一种基于电力审计制度的无监督知识图谱构建方法与流程
1.本发明涉及移动通讯技术领域,具体为一种基于电力审计制度的无监督知识图谱构建方法。
背景技术:
2.随着大数据时代的到来,知识工程受到了广泛关注,如何从海量的数据中提取有用的知识,是大数据分析的关键。知识图谱技术提供了一种从海量文本和图像中抽取结构化知识的手段,从而具有广阔的应用前景。
3.知识图谱的概念于2012年由谷歌正式提出,现已成为人工智能重要研究领域。知识图谱是结构化的语义网络,“主语
‑
谓语
‑
宾语”三元组(简称三元组)是其最小组成单位。从字面上看,三元组特指“主语,谓词,宾语”的组合,如“陨石,撞击,月球”这类事实。但实际上,这一概念是非常广泛的,它还可以用来指代形如“名词,属性,属性值”或“名词1,关系,名词2”的组合。为便于研究,一般将这些都统一记作“实体1,关系,实体2”。其中,实体指的是对真实世界对象的抽象。知识图谱包含数据与模式两个层面。数据即由三元组描述的每一条知识组成,规模较为庞大。模式又被称为本体,是对数据的抽象描述,规模较小。如对天眼查数据构建知识图谱,数据包含形如“张三,持股,10%”的具体知识,模式则包含“持股人,持股,持股份额”这类对数据的概括。模式可由专家人工构建或借助神经网络进行自动构建。
4.另一方面,三元组抽取为获取三元组的过程,三元组抽取是构建知识图谱的核心步骤,也是从知识图谱诞生以来就面临的一大难题。对半结构化或结构化的语料,只需对格式进行简单处理就能够得到所需的三元组。而对于非结构化的语料,则需要进行三元组抽取。由于人工抽取三元组耗时耗力、效率低下,研究者设计了诸多机器自动抽取三元组的方法。这些方法从技术层面可分为有监督、半监督和无监督三类。
5.有监督三元组抽取依赖于大量经标注的三元组。研究者需要先构造模式,并按照模式制作训练集,通过机器学习的方法训练关系分类器,然后使用关系分类器,将通过命名实体识别从句子中识别出的实体归类于模式中的关系,得到形如“实体1,关系,实体2”的三元组。常见的有监督三元组抽取方法包括基于卷积神经网络的三元组抽取、基于长短期记忆网络的三元组抽取、基于预训练语言模型bert的三元组抽取等。
6.以远程监督算法为代表的半监督三元组抽取同样需要大量经标注的三元组,但这些三元组是由机器参照一个相关领域的知识图谱自动进行标注的。该方法认为,如果一对实体之间具有某种关系,那么所有包含这对实体的句子都能够表达这种关系。例如参照知识图谱中包含“中国,首都,北京”这个三元组,那就认为待抽取语料中所有通过命名实体识别得到的含实体“中国”、“北京”的句子,都可以提取出该三元组,并将这些句子包含的关系标注为“首都”,从而完成对句子的标注。依照这一思想,研究者需要对待抽取语料按照参照图谱中的实体与关系对进行分包、关系标注,进行多事例学习。
7.无监督方法不需要标注数据,主要包括句法依存方法和特征模板方法。句法依存
方法要求研究者构筑相关领域的专用词词典,基于该词典对句子进行分词与语法依存分析,得到依存树。此后通过对依存树的遍历,根据语法特征(如主谓宾、主系表、定状补等)进行三元组抽取。特征模板方法要求研究者针对文本特征,设计特定规则模板抽取指定属性的三元组。
8.综上所述,当前尚无面向电力审计领域相关的法律制度的知识图谱构建方法,其它通用方法也未能考虑到电力审计知识图谱构建的任务特征,并且电力审计工作涉及的法律制度文件一般数量较大、规模较大,人工标注成本较高,该任务作为一个标注数据较为缺乏的中文知识图谱领域,采用有监督及半监督方法将大大提升人力和物力成本。
9.此外,当前知识图谱以及三元组抽取的无监督算法研究极少能够适应于电力审计任务中,它们通常没有考虑到电力审计相关的法律制度文档的特征,无法精准提取相关文档中的关键信息。
技术实现要素:
10.本发明的目的在于克服现有技术的不足之处,提供一种基于电力审计制度的无监督知识图谱构建方法,该方法以根据电力审计相关法律制度提取关键信息并构建知识图谱为目标,便于更好地利用电力审计相关法律制度中的相关信息,为智能问答等下游任务提供基础。
11.一种基于电力审计制度的无监督知识图谱构建方法,包括以下步骤:
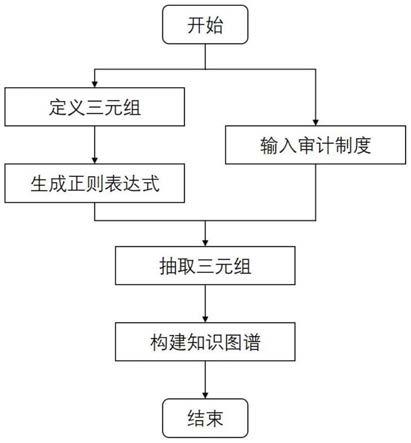
12.步骤1、定义电力审计法律制度文档关键信息的抽取规则;
13.步骤1.1、定义三元组类型与内容;
14.步骤1.2、根据定义的三元组生成正则表达式;
15.步骤2、抽取三元组:基于步骤1中生成的正则表达式以及输入的审计制度,采用无监督方法自动提取法律制度文档中的关键信息;
16.步骤3、构建知识图谱:基于步骤2中提取的三元组形式的法律制度文档中的关键信息,根据实体和关系构建知识图谱并保存,同时对关键信息进行上下文编码得到稠密的低维向量语义表示。
17.而且,步骤1中,电力审计法律制度文档关键信息抽取规则根据相关法律制度文档的特征,总结关键信息的特点并分类,定义“实体1
‑
关系
‑
实体2”三元组的内容,生成描述三元组的正则表达式。
18.而且,三元组的正则表达式包括以下几种模式:
19.模式1:法律,施行时间,对应施行时间;
20.模式2:法律,废止时间,对应废止时间;
21.模式3:法律,下属条目,对应法律第n条内容;
22.模式4:审计领域词汇,定义,对应定义内容;
23.模式5:审计领域事件,包含,对应事件包含内容。
24.而且,步骤2中,三元组抽取使用无监督的特征模板方法,根据正则表达式提取电力审计相关法律制度文件中的三元组信息。
25.而且,步骤3中,知识图谱构建根据抽取得到的三元组信息生成知识图,其中实体采用节点表示,关系采用带有方向的边来表示,并对关键信息进行上下文编码得到稠密的
低维向量语义表示。
26.本发明的优点和技术效果是:
27.本发明的一种基于电力审计制度的无监督知识图谱构建方法,针对电力审计这一特定领域的知识图谱构建任务,根据相关法律制度文档提出了五类三元组抽取模式,将文档知识转化为有结构的知识图谱,为基于知识图谱的下游任务(如电力审计知识问答)提供了基础。
28.本发明采用无监督方法抽取三元组,不需要人工额外标注数据,节省了时间和人力资源,且具有良好的扩展性和灵活性,对于今后颁布的更多新的电力审计任务相关的法律制度文件,仍可以使用本发明进行关键信息提取以及知识图谱更新。相比于基于句法依存算法抽取三元组的方法,本发明采用特征模板方法,关键信息抽取的准确率较高,且更利于知识图谱下游任务,具有智能问答中对语句近似度的比较分析等功能。
附图说明
29.图1为本发明中知识图谱构建方法的流程框图;
30.图2为本发明以实体“《专利代理条例》”为中心展开的局部知识图谱示例图。
具体实施方式
31.为能进一步了解本发明的内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下。需要说明的是,本实施例是描述性的,不是限定性的,不能由此限定本发明的保护范围。
32.一种基于电力审计制度的无监督知识图谱构建方法,包括如图1所示的以下步骤:
33.步骤1、定义电力审计法律制度文档关键信息的抽取规则;
34.步骤1.1、定义三元组类型与内容;
35.步骤1.2、根据定义的三元组生成正则表达式;
36.步骤2、抽取三元组:基于步骤1中生成的正则表达式以及输入的审计制度,采用无监督方法自动提取法律制度文档中的关键信息;
37.步骤3、构建知识图谱:基于步骤2中提取的三元组形式的法律制度文档中的关键信息,根据实体和关系构建知识图谱并保存,同时对关键信息进行上下文编码得到稠密的低维向量语义表示。
38.而且,步骤1中,电力审计法律制度文档关键信息抽取规则根据相关法律制度文档的特征,总结关键信息的特点并分类,定义“实体1
‑
关系
‑
实体2”三元组的内容,生成描述三元组的正则表达式。
39.而且,三元组的正则表达式包括以下几种模式:
40.模式1:法律,施行时间,对应施行时间;
41.模式2:法律,废止时间,对应废止时间;
42.模式3:法律,下属条目,对应法律第n条内容;
43.模式4:审计领域词汇,定义,对应定义内容;
44.模式5:审计领域事件,包含,对应事件包含内容。
45.而且,步骤2中,三元组抽取使用无监督的特征模板方法,根据正则表达式提取电
力审计相关法律制度文件中的三元组信息。
46.而且,步骤3中,知识图谱构建根据抽取得到的三元组信息生成知识图,其中实体采用节点表示,关系采用带有方向的边来表示,并对关键信息进行上下文编码得到稠密的低维向量语义表示。
47.另外,本发明优选的,为了保证系统的正常运行,在具体实施中,要求所使用的计算机平台配备不低于8g的内存,cpu核心数不低于4个且主频不低2.6ghz、gpu环境、linux操作系统,并安装python 3.6及以上版本、pytorch0.4及以上版本、neo4j图形数据库4.2.0及以上版本等必备软件环境。
48.为了更清楚地说明本发明的具体实施方式,下面提供一种实施例:
49.本发明基于来自中华人民共和国审计署网站中审计相关的法律文件内容,采用无监督特征模板方法提取三元组,构建知识图谱。
50.首先对法律文件的特征进行分析,提炼出知识图谱的模式,同时根据电力审计业务需求,总结出五类用来构建知识图谱的“实体1
‑
关系
‑
实体2”三元组模式,如下所示:
51.模式1:法律(实体1),施行时间(关系),对应施行时间(实体2)
52.模式2:法律(实体1),废止时间(关系),对应废止时间(实体2)
53.模式3:法律(实体1),下属条目(关系),对应法律第n条内容(实体2)
54.模式4:审计领域词汇(实体1),定义(关系),对应定义内容(实体2)
55.模式5:审计领域事件(实体1),包含(关系),对应事件包含内容(实体2)
56.根据上述模式及法律文本特征,设计特征模板进行三元组抽取。法律施行事件和废止时间限制了电力审计政策的查找范围,因此作为关键信息需要被抽取。此外,电力审计工作通常需要返回法律制度依据,因此模式3定义了形如“法律,下属条目,对应法律第n条内容”的三元组。特别地,为便于在将来知识图谱应用过程中溯源法律下属条目内容的来源,需要对形如“法律,下属条目,对应法律第n条内容”的三元组追加“第n条”的标签。审计领域专业词汇的定义以及审计领域事件的具体内容也是电力审计相关法律制度文档中的关键信息,分别被定义为模式4和模式5。
57.基于模式1“法律,施行时间,对应施行时间”抽取三元组。特征模板定义为
“……
施行
……”
。对《中华人民共和国监察法》文件抽取关键信息,最终抽取到的三元组结果为“《中华人民共和国监察法》,施行时间,2018年3月20日”。
58.基于模式2“法律,废止时间,对应废止时间”抽取三元组。特征模板定义为
“……
废止
……”
。对《中华人民共和国监察法》文件抽取关键信息,最终抽取到的三元组结果为“《中华人民共和国行政监察法》,废止时间,2018年3月20日”。
59.基于模式3“法律,下属条目,对应法律第n条内容”抽取三元组。特征模板定义为
“……
第n条
……”
。对《中华人民共和国监察法》文件抽取关键信息,最终抽取到的三元组结果之一为“《中华人民共和国监察法》,下属条目,中华人民共和国国家监察委员会是最高监察机关。省、自治区、直辖市、自治州、县、自治县、市、市辖区设立监察委员会。(第7条)”60.基于模式4“审计领域词汇,定义,对应定义内容”抽取三元组。特征模板定义为
“……
指的是/是指
……”
。对《中华人民共和国网络安全法》文件抽取关键信息,最终抽取到的三元组结果之一为“网络运营者,定义,网络的所有者、管理者和网络服务提供者。”61.基于模式5“审计领域事件,包含,对应事件包含内容”抽取三元组。特征模板定义
为
“……
下列/包含/包括
……”
。对《中华人民共和国监察法》文件抽取关键信息,最终抽取到的三元组结果之一为“监察机关对下列公职人员和有关人员进行监察,包含,国有企业管理人员”。
62.根据抽取的关键信息构建审计知识图谱。每个实体节点的特征表示利用word2vec模型在原始文档中对关键信息进行上下文编码得到稠密的低维向量语义表示。其次,利用图注意力深度学习模型,将知识图谱的拓朴结构信息融合到每个结点的语义表示中,通过掩码注意力将注意力机制引入图结构之中,计算与实体节点i的相邻的实体节点j特征,并使用softmax函数计算节点之间的联系。注意力机制使用一个单层的前馈神经网络,非线性激活函数为leakyrelu。注意力机制可以自适应的学习到邻居节点的融合程度。
63.传统的关系型数据库很难将存储在知识图谱中的知识及知识间的联系直观地向用户展现出来,为解决这一问题,需要以一种可视化的方式来完成三元组的存储及表示,本文采用neo4j工具以存储三元组、进行可视化知识表示,满足基于知识图谱进行智能问答的应用需求。图2是以实体“《专利代理条例》”为中心展开的局部知识图谱,其中圆形表示实体,箭头表示关系,箭头是有方向的,从实体1指向实体2。
64.最后,本发明的未述之处均采用现有技术中的成熟产品及成熟技术手段。
65.应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1