基于深度迁移网络的高炉铁水硅含量在线预测方法及系统
文档序号:27825476发布日期:2021-12-07 20:25阅读:189来源:国知局
导航: X技术> 最新专利>计算;推算;计数设备的制造及其应用技术
1.本发明主要涉及高炉炼铁技术领域,特指一种基于深度迁移网络的高炉铁水硅含量在线预测方法及系统。
背景技术:
2.高炉炼铁是钢铁流程中的上游和关键工序,是铁素物质流转换的核心关键单元。炼铁过程是一个连续鼓风、周期性加料和周期性出铁、在高温高压高尘等恶劣环境下发生复杂物理化学反应的生产过程。高炉炉缸内的铁水温度是衡量炉内热状态、高炉炉况和铁水质量的一个重要性能指标。由于高炉冶炼过程的封闭性要求,使得难以直接检测炉缸内部的铁水温度。
3.目前现场主要通过侵入式的热电偶在撇渣器处离线检测铁水温度来反应高炉炉缸内部的铁水温度。但连接撇渣器与炉缸出铁口的铁钩有一定的距离,使得检测到的温度存在一定的热损失无法准确的表征炉缸内的铁水温度。研究表明,铁水从炉缸流向撇渣器的过程中,铁水硅含量的信息不存在丢失,并且铁水硅含量与炉缸内铁水的温度具有较强的正相关关系,因此可以将铁水温度的检测转换为高炉铁水硅含量的预报。铁水硅含量偏低,说明铁水物理热不足,炉缸热储备不够,容易造成炉缸冻结事故。铁水硅含量偏高,有利于去除铁水中的有害元素磷和硫,但是过高的铁水硅含量又会使得生铁变硬变脆,收得率降低且易引起喷溅。目前,高炉现场操作者主要通过人工采样后离线化验的方式获取硅含量值,撇渣器处取铁水样本的过程具有一定的危险性,化验过程需要昂贵的仪器和人工成本,且化验的数据不具有时效性,使得铁水质量信息不能及时反馈,造成高炉铁水质量精细化调控困难。因此,实现铁水硅含量的实时在线预测对评估高炉状态、提升铁水质量、降低高炉能耗和保障高炉顺行具有重要的意义。
4.申请号202010226187.2申请日2020.03.27
5.申请公布号cn111444963a申请公布日2020.07.24
6.cn111444963a一种基于ssa
‑
svr模型的高炉铁水硅含量预测方法
7.该发明公开了一种基于ssa
‑
svr模型的高炉铁水硅含量预测方法,利用奇异谱分析对预处理的原始数据进行降噪处理,再提取样本中的趋势分量、波动分量和噪声分量,然后基于改进的奇异谱分析判决方法去除噪声分量,将趋势分量和波动分量重构为去噪数据集,利用支持向量回归机对高炉铁水硅含量进行在线预测。该方法采取合理的方法能降低数据噪声获得优质的数据集,进而提高模型的预测精度。
8.但该发明只对影响数据集质量的噪声因素加以考虑,且建模的支持向回归机是一个浅层的模型,难以准确地描述物理化学反应复杂、多相多场耦合的大滞后、非线性的高炉冶炼过程。
9.申请号201910163699.6申请日2019.03.05申请公布号cn109935280a申请公布日2016.06.25
10.cn109935280a一种基于集成学习的高炉铁水质量预测系统及方法
11.该发明公开了一种基于集成学习的高炉铁水质量预测系统及方法,通过相关数据处理构建铁水硅含量预测模型的样本集,再利用均方根误差概率加权集成随机权神经网络的多元铁水质量在线预报模型,得到在线预测结果。
12.但该发明建模的均方根误差概率加权集成随机权神经网络的性能对初始化的权值和偏置矩阵十分敏感,追求模型训练快速性而牺牲了通过误差反向传播调节模型的参数进而降低了模型的准确性。
13.申请号201910304149.1申请日2019.04.16
14.申请公布号cn110097929a申请公布日2019.08.06
15.cn110097929a一种高炉铁水硅含量在线预测方法
16.该发明提出了一种高炉铁水硅含量在线预测方法,通过分析高炉冶炼过程硅含量的迁移原理确定影响硅含量的过程变量,再采用皮尔森相关性分析确定模型的变量的滞后时间并进行样本输入输出时间配准。采用核极限学习机对下一时刻的铁水硅含量进行预测,利用滑动窗更新的方法对训练集数据进行在线更新,引入遗传算法对核极限学习机模型的关键参数进行优化。
17.该专利使用的核极限学习机是一种单隐含层的前向神经网络,通过随机的方式给输入节点和隐含节点赋予权值从而保证模型的快速性,但输出权值是在输入权值和隐层节点阈值的基础上求得的,输出权值是非最优的使得模型的准确度得不到保证。
18.综上所述,现有的高炉铁水硅含量在线预测模型大都是浅层网络模型,其表达能力和泛化能力有限,难以为复杂的高炉冶炼过程提供深层次的非线性描述,在非平稳炉况时模型的性能波动较大。且这些模型都是监督学习模式,对铁水硅含量标签数据的依赖较强,硅含量标签以人工采样、离线化验的方式获取使得采集大量带标签的样本是困难的。
技术实现要素:
19.本发明提供的基于深度迁移网络的高炉铁水硅含量在线预测方法及系统,解决了现有高炉铁水硅含量在线预测精度低的技术问题。
20.为解决上述技术问题,本发明提出的基于深度迁移网络的高炉铁水硅含量在线预测方法包括:
21.利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获得深度去噪自编码机网络;
22.在深度去噪自编码机网络前端嵌入动态注意力机制模块,后端加入一层回归层,获得基于动态注意力机制模块的深度网络,其中动态注意力机制模块用于描述输入样本的过程变量与预测目标之间的动态关系;
23.基于深度网络,获得铁水硅含量在线预报模型,并基于铁水硅含量在线预报模型对高炉铁水硅含量进行在线预测。
24.进一步地,在深度去噪自编码机网络前端嵌入动态注意力机制模块,后端加入一层回归层,获得基于动态注意力机制模块的深度网络包括:
25.基于多个全连接层构建注意力得分模块,且注意力得分模块的计算公式具体为:
26.ω
fe
=f
(m)
(w
(m)
(
…
f
(2)
(w
(2)
(f
(1)
(w
(1)
x
fe
+b
(1)
)+b
(2)
))...+b
(m)
)),
27.其中ω
fe
代表注意力得分模块计算的得分矩阵,x
fe
代表输入向量,f
(m)
为第m层神
经元的非线性激活函数,w
(m)
和b
(m)
分别代表第m层神经元与前一层神经元之间的权值矩阵跟偏置矩阵;
28.将注意力得分模块计算的得分矩阵ω
fe
与输入变量x
fe
做哈达玛积操作,并将输入变量x
fe
与得分矩阵ω
fe
对应位置元素相乘的矢量矩阵作为深度去噪自编码机网络的输入,从而获得基于动态注意力机制模块的深度网络,且基于动态注意力机制模块的深度网络的计算公式具体为:
[0029][0030]
其中为基于动态注意力机制模块的深度网络的输出,f
(n+1)
为第n+1层神经元的非线性激活函数,w
(n+1)
和b
(n+1)
分别代表第n+1层神经元与前一层神经元之间的权值矩阵跟偏置矩阵,ω
fe
⊙
x
fe
代表得分矩阵ω
fe
与输入变量x
fe
做哈达玛积操作。
[0031]
进一步地,获得基于动态注意力机制模块的深度网络之后还包括:
[0032]
利用带标签的铁水温度数据微调深度网络的结构参数。
[0033]
进一步地,基于深度网络,获得铁水硅含量在线预报模型包括:
[0034]
将训练好的深度网络迁移到铁水硅含量在线预报模型,获得铁水硅含量在线预报源模型;
[0035]
在铁水硅含量在线预报源模型中的深度去噪自编码机网络的输入层拼接对硅含量值有影响的过程变量,并利用带标签的铁水硅含量数据重新微调网络结构,获得铁水硅含量在线预报模型。
[0036]
进一步地,利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获得深度去噪自编码机网络包括:
[0037]
利用铁水温度数据无监督的预训练第一个去噪自编码机网络;
[0038]
采用误差反向传播算法最小化误差函数并保存训练好的隐含层的权值和偏置矩阵,将第一个去噪自编码机的隐含层输出作为第二个去噪自动编码机的输入,利用误差反向传播算法继续优化网络权值和偏置矩阵,依此循环,直到预设个数的去噪自编码机训练完成;
[0039]
提取预设个数的训练好的去噪自编码机的隐含层权值和偏置矩阵,堆叠成一个深度网络,从而获得深度去噪自编码机网络。
[0040]
进一步地,利用铁水温度数据无监督的预训练第一个去噪自编码机网络之前包括:
[0041]
采集高炉历史数据,并对高炉历史数据进行预处理,预处理包括输入输出样本时间配准、异常数据剔除、归一化处理和变量相关性分析。
[0042]
本发明提供的基于深度迁移网络的高炉铁水硅含量在线预测系统包括:
[0043]
存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现本发明提供的基于深度迁移网络的高炉铁水硅含量在线预测方法的步骤。
[0044]
与现有技术相比,本发明的优点在于:
[0045]
本发明提供的基于深度迁移网络的高炉铁水硅含量在线预测方法及系统,通过利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获
得深度去噪自编码机网络,在深度去噪自编码机网络前端嵌入动态注意力机制模块,获得基于动态注意力机制模块的深度网络,其中动态注意力机制模块用于描述输入样本的过程变量与预测目标之间的动态关系以及基于动态注意力机制模块的深度网络,将基于铁水温度数据训练好的铁水温度预报模型迁移到铁水硅含量预测任务上,并利用带标签的铁水硅含量数据重新微调网络结构,获得铁水硅含量在线预报模型,并基于铁水硅含量在线预报模型对高炉铁水硅含量进行在线预测,解决了现有高炉铁水硅含量在线预测精度低的技术问题,通过在深度去噪自编码机网络前端嵌入动态注意力机制模块,能实时的为每个输入样本的过程变量计算动态的注意力分数,使得模型能动态的为每个样本中有效的和有价值的过程变量分配更多的注意力,且迁移机制的引入,能使得铁水硅含量预测模型在训练的过程中减少对标签数据的依赖,进而更高效并精准地在线预测铁水硅含量。
附图说明
[0046]
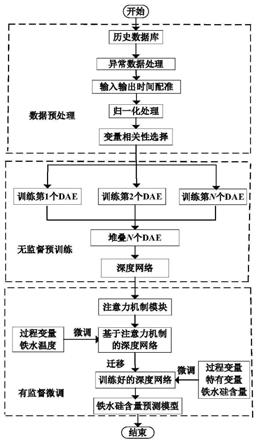
图1为本发明实施例一的基于深度迁移网络的高炉铁水硅含量在线预测方法的流程图;
[0047]
图2为本发明实施例二的去噪自动编码机结构图;
[0048]
图3为本发明实施例二的堆叠去噪自编码机示意图;
[0049]
图4为本发明实施例二的动态注意力机制模块;
[0050]
图5为本发明实施例二的铁水硅含量与铁水温度的对应关系;
[0051]
图6为本发明实施例二的基于深度迁移学习的铁水硅含量在线预报模型;
[0052]
图7为本发明实施例三的基于深度迁移网络的高炉铁水硅含量在线预测方法的流程图;
[0053]
图8为本发明实施例三的基于深度迁移学习的铁水硅含量预测结果;
[0054]
图9为本发明的基于深度迁移网络的高炉铁水硅含量在线预测系统的结构框图。
[0055]
附图标记:
[0056]
10、存储器;20、处理器。
具体实施方式
[0057]
为了便于理解本发明,下文将结合说明书附图和较佳的实施例对本发明作更全面、细致地描述,但本发明的保护范围并不限于以下具体的实施例。
[0058]
以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
[0059]
实施例一
[0060]
参照图1,本发明实施例一提供的基于深度迁移网络的高炉铁水硅含量在线预测方法,包括:
[0061]
步骤s101,利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获得深度去噪自编码机网络;
[0062]
步骤s102,在深度去噪自编码机网络前端嵌入动态注意力机制模块,后端加入一层回归层,获得基于动态注意力机制模块的深度网络,其中动态注意力机制模块用于描述输入样本的过程变量与预测目标之间的动态关系;
[0063]
步骤s103,基于深度网络,获得铁水硅含量在线预报模型,并基于铁水硅含量在线预报模型对高炉铁水硅含量进行在线预测。
[0064]
本发明实施例提供的基于深度迁移网络的高炉铁水硅含量在线预测方法,通过利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获得深度去噪自编码机网络,在深度去噪自编码机网络前端嵌入动态注意力机制模块,后端加入一层回归层,获得基于动态注意力机制模块的深度网络,其中动态注意力机制模块用于描述输入样本的过程变量与预测目标之间的动态关系以及基于动态注意力机制模块的深度网络,获得铁水硅含量在线预报模型,并基于铁水硅含量在线预报模型对高炉铁水硅含量进行在线预测,解决了现有高炉铁水硅含量在线预测精度低的技术问题,通过在深度去噪自编码机网络前端嵌入动态注意力机制模块,能实时的为每个输入样本的过程变量计算动态的注意力分数,使得模型能动态的为每个样本中有效的和有价值的过程变量分配更多的注意力,且迁移机制的引入,能使得铁水硅含量预测模型在训练的过程中减少对标签数据的依赖,进而更高效并精准地在线预测铁水硅含量。
[0065]
实施例二
[0066]
本发明实施例二提供的基于深度迁移网络的高炉铁水硅含量在线预测方法,包括:
[0067]
步骤s201,采集高炉历史数据,并对高炉历史数据进行预处理,预处理包括输入输出样本时间配准、异常数据剔除、归一化处理和变量相关性分析。
[0068]
具体地,高炉的历史数据库中保存了大量的历史数据,但在采集的过程中由于设备故障或者人工操作失误等多种原因造成数据不能真实准确的反应炉况,因此需要对数据进行预处理来消除上述问题和提高数据的质量以构建优质的数据集。具体步骤如下:
[0069]
(1)输入输出样本时间配准
[0070]
考虑到撇渣器处人工取样的铁水需要花费1h左右时间化验铁水硅含量百分比值,因此将数据库中记录的铁水硅含量数据往前推一个小时与传感器检测的过程变量在时间维度上进行配准。
[0071]
(2)异常数据处理
[0072]
当高炉出现受高温高压、故障等以及高炉减风、休风等非正常生产的影响时,采集到的数据可能会偏离正常范围,另外,一些需要手工录入计算机中的数据也会由于人为失误造成数据异常,对于异常数据使用箱线图进行剔除,对于休风以及设备故障等原因造成的缺失数据直接删除。为了构建完备的输输出样本集合,把经过数据预处理后的铁水温度数据集按每分钟取均值处理,铁水硅含量的数据按每小时取均值处理。
[0073]
(3)归一化处理
[0074]
数据集中样本的不同过程变量量纲存在较大的差异,因此在建模前需要对数据进行归一化处理进而消除不同量纲对模型的影响,通过如下公式标准化:
[0075][0076]
其中是第t个数据样本中的第d
x
个过程变量归一化处理后的结果,为第t个数据样本中第d
x
个过程变量的值,和分别为第d
x
个过程变量在所有的数据样本中的最大值和最小值。
[0077]
(4)变量相关性分析
[0078]
高炉历史数据库中记录了大量能反应铁水温度和硅含量的传感器检测数据,根据高炉的冶炼工艺机理、已安装的传感器检测设备和现场专家经验确定了对铁水温度和硅含量有影响的过程变量。为了定量的描述挑选的过程变量与铁水温度和铁水硅含量之间的相关性,采用最大互信息系数(mic,maximal information coefficient)来计算两个变量之间的相关性,mic定义如下:
[0079][0080]
其中p(x)为数据点落在x列的概率,p(y)为数据点落在y行的概率,p(x,y)为变量x与变量y联合概率,b为变量最优推荐值为数据量的0.6次方。
[0081]
步骤s202,利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获得深度去噪自编码机网络。
[0082]
具体地,深度网络通过从低层到高层将数据逐层抽象,进而自学习到原始数据的本质特征进而适应于各种复杂的任务。去噪自编码机是一种堆叠深度网络的基本单元,是一种典型的三层无监督神经网络,由输入层、隐含层和输出层组成,结构如图2所示。模型训练的目标是使得输出尽可能地复现输入,为了防止模型简单的输出复制输入,在训练的过程,隐含层的神经元数量一般小于输入层神经元数量,迫使隐含层神经元能学习到输入的压缩抽象特征表示。去噪自编码机为了提取更鲁棒的抽象特征表示进而更出色的完成任务,在输入样本中加入了随机噪声进行干扰。
[0083]
假设铁水温度预测模型的输入向量为其中其中d
x
是样本的维度,加入随机噪声污染后的第t个向量为对第t个污染后的输入向量进行编码可以得到隐含层特征编码函数f
θ
如下:
[0084][0085]
其中,f是隐含层的激活函数,w是大小为d
h
×
d
x
的权值矩阵,是隐含层的偏置向量。隐含层特征h
t
通过解码函数映射到重构特征解码函数g
θ
如下
[0086][0087]
其中w
′
和w互为转置矩阵,是输出层的偏置向量。去噪自编码机通过梯度下降算法不断最小化目标函数来反复调整参数组θ=(w,w
′
,b,b
′
),其目标函数为:
[0088][0089]
考虑到单个去噪自动编码机隐含层学习到的是原始数据的浅层特征,为了得到更加抽象和鲁棒的特征表示,可以通过堆叠多个去噪自动编码机来搭建深度网络,有多个非线性隐藏层的深度网络可以学习更复杂的输入和输出之间的关系,从而在高层得到更具抽象和鲁棒的特征表示。堆叠多个去噪自编码机过程如图3所示,当第一个去噪自编码训练完成后,其隐含层的特征表示其中经过随机污染后作为第二个去噪自编码机的输入,通过编码和解码过程得到网络的输出矩阵其中则第二个去噪自编码机的误差函数为
[0090][0091]
通过梯度下降算法最小化误差函数训练模型的参数,重复这个过程直到第n个去噪自编码机训练完成。第n个去噪自编码机的隐层输出就是深度网络自学习到的高级的抽象的和鲁棒的特征表示。无监督的预训练过程完成后,将n个训练好的去噪自编码机的隐含层权值和偏置矩阵取出来,堆叠成一个深度去噪自编码机。
[0092]
步骤s203,在深度去噪自编码机网络前端嵌入动态注意力机制模块,后端加入一层回归层,获得基于动态注意力机制模块的深度网络,并利用带标签的铁水温度数据微调深度网络的结构参数。
[0093]
具体地,预训练好的深度网络用带标签的铁水温度样本最小化损失函数,微调整个网络结构来提高铁水温度在线预测的性能,有监督微调的目标如式(7)所示:
[0094][0095]
其中为铁水温度真实值,为模型的预测值,f
(n+1)
为堆叠去噪自编码机第(n+1)层神经元的非线性激活函数,w
(n+1)
和b
(n+1)
分别为第(n+1)层神经元与前一层神经元之间的权值矩阵跟偏置矩阵。由式(7)可知,堆叠去噪自编码机形成的深度网络在使用带标签样本微调整个网络的时候对输入样本的每一维过程变量都给予了相同的关注度,使得模型前向传播的时候无差别地提取抽象特征表示。在铁水温度或者铁水硅含量在线预测任务中,为了描述不同过程变量对铁水温度或者铁水硅含量的影响程度,在工程应用技术中一般是采取先降维后建模的思路,通过变量相关性分析确定主要过程变量,忽略次要过程变量对铁水硅含量的影响。但是在高炉冶炼过程中,输入样本的主要过程变量跟铁水温度和者铁水硅含量相关系数是不一样的,并且随着入炉矿源品质的波动和冶炼条件的改变等原因,影响铁水硅含量的过程变量的重要性随时间呈现出一种动态变化的趋势。显然,传统的去
噪自编码机的静态建模思路无法准确地描述高炉冶炼过程的动态特性,且无差别地提取抽象特征无法准确地表征输入跟输出之间的非线性关系。因此,本文提出了一种动态的注意力机制模块,能实时的为每个输入样本的过程变量计算动态的注意力分数,使得模型能动态的为每个样本中有效的和有价值的过程变量分配更多的注意力,进而更高效地完成铁水温度或者铁水硅含量的预测任务。
[0096]
动态注意力机制模块由注意力得分模块和注意力聚焦模块两部分构成,其基本结构如图4所示。注意力得分模块由多个全连接层构成,隐含层和输出层神经元中非线性激活函数的存在使得网络能模拟高炉冶炼过程的复杂非线性特点。注意力聚焦模块由注意力得分模块计算的输入样本各过程变量的注意力分数与之对应的输入样本各过程变量相乘进而描述样本各过程变量与铁水硅含量之间的动态关系。动态注意力机制模块的数学表达过程描述如下,假设模块的输入向量为其中经过注意力得分模块计算后输出记为ω
fe
:
[0097]
ω
fe
=f
(m)
(w
(m)
(...f
(2)
(w
(2)
(f
(1)
(w
(1)
x
fe
+b
(1)
)+b
(2)
))...+b
(m)
))
ꢀꢀ
(8)
[0098]
其中f
(m)
为第m层神经元的非线性激活函数,w
(m)
和b
(m)
分别为第m层神经元与前一层神经元之间的权值矩阵跟偏置矩阵。将ω
fe
在每个样本的各维度上的过程变量上展开可得:
[0099][0100]
为了描述样本的过程变量在不同时刻与铁水硅含量之间的动态关系,将注意力得分模块计算得分矩阵ω
fe
与输入变量x
fe
做哈达玛积(hadamard)操作:
[0101][0102]
其中,输入样本x
fe
与得分矩阵ω
fe
对应位置元素相乘的矢量矩阵作为预训练好的堆叠去噪自编码机的输入,基于动态注意力机制模块的深度去噪自编码机网络如图4所示,整个网络的输出可表示:
[0103][0104]
则使用带标签的硅含量样本有监督微调基于动态注意力机制的深度网络时的损失函数为:
[0105][0106]
从式(12)可以看出,网络在训练的过程中考虑了每个输入样本的过程变量与预测目标之间的动态关系,能有区别的为每个样本提取目标相关的抽象特征表示来描述高炉冶炼过程进而提高温度在线预报模型的性能。
[0107]
步骤s204,将训练好的深度网络迁移到铁水硅含量在线预报模型,获得铁水硅含量在线预报源模型。
[0108]
步骤s205,在铁水硅含量在线预报源模型中的深度去噪自编码机网络的输入层拼接对硅含量值有影响的过程变量,获得铁水硅含量在线预报模型。
[0109]
具体地,本实施例采集高炉现场数据,绘制热电偶检测的铁水温度数据和硅含量化验值特征曲线如图5所示,可知,铁水温度跟硅含量之间存在较强的相关性,建模时加入铁水温度数据对提升硅含量在线预测模型的精度有一定的帮助。而高炉现场主要采用快速热电偶来检测高炉撇渣器处的铁水温度,一次出铁周期只能获取有限个温度数据,导致铁水温度数据的质量和数量得不到保证。在前期工作中,我们原创性的研发了铁水测温仪和高炉出铁口铁水温度红外视觉检测系统,能实时在线地检测高炉出铁口铁水温度,这为建立硅含量在线预报模型提供了分钟级独有的数据来源。
[0110]
考虑到红外视觉铁水测温系统和过程变量采样频率的相对快速性,铁水温度跟铁水硅含量之间的强相关系,为了充分利用铁水温度数据中的信息,通过构建分钟级优质数据集训练铁水温度在线预测模型,再将模型上学习到的知识迁移到铁水硅含量在线预测任务上,降低模型在实际硅含量预测任务上对标签数据的依赖。本实施例基于深度迁移学习的铁水硅含量在线预报模型结构如图6所示,主要步骤包括:
[0111]
(1)训练铁水温度在线预报源模型,利用分钟级铁水温度数据无监督地预训练去噪自编码机模型,并将训练好的n个去噪自编码机堆叠成一个深度网络;在深度网络的前端嵌入动态注意力机制模块,在网络的后端堆叠一层回归层,并利用分钟级铁水温度数据有监督地最小化误差函数进而调整网络结构;
[0112]
(2)重用铁水温度在线预报源模型,迁移分钟级铁水温度数据训练好的基于动态注意力机制的深度网络,且为进一步提高硅含量预测模型的性能,在堆叠去噪自编码机构建的深度网络的输入层拼接了对硅含量值有影响的特有过程变量。
[0113]
(3)微调铁水硅含量在线预报模型,利用带标签的铁水硅含量数据有监督地重新微调由铁水温度数据预训练好的深度网络,进而更好的适应铁水硅含量在线预报任务。
[0114]
由图6可以看出,迁移后的铁水硅含量在线预报模型与迁移前的网络模型结构基本相同,区别在于迁移前的网络的训练数据是分钟级别的,迁移后的网络的训练数据是小时级别的,且在迁移后的网络(即铁水硅含量在线预报源模型)中的深度去噪自编码机网络的输入层拼接对硅含量值有影响的过程变量本实施例拼接的特有的过程变量共有12个,具体为:
其中q
‑1x
t
=x
t
‑1、q
‑2x
t
=x
t
‑2和q
‑3x
t
=x
t
‑3分别表示在第t
‑
1,t
‑
2,t
‑
3时刻过程变量x的取值,这部分特有的过程变量主要考虑的是高炉冶炼过程中大惯性和时序性对铁水硅含量的影响,并利用铁水硅含量标签数据微调整个网络参数,进而完成硅含量预报模型的训练,从而最终获得高精度的铁水硅含量在线预报模型。
[0115]
需要说明的是,为了让铁水温度预测模型学习到的参数更好的适配铁水硅含量在线预测任务,动态注意力机制模块中输入是能反应铁水温度和硅含量的共同过程变量,唯一的区别是铁水温度模型数据是分钟级别采样的而铁水硅含量模型的数据是小时级别采样的。利用训练好的深度迁移网络能实现对铁水硅含量的实时在线预测,不仅降低硅含量预测模型训练过程中对标签数据的依赖,又在一定程度上提高了预测模型的精度。
[0116]
本发明的关键点包括:
[0117]
(1)提出了基于深度迁移网络的高炉铁水硅含量在线预测方法,能实现对高炉铁水硅含量在线实时预测,为高炉操作者及时提供冶炼过程的反馈信息,保障炉况的顺行和铁水的质量;
[0118]
(2)采用了表达能力和泛化能力较强的深度网络模型来为复杂的高炉冶炼过程提供深层次的非线性描述;
[0119]
(3)提出了一种新颖的动态注意力机制模块来捕获样本的各过程变量与铁水硅含量之间的动态的和非线性的关系,使得后端的深度去噪自编码机网络能有区别地为每个样本提取目标相关的抽象特征表示;
[0120]
(4)迁移了基于分钟级铁水温度数据训练的深度模型,利用小时级的硅含量标签数据微调网络结构,降低了铁水硅含量预测模型对硅含量标签数据的依赖和提高了预测模型的性能;
[0121]
(5)通过发明的基于深度迁移网络的高炉铁水硅含量在线预报方法,实现了对铁水硅含量在线实时预测。
[0122]
本发明实施例提供的基于深度迁移网络的高炉铁水硅含量在线预测方法,通过利用铁水温度数据无监督的训练去噪自编码机网络,并堆叠多个去噪自编码机网络,从而获得深度去噪自编码机网络,在深度去噪自编码机网络前端嵌入动态注意力机制模块,后端加入一层回归层,获得基于动态注意力机制模块的深度网络,其中动态注意力机制模块用于描述输入样本的过程变量与铁水硅含量之间的动态关系以及基于深度网络,获得铁水硅含量在线预报模型,并基于铁水硅含量在线预报模型对高炉铁水硅含量进行在线预测,解决了现有高炉铁水硅含量在线预测精度低的技术问题,通过在深度去噪自编码机网络前端嵌入动态注意力机制模块,能实时的为每个输入样本的过程变量计算动态的注意力分数,使得模型能动态的为每个样本中有效的和有价值的过程变量分配更多的注意力,且迁移机制的引入,能使得铁水硅含量预测模型在训练的过程中减少对标签数据的依赖,进而更高效并精准地在线预测铁水硅含量。
[0123]
具体地,本发明实施例以高炉冶炼过程中的铁水硅含量为研究对象,提出了基于深度迁移网络的高炉铁水硅含量在线预测方法。为了克服浅层网络难以为复杂的高炉冶炼过程提供深层次的非线性描述,采用了堆叠多个去噪自编码机形成的深度网络描述高炉冶炼过程。为了克服传统深度无区别地重构输入样本的每一维过程变量,进而导致逐层提取
抽象特征表示无法准确地表征过程变量跟输出之间的动态关系,提出了一种动态的注意力机制模块,能实时的为每个输入样本的过程变量计算动态的注意力分数,使得模型能动态的为每个样本中有效的和有价值的过程变量分配更多的注意力,进而更高效地完成铁水硅含量的预测任务。为了减少模型对硅含量标签数据的依赖,考虑铁水温度跟铁水硅含量之间的强相关系和反应铁水温度和硅含量的过程变量的相对一致性,利用了前期工作中研发的铁水温度红外视觉检测系统采集的出铁口实时温度数据训练基于动态注意力机制的深度网络模型,通过迁移学习从已训练的铁水温度在线预测任务中学习的知识来提升铁水硅含量在线预测模型的性能。本发明实施例提出了一种轻量化的动态注意力机制模块嵌入在深度去噪自编码机网络的前端,使得深度网络能有差别的动态提取与目标相关的过程变量的抽象特征,且实时地预测铁水硅含量能为现场操作者提供冶炼过程的及时反馈信息,为实现高炉精细化调控、保障高炉的顺行和稳定铁水的质量提供合理的操作指导与决策支持。
[0124]
实施例三
[0125]
参照图7,本发明实施例提供的基于深度迁移网络的高炉铁水硅含量在线预测方法,以某炼铁厂中的2650m3大型高炉进行验证,具体包括如下步骤:
[0126]
1)数据预处理。将高炉检测装置上的采集来的数据进行相关处理提高数据的质量,本实施例获取了高炉历史数据库中2020年8月1号到2020年12月17号的数据,其中过程变量有1160141组,铁水温度数据有172352组,硅含量数据有7282组,具体包括输入输出样本时间配准、异常数据处理、归一化处理和基于最大互信息系数相关特征选择,经过处理后铁水温度数据有111041组,铁水硅含量数据有3117组,选择后的特征有24个,即:富氧率,透气性指数,co,co2,标准风速,富氧流量,冷风流量,鼓风动能,炉腹煤气量,炉腹煤气指数,顶压,富氧压力,冷风压力,全压差,热风压力,实际风速,冷风温度,热风温度,顶温,顶温下降管,阻力系数,鼓风湿度,本小时实际喷煤量,上小时实际喷煤量。
[0127]
2)基于堆叠去噪自编码机的深度网络无监督预训练。经过步骤1)选取的能反应铁水温度和硅含量的24个过程变量作为深度模型的输入,堆叠了4个去噪自编码机(24
‑
160
‑
120
‑
80
‑
40
‑
1)搭建深度网络,其结构分别设置为24
‑
160
‑
24(输入层
‑
隐含层
‑
输出层),160
‑
120
‑
160,120
‑
80
‑
120和80
‑
40
‑
80,激活函数都设置为relu函数,加性高斯噪声的系数设为0.01,利用铁水温度数据无监督的预训练深度网络获得最佳的网络结构。
[0128]
3)基于动态注意力机制的深度网络有监督微调。为了动态的描述高炉冶炼过程,在无监督预训练好的深度网络前端嵌入动态注意力机制模块,动态注意力机制模块的全连接层层数设置为3,各层神经元个数分别设置为256,128,24,前面两个隐含层激活函数设置为relu函数,第三个隐含层激活函数设置为sigmoid函数,并在深度网络的最后一层加一层回归层,利用铁水温度数据微调整个网络的结构参数。
[0129]
4)迁移利用铁水温度数据训练好的深度网络到铁水硅含量任务上,并在铁水硅含量预测模型的深度网络输入层拼接了对铁水硅含量有影响的特有12个特有的过程变量,即:即:即:其中q
‑1x
t
=x
t
‑1、q
‑2x
t
=x
t
‑2和q
‑3x
t
=x
t
‑3分别表示在第t
‑
1,t
‑
2,t
‑
3时刻过程变量x的取值,这部分特有的过程变量主要考虑的是高炉冶炼过程中大惯性和时序性对铁水硅含量的影响,并利用铁水硅含量标签数据微调整个网络参数,进而完成硅含量预报模型的训练。
[0130]
5)111041组铁水温度数据用来建立基于动态注意力机制的深度网络预测模型,其中10万组数据用于训练模型,11041组数据用于测试模型。3117组铁水硅含量数据用于建立基于深度迁移网络的预测模型,其中2837组数据用于模型训练,280组数据用于模型测试。用训练好的深度迁移网络对铁水硅含量进行预测,模型性能如表1所示。从表1中可以看出本专利提出的基于深度迁移网络的均方根误差为0.0649,均方误差为0.0509,命中率为90%,从图8可以看出,模型能以较高的准确率命中分布在0.30%~0.60%的硅含量,说明了本专利所提方法的有效性和可行性,而对于少数波动范围大的样本预测值则不能及时准确的跟踪检测值,这是因为模型训练时超过0.6%或者低于0.3%数据样本占比较少,在模型的训练过程中难以挖掘到少样本数据中的隐藏信息,进而使得模型对该类样本预测性能欠佳。考虑到某炼铁厂现场入炉矿源的品质和铁水质量的要求,铁水硅含量化验值大部分时间稳定在0.30~0.60%范围内,因此对分布在[0.3%,0.6%]范围内硅含量样本的高预测准确率对现场操作也有较高的指导意义。
[0131]
表1模型预测性能指标
[0132][0133]
参照图9,本发明实施例提出的基于深度迁移网络的高炉铁水硅含量在线预测系统,包括:
[0134]
存储器10、处理器20以及存储在存储器10上并可在处理器20上运行的计算机程序,其中,处理器20执行计算机程序时实现本实施例提出的基于深度迁移网络的高炉铁水硅含量在线预测方法的步骤。
[0135]
本实施例的基于深度迁移网络的高炉铁水硅含量在线预测系统的具体工作过程和工作原理可参照本实施例中的基于深度迁移网络的高炉铁水硅含量在线预测方法的工作过程和工作原理。
[0136]
以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 该技术已申请专利。仅供学习研究,如用于商业用途,请联系技术所有人。
- 技术研发人员:蒋朝辉;蒋珂;谢永芳;潘冬;桂卫华
- 技术所有人:中南大学
- 我是此专利的发明人
- 该领域下的技术专家
- 如您需求助技术专家,请点此查看客服电话进行咨询。
- 1、李老师:1.计算力学 2.无损检测
- 2、毕老师:机构动力学与控制
- 3、袁老师:1.计算机视觉 2.无线网络及物联网
- 4、王老师:1.计算机网络安全 2.计算机仿真技术
- 5、王老师:1.网络安全;物联网安全 、大数据安全 2.安全态势感知、舆情分析和控制 3.区块链及应用
- 如您是高校老师,可以点此联系我们加入专家库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
精彩留言,会给你点赞!
专利分类正在加载中....