一种基于词性和语序分析的法律知识图谱自动构建方法与流程
1.本发明涉及一种法律知识图谱自动构建方法,具体为一种基于词性和语序分析的法律知识图谱自动构建方法。
背景技术:
2.知识图谱是一种由众多“实体—>关系—>实体”有向实体关系三元组组成的信息网络,这种结构可以较为有效简洁地表示现实世界中某一领域的知识关系,同时实体和关系之间的可传递性,又为知识推理创造了条件,以此可以使得原本静态的知识动态化,从而可用于辅助实现智能化的生产经营工作。目前,知识图谱已被初步应用于问答系统、推荐系统和金融风控等多个领域。在司法领域,法律判例文件中谱蕴含着的案件信息、裁判方法等信息,是宝贵的司法工作经验的综合应用和总结,若能将这些判例组织成知识图谱,再对其推理机制进行研究,那么对智能审判的实现必定能起到较大的推进作用。因此,法律判例知识图谱的构建已逐渐成为信息科学和数据科学领域的研究热点之一。
3.知识图谱的构建主要有自动化和半自动化两种方法。自动化方法虽然效率高,但是在实体识别和关系确定上,准确度并不高。而半自动化方法,虽然准确度较高,但是效率又较低。这两种方法,目前的研究都在通过各种手段去克服各自的缺点,来实现准确高效的知识图谱构建。知识图谱本身是一个复杂的信息网络,通过半自动化方式去标注构建,在人力有限的情况下,是不太现实的,而目前的自动构建方法,在实体和关系识别方面已相对成熟,但是在实体和实体之间关系的准确界定上,还并未有特别有效的方法。
技术实现要素:
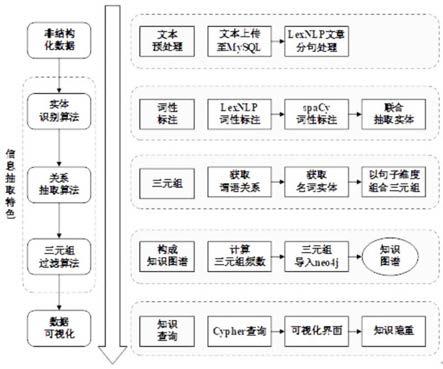
4.为解决以上现有问题,本发明提供一种基于词性和语序分析的法律知识图谱自动构建方法。本发明在已有基础上提出了一种基于实体和关系词性标注的知识图谱自动构建方法,该方法建立在lexnlp和spacy 双重词性标注基础上,根据词性标注的结果对实体进行分类,区分出句子中构成三元组中的实体和关系,再通过算法为三元组进行赋权,得到带有权重的三元组,根据权重过滤掉其中的无效三元,最终实现判例知识图谱的自动构建。本发明通过过以下技术方案实现。
5.一种基于词性和语序分析的法律知识图谱自动构建方法,包括以下步骤:
6.(一)文本预处理。将收集到的法律文本上传至mysql数据库中,并使用lexnlp进行分句处理,并记录每个句子的编号以及所在文本的编号;
7.(二)词性标注。以句子为单位,应用lexnlp进行词性分析,得到句子中的动词和名词,将这两类词连同文本编号和句子编号一起存入mysql数据库中,以确定该词在哪个文本的哪句句子中。这一步骤即完成所有法律文本的预处理,得到对应文本、对应句子的动词和名词的集合;
8.(三)三元组抽取。依次读取mysql存储的动、名词记录,根据其中事先存储的文本编号和句子编号,来确定该动名词对应的句子。应用spacy加载该句子,并对其进行语序分
析,按照三元组抽取算法原理,确定哪两个名词是主体,哪个动词是关系,以此确定三元组关系,并将该关系按照neo4j的格式规范,存入至neo4j中;
9.(四)基于三元组频数过滤的知识图谱构建。应用上述方法对整个法律文本集合进行计算,会出现多个相同的三元组,参考tf公式,使用三元组频数公式:
10.三元组频数=该三元组出现次数/出现该三元组的文章数量;
11.应用该公式计算各三元组的频数,设置一个阈值,以此来决定该三元组是否有效,有效则加入到neo4j 中。该阈值的确定,需要通过对生成的知识图谱的效果进行评估来确定;
12.(五)知识图谱的查询。通过上述步骤,所有法律文本均被转换成三元组,这些三元组共同组成了法律知识图谱,通过neo4j的知识查询功能,可以得到完整的知识图谱。
13.优选的,所述法律知识图谱自动构建方法包括选择美国caselaw access project公开的280个法律判例作为知识图谱构建语料,对所属语料进行分句和编号,将数据存储在mysql数据库。
14.优选的,所述法律知识图谱自动构建方法包括以句子为单位,使用python中的lexnlp包对分句后的语料进行词性标注,包括句子中的名词和动词,使用python中的spacy包对词性标注结果进行语序标注,包括主语、谓语、宾语。
15.优选的,所述法律知识图谱自动构建方法包括应用权重计算方法去除其中一部分无效三元组,将有效三元组以csv格式进行存储。
16.本发明的有益效果:本发明设计了一种基于词性和语序分析的知识图谱自动构建方法。该方法首先应用基于lexnlp的自然语言处理方法,以句子为单位对法律判例文本进行词性分析,以得到其中的名词和动词,再应用spacy对同一句中的名词和动词,进行语序的判断,若一个名词判断为主语或宾语,则标注为实体,若一个动词判断为宾语则标注为关系,同时提出了基于频次的三元组权重判断规则,以判断生成三元组的有效性,最终所有有效的三元组自动合并成知识图谱。最后以美国caselaw access project项目所含的判例为原始数据,进行方法有效性的验证。实验表明该方法可以有效地生成法律知识图谱。
附图说明
17.图1为本发明中三元组抽取原理的流程示意图;
18.图2为本发明中法律知识图谱构建架构图;
19.图3为法律知识图谱展示图;
20.图4为与court相关的实体及关系展示图;
21.图5为与interest相关的实体及关系展示图。
具体实施方式
22.下面根据附图对本发明的方案作更为详细、完整的说明。
23.具体实施例1,一种基于词性和语序分析的知识图谱自动构建方法;
24.基本原理:
25.<实体—>关系—>实体>三元组是知识图谱的组成单位,其描述了某一领域内的知识关系。在这一结构下,不同实体之间就存在了关系上的传导性,这种传导是知识图谱得以
进行知识推理的基础。因此三元组的确定是知识图谱构建的重要工作。而从目前的发展状况来看,实体的识别已基本实现,但实体和实体之间关系的准确界定则依然是悬而未决的问题,本发明从对词的词性和语序角度去确定实体及实体间的关系。根据图1所示,加载源文本,以句子为单位,进行句子的词性分析,得到句中的相关名词和动词,再按照语序对这些名词和动词进行分析。一个词是名词且是主语或宾语,那么该词就可以作为该句中的实体。一个词若为动词且是谓语,那么该词可视为该句所涉及实体的关系。通过这种方式,遍历所有源文件,即可得到若干三元组组成的集合,形成初步的法律知识图谱。
26.算法实现:
27.通过比较发现,lexnlp和spacy这两个自然语言处理工具,能够满足上述算法的实现要求。lexnlp 是专门针对法律领域非结构化文本的分析工具,能够对句子的词性进行分析,而spacy是世界上最快的工业级自然语言处理工具,其提供了句序分析等功能。知识图谱则采用图形数据库neo4j来存储和表示,同时,还需用mysql来存储一些算法实现过程中的辅助信息。
28.具体包括以下步骤:
29.(一)文本预处理。将收集到的法律文本上传至mysql数据库中,并使用lexnlp进行分句处理,并记录每个句子的编号以及所在文本的编号;
30.(二)词性标注。以句子为单位,应用lexnlp进行词性分析,得到句子中的动词和名词,将这两类词连同文本编号和句子编号一起存入mysql数据库中,以确定该词在哪个文本的哪句句子中。这一步骤即完成所有法律文本的预处理,得到对应文本、对应句子的动词和名词的集合;
31.(三)三元组抽取。依次读取mysql存储的动、名词记录,根据其中事先存储的文本编号和句子编号,来确定该动名词对应的句子。应用spacy加载该句子,并对其进行语序分析,按照三元组抽取算法原理,确定哪两个名词是主体,哪个动词是关系,以此确定三元组关系,并将该关系按照neo4j的格式规范,存入至neo4j中;
32.(四)基于三元组频数过滤的知识图谱构建。应用上述方法对整个法律文本集合进行计算,会出现多个相同的三元组,参考tf公式,使用三元组频数公式:
33.三元组频数=该三元组出现次数/出现该三元组的文章数量;
34.应用该公式计算各三元组的频数,设置一个阈值,以此来决定该三元组是否有效,有效则加入到neo4j 中。该阈值的确定,需要通过对生成的知识图谱的效果进行评估来确定;
35.(五)知识图谱的查询。通过上述步骤,所有法律文本均被转换成三元组,这些三元组共同组成了法律知识图谱,通过neo4j的知识查询功能,可以得到完整的知识图谱。
36.数据来源:
37.本发明选择美国caselaw access project公开的法律判例作为原始数据,该数据集目前共有650万个判例,其数据格式为jsonl。每个jsonl文件包含多个判例,实验随机选择了其中280个法律案例作为法律文本的原始数据,存入至mysql数据库中。
38.实验过程:
39.首先,对上传的280个判例进行分句,一共得到4818个句子,并与文章编号一起存入至mysql数据库中,再应用lexnlp进行词性标注,共得到68463个词语。应用spacy进行语
序分析,进而得到1844个实体和11595个三元组。以其中一句为例。
40.sentence=“plaintiff then orally moved the court to prohibit the government from using anyinformation which the defendant was precluded from using pursuant to order of the court datedseptember 11,1979.”。
41.该句子经过词性和语序标注后,结果如表1所示:
[0042][0043]
表1
[0044]
针对上述结果进行提出算法的分析后,生成的三元组如表2所示:
[0045]
[0046][0047]
表2
[0048]
其次,再将生成的所有三元组,应用权重计算方法去除其中一部分无效的三元组,最终得到7595个有效三元组,再将该三元组分为2个主体文件,另行构建一个关系文件,分别存储至csv文件中。
[0049]
最后,应用neo4j
‑
load工具将csv文件批量导入至neo4j中,存储成法律知识图谱。通过neo4j的查询语句,即可得到一张可视化的知识图谱语义网络。
[0050]
根据图3所示,框内的两个实体分别为judge、evidence,将鼠标放置在两个实体之间的连线,左下角显示关系为“find”。
[0051]
而借助neo4j的cypher查询语言,可以查询任意实体之间的关系结构,如:match(n:subject {name:'court'})
‑
[r]
‑
(a)return n,a可以查询出和court有关系的所有实体及关系,如图4所示。
[0052]
针对图中的“interests”实体,又可以查询到所有和“interest”实体节点有关系的实体节点“plaintiffs”,“abstract”等实体,如图5所示。
[0053]
整体流程:
[0054]
本发明提供一种法律知识图谱自动构建方法,包括:选择美国caselaw access project公开的280 个法律判例作为知识图谱构建语料,对所属语料进行分句和编号,将数据存储在mysql数据库;
[0055]
以句子为单位,使用python中的lexnlp包对分句后的语料进行词性标注,包括句子中的名词和动词,使用python中的spacy包对词性标注结果进行语序标注,包括主语、谓语、宾语;
[0056]
本发明的关键之处在于三元组的形成,三元组的形式<实体1,关系,实体2>。以句子为单位,选取每一个句子经过词性标注后的主语作为构成三元组的实体1,选取每一个句子经过词性标注后的宾语作为构成三元组的实体2,选取每一个句子经过词性标注后的谓
语作为构成三元组的关系;
[0057]
计算权重,应用权重计算方法去除其中一部分无效三元组,将有效三元组以csv格式进行存储;
[0058]
利用可视化工具包括:neo4j图形数据库。应用neo4j
‑
load工具将csv文件批量导入至neo4j中,存储成法律知识图谱;
[0059]
三元组频数=该三元组出现次数/出现该三元组的文章数量;
[0060]
上述方案中,选取美国caselaw access project公开的280个法律判例作为知识图谱构建语料,对语料进行分句和编号处理。根据分句结果,使用python中的lexnlp对分句结果进行词性标注,分别得到名词和动词,过滤掉句子中的其他词性。使用python中的spacy包进行句序标注,名词作为主语和宾语,动词作为谓语,分别得到句子中的主语、谓语、宾语,过滤掉句子中的其他成分。接下来是三元组的形成,选语序标注结果中的主语作为实体1,宾语作为实体2,谓语作为关系,形成<实体1,关系,实体2>这种结构的三元组抽取。
[0061]
以可视化方式对知识图谱进行展示,使用neo4j图形数据库。
[0062]
本发明设计的一种基于词性和语序分析的知识图谱自动构建方法。该方法首先应用基于lexnlp的自然语言处理方法,以句子为单位对法律判例文本进行词性分析,以得到其中的名词和动词,再应用spacy 对同一句中的名词和动词,进行语序的判断,若一个名词判断为主语或宾语,则标注为实体,若一个动词判断为宾语则标注为关系,同时提出了基于频次的三元组权重判断规则,以判断生成三元组的有效性,最终所有有效的三元组自动合并成知识图谱。最后以美国caselaw access project项目所含的判例为原始数据,进行方法有效性的验证。实验表明该方法可以有效地生成法律知识图谱。
[0063]
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”,“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0064]
以上所述仅为本发明专利的较佳实施例而已,并不用以限制本发明专利,凡在本发明专利的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明专利的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1