一种结合外部知识的文本隐式情感分析方法
1.本发明涉及一种结合外部知识的隐式情感分析方法,具体涉及一种利用外部常识知识库中抽取到的信息有效识别文本中的隐式情感的方法,属于自然语言处理情感分析技术领域。
背景技术:
2.近年来,随着互联网及社交网络的发展,文本情感分析已成为自然语言处理领域最热门的研究方向之一。全面、精确地理解文本所表达的情感,能够应用于股市预测、客户反馈跟踪、意见挖掘等众多场景,产生广泛的社会效益。
3.文本情感分析,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。从文本的语言表达层面,可划分为显式情感分析和隐式情感分析。其中,隐式情感分析被定义为“不含有显式情感词,但表达了主观情感的语言片段(句子,从句或短语)”。
4.目前,显式情感分析作为该领域的基础性研究内容,已经取得了许多丰硕的成果,而隐式情感分析研究仍处于起步阶段。在日常表达中,人们在对客观事物体验及其行为所反映出的情感是丰富而抽象的,除采用显式情感词表达情感外,还采用客观陈述或修辞方式来隐式地表达自己的情感。通过对隐式情感分析的研究,能够更全面、更精确得提升文本情感分析的性能,可以为文本表示学习、自然语言理解、用户建模、知识嵌入等方面研究起到积极的推动作用,也可进一步促进基于文本情感分析相关领域的应用和产业的快速发展。
5.目前,现有的隐式情感分析方法,主要是围绕文本语义信息、句法信息及上下文信息编码上,通过融合多层次的信息进行隐式情感的识别。然而,由于隐式情感文本本身所提供的信息不足,仅对隐式情感文本建模,无法有效捕获隐藏的情感特征。
技术实现要素:
6.本发明的目的是针对现有技术没有充分弥补隐式情感文本有效信息不足的缺陷,为解决有效捕获文本隐藏的情感特征的技术问题,提出了一种结合外部知识的文本隐式情感分析方法。
7.首先,对有关概念进行说明:
8.定义1:知识图谱g
9.指由实体(节点)和关系(不同类型的边)组成的多关系图。
10.知识图谱g由多个子图构成,其表达式为:代表一系列知识子图的集合。
11.定义2:文本序列s
12.其表达式为:{s=w1,w2,...,w
n
},表示需要进行情感分析的句子,该句子中有n个单词w1,w2,...,w
n
,下标n为句子单词序列长度,w代表单词。
13.定义3:输入文本序列的单词特征向量
14.指将输入文本序列向量化所使用的预训练向量,包括语义向量和位置向量。其中,语义向量指当前单词的语义特征信息,位置向量指当前单词在文本序列的位置特征信息。
15.定义4:注意力
16.指为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它的现象。
17.人工智能利用这一现象,提出使得神经网络具备选择特定的输入的能力。本方法中,注意力体现在:
18.(1)若知识图谱中关系(边)和实体(节点)的相关性更高,则赋予其更高的权重;
19.(2)若句子中的单词与当前句的表示更相关,则赋予这个词更高的权重。
20.本发明采用以下技术方案实现。
21.一种结合外部知识的文本隐式情感分析方法,包括以下步骤:
22.步骤1:利用transe模型(知识图谱领域的一种经典模型),对常识知识数据集进行预训练,得到实体嵌入和关系嵌入。
23.其中,所述常识知识数据集,是通过挑选conceptnet中满足条件的<头实体
‑
关系
‑
尾实体>三元组构建组成的知识图。
24.conceptnet是一个开放的、多语言的知识图谱,专注于单词和短语的含义相关的一般知识,能够表示短语的含义之间的众所周知的关系。
25.所述实体嵌入,是指知识图谱中的实体用低维向量的表示。
26.所述关系嵌入,是指知识图谱中的关系用低维向量的表示。
27.步骤2:对常识知识数据集中的每一个知识子图,通过注意力机制,计算每个知识子图的向量表示g
i
。
28.方法如下:
[0029][0030][0031][0032]
其中,g
i
代表知识图谱g中的第i个知识子图,其表达式为:代表知识图谱g中的第i个知识子图,其表达式为:代表一系列三元组的集合,表示第i个知识子图中三元组的个数。τ
i
代表子图中的第i个<头实体
‑
关系
‑
尾实体>三元组,表达式为:τ
i
=(h,r,t),h代表头实体,r代表关系,t代表尾实体。表示第n个三元组在整个知识子图中的注意力权重,即第n个三元组在整个知识子图中的重要性。表示第n个三元组的整体向量表示。s表示文本序列。t表示矩阵转置。w
h
、w
r
、w
t
分别是是第n个三元组中头实体h
n
、关系r
n
、尾实体t
n
的权重矩阵。
[0033]
步骤3:对于输入的需要进行隐式情感分析的句子,即文本序列,采用预训练的单词特征向量来表示文本序列中的每个单词的向量化表示,并与步骤2中获得的每个词为核心实体的知识图特征向量表示进行拼接,得到结合外部知识的单词融合特征表示。
[0034]
其中,每个单词的语义表示、位置表示的加和,作为单词特征向量,从而得到文本序列中各个词对应的特征向量。
[0035]
步骤4:使用双向长短时记忆网络lstm,对步骤3得到的融合外部知识的单词表示进行句子层面的文本编码。
[0036]
其中,长短时记忆网络按照式3至式7,进行网络中节点状态计算:
[0037]
i
(t)
=δ(u
i
x
(t)
+w
i
h
(t
‑
1)
+b
i
)
ꢀꢀꢀ
(3)
[0038]
f
(t)
=δ(u
f
x
(t)
+w
f
h
(t
‑
1)
+b
f
)
ꢀꢀꢀ
(4)
[0039]
o
(t)
=δ(u
o
x
(t)
+w
o
h
(t
‑
1)
+b
o
)
ꢀꢀꢀ
(5)
[0040]
c
(t)
=f
(t)
⊙
c
(t
‑
1)
+i
(t)
⊙
tanh(u
c
x
(t)
+w
c
h
(t
‑
1)
+b
c
)
ꢀꢀꢀ
(6)
[0041]
h
(t)
=o
(t)
⊙
tanh(c
(t)
)
ꢀꢀꢀ
(7)
[0042]
其中,x
(t)
,i
(t)
,f
(t)
,o
(t)
,c
(t)
及h
(t)
分别表示lstm在时刻t下的输入向量、输入门状态、遗忘门状态、输出门状态、内存单元状态和隐藏层状态。w、u、b分别代表循环网络结构的参数、输入结构的参数及偏差项参数。符号
⊙
表示元素积。可以根据模型的输出得到对应时刻t下每个句子的序列表示向量。δ()表示sigmoid函数。b
i
表示计算输入门状态时的偏差项参数,b
f
表示计算遗忘门状态时的偏差项参数,b
o
表示计算输出门状态时的偏差项参数,b
c
表示计算内存单元状态时的偏差项参数。u
i
表示计算输入门状态时输入向量的权重矩阵,u
f
表示计算遗忘门状态时输入向量的权重矩阵,u
o
表示计算输出门状态时输入向量的权重矩阵,u
c
表示计算内存单元状态时输入向量的权重矩阵。w
i
表示计算输入门状态时隐藏层状态的权重矩阵,w
f
表示计算遗忘门状态时隐藏层状态的权重矩阵,w
o
表示计算输出门状态时隐藏层状态的权重矩阵,w
c
表示计算内存单元状态时隐藏层状态的权重矩阵。
[0043]
为了获取每个词相关的前文和后文的信息,使用双向lstm对序列编码,将前向和后向lstm得到的序列的第i个元素的表示向量拼接,得到最终的表示h
i
。公式如下:
[0044][0045][0046][0047]
其中,表示前向lstm网络输出的第i个元素的隐状态表示,表示前向lstm网络,d
i
表示输入序列中第i个元素的表示,l表示句子中所包含的词语个数。表示后向lstm网络输出的第i个元素的隐状态表示,表示后向lstm网络。
[0048]
步骤5:通过注意力attention机制决定步骤4中每个词语在表示学习过程中的重要性。
[0049]
计算每个词语的注意力得分a
i
:
[0050][0051]
其中,h
i
表示输入序列中第i个元素的表示,h
j
表示输入序列中第j个元素的表示;l为句子中所包含的词语个数;w
a
为attention层的参数矩阵,每个句子表示为一组词序列,
进一步表示为词序列中各个经过连接后的词表示的加权平均,其中的权值即为式11计算出的attention值。
[0052]
具体地,每个句子的表示v为如下形式,其中l为句子中所包含的词语个数:
[0053][0054]
步骤6:将步骤5中的句子表示,通过softmax层计算对应的概率向量。
[0055]
所述概率向量y的每一个元素表示对应句子的特定隐式情感的概率,计算公式如下:
[0056][0057]
其中,y
i
表示句子为第i种隐式情感的概率,w
i
表示第i个权重参数,w
j
表示第j个权重参数;b
i
表示第i个偏差项参数,b
j
表示第j个偏差项参数;k表示概率向量的维度;v
t
表示句子表示v的转置。
[0058]
在得到每个句子对应的概率向量后,使用交叉熵作为损失函数,使用梯度下降的方式对参数进行更新,最小化模型的预测误差。
[0059]
至此,从步骤1到步骤6,得到了给定句子的隐式情感概率,完成了结合外部知识的隐式情感分析。
[0060]
有益效果
[0061]
本发明方法,对比现有技术,具有以下优点:
[0062]
本方法考虑到隐式情感句本身有效信息不足的问题,利用外部常识知识库对隐式情感句的信息进行扩充,丰富了句子的语义表达,可以更好地建模句子表示,提升隐式情感分析性能。
附图说明
[0063]
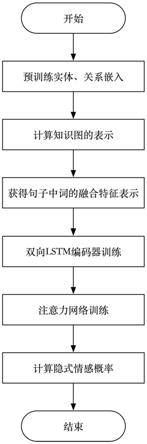
图1为本发明方法的流程图。
具体实施方式
[0064]
下面将结合说明书附图对及实施例对本发明方法作进一步详细说明。
[0065]
如图1所示,本发明包括以下步骤:
[0066]
步骤a:预训练实体、关系嵌入;
[0067]
具体到本实施例中,通过抽取到的常识知识数据集,预训练得到100维的实体嵌入和关系嵌入,具体与发明内容步骤1相同;
[0068]
步骤b:计算知识图的表示;
[0069]
具体到本实施例中,对每一个实体,以该实体为核心,通过常识知识数据集中的三元组,抽取到与该实体直接相连的知识子图,并通过注意力机制计算得到当前实体为核心的知识子图表示,具体与发明内容步骤2相同;
[0070]
步骤c:获得句子中词的融合特征表示;
[0071]
具体到本实施例中,将所需进行隐式情感分析的句子中每个单词的单词特征向量和当前单词为核心的知识子图表示拼接得到融合特征表示,具体与发明内容步骤3相同;
[0072]
步骤d:双向lstm编码器训练;
[0073]
具体到本实施例中,与发明内容步骤4相同;
[0074]
步骤e:注意力网络训练:
[0075]
具体到本实施例中,与发明内容步骤5相同;
[0076]
步骤f:计算隐式情感概率;
[0077]
具体到本实施例中,与发明内容步骤6相同。
[0078]
实施例
[0079]
以隐式情感句“i was asked to attend my best friend’s funeral”为实施例,本实施例将以具体实例对本发明所述的一种结合外部知识的隐式情感分析方法的具体操作步骤进行详细说明;
[0080]
一种结合外部知识的隐式情感分析方法的处理流程如图1所示;从图1可以看出,一种结合外部知识的隐式情感分析方法,包括以下步骤:
[0081]
步骤a:预训练实体、关系嵌入;
[0082]
具体到本实施例中,通过transe模型与训练从conceptnet常识知识库中抽取所有英文实体而构成的常识知识数据集,得到数据集中所有实体的100维嵌入和关系的100维嵌入。
[0083]
步骤b:计算知识图的表示;
[0084]
具体到本实施例“i was asked to attend my best friend’s funeral”中,计算句子中每个单词为核心实体的知识子图表示,以单词funeral为例,抽取出以其为核心实体的知识子图(funeral,synonyms,obsequy),(funeral,causesof,killing),(funeral,causesof,dying),(funeral,effectsof,sadness),通过注意力机制计算funeral的知识子图表示;
[0085]
步骤c:获得句子中词的融合特征表示;
[0086]
获取当前句子中每个词在大规模文本数据集上预训练的word2vec单词特征向量,并与每个词的知识子图表示进行拼接得到词的融合特征表示;
[0087]
步骤d:双向lstm编码器训练;
[0088]
具体到本实施例中,将i was asked to attend my best friend’s funeral输入到双向lstm编码其中,获得融合上下文信息的每个词的表示;
[0089]
步骤e:注意力网络训练:
[0090]
具体到本实施例中,通过注意力机制决定每个词语在表示学习过程中的重要性。计算每个词语的注意力得分,并作为权重计算得句子的最终表示;
[0091]
步骤f:计算隐式情感概率;
[0092]
具体到本实施例中,通过将句子表示输入softmax层计算对应的概率向量,得到句子最有可能所属的隐式情感。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1