顾及长期时序依赖关系的城市事件探测方法
顾及长期时序依赖关系的城市事件探测方法
1.技术领域:本发明属于地理信息科学和大数据领域,更具体地,本发明涉及一种基于长期时序依赖关系的城市事件探测方法。
背景技术:
2.随着城市的发展,城市事件发生的频率越来越高,类型也趋于多样,如节日、自然灾害、恐怖活动或疾病爆发等都属于城市事件的范畴。城市事件的发生会对居民的日常生活造成一定的影响,有效地探测城市事件及其详细信息将有利于政府应对突发情况,开展智能化的治理工作,对社会的可持续发展具有重大的意义。
3.随着大数据如手机定位数据、出租车轨迹数据和地理标签社交媒体数据的出现,探测城市事件开始出现新的机遇。人们也曾广泛地研究、讨论过从位置数据中探测城市事件的各种方法,提出过例如时空聚类、stl、arima和传统rnn等众多方法,但已有的这些方法均存在探测结果可靠性不高的问题。基于密度的聚类,人们提出了时空聚类方法。这种方法提取位置数据集群作为时空异常或代表城市事件,然而,这类方法假定的位置数据的时空分布几乎是均匀的。当位置数据分布不均时,其探测结果的可靠性仍有待考证。基于stl和arima等传统的统计模型,在一些情况下确实能够有效地探测城市事件,然而,这些模型对输入变量有一些先验假设,导致一旦有数据缺失或过多的噪声数据都会直接影响到模型的准确性。基于传统的rnn这一类强大的深层神经网络,可以高效地捕捉位置数据的时空演化,探测时空异常,然而,由于梯度的消失与爆炸等问题,传统的rnn还是不能在位置数据之间构建起长期时序依赖关系。
4.目前基于位置数据的研究均以城市动态的一般模式为模型,然后提取其中明显偏离于城市事件模式的异常做进一步分析。极少数方法考虑了位置数据的长期时序依赖关系,探测结果的精度与可靠性均难以进一步提高。
技术实现要素:
5.本发明提供一种基于长期时序依赖关系的城市事件探测方法。
6.本发明采用一种基于长期时序依赖关系的城市事件探测方法实现,所述方法具体包括如下步骤:
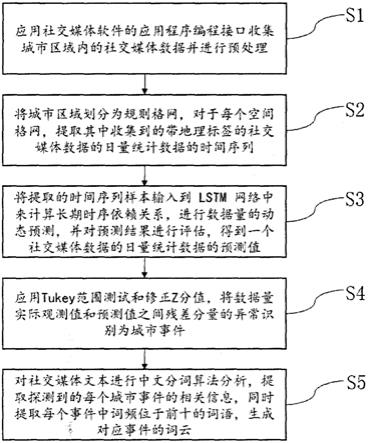
7.s1应用社交媒体软件的应用程序编程接口收集城市区域内的社交媒体数据并进行预处理;
8.s2将城市区域划分为规则格网,对于每个空间格网,提取其中收集到的带地理标签的社交媒体数据的日量统计数据的时间序列样本;
9.s3将提取的时间序列样本输入到lstm网络中来计算长期时序依赖关系,进行数据量的动态预测,并对预测结果进行评估,得到一个社交媒体数据的日量统计数据的预测值;
10.s4应用tukey范围测试和修正z分值,将数据量实际观测值和预测值之间残差分量的异常识别为城市事件;
11.s5对社交媒体文本进行中文分词算法分析,提取探测到的每个城市事件的相关信
息,同时提取每个事件中词频位于前十的词语,生成对应事件的词云。
12.进一步的所述进行数据收集和预处理的方法具体包括如下步骤:
13.基于社交媒体软件提供的应用程序接口,获取城市区域内某一连续期间内发布的带地理标签的社交媒体数据;
14.将收集到的社交媒体数据中的重复数据和噪声数据剔除,同时删除一些带有特定来源的数据,如“发布失败”的社交媒体数据,以及在其文本中带有某些特定符号例如“【】”的数据;
15.进一步的所述提取带地理标签的社交媒体数据的日量统计数据的时间序列样本的方法具体包括如下步骤:应用规则格网将特定城市区域均匀地划分为若干相同单元,对于每个单元,获取其在一定连续期间内发布的地理标签社交媒体数据的每日数量统计,得到相应格网的若干个时间序列,其中每个时间序列包括若干个连续的时间点,每个时间点的单位为一天;
16.已知某个格网内时间步t的社交媒体数据的日数量是由n个历史时间步的日数量序列所决定的,该序列可以用一个向量来表示,由此可以确定时间滞后值或历史时间点,即n。由于每天的地理标签社交媒体数据量以7天为一个周期更替,因此将时间滞后值设定为7,且每个样本都被提取为一个具有7个历史时间步的一维向量。
17.最终得到时间序列样本量n,其计算公式如下:
18.n=(一定连续期间的日期数
‑
7(时间滞后值))
×
格网数
19.进一步的所进行数据量动态预测的方法表示如下:
20.由于lstm方法在捕获长期时序依赖关系方面的良好性能,使用lstm网络结构来捕获社交媒体数据量之间的长期时序依赖关系;
21.基于keras框架,首先在lstm网络结构中的隐藏层中添加10个隐藏单元,并将lstm单元激活函数设置为线性函数,将模型的目标函数设为均方误差(mse),同时对lstm设置可以在训练过程中从神经网络中随机丢失单元的退出机制,避免发生过度拟合;
22.将提取的时间序列样本输入到lstm网络中,根据lstm模型的最终输出结果得到社交媒体数据量的预测值。
23.进一步的所使用的用来进行数据量的动态预测的lstm网络结构表示如下:
24.lstm网络结构由一个输入层,一个隐藏层(也被称为lstm单元)和一个输出层组成。将时间步骤t,x
t
的社交媒体数据量,输入lstm单元,即可输出为h
t
。
25.lstm单元中包括输入门、输出门和遗忘门,输入门和输出门是进入单元的激活,遗忘门用于在处理序列时设置内部单元格值的边界。单元的门控结构使lstm模型能够方便地构造长期时序依赖关系。输入门、输出门和遗忘门的输出可分别表示为i
t
,o
t
和f
t
,单元输入状态为其计算公式分别如下:
26.f
t
=σ(e
fx
x
t
+u
fh
h
t
‑1+b
f
)
27.i
t
=σ(w
ix
x
t
+u
ih
h
t
‑1+b
t
)
28.o
t
=σ(w
ox
x
t
+u
oh
h
t
‑1+b
o
)
29.30.其中,w
fx
,w
ix
,w
ox
和w
cx
分别表示连接lstm单元输入到遗忘门、输入门、输出门和单元输入状态的权重矩阵,u
fh
,u
ih
,u
oh
和u
ch
是连接单元前一状态到三个门和单元输入状态的权重矩阵,b
f
,b
i
,b
o
,和b
c
是偏置向量。
31.此外,lstm单元由三个单元状态组成:单元输入状态单元输出状态c
t
,以及以前的单元输出状态c
t
‑1。在lstm单元中,门激活函数表示为σ,tanh是指一个双曲正切函数,可以将自身值映射到0到1范围内的任意值。根据所得到的i
t
,o
t
,f
t
,和可以进一步用下面的方程计算出c
t
的单元输出状态和h
t
的单元输出状态:
[0032][0033]
h
t
=o
t
×
tanh(c
t
)
[0034]
其中,f
t
,o
t
和i
t
分别表示遗忘门、输出门和输入门的输出,c
t
‑1表示以前的单元输出状态。
[0035]
对于输入的每个具有n个历史时间步骤的样本x
t
=[x
t
‑
n
,x
t
‑
n+1
,
…
x
t
‑1],lstm模型的最终输出结果也是一个向量y
t
=[h
t
‑
n
,h
t
‑
n+1
,
…
h
t
‑1],该向量的最后一个元素,h
t
‑1,也即下一个时间步骤t时社交媒体量的预测值。
[0036]
进一步的所述异常城市事件的识别方法具体包括如下步骤:
[0037]
采用tukey范围测试和修正z分值两种方法从观测值和预测值之间的残差分量中探测城市事件。
[0038]
根据tukey的范围测试,残差分量异常也即城市事件是指超出其定义范围之外的值。
[0039]
计算残差分量中每个值的修正z分值,进一步量化、识别事件;
[0040]
进一步的tukey的范围的定义如下:
[0041]
[q1‑
k(q3‑
q1),q3+k(q3‑
q1)]
[0042]
其中,q1和q3分别是该组的上下四分位数,k为从1.5到3的任意值。
[0043]
进一步的修正z分值描述如下:
[0044]
z
i
=0.6745*(r
i
‑
μ)/mad
[0045]
在上式中,ri是残差分量中的第i个值;μ是残差分量的中值;mad是中值的绝对偏差的中值。
[0046]
进一步的所述提取事件相关信息并生成事件对应高频词云的方法如下:
[0047]
对事件探测的时空区域内的社交媒体数据进行提取后,对社交媒体文本应用中文分词算法进行分析,去掉其中无意义的词语,提取与探测到的城市事件相关的信息。
[0048]
提取每个事件的社交文本信息中出现频率最高的10个词语,生成了每个事件对应的词云。
[0049]
本发明提供的城市事件探测方法具有如下有益技术效果:
[0050]
(1)使用顾及长期时序依赖关系的城市事件探测方法,可以有效探测出城市事件,相比于其他探测城市事件的方法具有精确性和高效性,有利于政府面对突发城市事件如重大卫生事件,突发自然灾害,恐怖袭击等时采取相应的应急措施,对社会的可持续发展具有重要意义(2)通过对城市事件文本信息的探索与分析可以进一步探索城市事件的内涵,有利于城市管理者对城市的智能化治理与监控。
附图说明:
[0051]
图1为本发明实施例提供基于长期时序依赖关系的城市事件探测方法的流程图。
[0052]
图2为本发明所采用的lstm网络结构图
具体实施方式:
[0053]
下面对照附图,通过对实施例的描述,对本发明的具体实施方式作进一步详细的说明,以帮助本领域的技术人员对本发明的技术方案、发明构思有更完整、准确和深入的理解。
[0054]
本发明基于长期时序依赖关系,基于社交媒体软件的应用程序接口获取社交媒体数据,并使用规则格网将城市区域划分为若干相同单元,对每个单元提取其上一定连续期间内的地理标签社交媒体数据的日量统计数据,得到若干个包含连续时间点的时间序列,其中时间点的单位为1天;将提取的时间序列样本输入到lstm网络中来计算长期时序依赖关系,得到社交媒体数据量的预测值;最后通过tukey范围测试和修正z分值将预测值与观测值之间残差分量的异常识别为城市事件,同时对每一个事件进行文本分析,提取其中出现频率在前十位的词语生成对应事件的词云。
[0055]
首先基于新浪微博名为“地点”应用程序编程接口,获得北京核心区域(经度跨度为东经116.331
°
到东经116.448
°
,纬度跨度为北纬39.866
°
到北纬39.956
°
)的新浪微博数据,并对重复数据和特定来源微博进行删除,对噪声数据进行过滤。
[0056]
进一步的应用1x1千米规则格网将北京核心区域划分为100个单元,对于每个单元获取其2017年7月1日至2020年3月31日期间内所发布的地理标签社交媒体数据的每日数量统计,并利用这些数据得到相应格网的100个时间序列,其中的每个时间序列包括1005个连续的时间点,每个时间点的单位是一天。其中任意格网i的时间序列表示为
[0057]
已知任意格网内时间步t的日数量是由n个历史时间步的日数量序列所决定的,该序列可以用一个向量来表示,由此确定时间滞后值或历史时间点,即n。基于以往的研究,每天的地理标签社交媒体数据量以7天为一个周期更替,时间滞后值设定为7(涵盖一个周期)。
[0058]
样本量n的计算公式如下:
[0059]
n=(1005(日期数)
‑
7(时间滞后值)x100(格网数))=99800
[0060]
进一步的将提取样本量的时间序列输入到lstm网络中进行数据量的动态预测。
[0061]
基于keras框架,首先在lstm网络结构中的隐藏层中添加10个隐藏单元,并将lstm单元激活函数设置为线性函数,将模型的目标函数设为均方误差(mse),同时对lstm设置可以在训练过程中从神经网络中随机丢失单元的退出机制,避免发生过度拟合;
[0062]
所使用的用来进行数据量的动态预测的lstm网络结构表示如下:
[0063]
lstm网络结构由一个输入层,一个隐藏层(也被称为lstm单元)和一个输出层组成,如图2所示。将时间步骤t,x
t
的社交媒体数据量,输入lstm单元,即可输出为h
t
。
[0064]
lstm单元中包括输入门、输出门和遗忘门,输入门和输出门是进入单元的激活,遗忘门用于在处理序列时设置内部单元格值的边界。单元的门控结构使lstm模型能够方便地
构造长期时序依赖关系。输入门、输出门和遗忘门的输出可分别表示为i
t
,o
t
和f
t
,单元输入状态为其计算公式分别如下:
[0065]
f
t
=σ(w
fx
x
t
+u
fh
h
t
‑1+b
f
)
[0066]
i
t
=σ(w
ix
x
t
+u
ih
h
t
‑1+b
i
)
[0067]
o
t
=σ(w
ox
x
t
+u
oh
h
t
‑1+b
o
)
[0068][0069]
其中,w
fx
,w
ix
,w
ox
和w
cx
分别表示连接lstm单元输入到遗忘门、输入门、输出门和单元输入状态的权重矩阵,u
fh
,u
ih
,u
oh
和u
ch
是连接单元前一状态到三个门和单元输入状态的权重矩阵,b
f
,b
i
,b
o
,和b
c
是偏置向量。
[0070]
此外,lstm单元由三个单元状态组成:单元输入状态单元输出状态c
t
,以及以前的单元输出状态c
t
‑1。在lstm单元中,门激活函数表示为σ,tanh是指一个双曲正切函数,可以将自身值映射到0到1范围内的任意值。根据所得到的i
t
,o
t
,f
t
,和可以进一步用下面的方程计算出c
t
的单元输出状态和h
t
的单元输出状态:
[0071][0072]
h
t
=o
t
*tanh(c
t
)
[0073]
其中,f
t
,o
t
和i
t
分别表示遗忘门、输出门和输入门的输出,c
t
‑1表示以前的单元输出状态。
[0074]
对于输入的每个具有n个历史时间步骤的样本x
t
=[x
t
‑
n
,x
t
‑
n+1
,
…
x
t
‑1],lstm模型的最终输出结果也是一个向量y
t
=[h
t
‑
n
,h
t
‑
n+1
,
…
h
t
‑1],该向量的最后一个元素,h
t
‑1,也即下一个时间步骤t时社交媒体量的预测值。
[0075]
得到社交媒体量的预测值以后,进一步的应用tukey范围测试和修正z分值从预测值和观测值之间残差分量的异常中识别城市事件。
[0076]
根据tukey的范围测试,残差分量异常也即城市事件是指超出其定义范围之外的值。同时计算残差分量中每个值的修正z分值,进一步量化、识别城市事件;
[0077]
tukey的范围的定义如下:
[0078]
[q1‑
k(q3‑
q1),q3+k(q3‑
q1)]
[0079]
其中,q1和q3分别是该组的上下四分位数,k为从1.5到3的任意值。
[0080]
修正z分值描述如下:
[0081]
z
i
=0.6745*(r
i
‑
μ)/mad
[0082]
在上式中,ri是残差分量中的第i个值;μ是残差分量的中值;mad是中值的绝对偏差的中值。
[0083]
进一步的对探测出的每个城市事件进行社交媒体文本信息的探索并生成高频词词云。
[0084]
对事件探测的时空区域内的社交媒体数据进行提取后,对社交媒体文本应用中文分词算法进行分析,去掉其中无意义的词语,提取与探测到的城市事件相关的信息。
[0085]
提取每个事件的社交文本信息中出现频率最高的10个词语,生成了每个事件对应的词云。
[0086]
本发明提供的城市事件探测方法具有如下有益技术效果:
[0087]
(1)使用顾及长期时序依赖关系的城市事件探测方法,可以有探测出城市事件,相比于以往的探测城市事件的方法更精确可靠
[0088]
(2)通过对城市事件文本信息的探索与分析可以进一步探索城市事件的内涵。能够帮助城市的管理者制定更有效的策略来监控和管理一个城市,有利于政府面对突发城市事件采取相应的应急措施和社会的可持续发展。
[0089]
上面结合附图对本发明进行了示例性展示,但本发明实现不受单种方式的限制,只要采用了本发明的技术方案或构思方法进行的非实质性改进,或未经改进对本发明的技术和构思直接应用的,均在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1