一种基于BTM主题模型和Doc2vec的文本相似度计算方法
一种基于btm主题模型和doc2vec的文本相似度计算方法
技术领域
1.本发明属于自然语言处理技术领域,具体涉及一种文本相似度计算方法。
背景技术:
2.在自然语言处理、数据挖掘等领域,文本之间的相似度是一个重要的研究内容,随着大数据时代的到来,信息增长迅速,造成了大量数据冗余的问题,通过准确计算数据之间的相似度,来对冗余数据进行删除,可以有效解决这一问题。主题模型由于可以深度发掘文本之间的语义信息,对各文本的语义信息以主题的形式进行总结表述,可通过两本文之间的代表性的主题内容进行数据比对,因而较为广泛用于文本相似度的计算,传统的主题模型主要是通过计算词语在文档中的重要程度来进行模型建立,当语料较短时难以计算词语的重要性,导致数据稀疏。针对这一缺陷,btm主题模型应运而生。
3.自2003年词向量提出以来,深度学习的方法广泛应用于文本相似度计算之中,doc2vec模型作为一种无监督的训练模型,不需要依赖于标签数据信息就可以计算文本间的语义相似度。但由于无监督的深度学习模型需要大规模的数据进行训练,并且无法有效利用标签数据的信息,存在训练时间过长,检测准确率低等问题。
4.因此本发明使用btm主题模型与doc2vec模型相结合,将主题信息引入无监督训练模型之中,btm模型提取本文中的主题信息,与doc2vec模型处理得到的词向量信息相结合,更加准确地表征出数据内涵,最后使用余弦相似度计算公式,计算得到文本相似度值。
技术实现要素:
5.为了克服现有技术的不足,本发明提供了一种基于btm主题模型和doc2vec的文本相似度计算方法,首先进行数据预处理与基础模型训练,使用大规模语料库对基础doc2vec模型进行训练,对待检测的文本数据,进行分词处理,用于下一阶段doc2vec模型的数据输入;其次进行模型的数据训练处理,使用分词后的数据对doc2vec模型进行训练,得到文本向量集合,同时使用btm主题模型对待检测文本数据进行训练,得到文本主题集合。最后进行数据相似度的计算,在文本向量集合基础上,结合文本主题信息,得到主题向量集合,将文本向量与主题向量进行融合得到表征数据的距离向量,针对距离向量使用余弦相似度计算公式计算得到数据相似度值。本发明提出的检测模型提升了计算效率与文本之间相似度计算的准确度。
6.本发明解决其技术问题所采用的技术方案包括如下步骤:
7.步骤1:模型定义与数据预处理;
8.首先对如表1所示的基础doc2vec模型参数进行定义,再使用语料库对doc2vec基础模型进行训练;
9.对于待检测的文本数据d{d1,d2,...,d
n
},使用分词工具,对待检测文本数据进行分词处理,处理后的数据项用于进行下一阶段的模型训练处理;
10.表1doc2vec基础模型参数
[0011][0012]
步骤2:模型训练;
[0013]
使用处理后的数据项对经过语料库训练后的doc2vec模型再次进行训练,得到数据的文本向量集合{v(d1),v(d2),...,v(d
n
)};
[0014]
构建btm主题模型,使用btm主题模型对待检测文本数据进行文本主题信息的检测,得到文本主题数据集合{t1,t2,...,t
n
};
[0015]
步骤3:相似度计算;
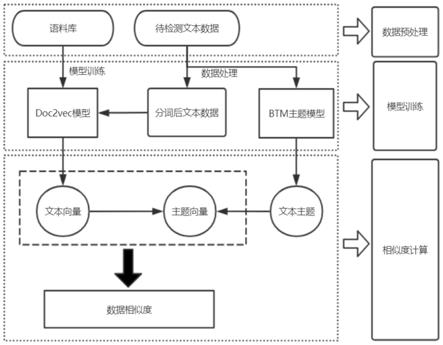
[0016]
在文本向量集合的基础上,结合文本主题数据集合进行向量数据筛选,得到主题向量集合,随后将主题向量信息与文本向量信息结合,计算得到文本相似度,相似度计算的具体过程如下:
[0017]
步骤3
‑
1:对每个文本主题中的高频词进行权重标注,将高频词出现的概率设定为主题权重,并且与文本向量集合中对应该文本主题的文本向量进行结合,得到主题向量集合,计算公式如下所示:
[0018][0019]
其中,v(d
i
)表示该文本主题的向量表示,表示主题权重,h为主题向量总数,m为主题向量序号;
[0020]
步骤3
‑
2:使用式(2)将文本向量与主题向量相结合,用两个向量之间的的距离来表征数据项的特征。
[0021]
dis(v(d
i
),v(t
i
))=|v(d
i
)
‑
v(t
i
)|
ꢀꢀ
(2)
[0022]
步骤3
‑
3:针对两个数据项的文本向量与主题向量,使用余弦相似度计算公式,计算公式如式(3):
[0023][0024]
得到两个文本数据项之间的相似度值。
[0025]
优选地,所述a=200,b=3,c=200,d=1,e=4。
[0026]
优选地,所述分词工具为jieba分词工具。
[0027]
本发明的有益效果如下:
[0028]
本发明将文本主题模型与深度学习网络模型相结合,doc2vec模型采用无监督学习的模式,不需要人工标注就可对语料数据进行训练学习,大大减少了传统人工标记工作方式的工作量,同时结合btm主题模型,通过计算出文本的主题信息,将主题信息与文本向量进行结合,得到表征数据内涵的距离向量,针对距离向量使用余弦相似度计算公式进行计算得到文本相似度值,与直接使用两种算法进行重复数据检测相比,本发明提出的检测
模型提升了计算效率与文本之间相似度计算的准确度。
附图说明
[0029]
图1为本发明进行文本相似度计算的架构图1。
[0030]
图2为本发明btm主题模型构建原理图。
[0031]
图3为本发明doc2vec模型构建原理图。
具体实施方式
[0032]
下面结合附图和实施例对本发明进一步说明。
[0033]
如图1所示,一种基于btm主题模型和doc2vec的文本相似度计算方法,包括如下步骤:
[0034]
步骤1:模型定义与数据预处理;
[0035]
首先对如表1所示的基础doc2vec模型参数进行定义,再使用大规模语料库对doc2vec基础模型进行训练;
[0036]
对于待检测的文本数据d{d1,d2,...,d
n
},使用当前应用最为广泛的jieba分词工具,对待检测文本数据进行分词处理,处理后的数据项用于进行下一阶段的模型训练处理;
[0037]
表1 doc2vec基础模型参数
[0038][0039]
步骤2:模型训练;
[0040]
使用处理后的数据项对经过语料库训练后的doc2vec模型再次进行训练,得到数据的文本向量集合{v(d1),v(d2),...,v(d
n
)};
[0041]
构建btm主题模型,使用btm主题模型对待检测文本数据进行文本主题信息的检测,得到文本主题数据集合{t1,t2,...,t
n
};
[0042]
步骤3:相似度计算;
[0043]
在文本向量集合的基础上,结合文本主题数据集合进行向量数据筛选,得到主题向量集合,随后将主题向量信息与文本向量信息结合,计算得到文本相似度,相似度计算的具体过程如下:
[0044]
步骤3
‑
1:对每个文本主题中的高频词进行权重标注,将高频词出现的概率设定为主题权重,并且与文本向量集合中对应该文本主题的文本向量进行结合,得到主题向量集合,计算公式如下所示:
[0045][0046]
其中,v(d
i
)表示该文本主题的向量表示,表示主题权重,h为主题向量总数,m
为主题向量序号;
[0047]
步骤3
‑
2:使用式(2)将文本向量与主题向量相结合,用两个向量之间的的距离来表征数据项的特征。
[0048]
dis(v(d
i
),v(t
i
))=|v(d
i
)
‑
v(t
i
)|
ꢀꢀ
(2)
[0049]
步骤3
‑
3:针对两个数据项的文本向量与主题向量,使用余弦相似度计算公式,计算公式如式(3):
[0050][0051]
得到两个文本数据项之间的相似度值。
[0052]
如图2所示,btm模型的思想是对训练集中的同一上下文共同出现的一对无序的词语进行建模。通过分析建模的结果,两个词语是否属于同一类别取决于它们的共现次数。在btm模型中,假设多个主题模型的混合分布产生全部的训练集,全局的主题分布中产生每个主题。
[0053]
如图3所示为doc2vec模型构建原理,每个段落/句子都被映射到向量空间中,可以用矩阵的一列来表示。每个单词同样被映射到向量空间,可以用矩阵的一列来表示。然后将段落向量和词向量级联或者求取平均得到特征,预测句子中的下一个单词。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1