差分卷积分类分支;所述人脸检测模块用于基于输入图片获取人脸检测框,并将所述人脸检测框输入至所述骨架网络模块;所述骨架网络模块用于提取卷积特征,所述卷积特征上接所述中心差分卷积分类分支;所述中心差分卷积分类分支用于判断所述输入图片的人脸是否为活体。
7.根据本发明实施例的第二方面,提供了一种静默式人脸活体检测方法,该方法包括:将待检测的人脸图像输入至上述任一方面提供所述的静默式人脸活体检测模型,获得所述静默式人脸活体检测模型输出的检测结果。
8.本发明实施例提供的静默式人脸活体检测模型及方法,至少具有如下效果:
9.(1)算法仅仅基于rgb单帧图像数据,且为实时静默式人脸活体检测,不需要视频数据和用户配合,相比于基于红外摄像头、3d结构光摄像头和多目摄像头的人脸活体检测方案大大节约成本;相比于配合式的人脸活体检测方案通行效率更高,用户体验更好。
10.(2)设计中心差分卷积的分类分支,通过汇聚特征图的语义信息和梯度信息来捕
获各种环境中细粒度特征和局部相关性,从而提取更加鲁棒的人脸活体特征,有力应对各种攻击,大大提升活体分类精度。
11.(3)引入反射图预测分支,通过对单张图像进行像素级反射剥离来构造监督信号,将来自光滑平面反射光引起的反射伪像作为判定活体与否的有力依据,充分应对2d成像攻击。
12.(4)设计深度图预测分支,将人脸的3d空间分布信息作为辅助监督信号,通过预训练的prnet来得到人脸图像的深度图标注,充分应对2d成像攻击。
13.(5)设计傅里叶频谱预测分支,将人脸图像的傅里叶频谱图作为额外监督信号,充分利用真实人脸与各种假人脸的显著傅里叶频谱分布差异,有效应对各种攻击,显著提升活体检测精度。
14.(6)设计即插即用的轻量级注意力模块,包含空间和通道注意力机制,增强需要增强的空间局部区域或者通道,同时抑制不必要的空间区域或者通道,提升骨架网络的学习能力和表达能力。
附图说明
15.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些图获得其他的附图。
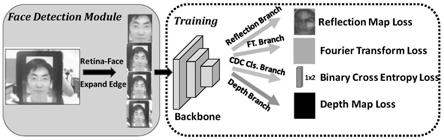
16.图1是本发明实施例的静默式人脸活体检测模型的结构示意图。
17.图2是本发明实施例的多尺度人脸图像产生过程示意图。
18.图3是本发明实施例的基于深度卷积神经网络和rgb单帧图像的静默式人脸活体检测模型的骨架网络结构示意图。
19.图4是本发明实施例的骨架网络中block1与block2的结构示意图。
20.图5是本发明实施例的注意力模块示意图。
21.图6是本发明实施例的通道注意力模块示意图。
22.图7是本发明实施例的空间注意力模块示意图。
23.图8是本发明实施例的中心差分卷积示意图。
24.图9是本发明实施例的中心差分卷积分类分支示意图。
25.图10是本发明实施例的反射图预测分支示意图。
26.图11是本发明实施例的傅里叶频谱图预测分支示意图。
27.图12是本发明实施例的深度图预测分支示意图。
具体实施方式
28.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
29.本发明实施例提供了一种基于深度卷积神经网络和rgb单帧图像的静默式人脸活
体检测模型,该模型不依赖深度摄像头或者双目摄像头,仅仅使用rgb图像,精心设计轻量的卷积神经网络结构和独特的功能算子,并引入空间注意力和通道注意力机制进行特征增强,利用多尺度人脸图片和多种辅助监督信号进行训练,包括深度图、傅里叶频谱图、反射图,并且在前向测试时充分考虑多尺度人脸信息和场景上下文信息,从而对视频监控下的人脸图片进行实时且精准的活体与否的判断。
30.具体地,图1是本发明实施例的静默式人脸活体检测模型的结构示意图,参照图1,本发明实施例提供的静默式人脸活体检测模型包括:人脸检测模块、骨架网络模块和中心差分卷积分类分支;所述人脸检测模块用于基于输入图片获取人脸检测框,并将所述人脸检测框输入至所述骨架网络模块;所述骨架网络模块用于提取卷积特征,所述卷积特征上接所述中心差分卷积分类分支;所述中心差分卷积分类分支用于判断所述输入图片的人脸是否为活体。
31.基于上述实施例的内容,作为一种可选实施例,静默式人脸活体检测模型还包括:反射图预测分支、傅里叶频谱图预测分支和深度图预测分支;所述反射图预测分支、所述傅里叶频谱图预测分支、所述深度图预测分支和所述中心差分卷积分类分支为上接所述卷积特征的并行分支;所述反射图预测分支用于预测所述输入图片的反射图;所述傅里叶频谱图预测分支用于预测所述输入图片的傅里叶频谱图;所述深度图预测分支用于预测所述输入图片的深度图。
32.基于上述实施例的内容,作为一种可选实施例,所述反射图预测分支、所述傅里叶频谱图预测分支和所述深度图预测分支用于在训练中为所述中心差分卷积分类分支的优化提供辅助监督信号;在实际使用时,只调用所述中心差分卷积分类分支。
33.具体地,人脸检测模块是整个算法的前处理过程,将所得人脸检测框送入骨架网络模块提取卷积特征,在该卷积特征之上接四个并行分支:反射图预测分支、傅里叶频谱图预测分支、深度图预测分支和中心差分卷积分类分支,前三个分支分别预测输入图片的反射图(reflection map)、傅里叶频谱图和深度图(depth map),分别以相应的实际标注进行监督。中心差分卷积分类分支利用中心差分卷积判断输入人脸是否为活体,前三个分支是用于在训练中为分类分支的优化提供辅助监督信号,在进行前向测试时,实际只调用分类分支。
34.基于上述实施例的内容,作为一种可选实施例,所述人脸检测模块具体用于在训练阶段产生多尺度人脸图片作为训练数据以进行模型训练,在实际使用阶段,实时产生多尺度人脸检测框作为输入。
35.具体地,人脸检测模块用于在训练阶段产生多尺度人脸图片作为活体检测训练数据,在测试阶段实时产生多尺度人脸检测框作为输入。以retinaface作为人脸检测器,首先在训练阶段制作训练数据,利用预训练的retinaface在原始视频监控图像上进行前向计算得到人脸检测框图片,将其分辨率缩放到112*112,并为增强模型对多尺度人脸的鲁棒性,将原始检测框在原图中外扩2倍,3倍,4倍,遇到图像边界就停止,然后均缩放至112*112的固定分辨率,因此一个人脸将得到四张不同尺度的训练图片;在测试阶段,为捕捉人脸的多尺度信息以及场景的上下文信息,同样将检测框外扩2倍,3倍,4倍,再均缩放至112*112,因此一个人脸将产生四张输入图片,同时将这四张图片送入模型,得到四个置信概率向量,将其均值作为最后的结果。
36.为提高模型对多尺度人脸的鲁棒性,在制作训练数据时,对人脸检测器检测出的人脸图片,对其检测框进行多尺度外扩,具体地,将原始检测框(分辨率为112
×
112)分别外扩2倍、3倍和4倍,然后将所有外扩之后的检测框均缩放至112
×
112,因此一个人脸对应产生四种不同尺度的训练图像,如图2,增强模型对于多尺度人连的鲁棒性。同样地,在进行前向测试时,为了增加感受野,充分利用场景上下文信息和多尺度人脸信息,同样进行上述多尺度变换,因而一次前向产生四个置信概率值,取其平均值作为最后的输出。
37.基于上述实施例的内容,作为一种可选实施例,所述骨架网络模块的模型由多个深度可分离卷积残差块堆叠而成,并在模型中引入空间和通道注意力机制,以端到端学习的方式分别建模特征图在空间上和在通道上的信息分布权重。
38.具体地,所述骨架网络(backbone)模块用于提取人脸图片的卷积特征,设计轻量级的卷积神经网络,引入空间注意力和通道注意力机制增强特征表达能力。然后以其ms1m
‑
arcface人脸识别数据集上的预训练模型作为特征提取网络,去掉全连接层,在其高层特征图上接上述四个分支。
39.骨架网络模块用于快速提取输入图片的卷积特征,具体设计上,为保证模型的高度实时性,降低模型的计算量和参数量,模型整体上为多个深度可分离卷积残差块堆叠而成,并对每层的通道数进行了精心设计,取得模型精度与速度的最佳平衡。同时为了增强特征的鲁棒性和表达能力,在模型中引入空间和通道注意力机制,以端到端学习的方式分别建模特征图在空间上和在通道上的信息分布权重,增强重要的局部空间区域和通道,减弱空间噪声和冗余通道信息;同时减少降采样的次数,获得较大分辨率的高层特征图,保留尽可能多的图像信息。
40.骨架网络的整体结构如图3,具体设计如下表,网络整体上由深度可分离卷积残差块堆叠而成,间以1
×
1卷积进行通道缩放。block1与block2均为bottleneck结构,其详细结构如图4。残差块结构通过短路连接能极大缓解深层网络梯度消失和梯度爆炸的问题,同时还能有效防止过拟合现象。此外,网络的通道数经过精心的剪枝和设计,以确保模型的高度实时性,并取得速度和精度的最佳平衡,本发明实施例设计的模型计算量仅为80m,参数量仅为0.4m。
41.表1骨架网络的整体结构
42.43.[0044][0045]
并且,为增强骨架网络的学习能力,进一步增强特征鲁棒性,本发明在骨架网络中插入轻量级的注意力模块,其示意图如图5,包含通道和空间注意力模块,分别如图6和图7,强调重要的通道和空间区域,同时抑制不必要的通道和空间区域,产生更加鲁棒和更具表
达能力的特征。具体地,对于维度为h
×
w
×
c的输入特征图,通道注意力模块首先通过平均池化和最大池化分别产生两个维度为1
×1×
c的特征向量,然后分别经过一个共享的多层感知机(即全连接层)得到对应的特征向量,其维度依然为1
×1×
c,然后将两者相加,经过一层sigmoid激活函数得到维度为1
×1×
c的通道注意力向量,该向量每个位置的值代表了对应通道的权重,取值在0到1之间,输入特征图与该通道注意力向量相乘得到维度为h
×
w
×
c的通道注意特征图,每个通道都与其对应的通道注意力权重相乘得到新的特征图,其中权重较大的通道得到加强,权重较小的通道被抑制。在通道注意特征图之后,再接上空间注意力模块,对于h
×
w
×
c的通道注意力特征图,首先分别经过通道上的平均池化和最大池化得到维度为h
×
w
×
1的池化特征图,意即对于特征图每一个空间位置,分别取其所有通道上的平均值或者最大值,得到h
×
w
×
1的池化结果,再经过sigmoid激活函数得到维度为h
×
w
×
1的空间注意力图,其中每个位置的取值代表该位置在空间上的的分布权重,将通道注意力特征图域该空间注意力图相乘得到最终的输出特征图,每个空间位置上所有通道的数值都乘以空间注意力图对应位置的权重,重要的局部区域得到增强而冗余的空间区域被抑制。
[0046]
基于上述实施例的内容,作为一种可选实施例,所述反射图预测分支具体用于预测所述输入图像的反射图,然后与实际的标注反射图计算mse损失,用于辅助所述中心差分卷积分类分支的学习;额外的监督信号针对2d成像攻击。
[0047]
具体地,反射图预测(reflection map)分支用于预测输入人脸图像的反射图,然后与实际标注的反射图计算mse损失,用于辅助分类分支的学习,而原图的反射图标注由感知反射图剥离算法(perceptual reflection removal)得到。该额外的监督信号主要针对2d成像攻击(视频、照片回放),因为这类攻击一般会出现比较明显的来自光滑平面反射光引起的反射伪像,可以作为判定活体与否的重要依据。
[0048]
设计反射图预测分支用于预测输入人脸图像的反射图,反映人脸图片中由光滑平面反射光引起的反射伪像,其结构如图10所示,首先用1
×
1卷积将骨架网络顶层特征图的通道从512减小至3,即特征图维度从14
×
14
×
512变为14
×
14
×
3,因为反射图为rgb三通道图,然后经过两层3
×
3卷积得到预测反射图,并与标注反射图计算mse损失,以此监督骨架网络的优化过程,辅助分类分支的学习。原图的标注反射图由预训练的感知反射图剥离模型(perceptual reflection removal)得到,该算法可对单张图片进行像素级反射分离,以此作为原图的反射图标注。
[0049]
基于上述实施例的内容,作为一种可选实施例,所述傅里叶频谱图预测分支具体用于预测所述输入图像的傅里叶频谱图,然后与实际标注的傅里叶频谱图计算mse损失,用于辅助所述中心差分卷积分类分支的学习。
[0050]
具体地,傅里叶频谱图预测分支用于预测输入图片的傅里叶频谱图,然后与实际标注的傅里叶频谱图计算mse损失,用于辅助分类分支的学习,傅里叶频谱标注由输入图片进行傅里叶变换得到。
[0051]
设计傅里叶频谱图预测分支用于预测输入图片的傅里叶频谱图,其结构如图11所示。将假脸图片与真实人脸图片转化为频域图,对比发现假脸的高频信息分布单一,基本沿着水平个垂直方向延伸,但是真实人脸的高频信息呈发散状,真脸和假脸的傅里叶频谱图存在差异,因而本发明引入傅里叶频谱预测分支来进行辅助监督。然后与实际标注的傅里
叶频谱图计算mse损失,用于辅助分类分支的学习。原图的傅里叶频谱标注由输入图片在线进行傅里叶变换,再进行归一化和resize得到。
[0052]
基于上述实施例的内容,作为一种可选实施例,所述深度图预测分支具体用于预测所述输入图像的深度图,反映输入人脸在3d空间中的分布状态,并根据预测的深度图与标注深度图计算mse损失,用于辅助所述中心差分卷积分类分支的学习。
[0053]
具体地,深度图(depth map)预测分支用于输入图片的深度图,反映输入人脸在3d空间中的分布状态,预测深度图与标注深度图计算mse损失,用于辅助分类分支的学习,深度图标注来源于prnet的预训练模型在输入人脸图像上的前向计算结果。
[0054]
设计深度图预测分支用于预测输入图片的深度图,反映输入人脸在3d空间中的分布状态,其结构如图12所示,首先用1
×
1卷积将骨架网络顶层特征图的通道从512减小至64,然后经过两层3
×
3卷积,不改变其分辨率,最后经过一层1
×
1卷积得到维度为14
×
14
×
1的预测深度图,最后与标注深度图计算mse损失,以此监督骨架网络的优化过程,辅助分类分支的学习。原图的标注深度图来源于prnet的预训练模型在输入人脸图像上的前向计算结果。prnet用于3d人脸重建,直接从2d人脸预测得到3d参数,输出uv位置映射图。
[0055]
基于上述实施例的内容,作为一种可选实施例,所述中心差分卷积分类分支具体用于预测所述输入图像中的人脸是否为活体,具体输出二维置信概率向量;中心差分局卷积模拟局部二值模式,用于捕捉局部相关性。
[0056]
具体地,所述中心差分卷积分类分支用于预测输入人脸是否为活体,具体输出二维置信概率向量,中心差分局卷积模拟局部二值模式(lbp),用于捕捉局部相关性,学习更加鲁棒的人脸活体特征,前述三个分支均是为了辅助该分类分支的优化,测试时,仅仅调用该分支进行前向计算。
[0057]
设计基于中心差分卷积的分类分支。中心差分卷积计算流程如图8,具体地,先将特征图上卷积核对应位置的值都减去中心位置的值,然后与卷积核参数进行计算。普通2d卷积的计算首先对输入特征图上卷积核的对应区域(感受野区域)进行局部采样,然后与卷积核的参数权重求加权和,如下式:
[0058][0059]
其中r代表特征图上的感受野,对于3
×
3卷积,r={(
‑
1,
‑
1),(
‑
1,0),
…
,(0,1),(1,1)},其中共9个位置,p0代表输入输出特征图上的当前位置,p
n
代表感受野上每个区域。通过模拟局部二值模式(lbp),初始中心差分卷积的计算表达式为:
[0060][0061]
当p
n
=(0,0)时,相对于中心位置的梯度值始终为0,对于人脸活体检测任务而言,特征图本身的语义信息和局部相关的梯度信息同等重要,因此本文设计的改进中心差分卷积将普通卷积与初始中心差分卷积结合起来,表达式如下:
[0062][0063]
化简得到:
[0064][0065]
本发明设置θ=0.7。中心差分卷积通过同时汇聚特征图的语义信息和梯度信息来捕获各种环境中细粒度特征和局部相关性,学习更加鲁棒的人脸活体特征。
[0066]
本发明设计的基于上述中心差分卷积的分类分支结构如下表,拓扑结构如图9,三层卷积核大小为3,步长为1的中心差分卷积构成残差块结构,然后经过全局平均池化和全连接层得到人脸是活体与否的概率向量。
[0067]
表2中心差分卷积的分类分支结构
[0068][0069]
基于上述实施例的内容,作为一种可选实施例,本发明实施例还提供一种人脸活体检测方法,包括:将待检测的人脸图像输入至上述任一实施例提供的静默式人脸活体检测模型,获得所述静默式人脸活体检测模型输出的检测结果。
[0070]
与现有的人脸活体检测算法相比,本发明实施例提供的基于卷积神经网络和rgb单帧图像的静默式人脸活体检测模型至少具有如下效果:
[0071]
(1)算法仅仅基于rgb单帧图像数据,且为实时静默式人脸活体检测,不需要视频数据和用户配合,相比于基于红外摄像头、3d结构光摄像头和多目摄像头的人脸活体检测方案大大节约成本;相比于配合式的人脸活体检测方案通行效率更高,用户体验更好。
[0072]
(2)设计中心差分卷积的分类分支,通过汇聚特征图的语义信息和梯度信息来捕获各种环境中细粒度特征和局部相关性,从而提取更加鲁棒的人脸活体特征,有力应对各
种攻击,大大提升活体分类精度。
[0073]
(3)引入反射图预测分支,通过对单张图像进行像素级反射剥离来构造监督信号,将来自光滑平面反射光引起的反射伪像作为判定活体与否的有力依据,充分应对2d成像攻击。
[0074]
(4)设计深度图预测分支,将人脸的3d空间分布信息作为辅助监督信号,通过预训练的prnet来得到人脸图像的深度图标注,充分应对2d成像攻击。
[0075]
(5)设计傅里叶频谱预测分支,将人脸图像的傅里叶频谱图作为额外监督信号,充分利用真实人脸与各种假人脸的显著傅里叶频谱分布差异,有效应对各种攻击,显著提升活体检测精度。
[0076]
(6)设计即插即用的轻量级注意力模块,包含空间和通道注意力机制,增强需要增强的空间局部区域或者通道,同时抑制不必要的空间区域或者通道,提升骨架网络的学习能力和表达能力。
[0077]
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
[0078]
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1